Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Ten artykuł jest drugą częścią siedmioczęściowej serii, która zawiera wskazówki dotyczące migracji z platformy Netezza do usługi Azure Synapse Analytics. The focus of this article is best practices for ETL and load migration.
Zagadnienia dotyczące migracji danych
Wstępne decyzje dotyczące migracji danych z netezza
Podczas migracji magazynu danych Netezza należy zadać kilka podstawowych pytań związanych z danymi. Na przykład:
Czy nieużywane struktury tabel powinny być migrowane?
Jakie jest najlepsze podejście do migracji w celu zminimalizowania ryzyka i wpływu użytkowników?
Podczas migrowania składnic danych: zostać przy rozwiązaniach fizycznych czy przejść na rozwiązania wirtualne?
W następnych sekcjach omówiono te kwestie w kontekście migracji z Netezza.
Czy przeprowadzić migrację nieużywanych tabel?
Tip
W starszych systemach nie jest niczym niezwykłym, aby tabele stały się nadmiarowe w miarę upływu czasu — w większości przypadków nie trzeba ich migrować.
Warto migrować tylko tabele, które są używane w istniejącym systemie. Tabele, które nie są aktywne, można zarchiwizować, a nie zmigrować, tak aby dane są dostępne w razie potrzeby w przyszłości. Najlepiej użyć systemowych metadanych i plików dziennika, a nie dokumentacji, aby określić, które tabele są używane, ponieważ dokumentacja może być nieaktualna.
Jeśli ta opcja jest włączona, tabele historii zapytań Netezza zawierają informacje, które mogą określić, kiedy dana tabela została ostatnio użyta — co z kolei może służyć do decydowania, czy tabela jest kandydatem do migracji.
Oto przykładowe zapytanie, które wyszukuje użycie określonej tabeli w danym przedziale czasu:
SELECT FORMAT_TABLE_ACCESS (usage),
hq.submittime
FROM "$v_hist_queries" hq
INNER JOIN "$hist_table_access_3" hta USING
(NPSID, NPSINSTANCEID, OPID, SESSIONID)
WHERE hq.dbname = 'PROD'
AND hta.schemaname = 'ADMIN'
AND hta.tablename = 'TEST_1'
AND hq.SUBMITTIME > '01-01-2015'
AND hq.SUBMITTIME <= '08-06-2015'
AND
(
instr(FORMAT_TABLE_ACCESS(usage),'ins') > 0
OR instr(FORMAT_TABLE_ACCESS(usage),'upd') > 0
OR instr(FORMAT_TABLE_ACCESS(usage),'del') > 0
)
AND status=0;
| FORMAT_TABLE_ACCESS | SUBMITTIME
----------------------+---------------------------
ins | 2015-06-16 18:32:25.728042
ins | 2015-06-16 17:46:14.337105
ins | 2015-06-16 17:47:14.430995
(3 rows)
To zapytanie używa funkcji pomocniczej FORMAT_TABLE_ACCESS i cyfry na końcu widoku $v_hist_table_access_3, aby zsynchronizować zainstalowaną wersję historii zapytań.
Jakie jest najlepsze podejście do migracji w celu zminimalizowania ryzyka i wpływu na użytkowników?
Często pojawia się to pytanie, ponieważ firmy mogą chcieć zmniejszyć wpływ zmian w modelu danych magazynu danych w celu zwiększenia elastyczności. Firmy często widzą możliwość dalszej modernizacji lub przekształcania danych podczas migracji ETL. Takie podejście wiąże się z wyższym ryzykiem, ponieważ zmienia jednocześnie wiele czynników, co utrudnia porównywanie wyników starego systemu w porównaniu z nowym. Making data model changes here could also affect upstream or downstream ETL jobs to other systems. Because of that risk, it's better to redesign on this scale after the data warehouse migration.
Nawet jeśli model danych został celowo zmieniony w ramach ogólnej migracji, dobrym rozwiązaniem jest migrowanie istniejącego modelu jako do usługi Azure Synapse, a nie ponownej inżynierii na nowej platformie. Takie podejście minimalizuje wpływ na istniejące systemy produkcyjne, a jednocześnie korzysta z wydajności i elastycznej skalowalności platformy Azure na potrzeby jednorazowych zadań ponownej inżynierii.
Podczas migracji z platformy Netezza często istniejący model danych jest już odpowiedni do migracji as-is do usługi Azure Synapse.
Tip
Najpierw przeprowadź migrację istniejącego modelu, nawet jeśli w przyszłości zaplanowano zmianę modelu danych.
Migrate data marts: stay physical or go virtual?
Tip
Wirtualizacja składnic danych może zaoszczędzić na magazynie i przetwarzaniu zasobów.
W starszych środowiskach magazynu danych Netezza często warto utworzyć kilka składnic danych, które mają strukturę zapewniającą dobrą wydajność dla zapytań samoobsługowych ad hoc i raportów dla danego działu lub funkcji biznesowej w organizacji. W związku z tym składnica danych zwykle składa się z podzestawu magazynu danych i zawiera zagregowane wersje danych w postaci, która umożliwia użytkownikom łatwe wykonywanie zapytań o te dane z szybkimi czasami odpowiedzi za pośrednictwem przyjaznych dla użytkownika narzędzi zapytań, takich jak Microsoft Power BI, Tableau lub MicroStrategy. Ten formularz jest zazwyczaj modelem danych wymiarowych. One use of data marts is to expose the data in a usable form, even if the underlying warehouse data model is something different, such as a data vault.
Możesz użyć oddzielnych składnic danych dla poszczególnych jednostek biznesowych w organizacji, aby zaimplementować niezawodne systemy zabezpieczeń danych, zezwalając tylko użytkownikom na dostęp do określonych składnic danych, które są dla nich istotne, oraz eliminując, zaciemniając lub anonimizując poufne dane.
Jeśli te składnice danych są implementowane jako tabele fizyczne, będą wymagać dodatkowych zasobów pamięciowych na ich przechowywanie oraz dodatkowego przetwarzania w celu regularnej budowy i odświeżania. Ponadto dane w bazie mart będą aktualne tylko do momentu ostatniej operacji odświeżania, dlatego mogą być nieodpowiednie dla bardzo zmiennych pulpitów danych.
Tip
Wydajność i skalowalność usługi Azure Synapse umożliwia wirtualizację bez poświęcania wydajności.
Wraz z pojawieniem się stosunkowo tanich, skalowalnych architektur MPP, takich jak Azure Synapse, oraz ich nieodłącznymi cechami wydajnościowymi, możliwe jest zapewnienie funkcjonalności składnicy danych bez konieczności instancjonowania jej jako zestawu fizycznych tabel. Jest to osiągane przez efektywne wirtualizację składnic danych za pośrednictwem widoków SQL w głównym magazynie danych lub za pośrednictwem warstwy wirtualizacji przy użyciu takich funkcji jak widoki na platformie Azure lub produkty wizualizacji partnerów firmy Microsoft. Takie podejście upraszcza lub eliminuje konieczność dodatkowego przetwarzania magazynu i agregacji oraz zmniejsza ogólną liczbę obiektów bazy danych do zmigrowania.
Istnieje kolejna potencjalna korzyść z tego podejścia. Implementując logikę agregacji i sprzężenia w warstwie wirtualizacji oraz prezentując zewnętrzne narzędzia raportowania za pośrednictwem zwirtualizowanego widoku, przetwarzanie wymagane do utworzenia tych widoków jest "wypychane" do magazynu danych, co jest zazwyczaj najlepszym miejscem do uruchamiania sprzężeń, agregacji i innych powiązanych operacji na dużych woluminach danych.
Podstawowe czynniki do wybierania implementacji wirtualnej składnicy danych zamiast fizycznej składnicy danych to:
Większa elastyczność: wirtualna składninica danych jest łatwiejsza do zmiany niż tabele fizyczne i skojarzone procesy ETL.
Niższy całkowity koszt posiadania: zwirtualizowana implementacja wymaga mniejszej liczby magazynów danych i kopii danych.
Eliminacja zadań ETL w celu migracji i uproszczenia architektury magazynu danych w środowisku zwirtualizowanym.
Performance: although physical data marts have historically been more performant, virtualization products now implement intelligent caching techniques to mitigate.
Migracja danych z platformy Netezza
Zrozum swoje dane
Część planowania migracji szczegółowo rozumie ilość danych, które należy migrować, ponieważ może to mieć wpływ na decyzje dotyczące podejścia do migracji. Użyj metadanych systemowych, aby określić miejsce fizyczne zajęte przez "nieprzetworzone dane" w tabelach do zmigrowania. W tym kontekście "surowe dane" oznaczają ilość miejsca używanego przez wiersze danych w tabeli, z wyłączeniem nadmiernych obciążeń, takich jak indeksy i kompresja. This is especially true for the largest fact tables since these will typically comprise more than 95% of the data.
Możesz uzyskać dokładną liczbę danych, które mają zostać zmigrowane dla danej tabeli, wyodrębniając reprezentatywną próbkę danych — na przykład milion wierszy — do nieskompresowanego prostego pliku danych ASCII. Następnie użyj rozmiaru tego pliku, aby uzyskać średni rozmiar danych pierwotnych na wiersz tej tabeli. Na koniec pomnóż ten średni rozmiar przez łączną liczbę wierszy w pełnej tabeli, aby nadać tabeli nieprzetworzone dane. Użyj tej wielkości surowych danych w planowaniu.
Mapowanie typu danych Netezza
Tip
Oceń wpływ nieobsługiwanych typów danych w ramach fazy przygotowania.
Większość typów danych Netezza ma bezpośredni odpowiednik w usłudze Azure Synapse. W poniższej tabeli przedstawiono te typy danych wraz z zalecanym podejściem do ich mapowania.
| Typ danych Netezza | Typ danych usługi Azure Synapse |
|---|---|
| BIGINT | BIGINT |
| BINARY VARYING(n) | VARBINARY(n) |
| BOOLEAN | BIT |
| BYTEINT | TINYINT |
| CHARACTER VARYING(n) | VARCHAR(n) |
| CHARACTER(n) | CHAR(n) |
| DATE | DATE(date) |
| DECIMAL(p,s) | DECIMAL(p,s) |
| PODWÓJNA PRECYZJA | FLOAT |
| FLOAT(n) | FLOAT(n) |
| INTEGER | INT |
| INTERWAŁ | Typy danych INTERVAL nie są obecnie bezpośrednio obsługiwane w usłudze Azure Synapse Analytics, ale można je obliczyć przy użyciu funkcji czasowych, takich jak DATEDIFF. |
| PIENIĄDZE | PIENIĄDZE |
| NATIONAL CHARACTER VARYING(n) | NVARCHAR(n) |
| ZNAK NARODOWY (n) | NCHAR(n) |
| NUMERIC(p,s) | NUMERIC(p,s) |
| REAL | REAL |
| SMALLINT | SMALLINT |
| ST_GEOMETRY(n) | Typy danych przestrzennych, takie jak ST_GEOMETRY, nie są obecnie obsługiwane w usłudze Azure Synapse Analytics, ale dane mogą być przechowywane jako VARCHAR lub VARBINARY. |
| CZAS | CZAS |
| TIME WITH TIME ZONE | DATETIMEOFFSET |
| TIMESTAMP | DATA I CZAS |
Użyj metadanych z tabel wykazu Netezza, aby określić, czy którykolwiek z tych typów danych należy zmigrować i zezwolić na to w planie migracji. Ważne widoki metadanych w netezza dla tego typu zapytania to:
_V_USER: widok użytkownika zawiera informacje o użytkownikach w systemie Netezza._V_TABLE: widok tabeli zawiera listę tabel utworzonych w systemie wydajności Netezza._V_RELATION_COLUMN: widok systemowego katalogu kolumn relacji zawiera kolumny dostępne w tabeli._V_OBJECTS: widok obiektów zawiera listę różnych obiektów, takich jak tabele, widok, funkcje itd., które są dostępne w netezza.
Na przykład to zapytanie Netezza SQL pokazuje kolumny i typy kolumn:
SELECT
tablename,
attname AS COL_NAME,
b.FORMAT_TYPE AS COL_TYPE,
attnum AS COL_NUM
FROM _v_table a
JOIN _v_relation_column b
ON a.objid = b.objid
WHERE a.tablename = 'ATT_TEST'
AND a.schema = 'ADMIN'
ORDER BY attnum;
TABLENAME | COL_NAME | COL_TYPE | COL_NUM
----------+-------------+----------------------+--------
ATT_TEST | COL_INT | INTEGER | 1
ATT_TEST | COL_NUMERIC | NUMERIC(10,2) | 2
ATT_TEST | COL_VARCHAR | CHARACTER VARYING(5) | 3
ATT_TEST | COL_DATE | DATE | 4
(4 rows)
Kwerendę można zmodyfikować, aby wyszukiwać wszystkie tabele pod kątem wystąpień nieobsługiwanych typów danych.
Usługa Azure Data Factory może służyć do przenoszenia danych ze starszego środowiska Netezza. Aby uzyskać więcej informacji, zobacz ŁĄCZNIK IBM Netezza.
Zewnętrzni dostawcy oferują narzędzia i usługi do automatyzacji migracji, w tym mapowanie typów danych zgodnie z wcześniejszym opisem. Ponadto narzędzia ETL innych firm, takie jak Informatica lub Talend, już używane w środowisku Netezza, mogą implementować wszystkie wymagane przekształcenia danych. W następnej sekcji omówiono migrację istniejących procesów ETL innych firm.
Zagadnienia dotyczące migracji ETL
Wstępne decyzje dotyczące migracji ETL Netezza
Tip
Zaplanuj z wyprzedzeniem podejście do migracji ETL i w razie potrzeby skorzystaj z obiektów platformy Azure.
W przypadku przetwarzania ETL/ELT starsze magazyny danych Netezza mogą używać niestandardowych skryptów za pomocą narzędzi Netezza, takich jak nzsql i nzload, lub narzędzi ETL innych firm, takich jak Informatica lub Ab Initio. Czasami magazyny danych Netezza używają kombinacji metod ETL i ELT, które ewoluowały wraz z upływem czasu. Podczas planowania migracji do usługi Azure Synapse należy określić najlepszy sposób wdrożenia wymaganego przetwarzania ETL/ELT w nowym środowisku przy jednoczesnym zminimalizowaniu kosztów i ryzyka. Aby dowiedzieć się więcej na temat przetwarzania ETL i ELT, zobacz Podejście projektowe ELT vs ETL.
The following sections discuss migration options and make recommendations for various use cases. Ten schemat blokowy zawiera podsumowanie jednego podejścia:
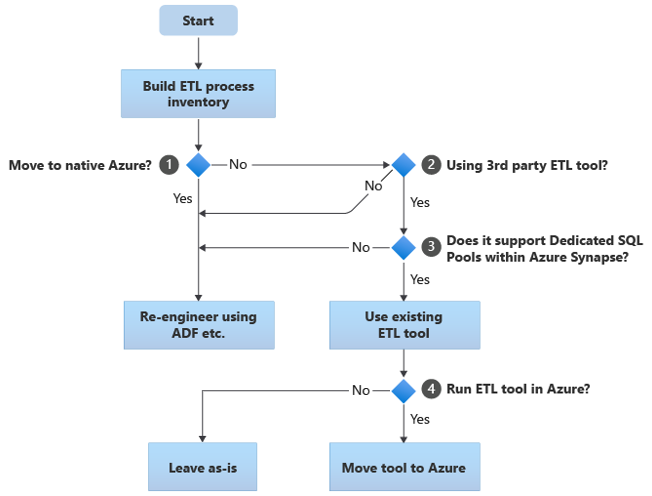
Pierwszym krokiem jest zawsze utworzenie spisu procesów ETL/ELT, które należy zmigrować. Podobnie jak w przypadku innych kroków, istnieje możliwość, że standardowe "wbudowane" funkcje platformy Azure sprawiają, że nie trzeba migrować niektórych istniejących procesów. Dla celów planowania ważne jest, aby zrozumieć skalę migracji do wykonania.
W poprzednim schemacie blokowym decyzja 1 odnosi się do decyzji wysokiego poziomu o tym, czy przeprowadzić migrację do całkowicie natywnego środowiska platformy Azure. Jeśli przechodzisz do całkowicie natywnego środowiska platformy Azure, zalecamy ponowne zaprojektowanie przetwarzania ETL przy użyciu potoków i działań w usłudze Azure Data Factory lub Azure Synapse Pipelines. Jeśli nie przenosisz się do całkowicie natywnego środowiska platformy Azure, decyzja 2 dotyczy tego, czy istniejące narzędzie ETL innej firmy jest już używane.
Tip
Wykorzystanie inwestycji w istniejące narzędzia innych firm w celu zmniejszenia kosztów i ryzyka.
Jeśli narzędzie ETL innej firmy jest już używane, a zwłaszcza jeśli istnieje duża inwestycja w umiejętności lub kilka istniejących przepływów pracy i harmonogramów używa tego narzędzia, decyzja 3 polega na tym, czy narzędzie może efektywnie obsługiwać usługę Azure Synapse jako środowisko docelowe. W idealnym przypadku narzędzie będzie zawierać "natywne" łączniki, które mogą korzystać z obiektów platformy Azure, takich jak PolyBase lub COPY INTO, w celu najbardziej wydajnego ładowania danych. Istnieje sposób wywoływania procesu zewnętrznego, takiego jak PolyBase lub COPY INTO, i przekazywania odpowiednich parametrów. W tym przypadku skorzystaj z istniejących umiejętności i przepływów pracy, korzystając z usługi Azure Synapse jako nowego środowiska docelowego.
Jeśli zdecydujesz się zachować istniejące narzędzie ETL innej firmy, mogą istnieć korzyści wynikające z uruchamiania tego narzędzia w środowisku platformy Azure (zamiast istniejącego lokalnego serwera ETL) i obsługi ogólnej aranżacji istniejących przepływów pracy w usłudze Azure Data Factory. Jedną z szczególnych korzyści jest to, że mniej danych należy pobrać z platformy Azure, przetworzyć, a następnie przekazać z powrotem na platformę Azure. Dlatego decyzja 4 dotyczy pozostawienia istniejącego narzędzia uruchomionego as-is lub przeniesienia go do środowiska platformy Azure w celu uzyskania korzyści związanych z kosztami, wydajnością i skalowalnością.
Przeprojektuj istniejące, specyficzne dla Netezza skrypty
Jeśli niektóre lub wszystkie istniejące przetwarzanie ETL/ELT magazynu Netezza są obsługiwane przez niestandardowe skrypty korzystające z narzędzi specyficznych dla platformy Netezza, takich jak nzsql lub nzload, te skrypty muszą zostać ponownie zakodowane dla nowego środowiska usługi Azure Synapse. Podobnie, jeśli procesy ETL zostały wdrożone przy użyciu procedur składowanych w Netezza, będą one również musiały zostać ponownie zakodowane.
Tip
Spis zadań ETL do zmigrowania powinien obejmować skrypty i procedury składowane.
Niektóre elementy procesu ETL można łatwo migrować, na przykład przez proste zbiorcze ładowanie danych do tabeli przejściowej z pliku zewnętrznego. Może być nawet możliwe zautomatyzowanie tych części procesu, na przykład przy użyciu technologii PolyBase zamiast nzload. Inne części procesu, które zawierają złożone zapytania SQL i/lub procedury składowane, będą wymagały więcej czasu na ponowne zaprojektowanie.
One way of testing Netezza SQL for compatibility with Azure Synapse is to capture some representative SQL statements from Netezza query history, then prefix those queries with EXPLAIN, and then—assuming a like-for-like migrated data model in Azure Synapse—run those EXPLAIN statements in Azure Synapse. Każdy niezgodny program SQL wygeneruje błąd, a informacje o błędzie mogą określić skalę zadania recodowania.
Partnerzy firmy Microsoft oferują narzędzia i usługi do migrowania programu Netezza SQL i procedur składowanych do usługi Azure Synapse.
Korzystanie z narzędzi ETL innych firm
Zgodnie z opisem w poprzedniej sekcji w wielu przypadkach istniejący starszy system magazynu danych zostanie już wypełniony i obsługiwany przez produkty ETL innych firm. Aby uzyskać listę partnerów integracji danych firmy Microsoft dla usługi Azure Synapse, zobacz Partnerzy integracji danych.
Ładowanie danych z platformy Netezza
Opcje dostępne podczas ładowania danych z platformy Netezza
Tip
Narzędzia innych firm mogą uprościć i zautomatyzować proces migracji, a tym samym zmniejszyć ryzyko.
Jeśli chodzi o migrację danych z magazynu danych Netezza, istnieją pewne podstawowe pytania związane z ładowaniem danych, które należy rozwiązać. Musisz zdecydować, w jaki sposób dane zostaną fizycznie przeniesione z istniejącego lokalnego środowiska Netezza do usługi Azure Synapse w chmurze i które narzędzia będą używane do przenoszenia i ładowania. Weź pod uwagę następujące pytania, które zostały omówione w następnych sekcjach.
Czy wyodrębnisz dane do plików, czy przeniesiesz je bezpośrednio przez połączenie sieciowe?
Czy zaaranżujesz proces z systemu źródłowego, czy ze środowiska docelowego platformy Azure?
Które narzędzia będą używane do automatyzacji procesu i zarządzania nim?
Transfer danych za pośrednictwem plików lub połączenia sieciowego?
Tip
Zapoznaj się z woluminami danych, które mają zostać zmigrowane, i dostępną przepustowością sieci, ponieważ te czynniki wpływają na decyzję dotyczącą podejścia do migracji.
Po utworzeniu tabel baz danych do zmigrowania w usłudze Azure Synapse możesz przenieść dane, aby wypełnić te tabele ze starszego systemu Netezza i do nowego środowiska. Istnieją dwa podstawowe podejścia:
Wyodrębnianie pliku: wyodrębnianie danych z tabel Netezza do plików prostych, zwykle w formacie CSV, za pośrednictwem narzędzia nzsql z opcją -o lub za pomocą instrukcji
CREATE EXTERNAL TABLE. Jeśli jest to możliwe, użyj tabeli zewnętrznej, ponieważ jest to najbardziej wydajne pod względem przepływności danych. Poniższy przykład SQL tworzy plik CSV za pośrednictwem tabeli zewnętrznej:CREATE EXTERNAL TABLE '/data/export.csv' USING (delimiter ',') AS SELECT col1, col2, expr1, expr2, col3, col1 || col2 FROM your table;Użyj tabeli zewnętrznej, jeśli eksportujesz dane do zainstalowanego systemu plików na lokalnym hoście Netezza. If you're exporting data to a remote machine that has JDBC, ODBC, or OLEDB installed, then your "remotesource odbc" option is the
USINGclause.Takie podejście wymaga miejsca, aby umieścić wyodrębnione pliki danych. Miejsce może być lokalne w źródłowej bazie danych Netezza (jeśli jest dostępna wystarczająca ilość miejsca) lub zdalne w usłudze Azure Blob Storage. Najlepszą wydajność jest osiągana, gdy plik jest zapisywany lokalnie, ponieważ pozwala to uniknąć narzutów sieciowych.
Aby zminimalizować wymagania dotyczące magazynu i transferu sieciowego, dobrym rozwiązaniem jest kompresowanie wyodrębnionych plików danych przy użyciu narzędzia takiego jak gzip.
Once extracted, the flat files can either be moved into Azure Blob Storage (collocated with the target Azure Synapse instance), or loaded directly into Azure Synapse using PolyBase or COPY INTO. Metoda fizycznego przenoszenia danych z lokalnego magazynu do środowiska chmury platformy Azure zależy od ilości danych i dostępnej przepustowości sieci.
Firma Microsoft oferuje różne opcje przenoszenia dużych ilości danych, w tym narzędzia AzCopy do przenoszenia plików między siecią do usługi Azure Storage, usługi Azure ExpressRoute na potrzeby przenoszenia danych zbiorczych za pośrednictwem prywatnego połączenia sieciowego, a także usługi Azure Data Box dla plików przenoszonych do fizycznego urządzenia magazynu, które następnie są wysyłane do centrum danych platformy Azure do ładowania. Aby uzyskać więcej informacji, zobacz Transfer danych.
Bezpośrednie wyodrębnianie i ładowanie między sieciami: docelowe środowisko platformy Azure wysyła żądanie wyodrębniania danych, zwykle za pomocą polecenia SQL, do starszego systemu Netezza w celu wyodrębnienia danych. Wyniki są wysyłane przez sieć i ładowane bezpośrednio do usługi Azure Synapse, bez konieczności przechodzenia danych do plików pośrednich. Czynnikiem ograniczającym w tym scenariuszu jest zwykle przepustowość połączenia sieciowego między bazą danych Netezza a środowiskiem platformy Azure. W przypadku bardzo dużych ilości danych takie podejście może nie być praktyczne.
Istnieje również podejście hybrydowe, które korzysta z obu metod. For example, you can use the direct network extract approach for smaller dimension tables and samples of the larger fact tables to quickly provide a test environment in Azure Synapse. W przypadku dużych tabel faktów historycznych można użyć metody wyodrębniania i transferu plików przy użyciu usługi Azure Data Box.
Orchestrate from Netezza or Azure?
Zalecane podejście podczas przechodzenia do usługi Azure Synapse polega na organizowaniu wyodrębniania i ładowania danych ze środowiska platformy Azure przy użyciu usług Azure Synapse Pipelines lub Azure Data Factory, a także skojarzonych narzędzi, takich jak PolyBase lub COPY INTO, w celu najbardziej wydajnego ładowania danych. Takie podejście wykorzystuje możliwości platformy Azure i zapewnia łatwą metodę tworzenia potoków ładowania danych wielokrotnego użytku.
Inne zalety tego podejścia obejmują ograniczony wpływ na system Netezza podczas procesu ładowania danych, ponieważ proces zarządzania i ładowania działa na platformie Azure oraz możliwość automatyzacji procesu przy użyciu potoków ładowania danych opartych na metadanych.
Których narzędzi można użyć?
Zadaniem przekształcania i przenoszenia danych jest podstawowa funkcja wszystkich produktów ETL. Jeśli jeden z tych produktów jest już używany w istniejącym środowisku Netezza, użycie istniejącego narzędzia ETL może uprościć migrację danych z netezza do usługi Azure Synapse. W tym podejściu przyjęto założenie, że narzędzie ETL obsługuje usługę Azure Synapse jako środowisko docelowe. Aby uzyskać więcej informacji na temat narzędzi obsługujących usługę Azure Synapse, zobacz Partnerzy integracji danych.
Jeśli używasz narzędzia ETL, rozważ uruchomienie tego narzędzia w środowisku platformy Azure, aby skorzystać z wydajności, skalowalności i kosztów platformy Azure oraz zwolnienia zasobów w centrum danych Netezza. Kolejną korzyścią jest zmniejszenie przenoszenia danych między chmurą i środowiskami lokalnymi.
Podsumowanie
Podsumowując, nasze zalecenia dotyczące migrowania danych i skojarzonych procesów ETL z Netezza do usługi Azure Synapse są następujące:
Zaplanuj z wyprzedzeniem pomyślne ćwiczenie migracji.
Utwórz szczegółowy spis danych i procesów, które mają zostać zmigrowane tak szybko, jak to możliwe.
Użyj systemowych metadanych i plików dziennika, aby uzyskać dokładne informacje na temat danych i użycia procesów. Nie należy polegać na dokumentacji, ponieważ może być nieaktualna.
Poznaj woluminy danych, które mają zostać zmigrowane, oraz przepustowość sieci między lokalnym centrum danych i środowiskami chmury platformy Azure.
Korzystaj ze standardowych "wbudowanych" funkcji platformy Azure, aby zminimalizować obciążenie migracji.
Identyfikowanie i zrozumienie najbardziej wydajnych narzędzi do wyodrębniania i ładowania danych zarówno w środowiskach Netezza, jak i platformy Azure. Użyj odpowiednich narzędzi w każdej fazie procesu.
Użyj obiektów platformy Azure, takich jak Azure Synapse Pipelines lub Azure Data Factory, aby zorganizować i zautomatyzować proces migracji przy jednoczesnym zminimalizowaniu wpływu na system Netezza.
Następne kroki
Aby dowiedzieć się więcej na temat operacji związanych z dostępem do zabezpieczeń, zobacz następny artykuł w tej serii: Zabezpieczenia, dostęp i operacje związane z migracjami Netezza.