Samouczek: tworzenie definicji zadania platformy Apache Spark w programie Synapse Studio
W tym samouczku pokazano, jak używać programu Synapse Studio do tworzenia definicji zadań platformy Apache Spark, a następnie przesyłać je do bezserwerowej puli platformy Apache Spark.
Ten samouczek obejmuje następujące zadania:
- Tworzenie definicji zadania platformy Apache Spark dla platformy PySpark (Python)
- Tworzenie definicji zadania platformy Apache Spark dla platformy Spark (Scala)
- Tworzenie definicji zadania platformy Apache Spark dla platformy .NET Spark (C#/F#)
- Tworzenie definicji zadania przez zaimportowanie pliku JSON
- Eksportowanie pliku definicji zadania platformy Apache Spark do lokalnego
- Przesyłanie definicji zadania platformy Apache Spark jako zadania wsadowego
- Dodawanie definicji zadania platformy Apache Spark do potoku
Wymagania wstępne
Przed rozpoczęciem pracy z tym samouczkiem upewnij się, że zostały spełnione następujące wymagania:
- Obszar roboczy usługi Azure Synapse Analytics. Aby uzyskać instrukcje, zobacz Tworzenie obszaru roboczego usługi Azure Synapse Analytics.
- Bezserwerowa pula platformy Apache Spark.
- Konto magazynu usługi ADLS Gen2. Musisz być współautorem danych obiektu blob usługi Storage w systemie plików usługi ADLS Gen2, z którym chcesz pracować. Jeśli tak nie jest, musisz ręcznie dodać uprawnienie.
- Jeśli nie chcesz używać domyślnego magazynu obszaru roboczego, połącz wymagane konto magazynu usługi ADLS Gen2 w programie Synapse Studio.
Tworzenie definicji zadania platformy Apache Spark dla platformy PySpark (Python)
W tej sekcji utworzysz definicję zadania platformy Apache Spark dla programu PySpark (Python).
Otwórz program Synapse Studio.
Możesz przejść do pozycji Przykładowe pliki służące do tworzenia definicji zadań platformy Apache Spark, aby pobrać przykładowe pliki dla python.zip, a następnie rozpakuj skompresowany pakiet i wyodrębnij pliki wordcount.py i shakespeare.txt .
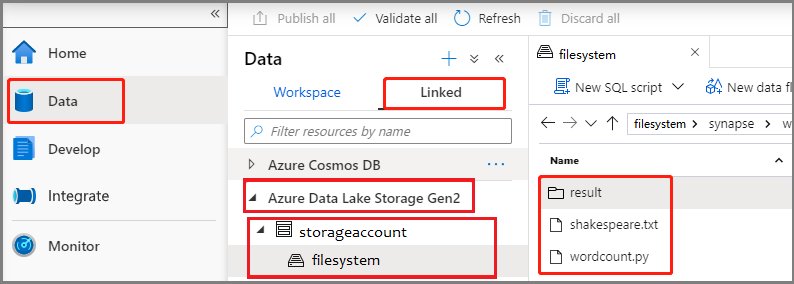
Wybierz pozycję Dane ->Linked ->Azure Data Lake Storage Gen2 i przekaż wordcount.py i shakespeare.txt do systemu plików usługi ADLS Gen2.
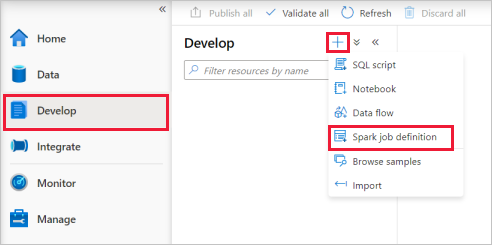
Wybierz pozycję Opracowywanie centrum, wybierz ikonę "+" i wybierz definicję zadania platformy Spark, aby utworzyć nową definicję zadania platformy Spark.
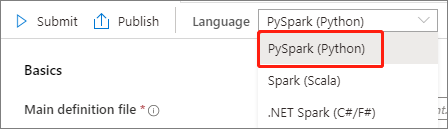
Wybierz pozycję PySpark (Python) z listy rozwijanej Język w oknie głównym definicji zadania platformy Apache Spark.
Podaj informacje dotyczące definicji zadania platformy Apache Spark.
Właściwości opis Nazwa definicji zadania Wprowadź nazwę definicji zadania platformy Apache Spark. Ta nazwa może zostać zaktualizowana w dowolnym momencie do momentu jej opublikowania.
Przykład:job definition sampleGłówny plik definicji Główny plik używany do zadania. Wybierz plik PY z magazynu. Możesz wybrać pozycję Przekaż plik , aby przekazać plik na konto magazynu.
Przykład:abfss://…/path/to/wordcount.pyArgumenty wiersza polecenia Opcjonalne argumenty zadania.
Próbka:abfss://…/path/to/shakespeare.txtabfss://…/path/to/result
Uwaga: dwa argumenty definicji przykładowego zadania są oddzielone spacją.Pliki referencyjne Dodatkowe pliki używane do odwołania w głównym pliku definicji. Możesz wybrać pozycję Przekaż plik , aby przekazać plik na konto magazynu. Pula platformy Spark Zadanie zostanie przesłane do wybranej puli platformy Apache Spark. Wersja platformy Spark Wersja platformy Apache Spark uruchomiona przez pulę platformy Apache Spark. Funkcje wykonawcze Liczba funkcji wykonawczych, które mają być podane w określonej puli platformy Apache Spark dla zadania. Rozmiar funkcji wykonawczej Liczba rdzeni i pamięci, które mają być używane dla funkcji wykonawczych podanych w określonej puli platformy Apache Spark dla zadania. Rozmiar sterownika Liczba rdzeni i pamięci, które mają być używane dla sterownika podanego w określonej puli platformy Apache Spark dla zadania. Konfiguracja platformy Apache Spark Dostosuj konfiguracje, dodając poniższe właściwości. Jeśli nie dodasz właściwości, usługa Azure Synapse będzie używać wartości domyślnej, jeśli ma to zastosowanie. 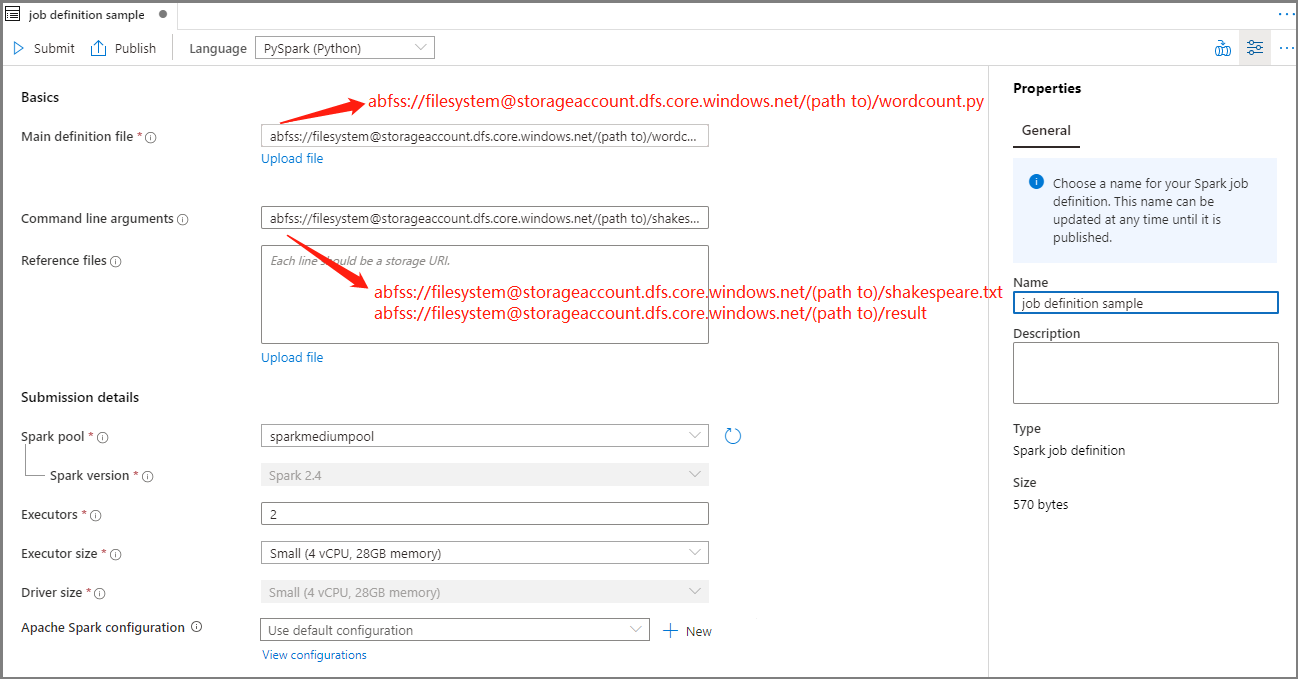
Wybierz pozycję Publikuj, aby zapisać definicję zadania platformy Apache Spark.

Tworzenie definicji zadania platformy Apache Spark dla platformy Apache Spark (Scala)
W tej sekcji utworzysz definicję zadania platformy Apache Spark dla platformy Apache Spark (Scala).
Otwórz program Azure Synapse Studio.
Możesz przejść do pozycji Przykładowe pliki służące do tworzenia definicji zadań platformy Apache Spark, aby pobrać przykładowe pliki dla scala.zip, a następnie rozpakuj skompresowany pakiet i wyodrębnij pliki wordcount.jar i shakespeare.txt .
Wybierz pozycję Dane ->Linked ->Azure Data Lake Storage Gen2 i przekaż wordcount.jar i shakespeare.txt do systemu plików usługi ADLS Gen2.
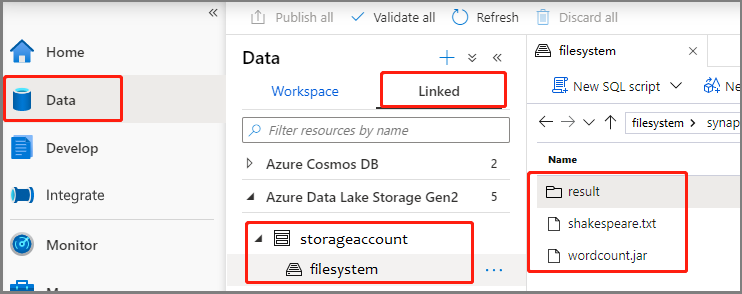
Wybierz pozycję Opracowywanie centrum, wybierz ikonę "+" i wybierz definicję zadania platformy Spark, aby utworzyć nową definicję zadania platformy Spark. (Przykładowy obraz jest taki sam jak w kroku 4) Utwórz definicję zadania platformy Apache Spark (Python) dla programu PySpark.
Wybierz pozycję Spark(Scala) z listy rozwijanej Język w oknie głównym definicji zadania platformy Apache Spark.
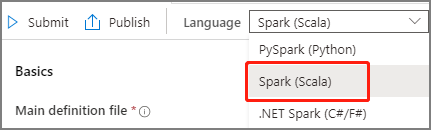
Podaj informacje dotyczące definicji zadania platformy Apache Spark. Możesz skopiować przykładowe informacje.
Właściwości opis Nazwa definicji zadania Wprowadź nazwę definicji zadania platformy Apache Spark. Ta nazwa może zostać zaktualizowana w dowolnym momencie do momentu jej opublikowania.
Przykład:scalaGłówny plik definicji Główny plik używany do zadania. Wybierz plik JAR z magazynu. Możesz wybrać pozycję Przekaż plik , aby przekazać plik na konto magazynu.
Przykład:abfss://…/path/to/wordcount.jarNazwa klasy głównej W pełni kwalifikowany identyfikator lub klasa główna, która znajduje się w głównym pliku definicji.
Przykład:WordCountArgumenty wiersza polecenia Opcjonalne argumenty zadania.
Próbka:abfss://…/path/to/shakespeare.txtabfss://…/path/to/result
Uwaga: dwa argumenty definicji przykładowego zadania są oddzielone spacją.Pliki referencyjne Dodatkowe pliki używane do odwołania w głównym pliku definicji. Możesz wybrać pozycję Przekaż plik , aby przekazać plik na konto magazynu. Pula platformy Spark Zadanie zostanie przesłane do wybranej puli platformy Apache Spark. Wersja platformy Spark Wersja platformy Apache Spark uruchomiona przez pulę platformy Apache Spark. Funkcje wykonawcze Liczba funkcji wykonawczych, które mają być podane w określonej puli platformy Apache Spark dla zadania. Rozmiar funkcji wykonawczej Liczba rdzeni i pamięci, które mają być używane dla funkcji wykonawczych podanych w określonej puli platformy Apache Spark dla zadania. Rozmiar sterownika Liczba rdzeni i pamięci, które mają być używane dla sterownika podanego w określonej puli platformy Apache Spark dla zadania. Konfiguracja platformy Apache Spark Dostosuj konfiguracje, dodając poniższe właściwości. Jeśli nie dodasz właściwości, usługa Azure Synapse będzie używać wartości domyślnej, jeśli ma to zastosowanie. 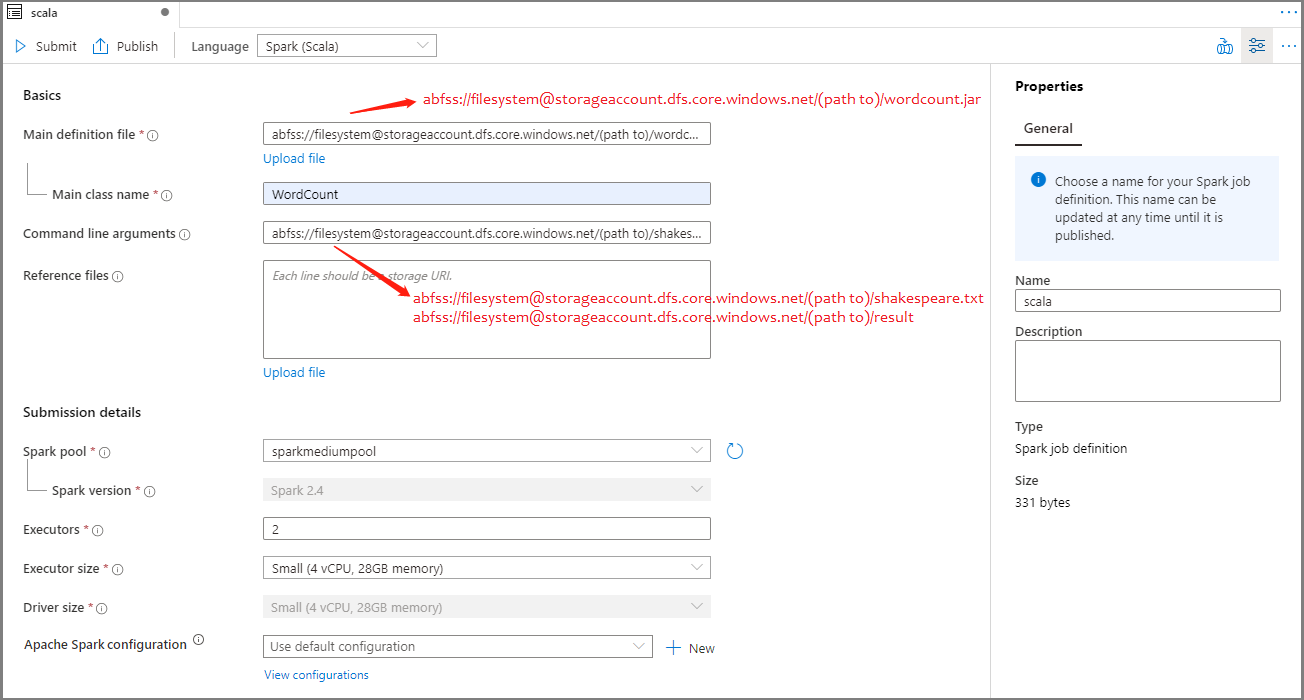
Wybierz pozycję Publikuj, aby zapisać definicję zadania platformy Apache Spark.

Tworzenie definicji zadania platformy Apache Spark dla platformy .NET Spark(C#/F#)
W tej sekcji utworzysz definicję zadania platformy Apache Spark dla platformy .NET Spark(C#/F#).
Otwórz program Azure Synapse Studio.
Możesz przejść do pozycji Przykładowe pliki służące do tworzenia definicji zadań platformy Apache Spark, aby pobrać przykładowe pliki dla dotnet.zip, a następnie rozpakuj skompresowany pakiet i wyodrębnij pliki wordcount.zip i shakespeare.txt .
Wybierz pozycję Dane ->Linked ->Azure Data Lake Storage Gen2 i przekaż wordcount.zip i shakespeare.txt do systemu plików usługi ADLS Gen2.
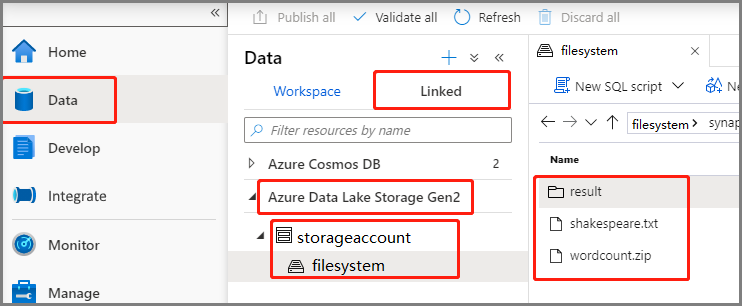
Wybierz pozycję Opracowywanie centrum, wybierz ikonę "+" i wybierz definicję zadania platformy Spark, aby utworzyć nową definicję zadania platformy Spark. (Przykładowy obraz jest taki sam jak w kroku 4) Utwórz definicję zadania platformy Apache Spark (Python) dla programu PySpark.
Wybierz pozycję .NET Spark(C#/F#) z listy rozwijanej Język w oknie głównym Definicji zadania platformy Apache Spark.
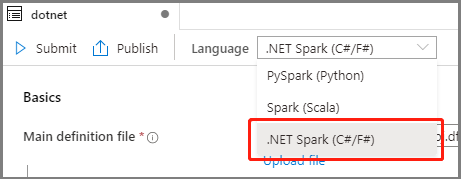
Podaj informacje dotyczące definicji zadania platformy Apache Spark. Możesz skopiować przykładowe informacje.
Właściwości opis Nazwa definicji zadania Wprowadź nazwę definicji zadania platformy Apache Spark. Ta nazwa może zostać zaktualizowana w dowolnym momencie do momentu jej opublikowania.
Przykład:dotnetGłówny plik definicji Główny plik używany do zadania. Wybierz plik ZIP zawierający aplikację platformy .NET dla platformy Apache Spark (czyli główny plik wykonywalny, biblioteki DLL zawierające funkcje zdefiniowane przez użytkownika i inne wymagane pliki) z magazynu. Możesz wybrać pozycję Przekaż plik , aby przekazać plik na konto magazynu.
Przykład:abfss://…/path/to/wordcount.zipGłówny plik wykonywalny Główny plik wykonywalny w głównym pliku ZIP definicji.
Przykład:WordCountArgumenty wiersza polecenia Opcjonalne argumenty zadania.
Próbka:abfss://…/path/to/shakespeare.txtabfss://…/path/to/result
Uwaga: dwa argumenty definicji przykładowego zadania są oddzielone spacją.Pliki referencyjne Dodatkowe pliki wymagane przez węzły procesu roboczego do wykonywania aplikacji platformy .NET dla platformy Apache Spark, które nie są uwzględnione w głównym pliku ZIP definicji (tj. zależne pliki JAR, dodatkowe biblioteki DLL funkcji zdefiniowane przez użytkownika i inne pliki konfiguracji). Możesz wybrać pozycję Przekaż plik , aby przekazać plik na konto magazynu. Pula platformy Spark Zadanie zostanie przesłane do wybranej puli platformy Apache Spark. Wersja platformy Spark Wersja platformy Apache Spark uruchomiona przez pulę platformy Apache Spark. Funkcje wykonawcze Liczba funkcji wykonawczych, które mają być podane w określonej puli platformy Apache Spark dla zadania. Rozmiar funkcji wykonawczej Liczba rdzeni i pamięci, które mają być używane dla funkcji wykonawczych podanych w określonej puli platformy Apache Spark dla zadania. Rozmiar sterownika Liczba rdzeni i pamięci, które mają być używane dla sterownika podanego w określonej puli platformy Apache Spark dla zadania. Konfiguracja platformy Apache Spark Dostosuj konfiguracje, dodając poniższe właściwości. Jeśli nie dodasz właściwości, usługa Azure Synapse będzie używać wartości domyślnej, jeśli ma to zastosowanie. 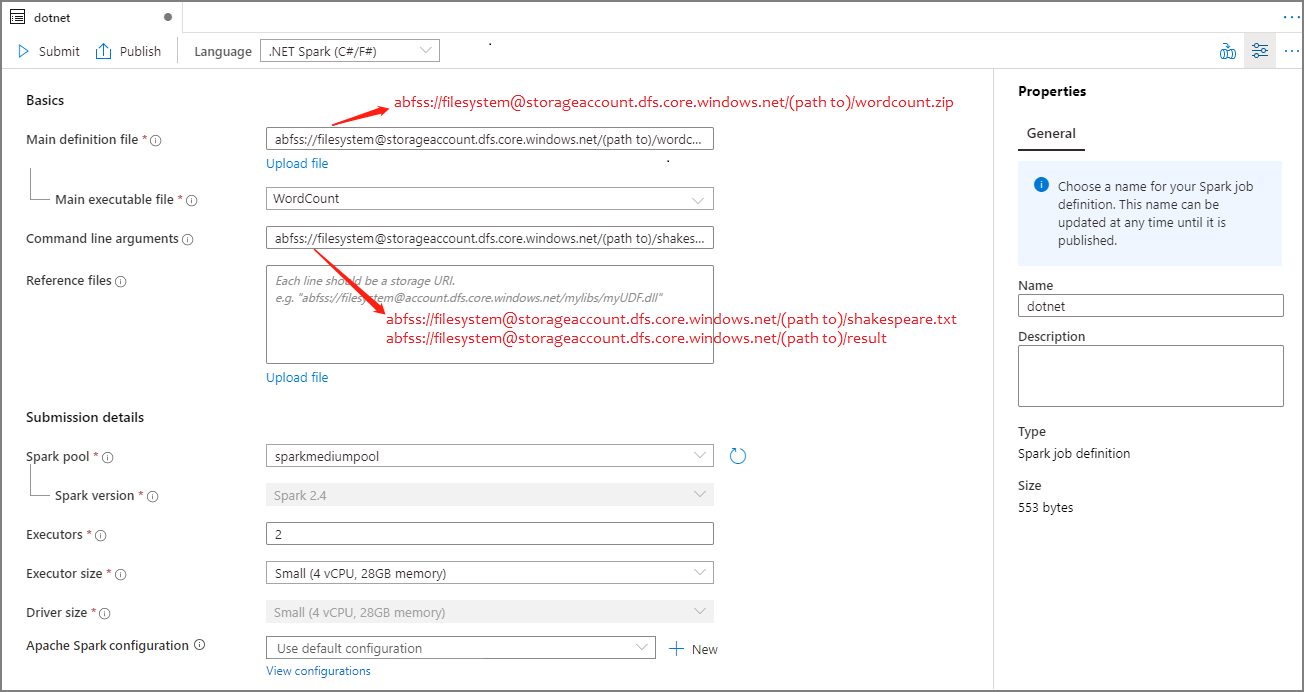
Wybierz pozycję Publikuj, aby zapisać definicję zadania platformy Apache Spark.

Uwaga
W przypadku konfiguracji platformy Apache Spark, jeśli definicja zadania platformy Apache Spark konfiguracji platformy Apache Spark nie wykonuje żadnych specjalnych czynności, podczas uruchamiania zadania zostanie użyta domyślna konfiguracja.
Tworzenie definicji zadania platformy Apache Spark przez zaimportowanie pliku JSON
Istniejący lokalny plik JSON można zaimportować do obszaru roboczego usługi Azure Synapse z menu Akcje (...) Eksploratora definicji zadania platformy Apache Spark w celu utworzenia nowej definicji zadania platformy Apache Spark.
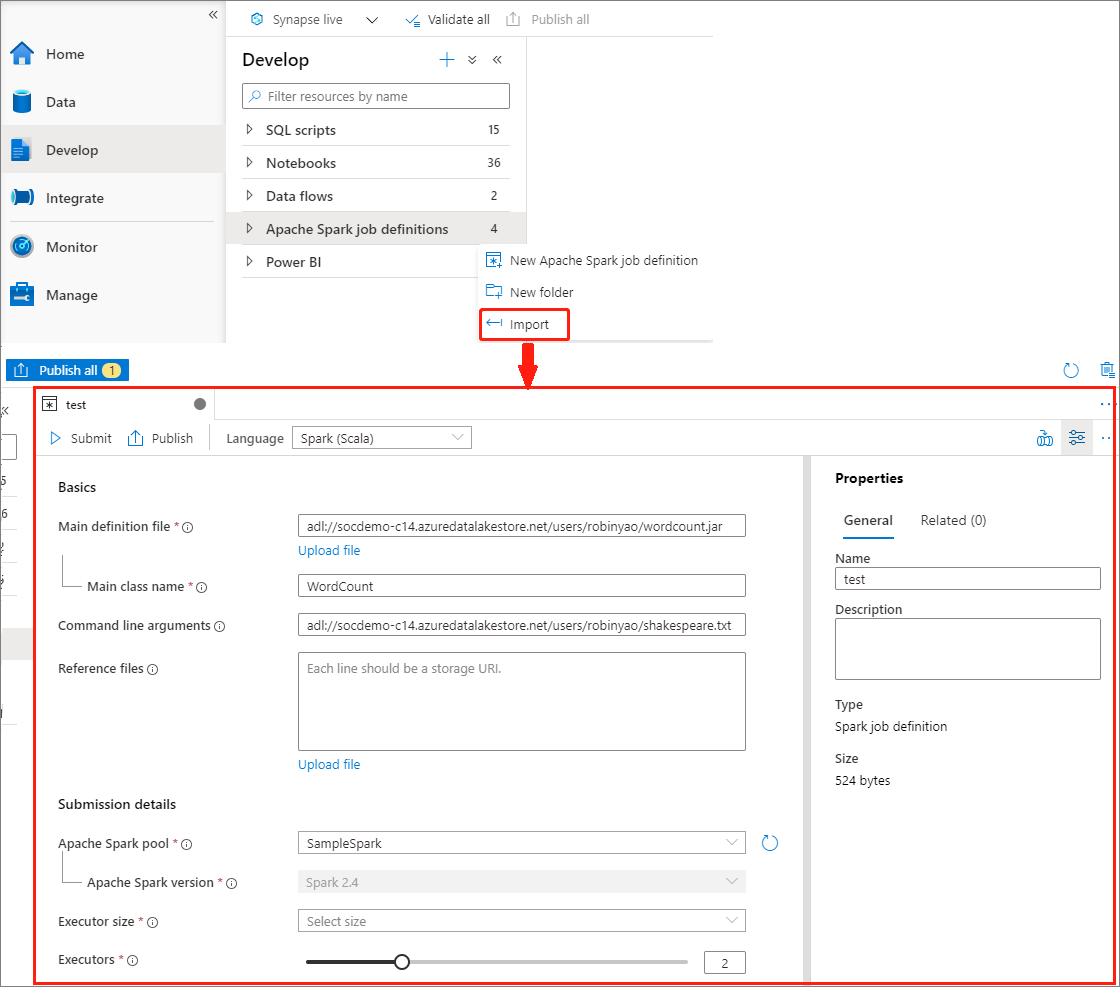
Definicja zadania platformy Spark jest w pełni zgodna z interfejsem API usługi Livy. Możesz dodać dodatkowe parametry dla innych właściwości usługi Livy (Livy Docs — interfejs API REST (apache.org) w lokalnym pliku JSON. Możesz również określić parametry powiązane z konfiguracją platformy Spark we właściwości konfiguracji, jak pokazano poniżej. Następnie możesz zaimportować plik JSON z powrotem, aby utworzyć nową definicję zadania platformy Apache Spark dla zadania wsadowego. Przykładowy kod JSON dla importowania definicji platformy Spark:
{
"targetBigDataPool": {
"referenceName": "socdemolarge",
"type": "BigDataPoolReference"
},
"requiredSparkVersion": "2.3",
"language": "scala",
"jobProperties": {
"name": "robinSparkDefinitiontest",
"file": "adl://socdemo-c14.azuredatalakestore.net/users/robinyao/wordcount.jar",
"className": "WordCount",
"args": [
"adl://socdemo-c14.azuredatalakestore.net/users/robinyao/shakespeare.txt"
],
"jars": [],
"files": [],
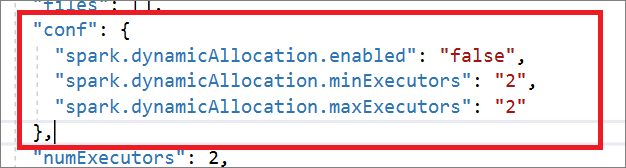
"conf": {
"spark.dynamicAllocation.enabled": "false",
"spark.dynamicAllocation.minExecutors": "2",
"spark.dynamicAllocation.maxExecutors": "2"
},
"numExecutors": 2,
"executorCores": 8,
"executorMemory": "24g",
"driverCores": 8,
"driverMemory": "24g"
}
}
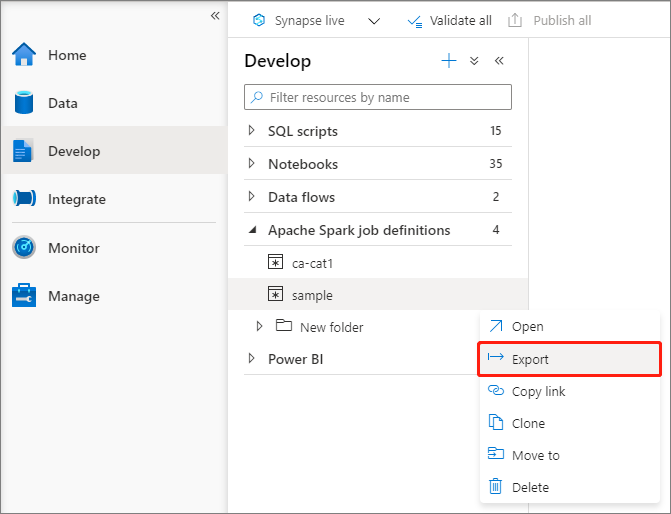
Eksportowanie istniejącego pliku definicji zadania platformy Apache Spark
Istniejące pliki definicji zadań platformy Apache Spark można wyeksportować do lokalizacji lokalnej z menu Akcje (...) Eksplorator plików. Możesz dodatkowo zaktualizować plik JSON pod kątem dodatkowych właściwości usługi Livy i zaimportować go z powrotem, aby w razie potrzeby utworzyć nową definicję zadania.
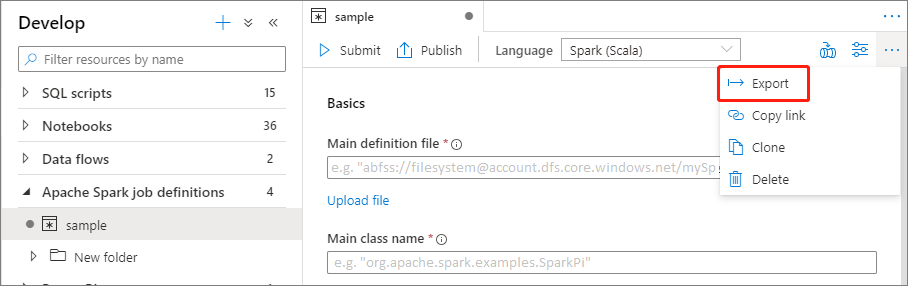
Przesyłanie definicji zadania platformy Apache Spark jako zadania wsadowego
Po utworzeniu definicji zadania platformy Apache Spark możesz przesłać ją do puli platformy Apache Spark. Upewnij się, że jesteś współautorem danych obiektu blob usługi Storage w systemie plików usługi ADLS Gen2, z którym chcesz pracować. Jeśli tak nie jest, musisz ręcznie dodać uprawnienie.
Scenariusz 1. Przesyłanie definicji zadania platformy Apache Spark
Otwórz okno definicji zadania platformy Apache Spark, wybierając je.
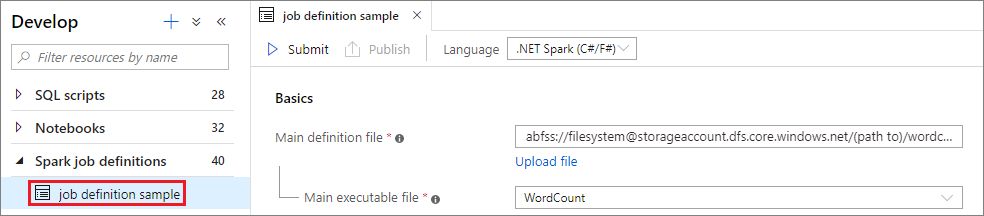
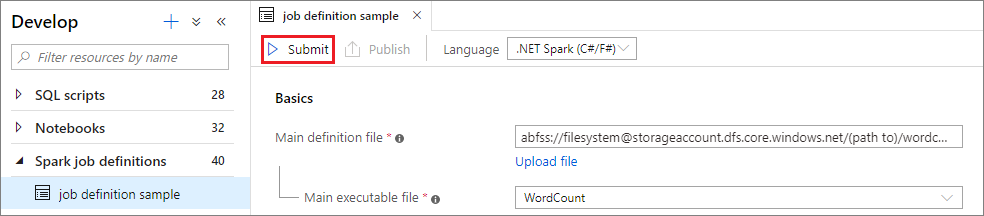
Wybierz przycisk Prześlij , aby przesłać projekt do wybranej puli platformy Apache Spark. Możesz wybrać kartę Adres URL monitorowania platformy Spark, aby wyświetlić pozycję LogQuery aplikacji Apache Spark.
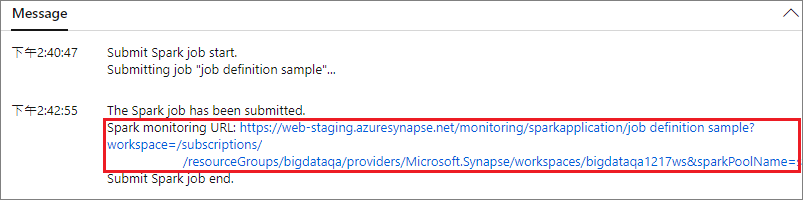
Scenariusz 2. Wyświetlanie postępu uruchamiania zadania platformy Apache Spark
Wybierz pozycję Monitoruj, a następnie wybierz opcję Aplikacje platformy Apache Spark. Przesłaną aplikację Platformy Apache Spark można znaleźć.
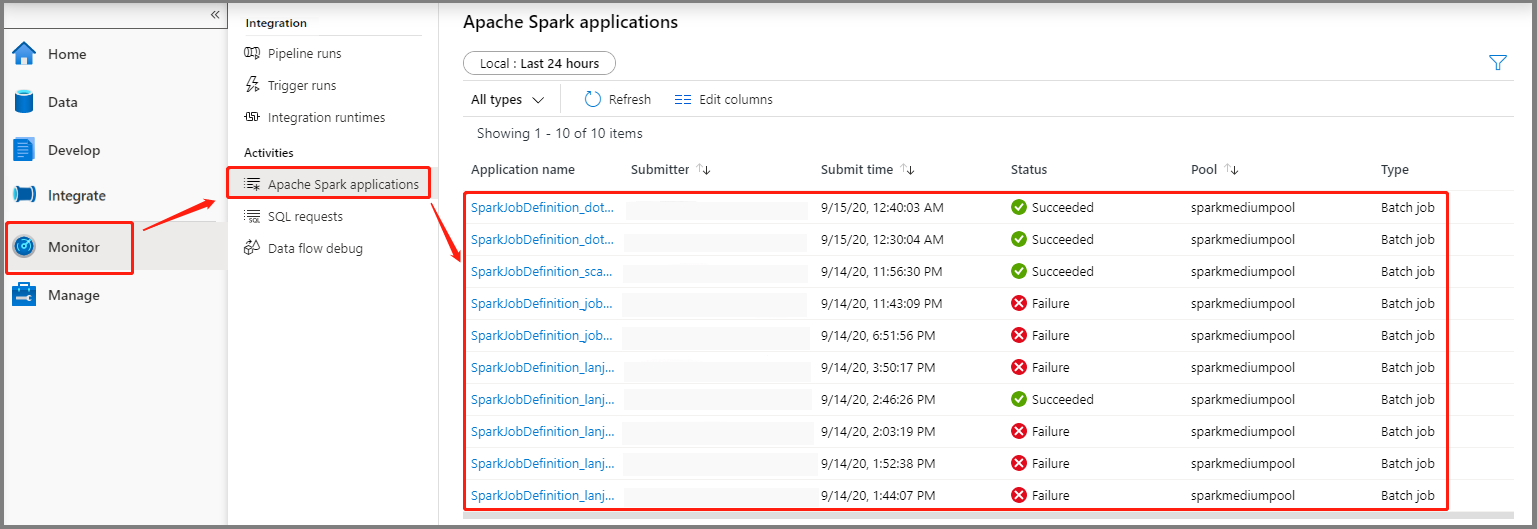
Następnie wybierz aplikację Platformy Apache Spark, zostanie wyświetlone okno zadania SparkJobDefinition . Postęp wykonywania zadania można wyświetlić tutaj.
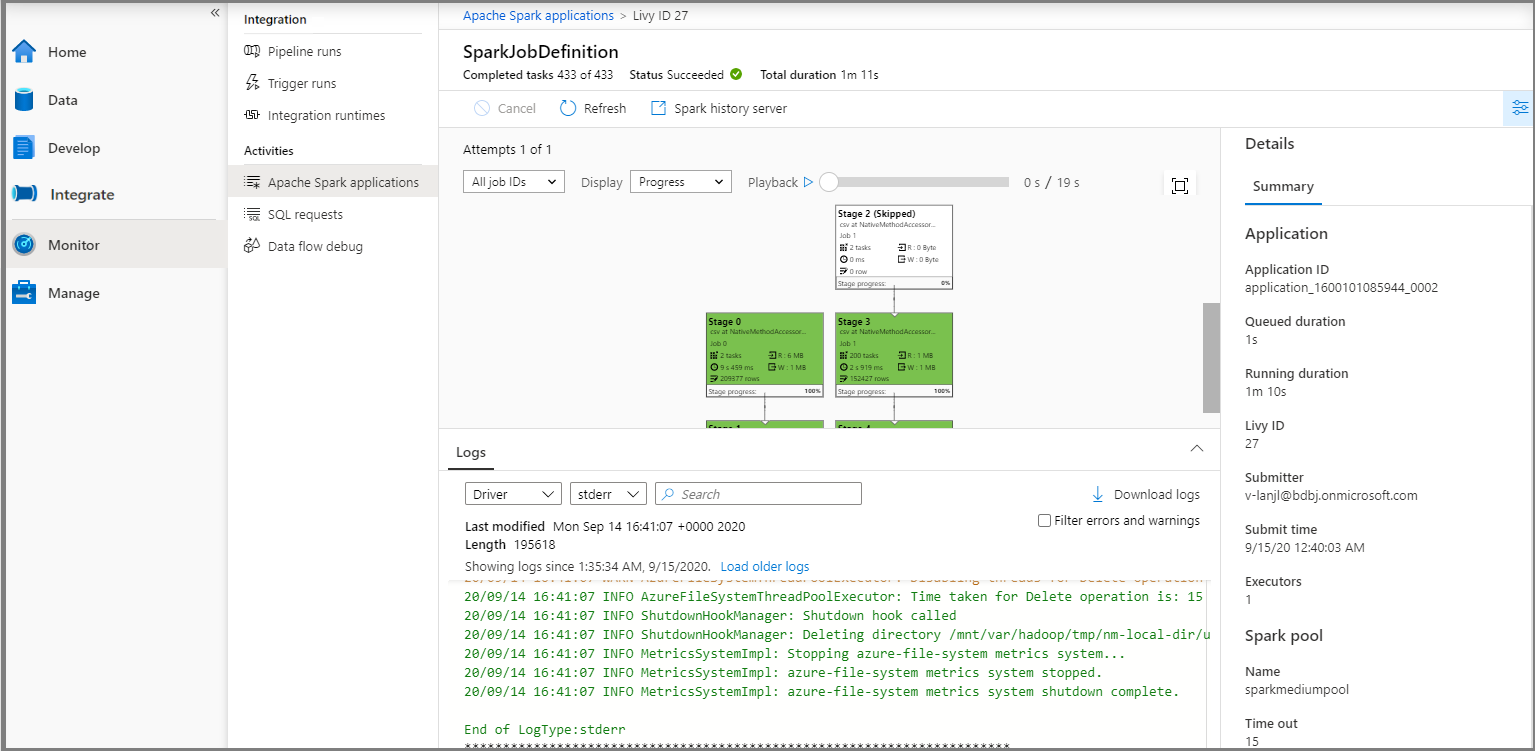
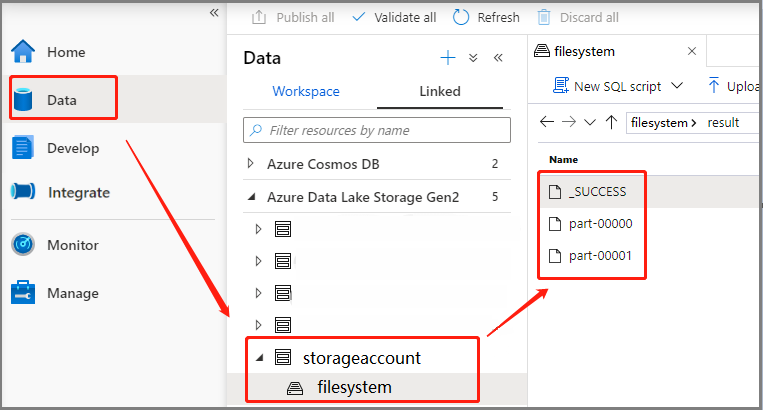
Scenariusz 3. Sprawdzanie pliku wyjściowego
Wybierz pozycję Dane ->Linked ->Azure Data Lake Storage Gen2 (hozhaobdbj), otwórz utworzony wcześniej folder wyników , możesz przejść do folderu wyników i sprawdzić, czy dane wyjściowe są generowane.
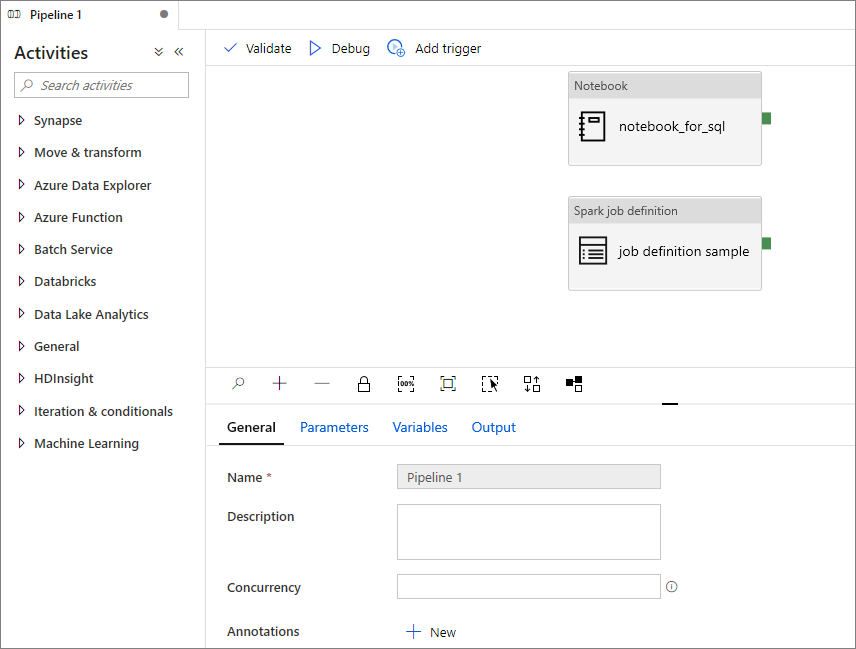
Dodawanie definicji zadania platformy Apache Spark do potoku
W tej sekcji do potoku dodasz definicję zadania platformy Apache Spark.
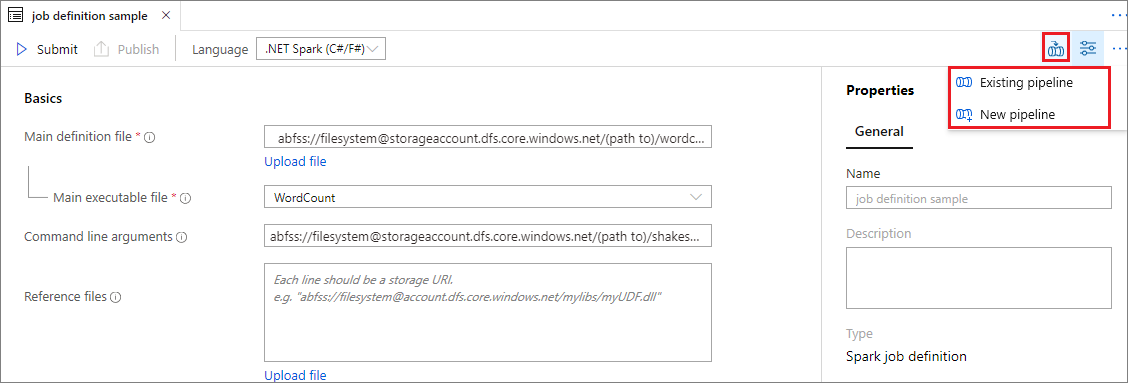
Otwórz istniejącą definicję zadania platformy Apache Spark.
Wybierz ikonę w prawym górnym rogu definicji zadania platformy Apache Spark, wybierz pozycję Istniejący potok lub Nowy potok. Więcej informacji można znaleźć na stronie Potok.
Następne kroki
Następnie możesz użyć usługi Azure Synapse Studio do tworzenia zestawów danych usługi Power BI i zarządzania danymi usługi Power BI. Przejdź do artykułu Łączenie obszaru roboczego usługi Power BI z obszarem roboczym usługi Synapse, aby dowiedzieć się więcej.
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla