Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
This article is part two of a seven-part series that provides guidance on how to migrate from Teradata to Azure Synapse Analytics. The focus of this article is best practices for ETL and load migration.
Zagadnienia dotyczące migracji danych
Initial decisions for data migration from Teradata
When migrating a Teradata data warehouse, you need to ask some basic data-related questions. Na przykład:
Czy nieużywane struktury tabel powinny być migrowane?
Jakie jest najlepsze podejście do migracji w celu zminimalizowania ryzyka i wpływu użytkowników?
Podczas migrowania składnic danych: zostać przy rozwiązaniach fizycznych czy przejść na rozwiązania wirtualne?
The next sections discuss these points within the context of migration from Teradata.
Czy przeprowadzić migrację nieużywanych tabel?
Tip
W starszych systemach nie jest niczym niezwykłym, aby tabele stały się nadmiarowe w miarę upływu czasu — w większości przypadków nie trzeba ich migrować.
Warto migrować tylko tabele, które są używane w istniejącym systemie. Tabele, które nie są aktywne, można zarchiwizować, a nie zmigrować, tak aby dane są dostępne w razie potrzeby w przyszłości. Najlepiej użyć systemowych metadanych i plików dziennika, a nie dokumentacji, aby określić, które tabele są używane, ponieważ dokumentacja może być nieaktualna.
If enabled, Teradata system catalog tables and logs contain information that can determine when a given table was last accessed—which can in turn be used to decide whether a table is a candidate for migration.
Here's an example query on DBC.Tables that provides the date of last access and last modification:
SELECT TableName, CreatorName, CreateTimeStamp, LastAlterName,
LastAlterTimeStamp, AccessCount, LastAccessTimeStamp
FROM DBC.Tables t
WHERE DataBaseName = 'databasename'
If logging is enabled and the log history is accessible, other information, such as SQL query text, is available in table DBQLogTbl and associated logging tables. For more information, see Teradata log history.
Jakie jest najlepsze podejście do migracji w celu zminimalizowania ryzyka i wpływu na użytkowników?
Często pojawia się to pytanie, ponieważ firmy mogą chcieć zmniejszyć wpływ zmian w modelu danych magazynu danych w celu zwiększenia elastyczności. Firmy często widzą możliwość dalszej modernizacji lub przekształcania danych podczas migracji ETL. Takie podejście wiąże się z wyższym ryzykiem, ponieważ zmienia jednocześnie wiele czynników, co utrudnia porównywanie wyników starego systemu w porównaniu z nowym. Making data model changes here could also affect upstream or downstream ETL jobs to other systems. Because of that risk, it's better to redesign on this scale after the data warehouse migration.
Nawet jeśli model danych został celowo zmieniony w ramach ogólnej migracji, dobrym rozwiązaniem jest migrowanie istniejącego modelu jako do usługi Azure Synapse, a nie ponownej inżynierii na nowej platformie. Takie podejście minimalizuje wpływ na istniejące systemy produkcyjne, a jednocześnie korzysta z wydajności i elastycznej skalowalności platformy Azure na potrzeby jednorazowych zadań ponownej inżynierii.
When migrating from Teradata, consider creating a Teradata environment in a VM within Azure as a stepping-stone in the migration process.
Tip
Najpierw przeprowadź migrację istniejącego modelu, nawet jeśli w przyszłości zaplanowano zmianę modelu danych.
Use a VM Teradata instance as part of a migration
One optional approach for migrating from an on-premises Teradata environment is to leverage the Azure environment to create a Teradata instance in a VM within Azure, collocated with the target Azure Synapse environment. This is possible because Azure provides cheap cloud storage and elastic scalability.
With this approach, standard Teradata utilities, such as Teradata Parallel Data Transporter—or third-party data replication tools, such as Attunity Replicate—can be used to efficiently move the subset of Teradata tables that need to be migrated to the VM instance. Then, all migration tasks can take place within the Azure environment. Takie podejście ma kilka korzyści:
After the initial replication of data, migration tasks don't impact the source system.
The Azure environment has familiar Teradata interfaces, tools, and utilities.
The Azure environment provides network bandwidth availability between the on-premises source system and the cloud target system.
Tools like Azure Data Factory can efficiently call utilities like Teradata Parallel Transporter to migrate data quickly and easily.
Proces migracji jest zorganizowany i kontrolowany całkowicie w środowisku platformy Azure.
Podczas migrowania składnic danych: zostać przy rozwiązaniach fizycznych czy przejść na rozwiązania wirtualne?
Tip
Wirtualizacja składnic danych może zaoszczędzić na magazynie i przetwarzaniu zasobów.
In legacy Teradata data warehouse environments, it's common practice to create several data marts that are structured to provide good performance for ad hoc self-service queries and reports for a given department or business function within an organization. W związku z tym składnica danych zwykle składa się z podzestawu magazynu danych i zawiera zagregowane wersje danych w postaci, która umożliwia użytkownikom łatwe wykonywanie zapytań o te dane z szybkimi czasami odpowiedzi za pośrednictwem przyjaznych dla użytkownika narzędzi zapytań, takich jak Microsoft Power BI, Tableau lub MicroStrategy. Ten formularz jest zazwyczaj modelem danych wymiarowych. One use of data marts is to expose the data in a usable form, even if the underlying warehouse data model is something different, such as a data vault.
Możesz użyć oddzielnych składnic danych dla poszczególnych jednostek biznesowych w organizacji, aby zaimplementować niezawodne systemy zabezpieczeń danych, zezwalając tylko użytkownikom na dostęp do określonych składnic danych, które są dla nich istotne, oraz eliminując, zaciemniając lub anonimizując poufne dane.
Jeśli te składnice danych są implementowane jako tabele fizyczne, będą wymagać dodatkowych zasobów pamięciowych na ich przechowywanie oraz dodatkowego przetwarzania w celu regularnej budowy i odświeżania. Ponadto dane w bazie mart będą aktualne tylko do momentu ostatniej operacji odświeżania, dlatego mogą być nieodpowiednie dla bardzo zmiennych pulpitów danych.
Tip
Wydajność i skalowalność usługi Azure Synapse umożliwia wirtualizację bez poświęcania wydajności.
Wraz z pojawieniem się stosunkowo tanich, skalowalnych architektur MPP, takich jak Azure Synapse, oraz ich nieodłącznymi cechami wydajnościowymi, możliwe jest zapewnienie funkcjonalności składnicy danych bez konieczności instancjonowania jej jako zestawu fizycznych tabel. Jest to osiągane przez efektywne wirtualizację składnic danych za pośrednictwem widoków SQL w głównym magazynie danych lub za pośrednictwem warstwy wirtualizacji przy użyciu takich funkcji jak widoki na platformie Azure lub produkty wizualizacji partnerów firmy Microsoft. Takie podejście upraszcza lub eliminuje konieczność dodatkowego przetwarzania magazynu i agregacji oraz zmniejsza ogólną liczbę obiektów bazy danych do zmigrowania.
Istnieje kolejna potencjalna korzyść z tego podejścia. Implementując logikę agregacji i sprzężenia w warstwie wirtualizacji oraz prezentując zewnętrzne narzędzia raportowania za pośrednictwem zwirtualizowanego widoku, przetwarzanie wymagane do utworzenia tych widoków jest "wypychane" do magazynu danych, co jest zazwyczaj najlepszym miejscem do uruchamiania sprzężeń, agregacji i innych powiązanych operacji na dużych woluminach danych.
Podstawowe czynniki do wybierania implementacji wirtualnej składnicy danych zamiast fizycznej składnicy danych to:
Większa elastyczność: wirtualna składninica danych jest łatwiejsza do zmiany niż tabele fizyczne i skojarzone procesy ETL.
Niższy całkowity koszt posiadania: zwirtualizowana implementacja wymaga mniejszej liczby magazynów danych i kopii danych.
Eliminacja zadań ETL w celu migracji i uproszczenia architektury magazynu danych w środowisku zwirtualizowanym.
Performance: although physical data marts have historically been more performant, virtualization products now implement intelligent caching techniques to mitigate.
Data migration from Teradata
Zrozum swoje dane
Część planowania migracji szczegółowo rozumie ilość danych, które należy migrować, ponieważ może to mieć wpływ na decyzje dotyczące podejścia do migracji. Użyj metadanych systemowych, aby określić miejsce fizyczne zajęte przez "nieprzetworzone dane" w tabelach do zmigrowania. W tym kontekście "surowe dane" oznaczają ilość miejsca używanego przez wiersze danych w tabeli, z wyłączeniem nadmiernych obciążeń, takich jak indeksy i kompresja. This is especially true for the largest fact tables since these will typically comprise more than 95% of the data.
Możesz uzyskać dokładną liczbę danych, które mają zostać zmigrowane dla danej tabeli, wyodrębniając reprezentatywną próbkę danych — na przykład milion wierszy — do nieskompresowanego prostego pliku danych ASCII. Następnie użyj rozmiaru tego pliku, aby uzyskać średni rozmiar danych pierwotnych na wiersz tej tabeli. Na koniec pomnóż ten średni rozmiar przez łączną liczbę wierszy w pełnej tabeli, aby nadać tabeli nieprzetworzone dane. Użyj tej wielkości surowych danych w planowaniu.
Zagadnienia dotyczące migracji ETL
Initial decisions regarding Teradata ETL migration
Tip
Zaplanuj z wyprzedzeniem podejście do migracji ETL i w razie potrzeby skorzystaj z obiektów platformy Azure.
For ETL/ELT processing, legacy Teradata data warehouses may use custom-built scripts using Teradata utilities such as BTEQ and Teradata Parallel Transporter (TPT), or third-party ETL tools such as Informatica or Ab Initio. Sometimes, Teradata data warehouses use a combination of ETL and ELT approaches that's evolved over time. When planning a migration to Azure Synapse, you need to determine the best way to implement the required ETL/ELT processing in the new environment while minimizing the cost and risk involved. Aby dowiedzieć się więcej na temat przetwarzania ETL i ELT, zobacz Podejście projektowe ELT vs ETL.
The following sections discuss migration options and make recommendations for various use cases. Ten schemat blokowy zawiera podsumowanie jednego podejścia:
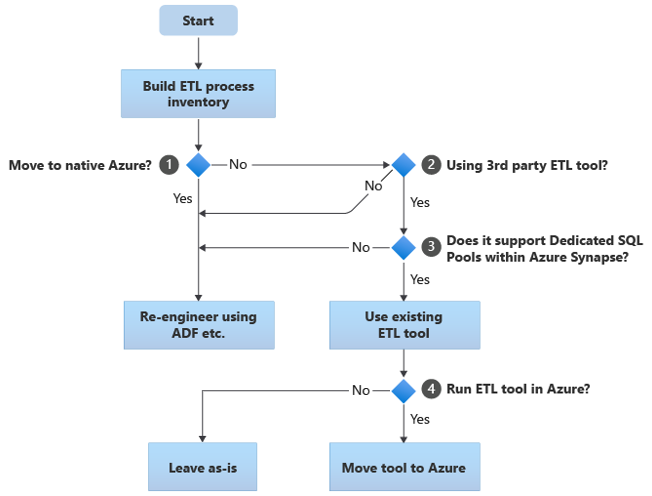
Pierwszym krokiem jest zawsze utworzenie spisu procesów ETL/ELT, które należy zmigrować. Podobnie jak w przypadku innych kroków, istnieje możliwość, że standardowe "wbudowane" funkcje platformy Azure sprawiają, że nie trzeba migrować niektórych istniejących procesów. Dla celów planowania ważne jest, aby zrozumieć skalę migracji do wykonania.
W poprzednim schemacie blokowym decyzja 1 odnosi się do decyzji wysokiego poziomu o tym, czy przeprowadzić migrację do całkowicie natywnego środowiska platformy Azure. Jeśli przechodzisz do całkowicie natywnego środowiska platformy Azure, zalecamy ponowne zaprojektowanie przetwarzania ETL przy użyciu potoków i działań w usłudze Azure Data Factory lub Azure Synapse Pipelines. Jeśli nie przenosisz się do całkowicie natywnego środowiska platformy Azure, decyzja 2 dotyczy tego, czy istniejące narzędzie ETL innej firmy jest już używane.
In the Teradata environment, some or all ETL processing may be performed by custom scripts using Teradata-specific utilities like BTEQ and TPT. In this case, your approach should be to re-engineer using Data Factory.
Tip
Wykorzystanie inwestycji w istniejące narzędzia innych firm w celu zmniejszenia kosztów i ryzyka.
Jeśli narzędzie ETL innej firmy jest już używane, a zwłaszcza jeśli istnieje duża inwestycja w umiejętności lub kilka istniejących przepływów pracy i harmonogramów używa tego narzędzia, decyzja 3 polega na tym, czy narzędzie może efektywnie obsługiwać usługę Azure Synapse jako środowisko docelowe. W idealnym przypadku narzędzie będzie zawierać "natywne" łączniki, które mogą korzystać z obiektów platformy Azure, takich jak PolyBase lub COPY INTO, w celu najbardziej wydajnego ładowania danych. Istnieje sposób wywoływania procesu zewnętrznego, takiego jak PolyBase lub COPY INTO, i przekazywania odpowiednich parametrów. W tym przypadku skorzystaj z istniejących umiejętności i przepływów pracy, korzystając z usługi Azure Synapse jako nowego środowiska docelowego.
Jeśli zdecydujesz się zachować istniejące narzędzie ETL innej firmy, mogą istnieć korzyści wynikające z uruchamiania tego narzędzia w środowisku platformy Azure (zamiast istniejącego lokalnego serwera ETL) i obsługi ogólnej aranżacji istniejących przepływów pracy w usłudze Azure Data Factory. Jedną z szczególnych korzyści jest to, że mniej danych należy pobrać z platformy Azure, przetworzyć, a następnie przekazać z powrotem na platformę Azure. Dlatego decyzja 4 dotyczy pozostawienia istniejącego narzędzia uruchomionego as-is lub przeniesienia go do środowiska platformy Azure w celu uzyskania korzyści związanych z kosztami, wydajnością i skalowalnością.
Re-engineer existing Teradata-specific scripts
If some or all the existing Teradata warehouse ETL/ELT processing is handled by custom scripts that utilize Teradata-specific utilities, such as BTEQ, MLOAD, or TPT, these scripts need to be recoded for the new Azure Synapse environment. Similarly, if ETL processes were implemented using stored procedures in Teradata, then these will also have to be recoded.
Tip
Spis zadań ETL do zmigrowania powinien obejmować skrypty i procedury składowane.
Niektóre elementy procesu ETL można łatwo migrować, na przykład przez proste zbiorcze ładowanie danych do tabeli przejściowej z pliku zewnętrznego. It may even be possible to automate those parts of the process, for example, by using PolyBase instead of fast load or MLOAD. If the exported files are Parquet, you can use a native Parquet reader, which is a faster option than PolyBase. Inne części procesu, które zawierają złożone zapytania SQL i/lub procedury składowane, będą wymagały więcej czasu na ponowne zaprojektowanie.
One way of testing Teradata SQL for compatibility with Azure Synapse is to capture some representative SQL statements from Teradata logs, then prefix those queries with EXPLAIN, and then—assuming a like-for-like migrated data model in Azure Synapse—run those EXPLAIN statements in Azure Synapse. Każdy niezgodny program SQL wygeneruje błąd, a informacje o błędzie mogą określić skalę zadania recodowania.
Microsoft partners offer tools and services to migrate Teradata SQL and stored procedures to Azure Synapse.
Korzystanie z narzędzi ETL innych firm
Zgodnie z opisem w poprzedniej sekcji w wielu przypadkach istniejący starszy system magazynu danych zostanie już wypełniony i obsługiwany przez produkty ETL innych firm. Aby uzyskać listę partnerów integracji danych firmy Microsoft dla usługi Azure Synapse, zobacz Partnerzy integracji danych.
Data loading from Teradata
Choices available when loading data from Teradata
Tip
Narzędzia innych firm mogą uprościć i zautomatyzować proces migracji, a tym samym zmniejszyć ryzyko.
When it comes to migrating data from a Teradata data warehouse, there are some basic questions associated with data loading that need to be resolved. You'll need to decide how the data will be physically moved from the existing on-premises Teradata environment into Azure Synapse in the cloud, and which tools will be used to perform the transfer and load. Weź pod uwagę następujące pytania, które zostały omówione w następnych sekcjach.
Czy wyodrębnisz dane do plików, czy przeniesiesz je bezpośrednio przez połączenie sieciowe?
Czy zaaranżujesz proces z systemu źródłowego, czy ze środowiska docelowego platformy Azure?
Które narzędzia będą używane do automatyzacji procesu i zarządzania nim?
Transfer danych za pośrednictwem plików lub połączenia sieciowego?
Tip
Zapoznaj się z woluminami danych, które mają zostać zmigrowane, i dostępną przepustowością sieci, ponieważ te czynniki wpływają na decyzję dotyczącą podejścia do migracji.
Once the database tables to be migrated have been created in Azure Synapse, you can move the data to populate those tables out of the legacy Teradata system and into the new environment. Istnieją dwa podstawowe podejścia:
File extract: extract the data from the Teradata tables to flat files, normally in CSV format, via BTEQ, Fast Export, or Teradata Parallel Transporter (TPT). Use TPT whenever possible since it's the most efficient in terms of data throughput.
Takie podejście wymaga miejsca, aby umieścić wyodrębnione pliki danych. The space could be local to the Teradata source database (if sufficient storage is available), or remote in Azure Blob Storage. Najlepszą wydajność jest osiągana, gdy plik jest zapisywany lokalnie, ponieważ pozwala to uniknąć narzutów sieciowych.
Aby zminimalizować wymagania dotyczące magazynu i transferu sieciowego, dobrym rozwiązaniem jest kompresowanie wyodrębnionych plików danych przy użyciu narzędzia takiego jak gzip.
Once extracted, the flat files can either be moved into Azure Blob Storage (collocated with the target Azure Synapse instance) or loaded directly into Azure Synapse using PolyBase or COPY INTO. Metoda fizycznego przenoszenia danych z lokalnego magazynu do środowiska chmury platformy Azure zależy od ilości danych i dostępnej przepustowości sieci.
Microsoft provides different options to move large volumes of data, including AZCopy for moving files across the network into Azure Storage, Azure ExpressRoute for moving bulk data over a private network connection, and Azure Data Box where the files are moved to a physical storage device that's then shipped to an Azure data center for loading. Aby uzyskać więcej informacji, zobacz Transfer danych.
Direct extract and load across network: the target Azure environment sends a data extract request, normally via a SQL command, to the legacy Teradata system to extract the data. Wyniki są wysyłane przez sieć i ładowane bezpośrednio do usługi Azure Synapse, bez konieczności przechodzenia danych do plików pośrednich. The limiting factor in this scenario is normally the bandwidth of the network connection between the Teradata database and the Azure environment. For very large data volumes this approach may not be practical.
Istnieje również podejście hybrydowe, które korzysta z obu metod. For example, you can use the direct network extract approach for smaller dimension tables and samples of the larger fact tables to quickly provide a test environment in Azure Synapse. For the large volume historical fact tables, you can use the file extract and transfer approach using Azure Data Box.
Orchestrate from Teradata or Azure?
The recommended approach when moving to Azure Synapse is to orchestrate the data extract and loading from the Azure environment using Azure Synapse Pipelines or Azure Data Factory, as well as associated utilities, such as PolyBase or COPY INTO, for most efficient data loading. This approach leverages the Azure capabilities and provides an easy method to build reusable data loading pipelines.
Other benefits of this approach include reduced impact on the Teradata system during the data load process since the management and loading process is running in Azure, and the ability to automate the process by using metadata-driven data load pipelines.
Których narzędzi można użyć?
Zadaniem przekształcania i przenoszenia danych jest podstawowa funkcja wszystkich produktów ETL. If one of these products is already in use in the existing Teradata environment, then using the existing ETL tool may simplify data migration from Teradata to Azure Synapse. W tym podejściu przyjęto założenie, że narzędzie ETL obsługuje usługę Azure Synapse jako środowisko docelowe. Aby uzyskać więcej informacji na temat narzędzi obsługujących usługę Azure Synapse, zobacz Partnerzy integracji danych.
If you're using an ETL tool, consider running that tool within the Azure environment to benefit from Azure cloud performance, scalability, and cost, and free up resources in the Teradata data center. Kolejną korzyścią jest zmniejszenie przenoszenia danych między chmurą i środowiskami lokalnymi.
Podsumowanie
To summarize, our recommendations for migrating data and associated ETL processes from Teradata to Azure Synapse are:
Zaplanuj z wyprzedzeniem pomyślne ćwiczenie migracji.
Utwórz szczegółowy spis danych i procesów, które mają zostać zmigrowane tak szybko, jak to możliwe.
Użyj systemowych metadanych i plików dziennika, aby uzyskać dokładne informacje na temat danych i użycia procesów. Nie należy polegać na dokumentacji, ponieważ może być nieaktualna.
Poznaj woluminy danych, które mają zostać zmigrowane, oraz przepustowość sieci między lokalnym centrum danych i środowiskami chmury platformy Azure.
Consider using a Teradata instance in an Azure VM as a stepping stone to offload migration from the legacy Teradata environment.
Korzystaj ze standardowych "wbudowanych" funkcji platformy Azure, aby zminimalizować obciążenie migracji.
Identify and understand the most efficient tools for data extraction and loading in both Teradata and Azure environments. Użyj odpowiednich narzędzi w każdej fazie procesu.
Use Azure facilities, such as Azure Synapse Pipelines or Azure Data Factory, to orchestrate and automate the migration process while minimizing impact on the Teradata system.
Następne kroki
To learn more about security access operations, see the next article in this series: Security, access, and operations for Teradata migrations.