Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Tip
Microsoft Fabric Data Warehouse to magazyn relacyjny w skali przedsiębiorstwa na podstawie bazy danych data lake z architekturą gotową do użycia w przyszłości, wbudowaną sztuczną inteligencją i nowymi funkcjami. Jeśli dopiero zaczynasz korzystać z magazynowania danych, zacznij od Fabric Data Warehouse. Istniejące obciążenia dedykowanej puli SQL mogą zostać zaktualizowane do Fabric, aby uzyskać dostęp do nowych możliwości w zakresie nauki o danych, analizy w czasie rzeczywistym i raportowania.
W tym artykule dowiesz się, jak wykonywać zapytania dotyczące pojedynczego pliku CSV przy użyciu bezserwerowej puli SQL w Azure Synapse Analytics. Pliki CSV mogą mieć różne formaty:
- Z i bez wiersza nagłówka
- Wartości rozdzielane przecinkami i tabulatorami
- Znaki końca linii w stylu Windows i Unix
- Niekwotowane i cytowane wartości oraz znaki ucieczkowe
Wszystkie powyższe odmiany zostaną omówione poniżej.
Przykład szybkiego startu
OPENROWSET funkcja umożliwia odczytywanie zawartości pliku CSV przez podanie adresu URL do pliku.
Odczytywanie pliku CSV
Najprostszym sposobem wyświetlenia zawartości CSV pliku jest podanie adresu URL pliku do funkcji OPENROWSET, określenie typu csv FORMAT, i 2.0 PARSER_VERSION. Jeśli plik jest publicznie dostępny lub jeśli tożsamość Microsoft Entra może uzyskać dostęp do tego pliku, powinna być widoczna zawartość pliku przy użyciu zapytania, takiego jak pokazany w poniższym przykładzie:
select top 10 *
from openrowset(
bulk 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
format = 'csv',
parser_version = '2.0',
firstrow = 2 ) as rows
Opcja firstrow służy do pomijania pierwszego wiersza w pliku CSV, który reprezentuje nagłówek w tym przypadku. Upewnij się, że masz dostęp do tego pliku. Jeśli plik jest chroniony przy użyciu klucza SAS lub niestandardowej tożsamości, musisz skonfigurować poświadczenia na poziomie serwera dla logowania SQL.
Ważne
Jeśli plik CSV zawiera znaki UTF-8, upewnij się, że używasz sortowania bazy danych UTF-8 (na przykład Latin1_General_100_CI_AS_SC_UTF8).
Niezgodność między kodowaniem tekstu w pliku a sortowaniem może spowodować nieoczekiwane błędy konwersji.
Domyślne sortowanie bieżącej bazy danych można łatwo zmienić przy użyciu następującej instrukcji języka T-SQL: alter database current collate Latin1_General_100_CI_AI_SC_UTF8
Użycie źródła danych
Poprzedni przykład używa pełnej ścieżki do pliku. Alternatywnie możesz utworzyć zewnętrzne źródło danych z lokalizacją wskazującą na ten katalog główny magazynu.
create external data source covid
with ( location = 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases' );
Po utworzeniu źródła danych możesz użyć tego źródła danych i ścieżki względnej do pliku w OPENROWSET funkcji:
select top 10 *
from openrowset(
bulk 'latest/ecdc_cases.csv',
data_source = 'covid',
format = 'csv',
parser_version ='2.0',
firstrow = 2
) as rows
Jeśli źródło danych jest chronione przy użyciu klucza SAS lub tożsamości niestandardowej, możesz skonfigurować źródło danych przy użyciu poświadczenia skojarzonego z zakresem bazy danych.
Jawne określanie schematu
OPENROWSET Umożliwia jawne określenie kolumn, które mają być odczytywane z pliku przy użyciu WITH klauzuli :
select top 10 *
from openrowset(
bulk 'latest/ecdc_cases.csv',
data_source = 'covid',
format = 'csv',
parser_version ='2.0',
firstrow = 2
) with (
date_rep date 1,
cases int 5,
geo_id varchar(6) 8
) as rows
Liczby po typie danych w klauzuli WITH reprezentują indeks kolumny w pliku CSV.
Ważne
Jeśli plik CSV zawiera znaki UTF-8, upewnij się, że jawnie określono sortowanie UTF-8 (na przykład Latin1_General_100_CI_AS_SC_UTF8) dla wszystkich kolumn w WITH klauzuli lub ustaw sortowanie UTF-8 na poziomie bazy danych.
Niezgodność między kodowaniem tekstu w pliku i sortowaniu może spowodować nieoczekiwane błędy konwersji.
Domyślne sortowanie bieżącej bazy danych można łatwo zmienić przy użyciu następującej instrukcji języka T-SQL:
alter database current collate Latin1_General_100_CI_AI_SC_UTF8 Sortowanie typów kolumn można łatwo ustawić przy użyciu następującej definicji: geo_id varchar(6) collate Latin1_General_100_CI_AI_SC_UTF8 8
W poniższych sekcjach przedstawiono sposób wykonywania zapytań dotyczących różnych typów plików CSV.
Prerequisites
Pierwszym krokiem jest utworzenie bazy danych , w której zostaną utworzone tabele. Następnie zainicjuj obiekty, wykonując skrypt setup w tej bazie danych. Ten skrypt instalacyjny utworzy źródła danych, poświadczenia o zakresie bazy danych i zewnętrzne formaty plików, które są używane w tych przykładach.
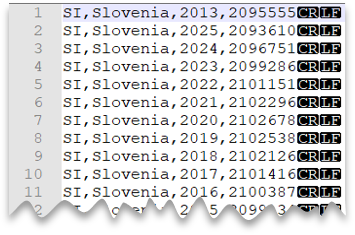
nowy wiersz w stylu Windows
Poniższe zapytanie pokazuje, jak odczytać plik CSV bez wiersza nagłówka z nowym wierszem w stylu Windows i kolumnami rozdzielanymi przecinkami.
Podgląd pliku:
SELECT *
FROM OPENROWSET(
BULK 'csv/population/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '\n'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017;
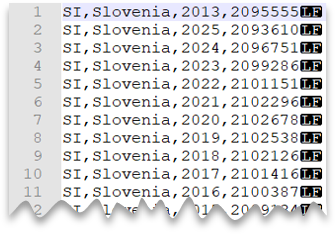
Nowa linia w stylu unix
Poniższe zapytanie pokazuje, jak odczytać plik bez wiersza nagłówka z nowym wierszem w stylu unix i kolumnami rozdzielanymi przecinkami. Zwróć uwagę na inną lokalizację pliku w porównaniu z innymi przykładami.
Podgląd pliku:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017;
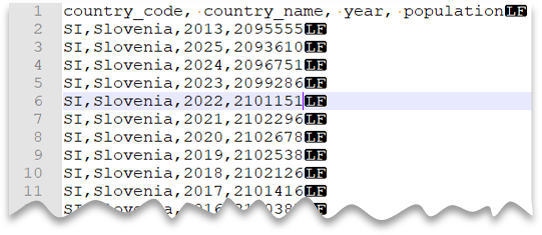
Wiersz nagłówka
Poniższe zapytanie pokazuje, jak odczytać plik z wierszem nagłówka, stosując nowy wiersz w stylu unix oraz kolumny rozdzielane przecinkami. Zwróć uwagę na inną lokalizację pliku w porównaniu z innymi przykładami.
Podgląd pliku:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
HEADER_ROW = TRUE
) AS [r]
Opcja HEADER_ROW = TRUE spowoduje odczytywanie nazw kolumn z wiersza nagłówka w pliku. Jest to doskonałe rozwiązanie do celów eksploracji, gdy nie znasz zawartości pliku. Aby uzyskać najlepszą wydajność, zobacz sekcję Używanie odpowiednich typów danych w temacie Najlepsze rozwiązania. Można również przeczytać więcej o składni OPENROWSET tutaj.
Niestandardowy znak cudzysłowu
Poniższe zapytanie pokazuje, jak odczytać plik z wierszem nagłówka, z nową linią w stylu Unix, kolumnami rozdzielanymi przecinkami i wartościami w cudzysłowach. Zwróć uwagę na inną lokalizację pliku w porównaniu z innymi przykładami.
Podgląd pliku:

SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-quoted/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2,
FIELDQUOTE = '"'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017;
Uwaga
To zapytanie zwróci te same wyniki, jeśli pominiesz parametr FIELDQUOTE, ponieważ wartość domyślna FIELDQUOTE jest podwójnym cudzysłowem.
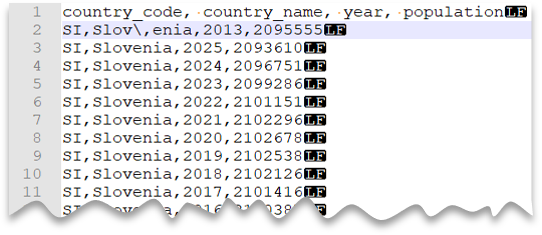
Znaki ucieczki
Poniższe zapytanie pokazuje, jak odczytać plik z wierszem nagłówka, z nową linią w stylu systemu Unix, kolumnami rozdzielanymi przecinkami i znakiem escape używanym jako separator pola (przecinek) wewnątrz wartości. Zwróć uwagę na inną lokalizację pliku w porównaniu z innymi przykładami.
Podgląd pliku:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-escape/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2,
ESCAPECHAR = '\\'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Slovenia';
Uwaga
To zapytanie zakończy się niepowodzeniem, jeśli funkcja ESCAPECHAR nie zostanie określona, ponieważ przecinek w nazwie "Slov,enia" byłby traktowany jako ogranicznik pola zamiast części nazwy kraju/regionu. "Slov,enia" będzie traktowany jako dwie kolumny. W związku z tym konkretny wiersz zawierałby jedną kolumnę więcej niż inne wiersze, a jedną kolumnę więcej niż zdefiniowano w klauzuli WITH.
Znaki cudzysłów ucieczki
Poniższe zapytanie pokazuje, jak odczytać plik z wierszem nagłówka, używając nowego wiersza w stylu systemu Unix, kolumn rozdzielanych przecinkami oraz znaku podwójnego cudzysłowu wewnątrz wartości. Zwróć uwagę na inną lokalizację pliku w porównaniu z innymi przykładami.
Podgląd pliku:
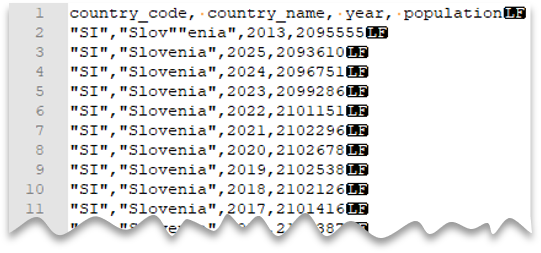
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-escape-quoted/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Slovenia';
Uwaga
Znak cudzysłowu musi być zastąpiony innym znakiem cudzysłowu. Znaki cudzysłowu mogą pojawić się w wartości kolumny tylko wtedy, gdy wartość jest ujęta w znaki cudzysłowu.
Pliki rozdzielane tabulatorami
Poniższe zapytanie pokazuje, jak odczytać plik z wierszem nagłówka z nowym wierszem w stylu unix i kolumnami rozdzielanymi tabulatorami. Zwróć uwagę na inną lokalizację pliku w porównaniu z innymi przykładami.
Podgląd pliku:
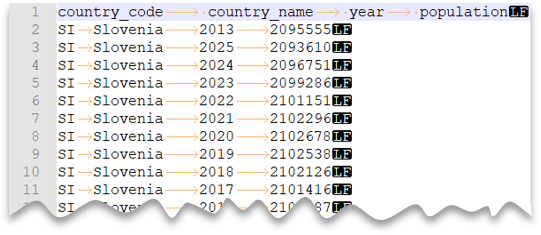
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-tsv/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR ='\t',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017
Zwracanie podzbioru kolumn
Do tej pory określono schemat pliku CSV przy użyciu funkcji WITH i listę wszystkich kolumn. W zapytaniu można określić tylko kolumny, których rzeczywiście potrzebujesz, używając numeru porządkowego dla każdej wymaganej kolumny. Również pomiń kolumny, które Cię nie interesują.
Następujące zapytanie zwraca liczbę unikatowych nazw krajów/regionów w pliku, określając tylko potrzebne kolumny:
Uwaga
Spójrz na klauzulę WITH w poniższym zapytaniu i zwróć uwagę, że na końcu wiersza znajduje się '2' (bez cudzysłowów), gdzie definiujesz kolumnę [country_name]. Oznacza to, że kolumna [country_name] jest drugą kolumną w pliku. Zapytanie zignoruje wszystkie kolumny w pliku z wyjątkiem drugiej.
SELECT
COUNT(DISTINCT country_name) AS countries
FROM OPENROWSET(
BULK 'csv/population/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '\n'
)
WITH (
--[country_code] VARCHAR (5),
[country_name] VARCHAR (100) 2
--[year] smallint,
--[population] bigint
) AS [r]
Wykonywanie zapytań dotyczących dołączanych plików
Pliki CSV używane w zapytaniu nie powinny być zmieniane podczas uruchamiania zapytania. W długotrwałym zapytaniu pula SQL może ponowić próbę odczytu, odczytu części plików, a nawet wielokrotnie odczytywać plik. Zmiany zawartości pliku spowodują nieprawidłowe wyniki. W związku z tym pula SQL kończy się niepowodzeniem zapytania, jeśli wykryje, że czas modyfikacji dowolnego pliku zostanie zmieniony podczas wykonywania zapytania.
W niektórych scenariuszach warto odczytać pliki, które są stale dołączane. Aby uniknąć błędów zapytań spowodowanych stale dołączanymi plikami, możesz dopuścić, aby funkcja OPENROWSET ignorowała potencjalnie niespójne odczyty, korzystając z ustawienia ROWSET_OPTIONS.
select top 10 *
from openrowset(
bulk 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
format = 'csv',
parser_version = '2.0',
firstrow = 2,
ROWSET_OPTIONS = '{"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}') as rows
Opcja ALLOW_INCONSISTENT_READS odczytu spowoduje wyłączenie sprawdzania czasu modyfikacji pliku w cyklu życia zapytania i odczytanie dowolnego elementu dostępnego w pliku. W dołączanych plikach istniejąca zawartość nie jest aktualizowana i dodawane są tylko nowe wiersze. W związku z tym prawdopodobieństwo nieprawidłowych wyników jest zminimalizowane w porównaniu z plikami z możliwością aktualizacji. Ta opcja może umożliwić odczytywanie często dołączanych plików bez potrzeby obsługi błędów. W większości scenariuszy pula SQL po prostu ignoruje niektóre wiersze dołączane do plików podczas wykonywania zapytania.
Powiązana zawartość
W następnych artykułach pokazano, jak wykonać następujące czynności: