Zarządzanie pakietami o zakresie sesji
Oprócz pakietów na poziomie puli można również określić biblioteki o zakresie sesji na początku sesji notesu. Biblioteki o zakresie sesji umożliwiają określanie i używanie pakietów python, jar i R w ramach sesji notesu.
Podczas korzystania z bibliotek o zakresie sesji należy pamiętać o następujących kwestiach:
- Podczas instalowania bibliotek o zakresie sesji tylko bieżący notes ma dostęp do określonych bibliotek.
- Te biblioteki nie mają wpływu na inne sesje ani zadania korzystające z tej samej puli platformy Spark.
- Te biblioteki są instalowane na podstawie podstawowych bibliotek środowiska uruchomieniowego i bibliotek na poziomie puli oraz mają najwyższy priorytet.
- Biblioteki o zakresie sesji nie są utrwalane między sesjami.
Pakiety języka Python o zakresie sesji
Zarządzanie pakietami języka Python o zakresie sesji za pomocą pliku environment.yml
Aby określić pakiety języka Python o zakresie sesji:
- Przejdź do wybranej puli platformy Spark i upewnij się, że włączono biblioteki na poziomie sesji. To ustawienie można włączyć, przechodząc do karty Zarządzanie pakietami> puli >platformy Apache Spark.

- Po wprowadzeniu tego ustawienia można otworzyć notes i wybrać pozycję Konfiguruj pakiety sesji>.

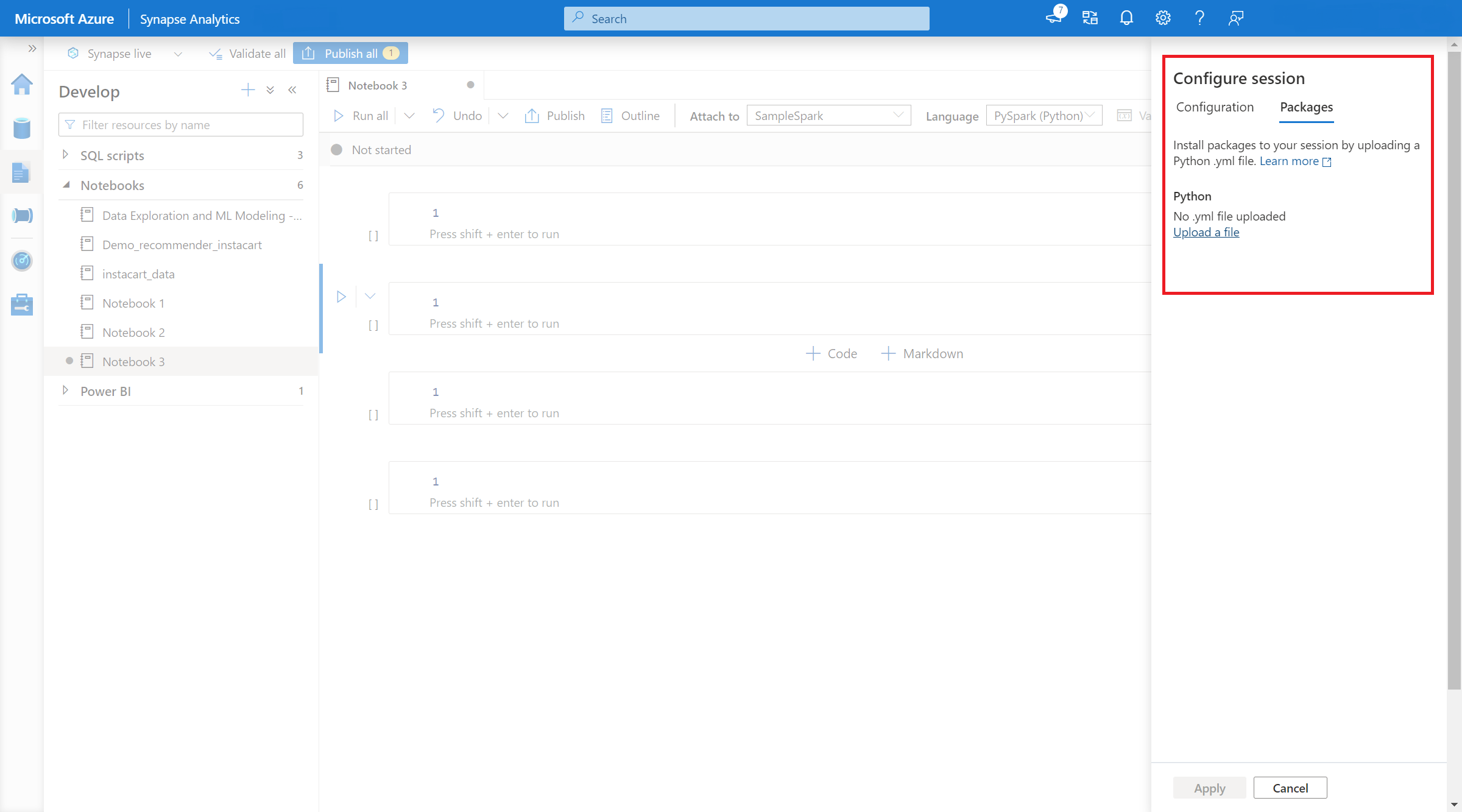
- W tym miejscu możesz przekazać plik Conda environment.yml , aby zainstalować lub uaktualnić pakiety w ramach sesji. Określone biblioteki są obecne po rozpoczęciu sesji. Te biblioteki nie będą już dostępne po zakończeniu sesji.

Zarządzanie pakietami języka Python o zakresie sesji za pomocą poleceń %pip i %conda
Możesz użyć popularnych poleceń %pip i %conda , aby zainstalować dodatkowe biblioteki innych firm lub biblioteki niestandardowe podczas sesji notesu platformy Apache Spark. W tej sekcji użyjemy poleceń %pip , aby zademonstrować kilka typowych scenariuszy.
Uwaga
- Zalecamy umieszczenie poleceń %pip i %conda w pierwszej komórce notesu, jeśli chcesz zainstalować nowe biblioteki. Interpreter języka Python zostanie uruchomiony ponownie po rozpoczęciu zarządzania biblioteką na poziomie sesji w celu wprowadzenia zmian.
- Te polecenia zarządzania bibliotekami języka Python zostaną wyłączone podczas uruchamiania zadań potoku. Jeśli chcesz zainstalować pakiet w potoku, musisz wykorzystać możliwości zarządzania bibliotekami na poziomie puli.
- Biblioteki języka Python o zakresie sesji są automatycznie instalowane zarówno w węzłach sterownika, jak i procesu roboczego.
- Następujące polecenia %conda nie są obsługiwane: tworzenie, czyszczenie, porównywanie, aktywowanie, dezaktywowanie, uruchamianie, pakowanie.
- Aby uzyskać pełną listę poleceń, możesz zapoznać się z poleceniami %pip i poleceniami %conda .
Instalowanie pakietu innej firmy
Bibliotekę języka Python można łatwo zainstalować z poziomu interfejsu PyPI.
# Install vega_datasets
%pip install altair vega_datasets
Aby sprawdzić wynik instalacji, możesz uruchomić następujący kod, aby zwizualizować vega_datasets
# Create a scatter plot
# Plot Miles per gallon against the horsepower across different region
import altair as alt
from vega_datasets import data
cars = data.cars()
alt.Chart(cars).mark_point().encode(
x='Horsepower',
y='Miles_per_Gallon',
color='Origin',
).interactive()
Instalowanie pakietu wheel z konta magazynu
Aby zainstalować bibliotekę z magazynu, należy zainstalować ją na koncie magazynu, uruchamiając następujące polecenia.
from notebookutils import mssparkutils
mssparkutils.fs.mount(
"abfss://<<file system>>@<<storage account>.dfs.core.windows.net",
"/<<path to wheel file>>",
{"linkedService":"<<storage name>>"}
)
Następnie możesz użyć polecenia %pip install , aby zainstalować wymagany pakiet wheel
%pip install /<<path to wheel file>>/<<wheel package name>>.whl
Instalowanie innej wersji wbudowanej biblioteki
Możesz użyć następującego polecenia, aby zobaczyć, jaka jest wbudowana wersja określonego pakietu. Jako przykład używamy biblioteki pandas
%pip show pandas
Wynikiem jest następujący dziennik:
Name: pandas
Version: **1.2.3**
Summary: Powerful data structures for data analysis, time series, and statistics
Home-page: https://pandas.pydata.org
... ...
Aby przełączyć bibliotekę pandas na inną wersję, możesz użyć następującego polecenia: 1.2.4
%pip install pandas==1.2.4
Odinstalowywanie biblioteki o zakresie sesji
Jeśli chcesz odinstalować pakiet zainstalowany w tej sesji notesu, możesz zapoznać się z następującymi poleceniami. Nie można jednak odinstalować wbudowanych pakietów.
%pip uninstall altair vega_datasets --yes
Instalowanie bibliotek z plikurequirement.txt za pomocą polecenia %pip
%pip install -r /<<path to requirement file>>/requirements.txt
Pakiety Java lub Scala o zakresie sesji
Aby określić pakiety Java lub Scala o zakresie sesji, możesz użyć %%configure opcji:
%%configure -f
{
"conf": {
"spark.jars": "abfss://<<file system>>@<<storage account>.dfs.core.windows.net/<<path to JAR file>>",
}
}
Uwaga
- Zalecamy uruchomienie narzędzia %%configure na początku notesu. Aby uzyskać pełną listę prawidłowych parametrów, możesz zapoznać się z tym dokumentem .
Pakiety języka R o zakresie sesji (wersja zapoznawcza)
Azure Synapse Pule analizy obejmują wiele popularnych bibliotek języka R. Możesz również zainstalować dodatkowe biblioteki innych firm podczas sesji notesu platformy Apache Spark.
Uwaga
- Te polecenia zarządzania bibliotekami języka R zostaną wyłączone podczas uruchamiania zadań potoku. Jeśli chcesz zainstalować pakiet w potoku, musisz wykorzystać możliwości zarządzania bibliotekami na poziomie puli.
- Biblioteki języka R o zakresie sesji są automatycznie instalowane w węzłach sterownika i procesu roboczego.
Instalowanie pakietu
Bibliotekę języka R można łatwo zainstalować z poziomu usługi CRAN.
# Install a package from CRAN
install.packages(c("nycflights13", "Lahman"))
Możesz również użyć migawek CRAN jako repozytorium, aby upewnić się, że pobiera tę samą wersję pakietu za każdym razem.
install.packages("highcharter", repos = "https://cran.microsoft.com/snapshot/2021-07-16/")
Instalowanie pakietów przy użyciu narzędzia devtools
Biblioteka devtools upraszcza opracowywanie pakietów w celu przyspieszenia typowych zadań. Ta biblioteka jest instalowana w domyślnym środowisku uruchomieniowym usługi Azure Synapse Analytics.
Można użyć devtools polecenia , aby określić określoną wersję biblioteki do zainstalowania. Te biblioteki zostaną zainstalowane we wszystkich węzłach w klastrze.
# Install a specific version.
install_version("caesar", version = "1.0.0")
Podobnie możesz zainstalować bibliotekę bezpośrednio z usługi GitHub.
# Install a GitHub library.
install_github("jtilly/matchingR")
Obecnie w usłudze Azure Synapse Analytics są obsługiwane następujące devtools funkcje:
| Polecenie | Opis |
|---|---|
| install_github() | Instaluje pakiet języka R z usługi GitHub |
| install_gitlab() | Instaluje pakiet języka R z narzędzia GitLab |
| install_bitbucket() | Instaluje pakiet języka R z usługi BitBucket |
| install_url() | Instaluje pakiet języka R z dowolnego adresu URL |
| install_git() | Instaluje z dowolnego repozytorium Git |
| install_local() | Instaluje z pliku lokalnego na dysku |
| install_version() | Instaluje z określonej wersji w usłudze CRAN |
Wyświetlanie zainstalowanych bibliotek
Zapytania dotyczące wszystkich bibliotek zainstalowanych w sesji można wykonać za pomocą library polecenia .
library()
Możesz użyć packageVersion funkcji , aby sprawdzić wersję biblioteki:
packageVersion("caesar")
Usuwanie pakietu języka R z sesji
Możesz użyć detach funkcji , aby usunąć bibliotekę z przestrzeni nazw. Te biblioteki pozostają na dysku, dopóki nie zostaną ponownie załadowane.
# detach a library
detach("package: caesar")
Aby usunąć pakiet o zakresie sesji z notesu remove.packages() , użyj polecenia . Ta zmiana biblioteki nie ma wpływu na inne sesje w tym samym klastrze. Użytkownicy nie mogą odinstalować ani usunąć wbudowanych bibliotek domyślnego środowiska uruchomieniowego usługi Azure Synapse Analytics.
remove.packages("caesar")
Uwaga
Nie można usuwać podstawowych pakietów, takich jak SparkR, SparklyR lub R.
Biblioteki języka R o zakresie sesji i sparkR
Biblioteki o zakresie notesu są dostępne dla procesów roboczych platformy SparkR.
install.packages("stringr")
library(SparkR)
str_length_function <- function(x) {
library(stringr)
str_length(x)
}
docs <- c("Wow, I really like the new light sabers!",
"That book was excellent.",
"R is a fantastic language.",
"The service in this restaurant was miserable.",
"This is neither positive or negative.")
spark.lapply(docs, str_length_function)
Biblioteki języka R o zakresie sesji i interfejs SparklyR
Za pomocą spark_apply() w interfejsie SparklyR można użyć dowolnego pakietu języka R wewnątrz platformy Spark. Domyślnie w funkcji sparklyr::spark_apply() argument packages ustawia wartość FALSE. Spowoduje to skopiowanie bibliotek w bieżącej bibliotece libPaths do procesów roboczych, co umożliwia importowanie i używanie ich w ramach procesów roboczych. Możesz na przykład uruchomić następujące polecenie, aby wygenerować wiadomość zaszyfrowaną za pomocą narzędzia sparklyr::spark_apply():
install.packages("caesar", repos = "https://cran.microsoft.com/snapshot/2021-07-16/")
spark_version <- "3.2"
config <- spark_config()
sc <- spark_connect(master = "yarn", version = spark_version, spark_home = "/opt/spark", config = config)
apply_cases <- function(x) {
library(caesar)
caesar("hello world")
}
sdf_len(sc, 5) %>%
spark_apply(apply_cases, packages=FALSE)
Następne kroki
- Wyświetlanie bibliotek domyślnych: obsługa wersji platformy Apache Spark
- Zarządzanie pakietami poza portalem Synapse Studio: zarządzanie pakietami za pomocą poleceń Az i interfejsów API REST