Zbieranie dzienników i metryk aplikacji platformy Apache Spark przy użyciu konta usługi Azure Storage
Rozszerzenie emitera diagnostycznego usługi Synapse Apache Spark to biblioteka umożliwiająca aplikacji Apache Spark emitowanie dzienników, dzienników zdarzeń i metryk do co najmniej jednego miejsca docelowego, w tym usługi Azure Log Analytics, Azure Storage i Azure Event Hubs.
Z tego samouczka dowiesz się, jak używać rozszerzenia emitera diagnostycznego usługi Synapse Apache Spark do emitowania dzienników, dzienników zdarzeń i metryk aplikacji platformy Apache Spark do konta usługi Azure Storage.
Zbieranie dzienników i metryk na koncie magazynu
Krok 1. Tworzenie konta magazynu
Aby zebrać dzienniki diagnostyczne i metryki na koncie magazynu, możesz użyć istniejących kont usługi Azure Storage. Jeśli go nie masz, możesz utworzyć konto usługi Azure Blob Storage lub utworzyć konto magazynu do użycia z usługą Azure Data Lake Storage Gen2.
Krok 2. Tworzenie pliku konfiguracji platformy Apache Spark
Utwórz element i skopiuj następującą diagnostic-emitter-azure-storage-conf.txt zawartość do pliku. Możesz też pobrać przykładowy plik szablonu dla konfiguracji puli platformy Apache Spark.
spark.synapse.diagnostic.emitters MyDestination1
spark.synapse.diagnostic.emitter.MyDestination1.type AzureStorage
spark.synapse.diagnostic.emitter.MyDestination1.categories Log,EventLog,Metrics
spark.synapse.diagnostic.emitter.MyDestination1.uri https://<my-blob-storage>.blob.core.windows.net/<container-name>/<folder-name>
spark.synapse.diagnostic.emitter.MyDestination1.auth AccessKey
spark.synapse.diagnostic.emitter.MyDestination1.secret <storage-access-key>
Wypełnij następujące parametry w pliku konfiguracji: <my-blob-storage>, <container-name>, <folder-name>, <storage-access-key>.
Aby uzyskać więcej informacji na temat parametrów, zobacz Konfiguracje usługi Azure Storage
Krok 3. Przekazywanie pliku konfiguracji platformy Apache Spark do programu Synapse Studio i używanie go w puli Spark
- Otwórz stronę Konfiguracji platformy Apache Spark (Zarządzaj —> konfiguracje platformy Apache Spark).
- Kliknij przycisk Importuj, aby przekazać plik konfiguracji platformy Apache Spark do programu Synapse Studio.
- Przejdź do puli platformy Apache Spark w programie Synapse Studio (Zarządzanie —> pule platformy Apache Spark).
- Kliknij przycisk "..." po prawej stronie puli platformy Apache Spark i wybierz pozycję Konfiguracja platformy Apache Spark.
- Możesz wybrać właśnie przekazany plik konfiguracji w menu rozwijanym.
- Kliknij przycisk Zastosuj po wybraniu pliku konfiguracji.
Krok 4. Wyświetlanie plików dzienników na koncie usługi Azure Storage
Po przesłaniu zadania do skonfigurowanej puli platformy Apache Spark powinno być możliwe wyświetlenie dzienników i plików metryk na docelowym koncie magazynu.
Dzienniki zostaną umieszczone w odpowiednich ścieżkach zgodnie z różnymi aplikacjami według .<workspaceName>.<sparkPoolName>.<livySessionId>
Wszystkie pliki dzienników będą w formacie wierszy JSON (nazywanym również plikiem JSON rozdzielanym wierszami JSON, ndjson), który jest wygodny w przetwarzaniu danych.
Dostępne konfiguracje
| Konfigurowanie | opis |
|---|---|
spark.synapse.diagnostic.emitters |
Wymagane. Rozdzielane przecinkami nazwy docelowe emiterów diagnostycznych. Na przykład MyDest1,MyDest2 |
spark.synapse.diagnostic.emitter.<destination>.type |
Wymagany. Wbudowany typ miejsca docelowego. Aby włączyć miejsce docelowe usługi Azure Storage, AzureStorage należy uwzględnić je w tym polu. |
spark.synapse.diagnostic.emitter.<destination>.categories |
Opcjonalny. Rozdzielone przecinkami kategorie dzienników. Dostępne wartości obejmują DriverLog, , EventLogExecutorLog, Metrics. Jeśli nie zostanie ustawiona, wartość domyślna to wszystkie kategorie. |
spark.synapse.diagnostic.emitter.<destination>.auth |
Wymagany. AccessKeydo korzystania z autoryzacji klucza dostępu do konta magazynu. SAS w przypadku autoryzacji sygnatur dostępu współdzielonego. |
spark.synapse.diagnostic.emitter.<destination>.uri |
Wymagany. Identyfikator URI docelowego folderu kontenera obiektów blob. Powinien być zgodny ze wzorcem https://<my-blob-storage>.blob.core.windows.net/<container-name>/<folder-name>. |
spark.synapse.diagnostic.emitter.<destination>.secret |
Opcjonalny. Zawartość wpisu tajnego (AccessKey lub SAS). |
spark.synapse.diagnostic.emitter.<destination>.secret.keyVault |
Wymagane, jeśli .secret nie zostanie określony. Nazwa magazynu kluczy platformy Azure, w którym jest przechowywany wpis tajny (AccessKey lub SAS). |
spark.synapse.diagnostic.emitter.<destination>.secret.keyVault.secretName |
Wymagane, jeśli .secret.keyVault jest określony. Nazwa wpisu tajnego usługi Azure Key Vault, w której jest przechowywany klucz tajny (AccessKey lub SAS). |
spark.synapse.diagnostic.emitter.<destination>.secret.keyVault.linkedService |
Opcjonalny. Połączona nazwa usługi Azure Key Vault. Po włączeniu w potoku usługi Synapse jest to konieczne do uzyskania wpisu tajnego z usługi AKV. (Upewnij się, że tożsamość usługi zarządzanej ma uprawnienia do odczytu w usłudze AKV). |
spark.synapse.diagnostic.emitter.<destination>.filter.eventName.match |
Opcjonalny. Rozdzielane przecinkami nazwy zdarzeń platformy Spark można określić, które zdarzenia mają być zbierane. Na przykład: SparkListenerApplicationStart,SparkListenerApplicationEnd. |
spark.synapse.diagnostic.emitter.<destination>.filter.loggerName.match |
Opcjonalny. Nazwy rejestratora log4j rozdzielane przecinkami można określić, które dzienniki mają być zbierane. Na przykład: org.apache.spark.SparkContext,org.example.Logger. |
spark.synapse.diagnostic.emitter.<destination>.filter.metricName.match |
Opcjonalny. Sufiksy nazw metryk platformy Spark rozdzielone przecinkami umożliwiają określenie metryk do zebrania. Na przykład: jvm.heap.used. |
Przykład danych dziennika
Oto przykładowy rekord dziennika w formacie JSON:
{
"timestamp": "2021-01-02T12:34:56.789Z",
"category": "Log|EventLog|Metrics",
"workspaceName": "<my-workspace-name>",
"sparkPool": "<spark-pool-name>",
"livyId": "<livy-session-id>",
"applicationId": "<application-id>",
"applicationName": "<application-name>",
"executorId": "<driver-or-executor-id>",
"properties": {
// The message properties of logs, events and metrics.
"timestamp": "2021-01-02T12:34:56.789Z",
"message": "Registering signal handler for TERM",
"logger_name": "org.apache.spark.util.SignalUtils",
"level": "INFO",
"thread_name": "main"
// ...
}
}
Obszar roboczy usługi Synapse z włączoną ochroną przed eksfiltracją danych
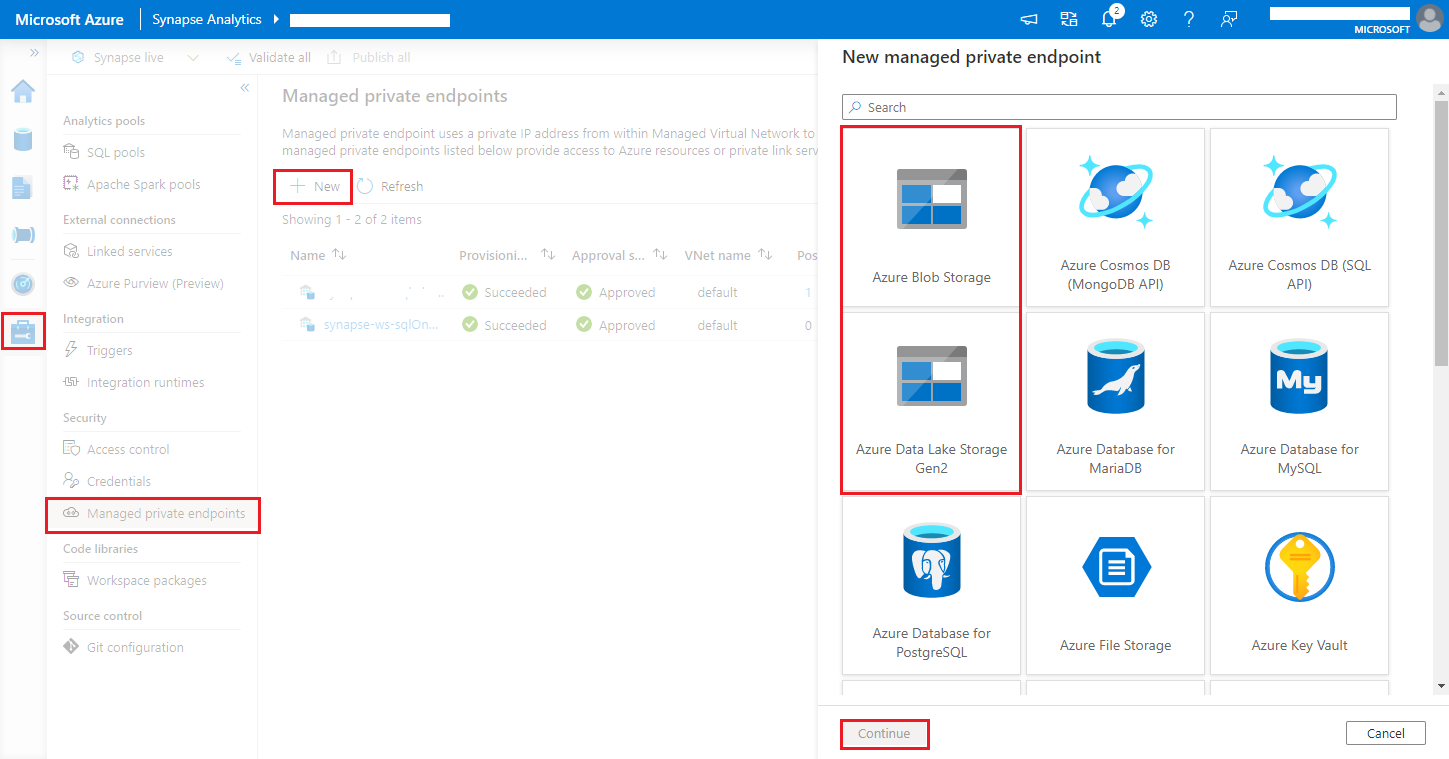
Obszary robocze usługi Azure Synapse Analytics obsługują włączanie ochrony przed eksfiltracją danych dla obszarów roboczych. W przypadku ochrony przed eksfiltracją dzienniki i metryki nie mogą być wysyłane bezpośrednio do docelowych punktów końcowych. W tym scenariuszu można utworzyć odpowiednie zarządzane prywatne punkty końcowe dla różnych docelowych punktów końcowych lub utworzyć reguły zapory adresów IP.
Przejdź do obszaru Zarządzanie zarządzanymi > prywatnymi punktami końcowymi usługi Synapse Studio>, kliknij przycisk Nowy, wybierz pozycję Azure Blob Storage lub Azure Data Lake Storage Gen2 i kontynuuj.
Uwaga
Możemy obsługiwać zarówno usługę Azure Blob Storage, jak i usługę Azure Data Lake Storage Gen2. Nie można jednak przeanalizować formatu abfss:// . Punkty końcowe usługi Azure Data Lake Storage Gen2 powinny być sformatowane jako adres URL obiektu blob:
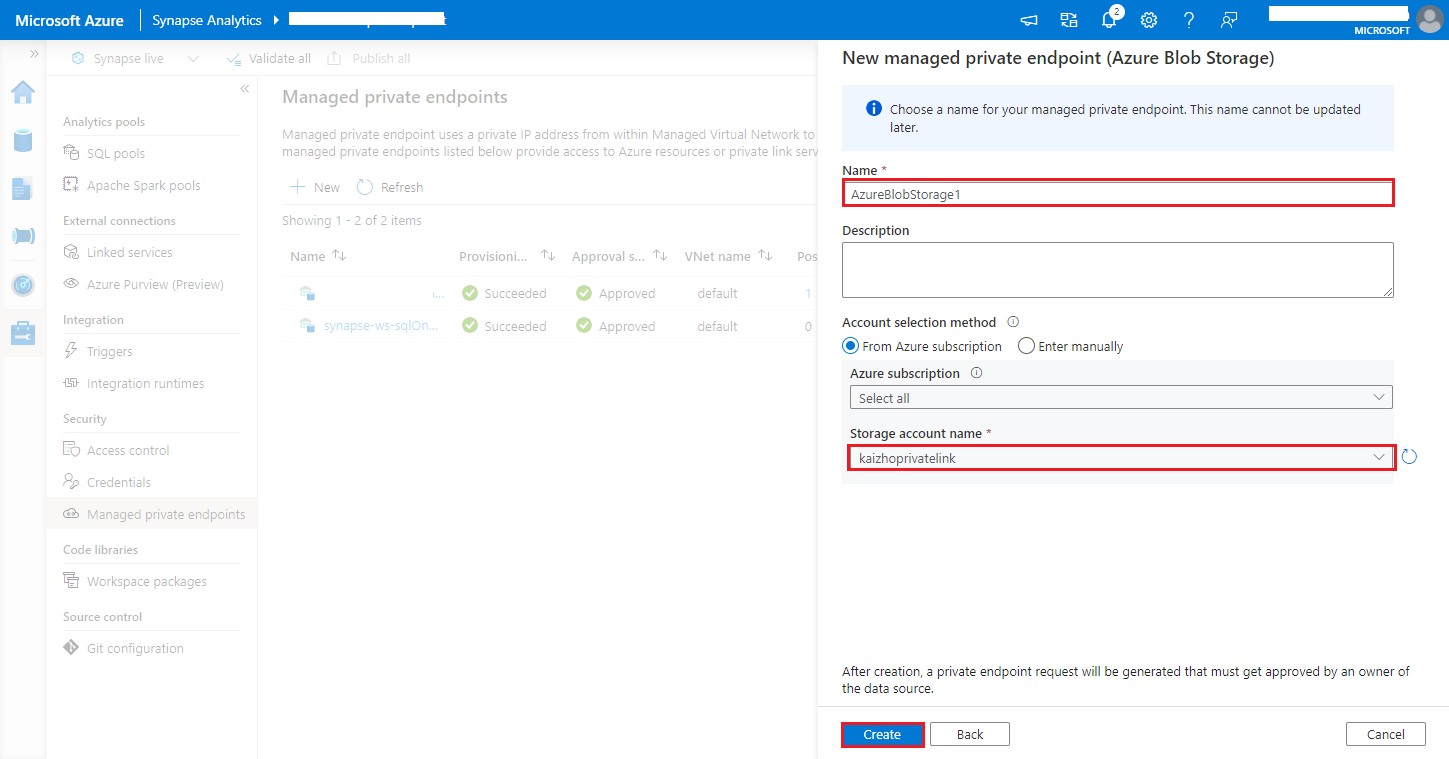
https://<my-blob-storage>.blob.core.windows.net/<container-name>/<folder-name>Wybierz konto usługi Azure Storage w nazwie konta magazynu, a następnie kliknij przycisk Utwórz .
Poczekaj kilka minut na aprowizowanie prywatnego punktu końcowego.
Przejdź do konta magazynu w witrynie Azure Portal na stronie Połączenia prywatnego punktu końcowego sieci>wybierz aprowizowaną połączenie i zatwierdź.