Używanie tabel zewnętrznych z usługą Synapse SQL
Tabela zewnętrzna wskazuje dane znajdujące się w usłudze Hadoop, obiekcie blob usługi Azure Storage lub usłudze Azure Data Lake Storage. Tabele zewnętrzne umożliwiają odczytywanie danych z plików lub zapisywanie danych w plikach w usłudze Azure Storage.
Usługa Synapse SQL umożliwia odczytywanie danych zewnętrznych przy użyciu dedykowanej puli SQL lub bezserwerowej puli SQL.
W zależności od typu zewnętrznego źródła danych można użyć dwóch typów tabel zewnętrznych:
- Tabele zewnętrzne usługi Hadoop, których można użyć do odczytywania i eksportowania danych w różnych formatach danych, takich jak CSV, Parquet i ORC. Tabele zewnętrzne usługi Hadoop są dostępne w dedykowanych pulach SQL, ale nie są dostępne w bezserwerowych pulach SQL.
- Natywne tabele zewnętrzne, których można użyć do odczytywania i eksportowania danych w różnych formatach danych, takich jak CSV i Parquet. Natywne tabele zewnętrzne są dostępne w bezserwerowych pulach SQL i są dostępne w publicznej wersji zapoznawczej w dedykowanych pulach SQL. Zapisywanie/eksportowanie danych przy użyciu instrukcji CETAS i natywnych tabel zewnętrznych jest dostępne tylko w bezserwerowej puli SQL, ale nie w dedykowanych pulach SQL.
Najważniejsze różnice między usługą Hadoop i natywnymi tabelami zewnętrznymi:
| Typ tabeli zewnętrznej | Hadoop | Macierzyste |
|---|---|---|
| Dedykowana pula SQL | Dostępny | Tylko tabele Parquet są dostępne w publicznej wersji zapoznawczej. |
| Bezserwerowa pula SQL | Niedostępny | Dostępna |
| Obsługiwane formaty | Rozdzielane/CSV, Parquet, ORC, Hive RC i RC | Bezserwerowa pula SQL: rozdzielane/CSV, Parquet i Delta Lake Dedykowana pula SQL: Parquet (wersja zapoznawcza) |
| Eliminacja partycji folderu | Nie. | Eliminacja partycji jest dostępna tylko w tabelach partycjonowanych utworzonych w formatach Parquet lub CSV synchronizowanych z pul platformy Apache Spark. Tabele zewnętrzne można tworzyć w folderach podzielonych na partycje Parquet, ale kolumny partycjonowania są niedostępne i ignorowane, podczas gdy eliminacja partycji nie zostanie zastosowana. Nie twórz tabel zewnętrznych w folderach usługi Delta Lake, ponieważ nie są one obsługiwane. Użyj widoków podzielonych na partycje różnicowe, jeśli musisz wykonać zapytanie dotyczące partycjonowanych danych usługi Delta Lake. |
| Eliminacja plików (wypychanie predykatu) | Nie. | Tak w bezserwerowej puli SQL. W przypadku wypychania ciągu należy użyć Latin1_General_100_BIN2_UTF8 sortowania w VARCHAR kolumnach, aby włączyć wypychanie. Aby uzyskać więcej informacji na temat sortowania, zobacz Typy sortowania obsługiwane dla usługi Synapse SQL. |
| Niestandardowy format lokalizacji | Nie. | Tak, używając symboli wieloznacznych, takich jak /year=*/month=*/day=* w formatach Parquet lub CSV. Niestandardowe ścieżki folderów nie są dostępne w usłudze Delta Lake. W bezserwerowej puli SQL można również używać cyklicznych symboli /logs/** wieloznacznych, aby odwoływać się do plików Parquet lub CSV w dowolnym podfolderze pod przywołytym folderem. |
| Skanowanie folderów cyklicznych | Tak | Tak. Na końcu ścieżki lokalizacji należy określić /** bezserwerowe pule SQL. W dedykowanej puli foldery są zawsze skanowane rekursywnie. |
| Uwierzytelnianie magazynu | Klucz dostępu do magazynu (SAK), microsoft entra passthrough, tożsamość zarządzana, niestandardowa aplikacja Microsoft Entra identity | Sygnatura dostępu współdzielonego (SAS), microsoft Entra passthrough, tożsamość zarządzana, tożsamość niestandardowa aplikacji firmy Microsoft Entra. |
| Mapowanie kolumn | Porządkowe — kolumny w definicji tabeli zewnętrznej są mapowane na kolumny w źródłowych plikach Parquet według pozycji. | Pula bezserwerowa: według nazwy. Kolumny w definicji tabeli zewnętrznej są mapowane na kolumny w źródłowych plikach Parquet według pasującej nazwy kolumny. Dedykowana pula: dopasowywanie porządkowe. Kolumny w definicji tabeli zewnętrznej są mapowane na kolumny w źródłowych plikach Parquet według pozycji. |
| CETAS (eksportowanie/przekształcanie) | Tak | Instrukcje CETAS z tabelami natywnymi jako element docelowy działają tylko w bezserwerowej puli SQL. Nie można używać dedykowanych pul SQL do eksportowania danych przy użyciu tabel natywnych. |
Uwaga
Natywne tabele zewnętrzne są zalecanym rozwiązaniem w pulach, w których są one ogólnie dostępne. Jeśli potrzebujesz dostępu do danych zewnętrznych, zawsze używaj tabel natywnych w pulach bezserwerowych. W dedykowanych pulach należy przełączyć się do tabel natywnych na potrzeby odczytywania plików Parquet, gdy znajdują się w ogólnie dostępnej wersji. Tabele usługi Hadoop należy używać tylko wtedy, gdy trzeba uzyskać dostęp do niektórych typów, które nie są obsługiwane w natywnych tabelach zewnętrznych (na przykład — ORC, RC) lub jeśli wersja natywna jest niedostępna.
Tabele zewnętrzne w dedykowanej puli SQL i bezserwerowej puli SQL
Tabele zewnętrzne umożliwiają:
- Wykonywanie zapytań dotyczących usług Azure Blob Storage i Azure Data Lake Gen2 przy użyciu instrukcji Języka Transact-SQL.
- Przechowywanie wyników zapytań do plików w usłudze Azure Blob Storage lub Azure Data Lake Storage przy użyciu instrukcji CETAS.
- Zaimportuj dane z usług Azure Blob Storage i Azure Data Lake Storage i przechowuj je w dedykowanej puli SQL (tylko tabele usługi Hadoop w dedykowanej puli).
Uwaga
W połączeniu z instrukcją CREATE TABLE AS SELECT wybranie z tabeli zewnętrznej importuje dane do tabeli w dedykowanej puli SQL.
Jeśli wydajność tabel zewnętrznych usługi Hadoop w dedykowanych pulach nie spełnia Twoich celów wydajności, rozważ załadowanie danych zewnętrznych do tabel magazynu danych przy użyciu instrukcji COPY.
Aby zapoznać się z samouczkiem ładowania, zobacz Ładowanie danych z usługi Azure Blob Storage przy użyciu technologii PolyBase.
Tabele zewnętrzne można tworzyć w pulach SQL usługi Synapse, wykonując następujące kroki:
- UTWÓRZ ZEWNĘTRZNE ŹRÓDŁO DANYCH, aby odwołać się do zewnętrznego magazynu platformy Azure i określić poświadczenia, które mają być używane do uzyskiwania dostępu do magazynu.
- UTWÓRZ FORMAT PLIKU ZEWNĘTRZNEGO, aby opisać format plików CSV lub Parquet.
- UTWÓRZ TABELĘ ZEWNĘTRZNĄ na podstawie plików umieszczonych w źródle danych w tym samym formacie pliku.
Eliminacja partycji folderu
Natywne tabele zewnętrzne w pulach usługi Synapse mogą ignorować pliki umieszczone w folderach, które nie są istotne dla zapytań. Jeśli pliki są przechowywane w hierarchii folderów (na przykład — /year=2020/month=03/day=16) i wartości yearmonth, i day są widoczne jako kolumny, zapytania zawierające filtry, takie jakyear=2020, będą odczytywać pliki tylko z podfolderów umieszczonych w folderzeyear=2020. Pliki i foldery umieszczone w innych folderach (year=2021 lub year=2022) zostaną zignorowane w tym zapytaniu. Ta eliminacja jest znana jako eliminacja partycji.
Eliminacja partycji folderu jest dostępna w natywnych tabelach zewnętrznych synchronizowanych z pul platformy Spark usługi Synapse. Jeśli zestaw danych został podzielony na partycje i chcesz wykorzystać eliminację partycji z utworzonymi tabelami zewnętrznymi, użyj widoków partycjonowanych zamiast tabel zewnętrznych.
Eliminacja plików
Niektóre formaty danych, takie jak Parquet i Delta, zawierają statystyki plików dla każdej kolumny (na przykład wartości minimalne/maksymalne dla każdej kolumny). Zapytania filtrujące dane nie będą odczytywać plików, w których nie istnieją wymagane wartości kolumn. Zapytanie najpierw zbada wartości minimalne/maksymalne dla kolumn używanych w predykacie zapytania w celu znalezienia plików, które nie zawierają wymaganych danych. Te pliki zostaną zignorowane i wyeliminowane z planu zapytania.
Ta technika jest również znana jako wypychanie predykatu filtru i może zwiększyć wydajność zapytań. Wypychanie filtru jest dostępne w bezserwerowych pulach SQL w formatach Parquet i Delta. Aby wykorzystać wypychanie filtru dla typów ciągów, użyj typu VARCHAR z sortowaniem Latin1_General_100_BIN2_UTF8 . Aby uzyskać więcej informacji na temat sortowania, zobacz Typy sortowania obsługiwane dla usługi Synapse SQL.
Zabezpieczenia
Użytkownik musi mieć SELECT uprawnienia do tabeli zewnętrznej, aby odczytać dane.
Tabele zewnętrzne uzyskują dostęp do bazowego magazynu platformy Azure przy użyciu poświadczeń o zakresie bazy danych zdefiniowanych w źródle danych przy użyciu następujących reguł:
- Źródło danych bez poświadczeń umożliwia zewnętrznym tabelom dostęp do publicznie dostępnych plików w usłudze Azure Storage.
- Źródło danych może mieć poświadczenia umożliwiające zewnętrznym tabelom dostęp tylko do plików w usłudze Azure Storage przy użyciu tokenu SAS lub tożsamości zarządzanej obszaru roboczego — na przykład zobacz artykuł Tworzenie kontroli dostępu do magazynu plików magazynu.
Przykład TWORZENIA ZEWNĘTRZNEGO ŹRÓDŁA DANYCH
Poniższy przykład tworzy zewnętrzne źródło danych usługi Hadoop w dedykowanej puli SQL dla usługi Azure Data Lake Gen2 wskazujące zestaw danych w Nowym Jorku:
CREATE DATABASE SCOPED CREDENTIAL [ADLS_credential]
WITH IDENTITY='SHARED ACCESS SIGNATURE',
SECRET = 'sv=2018-03-28&ss=bf&srt=sco&sp=rl&st=2019-10-14T12%3A10%3A25Z&se=2061-12-31T12%3A10%3A00Z&sig=KlSU2ullCscyTS0An0nozEpo4tO5JAgGBvw%2FJX2lguw%3D'
GO
CREATE EXTERNAL DATA SOURCE AzureDataLakeStore
WITH
-- Please note the abfss endpoint when your account has secure transfer enabled
( LOCATION = 'abfss://data@newyorktaxidataset.dfs.core.windows.net' ,
CREDENTIAL = ADLS_credential ,
TYPE = HADOOP
) ;
Poniższy przykład tworzy zewnętrzne źródło danych dla usługi Azure Data Lake Gen2 wskazujące publicznie dostępny zestaw danych w Nowym Jorku:
CREATE EXTERNAL DATA SOURCE YellowTaxi
WITH ( LOCATION = 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/',
TYPE = HADOOP)
Przykład: CREATE EXTERNAL FILE FORMAT (TWORZENIE FORMATU PLIKU ZEWNĘTRZNEGO)
Poniższy przykład tworzy format pliku zewnętrznego dla plików spisu:
CREATE EXTERNAL FILE FORMAT census_file_format
WITH
(
FORMAT_TYPE = PARQUET,
DATA_COMPRESSION = 'org.apache.hadoop.io.compress.SnappyCodec'
)
Przykład CREATE EXTERNAL TABLE
Poniższy przykład tworzy tabelę zewnętrzną. Zwraca pierwszy wiersz:
CREATE EXTERNAL TABLE census_external_table
(
decennialTime varchar(20),
stateName varchar(100),
countyName varchar(100),
population int,
race varchar(50),
sex varchar(10),
minAge int,
maxAge int
)
WITH (
LOCATION = '/parquet/',
DATA_SOURCE = population_ds,
FILE_FORMAT = census_file_format
)
GO
SELECT TOP 1 * FROM census_external_table
Tworzenie tabel zewnętrznych i wykonywanie na ich podstawie zapytań na podstawie pliku w usłudze Azure Data Lake
Korzystając z możliwości eksploracji usługi Synapse Studio w usłudze Data Lake, można teraz tworzyć i wykonywać zapytania względem tabeli zewnętrznej przy użyciu puli Synapse SQL z prostym kliknięciem prawym przyciskiem myszy pliku. Gest jednym kliknięciem umożliwiający utworzenie tabel zewnętrznych na podstawie konta magazynu usługi ADLS Gen2 jest obsługiwany tylko w przypadku plików Parquet.
Wymagania wstępne
Musisz mieć dostęp do obszaru roboczego z co najmniej
Storage Blob Data Contributorrolą dostępu do konta usługi ADLS Gen2 lub list kontroli dostępu (ACL), które umożliwiają wykonywanie zapytań dotyczących plików.Musisz mieć co najmniej uprawnienia do tworzenia tabeli zewnętrznej i wykonywania zapytań względem tabel zewnętrznych w puli SQL usługi Synapse (dedykowanej lub bezserwerowej).
Na panelu Dane wybierz plik, z którego chcesz utworzyć tabelę zewnętrzną:
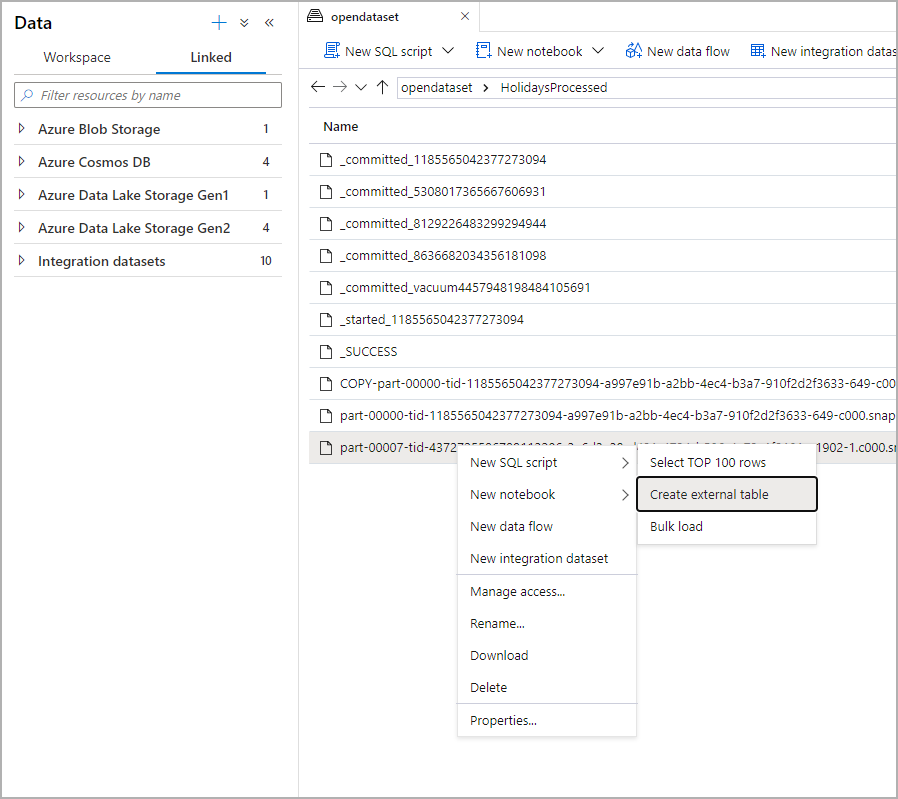
Zostanie otwarte okno dialogowe. Wybierz dedykowaną pulę SQL lub bezserwerową pulę SQL, nadaj tabeli nazwę i wybierz pozycję Otwórz skrypt:
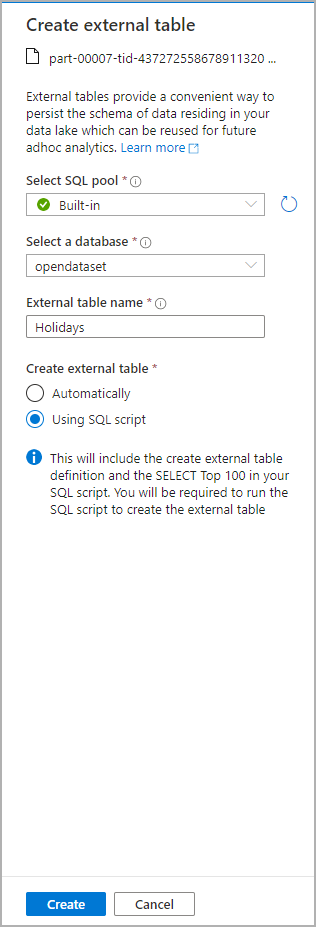
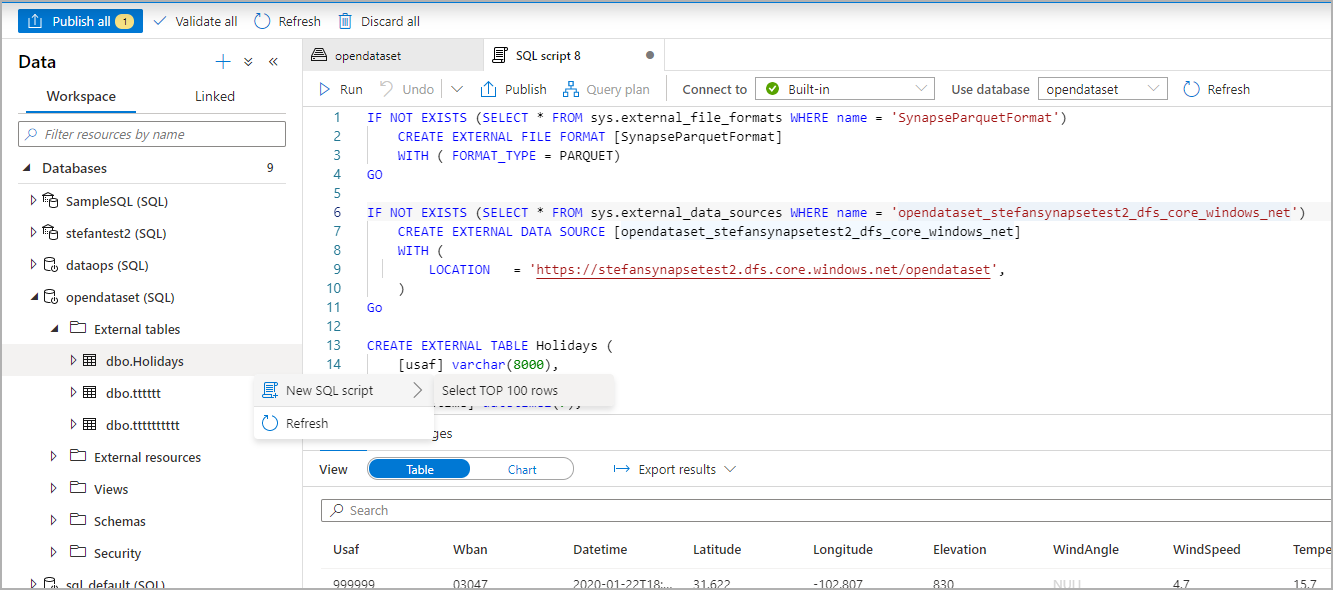
Skrypt SQL jest automatycznie generowany podczas wnioskowania schematu z pliku:
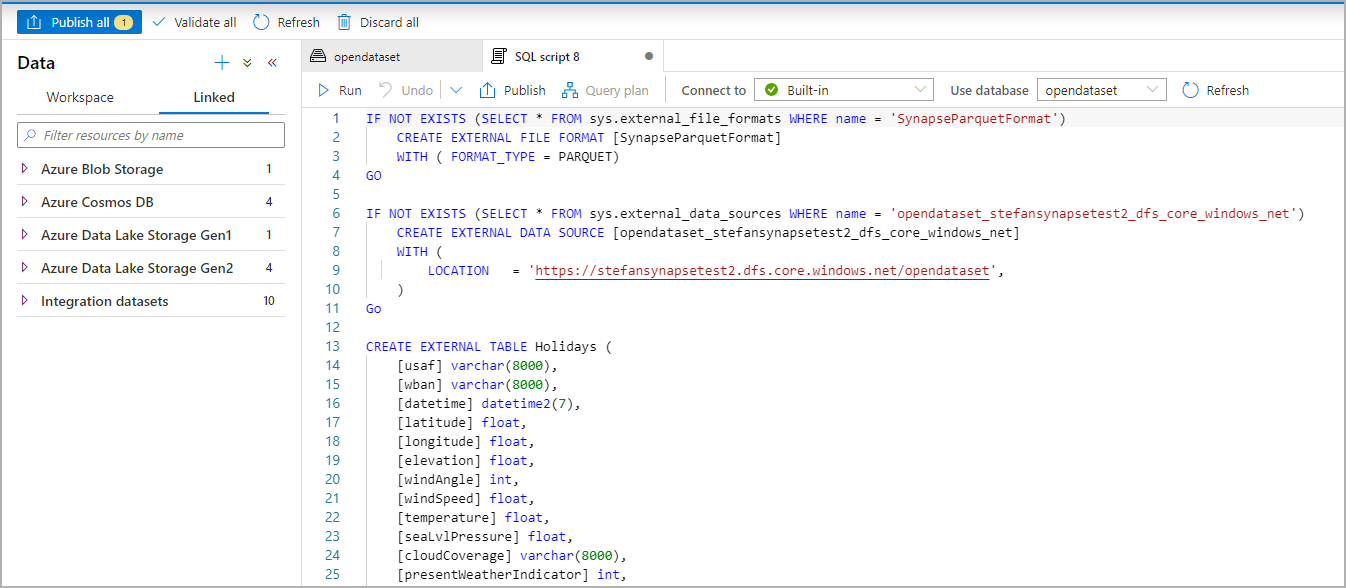
Uruchom skrypt. Skrypt automatycznie uruchomi 100 pierwszych *.:
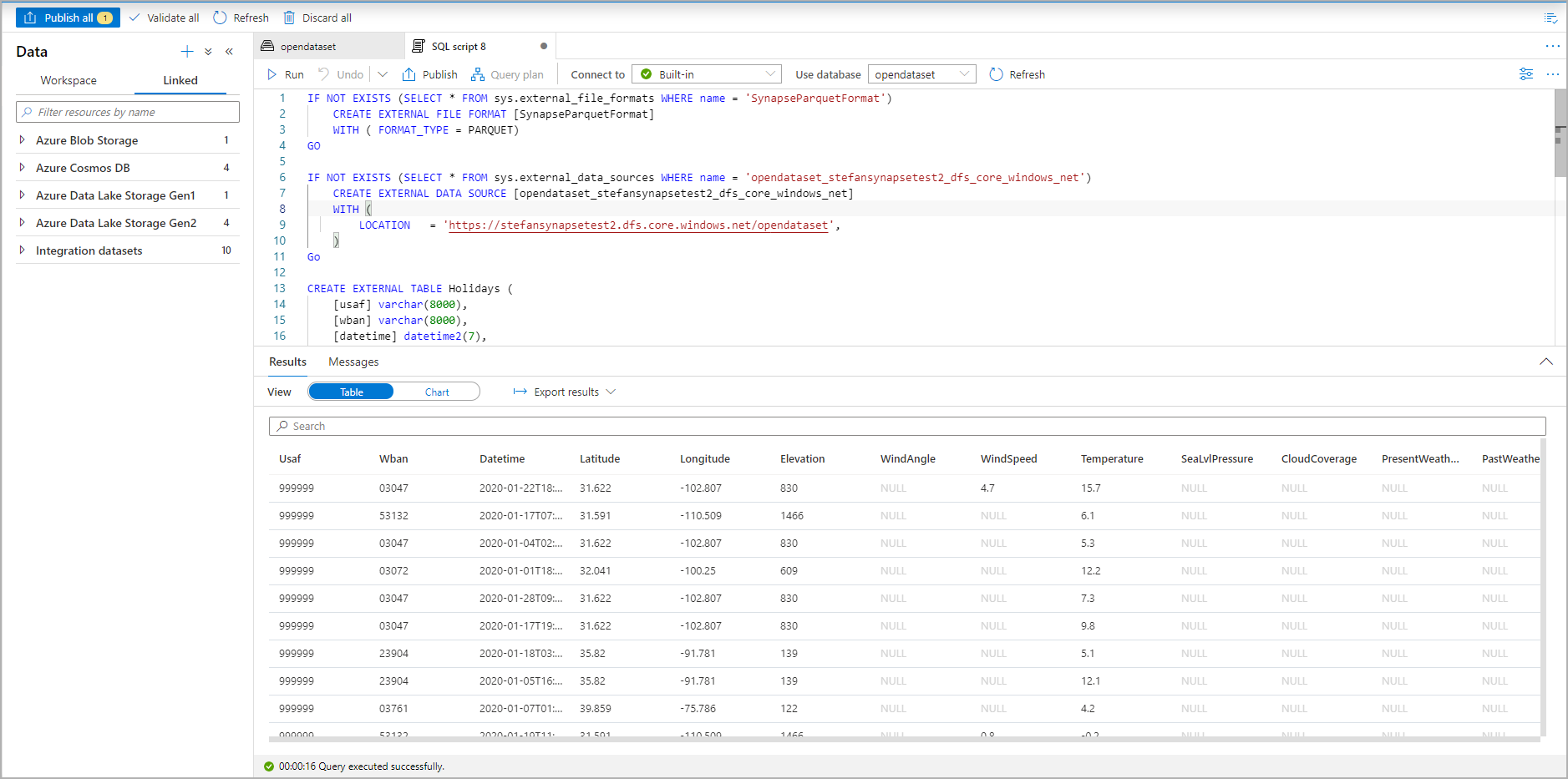
Tabela zewnętrzna jest teraz tworzona, aby w przyszłości zbadać zawartość tej tabeli zewnętrznej, użytkownik może wykonywać zapytania bezpośrednio w okienku Dane:
Następne kroki
Zobacz artykuł CETAS, aby dowiedzieć się, jak zapisywać wyniki zapytań w tabeli zewnętrznej w usłudze Azure Storage. Możesz też rozpocząć wykonywanie zapytań względem platformy Apache Spark dla tabel zewnętrznych usługi Azure Synapse.