Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Tip
Microsoft Fabric Data Warehouse to magazyn relacyjny w skali przedsiębiorstwa na podstawie bazy danych data lake z architekturą gotową do użycia w przyszłości, wbudowaną sztuczną inteligencją i nowymi funkcjami. Jeśli dopiero zaczynasz korzystać z magazynowania danych, zacznij od Fabric Data Warehouse. Istniejące obciążenia dedykowanej puli SQL mogą zostać zaktualizowane do Fabric, aby uzyskać dostęp do nowych możliwości w zakresie nauki o danych, analizy w czasie rzeczywistym i raportowania.
W tym artykule wyjaśniono, jak oszacować koszty bezserwerowej puli SQL i zarządzać nimi w usłudze Azure Synapse Analytics:
- Szacowanie ilości przetwarzanych danych przed wysłaniem zapytania
- Ustawianie budżetu przy użyciu funkcji kontroli kosztów
Dowiedz się, że koszty bezserwerowej puli SQL w usłudze Azure Synapse Analytics są tylko częścią miesięcznych kosztów na rachunku za platformę Azure. Jeśli korzystasz z innych usług platformy Azure, opłaty są naliczane za wszystkie usługi i zasoby platformy Azure używane w ramach subskrypcji platformy Azure, w tym usługi innych firm. W tym artykule wyjaśniono, jak planować koszty bezserwerowej puli SQL i zarządzać nimi w usłudze Azure Synapse Analytics.
Przetworzone dane
Przetwarzane dane to ilość danych, które system tymczasowo przechowuje podczas uruchamiania zapytania. Przetworzone dane składają się z następujących ilości:
- Ilość danych odczytanych z pamięci masowej. Ta kwota obejmuje:
- Dane odczytywane podczas odczytywania danych.
- Dane odczytywane podczas odczytywania metadanych (w przypadku formatów plików zawierających metadane, takie jak Parquet).
- Ilość danych w wynikach pośrednich. Te dane są przesyłane między węzłami podczas wykonywania zapytania. Zawiera on transfer danych do punktu końcowego w formacie nieskompresowanym.
- Ilość danych zapisanych na nośniku. Jeśli używasz instrukcji CETAS do eksportowania zestawu wyników do magazynu, ilość zapisanych danych jest dodawana do ilości danych przetwarzanych dla części SELECT CETAS.
Odczytywanie plików z magazynu jest wysoce zoptymalizowane. W procesie są używane następujące opisano:
- Pobieranie wstępne, co może spowodować dodanie pewnego obciążenia do ilości odczytanych danych. Jeśli zapytanie odczytuje cały plik, nie ma obciążenia. Jeśli plik jest odczytywany częściowo, podobnie jak w zapytaniach TOP N, nieco więcej danych jest odczytywanych przy użyciu pobierania wstępnego.
- Zoptymalizowany analizator wartości rozdzielanych przecinkami (CSV). Jeśli używasz PARSER_VERSION='2.0' do odczytywania plików CSV, ilość danych odczytanych z magazynu nieznacznie wzrasta. Zoptymalizowany analizator CSV odczytuje pliki równolegle w fragmentach o równym rozmiarze. Fragmenty nie muszą zawierać całych wierszy. Aby upewnić się, że wszystkie wiersze są analizowane, zoptymalizowany analizator CSV odczytuje również małe fragmenty sąsiednich fragmentów. Ten proces dodaje niewielką ilość obciążeń.
Statystyka
Optymalizator zapytań bezserwerowej puli SQL opiera się na statystykach w celu generowania optymalnych planów wykonywania zapytań. Statystyki można tworzyć ręcznie. W przeciwnym razie bezserwerowa pula SQL tworzy je automatycznie. Tak czy inaczej, statystyki są tworzone przez uruchomienie oddzielnego zapytania, które zwraca określoną kolumnę z podaną częstotliwością próbkowania. To zapytanie ma związaną z tym ilość przetworzonych danych.
Jeśli uruchomisz to samo lub inne zapytanie, które skorzystałoby z utworzonych statystyk, statystyki będą ponownie używane, jeśli to możliwe. Nie ma żadnych dodatkowych danych przetwarzanych na potrzeby tworzenia statystyk.
Podczas tworzenia statystyk dla kolumny Parquet tylko odpowiednia kolumna jest odczytywana z plików. Po utworzeniu statystyk dla kolumny CSV całe pliki są odczytywane i analizowane.
Zaokrąglanie
Ilość przetwarzanych danych jest zaokrąglona do najbliższej MB na zapytanie. Każde zapytanie ma co najmniej 10 MB przetworzonych danych.
Czego nie obejmują przetwarzane dane
- Metadane na poziomie serwera (takie jak identyfikatory logowania, role i poświadczenia na poziomie serwera).
- Bazy danych tworzone w punkcie końcowym. Te bazy danych zawierają tylko metadane (takie jak użytkownicy, role, schematy, widoki, wbudowane funkcje tabel [TVFs], procedury składowane, poświadczenia w zakresie bazy danych, zewnętrzne źródła danych, zewnętrzne formaty plików i tabele zewnętrzne).
- Jeśli używasz wnioskowania schematu, fragmenty plików są odczytywane w celu wnioskowania nazw kolumn i typów danych, a ilość odczytanych danych jest dodawana do ilości przetwarzanych danych.
- Instrukcje języka definicji danych (DDL), z wyjątkiem instrukcji CREATE STATISTICS, ponieważ przetwarzają dane z magazynu na podstawie określonej wartości procentowej próbki.
- Zapytania tylko do metadanych.
Zmniejszenie ilości przetwarzanych danych
Możesz zoptymalizować ilość przetwarzanych danych na zapytanie i zwiększyć wydajność, partycjonując i konwertując dane na skompresowany format oparty na kolumnie, taki jak Parquet.
Przykłady
Wyobraź sobie trzy tabele.
- Tabela population_csv jest wspierana przez 5 TB plików CSV. Pliki są uporządkowane w pięciu kolumnach o równych rozmiarach.
- Tabela population_parquet zawiera te same dane co tabela population_csv. Jest on wspierany przez 1 TB plików Parquet. Ta tabela jest mniejsza niż poprzednia, ponieważ dane są kompresowane w formacie Parquet.
- Tabela very_small_csv jest wspierana przez 100 KB plików CSV.
Zapytanie 1: SELECT SUM(population) FROM population_csv
To zapytanie odczytuje i analizuje całe pliki, aby uzyskać wartości dla kolumny populacji. Węzły przetwarzają fragmenty tej tabeli, a suma populacji dla każdego fragmentu jest przenoszona między węzłami. Końcowa suma zostanie przekazana do Twojego punktu końcowego.
To zapytanie przetwarza 5 TB danych oraz niewielkie obciążenie związane z transferem sum fragmentów.
Zapytanie 2: SELECT SUM(population) FROM population_parquet
Podczas wykonywania zapytań dotyczących formatów skompresowanych i opartych na kolumnach, takich jak Parquet, mniej danych jest odczytywanych niż w zapytaniu 1. Ten wynik jest widoczny, ponieważ bezserwerowa pula SQL odczytuje jedną skompresowaną kolumnę zamiast całego pliku. W tym przypadku odczytane jest 0,2 TB. (Pięć kolumn o równych rozmiarach to 0,2 TB. Węzły przetwarzają fragmenty tej tabeli, a suma populacji dla każdego fragmentu jest przenoszona między węzłami. Końcowa suma zostanie przekazana do Twojego punktu końcowego.
To zapytanie przetwarza 0,2 TB plus niewielki narzut na transfer sumy fragmentów.
Zapytanie 3: SELECT * FROM population_parquet
To zapytanie odczytuje wszystkie kolumny i przesyła wszystkie dane w formacie nieskompresowanym. Jeśli format kompresji wynosi 5:1, zapytanie przetwarza 6 TB, ponieważ odczytuje 1 TB i przesyła 5 TB nieskompresowanych danych.
Zapytanie 4: SELECT COUNT(*) FROM very_small_csv
To zapytanie odczytuje całe pliki. Łączny rozmiar plików w magazynie dla tej tabeli wynosi 100 KB. Węzły przetwarzają fragmenty tej tabeli, a suma dla każdego fragmentu jest przenoszona między węzłami. Końcowa suma zostanie przekazana do Twojego punktu końcowego.
To zapytanie przetwarza nieco ponad 100 KB danych. Ilość danych przetwarzanych dla tego zapytania jest zaokrąglona do 10 MB, jak określono w sekcji Zaokrąglanie tego artykułu.
Kontrola kosztów
Funkcja kontroli kosztów w bezserwerowej puli SQL umożliwia ustawienie budżetu na ilość przetwarzanych danych. Budżet można ustawić w TB danych przetwarzanych przez dzień, tydzień i miesiąc. Jednocześnie można ustawić co najmniej jeden budżet. Aby skonfigurować kontrolę kosztów dla bezserwerowej puli SQL, możesz użyć programu Synapse Studio lub języka T-SQL.
Konfigurowanie kontroli kosztów dla bezserwerowej puli SQL w programie Synapse Studio
pl-PL: Aby skonfigurować kontrolę kosztów dla bezserwerowej puli SQL w programie Synapse Studio, przejdź do pozycji Zarządzaj w menu po lewej stronie, następnie wybierz pozycję Pula SQL w sekcji Pule analiz. Przy najechaniu wskaźnikiem myszy na bezserwerową pulę SQL, zauważysz ikonę kontroli kosztów – kliknij na tę ikonę.
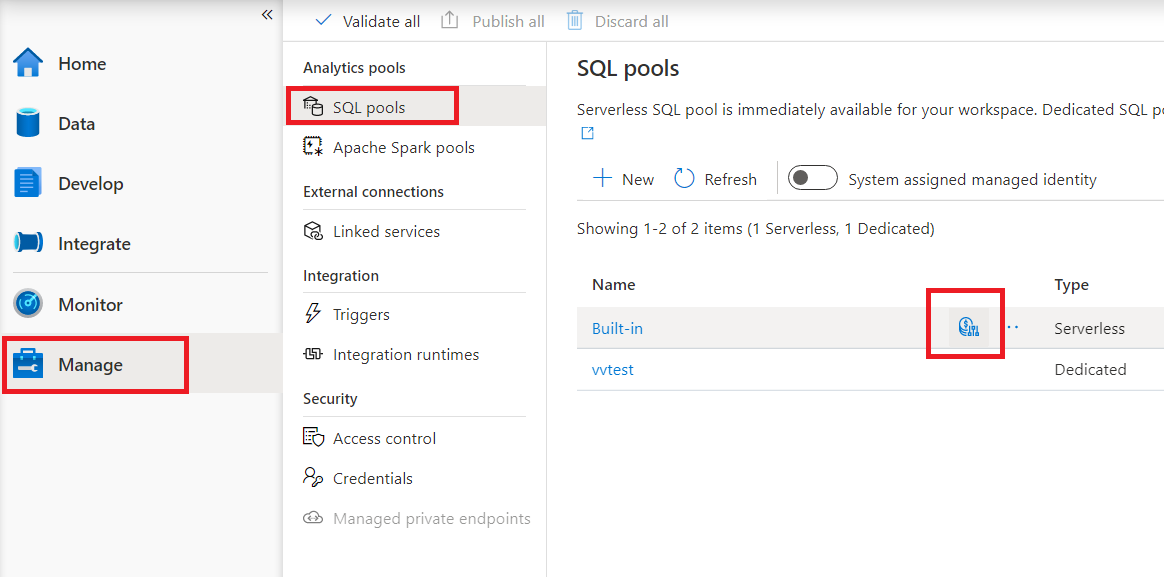
Po kliknięciu ikony kontroli kosztów zostanie wyświetlony pasek boczny:
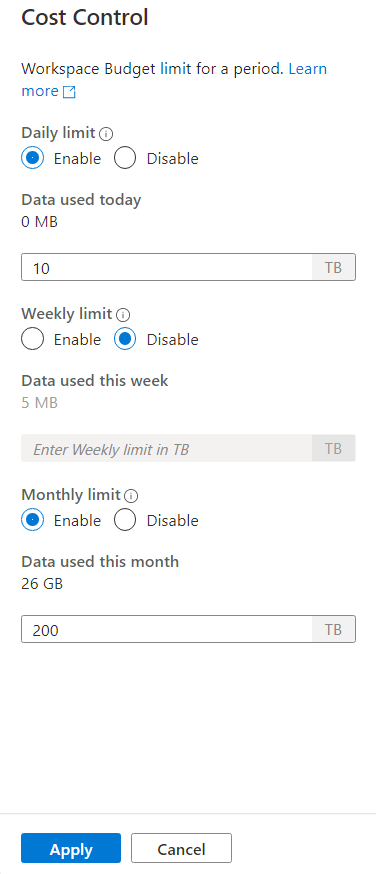
Aby ustawić co najmniej jeden budżet, najpierw kliknij przycisk opcji 'Włącz' dla budżetu, który chcesz ustawić, następnie wprowadź wartość całkowitą w polu tekstowym. Jednostka wartości to TBs. Po skonfigurowaniu budżetów, które chcesz, kliknij przycisk Zastosuj w dolnej części paska bocznego. To wszystko, budżet jest teraz ustalony.
Konfigurowanie kontroli kosztów dla bezserwerowej puli SQL w języku T-SQL
Aby skonfigurować kontrolę kosztów dla bezserwerowej puli SQL w języku T-SQL, należy wykonać co najmniej jedną z poniższych procedur składowanych.
sp_set_data_processed_limit
@type = N'daily',
@limit_tb = 1
sp_set_data_processed_limit
@type= N'weekly',
@limit_tb = 2
sp_set_data_processed_limit
@type= N'monthly',
@limit_tb = 3334
Aby wyświetlić bieżącą konfigurację, wykonaj następującą instrukcję języka T-SQL:
SELECT * FROM sys.configurations
WHERE name like 'Data processed %';
Aby sprawdzić, ile danych zostało przetworzonych w bieżącym dniu, tygodniu lub miesiącu, wykonaj następującą instrukcję języka T-SQL:
SELECT * FROM sys.dm_external_data_processed
Przekraczanie limitów zdefiniowanych w kontrolce kosztów
W przypadku przekroczenia limitu podczas wykonywania zapytania zapytanie nie zostanie zakończone.
Po przekroczeniu limitu nowe zapytanie zostanie odrzucone z komunikatem o błędzie zawierającym szczegóły dotyczące okresu, zdefiniowanego limitu dla tego okresu i danych przetwarzanych w tym okresie. Na przykład w przypadku wykonania nowego zapytania, gdzie cotygodniowy limit jest ustawiony na 1 TB i został przekroczony, komunikat o błędzie będzie następujący:
Query is rejected because SQL Serverless budget limit for a period is exceeded. (Period = Weekly: Limit = 1 TB, Data processed = 1 TB))
Następne kroki
Aby dowiedzieć się, jak zoptymalizować zapytania pod kątem wydajności, zobacz Najlepsze praktyki dotyczące bezserwerowej puli SQL.