Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Usługa Azure Traffic Manager obejmuje wbudowane monitorowanie punktów dostępu i automatyczne przełączanie punktów dostępu. Ta funkcja ułatwia dostarczanie aplikacji o wysokiej dostępności, które są odporne na awarie punktów końcowych, a w tym awarie regionów platformy Azure. Monitorowanie punktu końcowego jest domyślnie włączone. Aby wyłączyć monitorowanie, zobacz Włączanie lub wyłączanie kontroli kondycji.
Konfigurowanie monitorowania punktu końcowego
Aby skonfigurować monitorowanie punktu końcowego, należy określić następujące ustawienia w profilu usługi Traffic Manager:
- Protokół. Wybierz protokół HTTP, HTTPS lub TCP jako protokół używany przez usługę Traffic Manager podczas sondowania punktu końcowego w celu sprawdzenia jego kondycji. Monitorowanie protokołu HTTPS nie sprawdza, czy certyfikat TLS/SSL jest prawidłowy, sprawdza tylko, czy certyfikat jest obecny.
Uwaga
Obsługa protokołu TLS 1.0 i 1.1 w usłudze Traffic Manager zakończyła się 28 lutego 2025 r. Aby uzyskać więcej informacji, zobacz Często zadawane pytania dotyczące protokołu TLS usługi Traffic Manager.
- Port. Wybierz port używany dla żądania.
-
Ścieżka. To ustawienie konfiguracji jest prawidłowe tylko dla protokołów HTTP i HTTPS, dla których wymagane jest określenie ustawienia ścieżki. Podanie tego ustawienia dla protokołu monitorowania TCP powoduje wystąpienie błędu. W przypadku protokołu HTTP i HTTPS podaj ścieżkę względną oraz nazwę strony internetowej lub pliku, do którego uzyskuje dostęp monitorowanie. Ukośnik
/do przodu jest prawidłowym wpisem dla ścieżki względnej. Ta wartość oznacza, że plik znajduje się w katalogu głównym (wartość domyślna). -
Ustawienia nagłówka niestandardowego. To ustawienie konfiguracji ułatwia dodawanie określonych nagłówków HTTP do kontroli kondycji wysyłanych przez usługę Traffic Manager do punktów końcowych w profilu. Nagłówki niestandardowe można określić na poziomie profilu, co sprawi, że będą one dotyczyły wszystkich punktów końcowych w danym profilu, oraz/lub na poziomie poszczególnych punktów końcowych, gdzie będą miały zastosowanie tylko do tych konkretnych punktów. Do sprawdzania kondycji punktów końcowych w środowisku wielodostępnym można użyć nagłówków niestandardowych. W ten sposób, określając nagłówek hostowy, można prawidłowo skierować go do celu. To ustawienie można również użyć, dodając unikatowe nagłówki, które mogą służyć do identyfikowania żądań HTTP(S) pochodzących z usługi Traffic Manager i przetwarzania ich w inny sposób. Można określić maksymalnie osiem
header:valuepar rozdzielonych przecinkami. Na przykładheader1:value1, header2:value2.
Uwaga
Używanie znaków gwiazdki (*) w niestandardowych nagłówkach Host jest niewspierane.
Zakresy oczekiwanych kodów stanu. To ustawienie umożliwia określenie wielu zakresów kodu sukcesu w formacie 200-299, 301-301. Jeśli te kody stanu są odbierane jako odpowiedź z punktu końcowego po zakończeniu sprawdzania kondycji, usługa Traffic Manager oznaczy te punkty końcowe jako w dobrej kondycji. Można określić maksymalnie osiem zakresów kodu stanu. To ustawienie ma zastosowanie tylko do protokołu HTTP i HTTPS oraz do wszystkich punktów końcowych. To ustawienie jest na poziomie profilu usługi Traffic Manager, a domyślnie wartość 200 jest definiowana jako kod stanu powodzenia.
Interwał sondowania. Ta wartość określa, jak często punkt końcowy jest sprawdzany pod kątem swojej kondycji przez agenta sondowania usługi Traffic Manager. W tym miejscu można określić dwie wartości: 30 sekund (normalne sondowanie) i 10 sekund (szybkie sondowanie). Jeśli nie podano żadnych wartości, profil ustawia wartość domyślną 30 sekund. Odwiedź stronę cennika usługi Traffic Manager, aby dowiedzieć się więcej na temat szybkich cen sondowania.
Tolerowana liczba awarii. Ta wartość określa liczbę niepowodzeń tolerowanych przez agenta sondowania usługi Traffic Manager przed oznaczeniem tego punktu końcowego jako niezdrowy. Jej wartość może mieścić się w zakresie od 0 do 9. Wartość 0 oznacza, że pojedynczy błąd monitorowania może spowodować oznaczenie tego punktu końcowego jako w złej kondycji. Jeśli żadna wartość nie zostanie określona, zostanie użyta wartość domyślna 3.
Limit czasu sondy. Ta właściwość określa, ile czasu agent monitorujący usługi Traffic Manager powinien czekać przed uznaniem badania stanu zdrowia w punkcie końcowym za nieudane. Jeśli interwał sondowania jest ustawiony na 30 sekund, możesz ustawić wartość limitu czasu z zakresu od 5 do 10 sekund. Jeśli żadna wartość nie zostanie określona, zostanie użyta wartość domyślna 10 sekund. Jeśli interwał sondowania jest ustawiony na 10 sekund, możesz ustawić wartość limitu czasu z zakresu od 5 do 9 sekund. Jeśli nie określono wartości limitu czasu, zostanie użyta wartość domyślna 9 sekund.
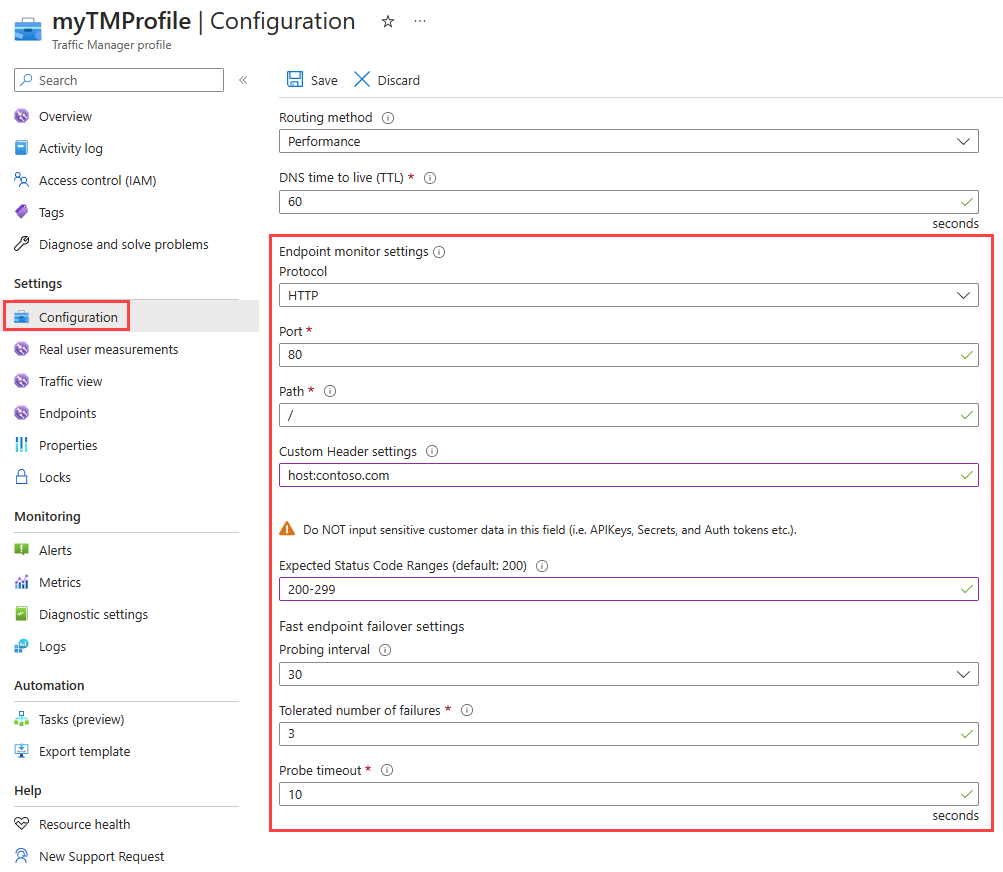
Rysunek: Monitorowanie punktu końcowego usługi Traffic Manager

Jak działa monitorowanie punktów końcowych
Gdy protokół monitorowania jest ustawiony jako HTTP lub HTTPS, agent sondowania usługi Traffic Manager wysyła żądanie GET do punktu końcowego przy użyciu podanego protokołu, portu i ścieżki względnej. Punkt końcowy jest uznawany za w dobrej kondycji, jeśli agent sondowania otrzyma odpowiedź 200-OK lub dowolną z odpowiedzi skonfigurowanych w zakresach oczekiwanego kodu stanu. Jeśli odpowiedź jest inną wartością lub żadna odpowiedź nie zostanie odebrana w okresie limitu czasu, agent sondowania usługi Traffic Manager ponawia próbę zgodnie z ustawieniem Tolerowana liczba niepowodzeń. Jeśli to ustawienie ma wartość 0, nie są podejmowane żadne ponowne próby. Punkt końcowy jest oznaczony jako w złej kondycji, jeśli liczba kolejnych niepowodzeń jest większa niż tolerowana liczba niepowodzeń .
Gdy protokół monitorowania to TCP, agent sondowania usługi Traffic Manager tworzy żądanie połączenia TCP przy użyciu określonego portu. Jeśli punkt końcowy odpowiada na żądanie z odpowiedzią na nawiązanie połączenia, ta kontrola kondycji zostanie oznaczona jako powodzenie. Agent sondowania usługi Traffic Manager resetuje połączenie TCP. W przypadkach, gdy odpowiedź jest inną wartością lub żadna odpowiedź nie zostanie odebrana w okresie przekroczenia limitu czasu, agent testujący usługi Traffic Manager ponawia próbę zgodnie z ustawieniem Tolerowana liczba błędów. Jeśli to ustawienie wynosi 0, nie są wykonywane żadne ponowne próby. Jeśli liczba kolejnych niepowodzeń jest większa niż tolerowana liczba niepowodzeń , oznacza to, że punkt końcowy jest oznaczony jako w złej kondycji.
Sondy usługi Traffic Manager przebiegają z wielu lokalizacji we wszystkich przypadkach. Kolejna awaria określa, co się dzieje w każdym regionie. Dlatego punkty końcowe otrzymują sondy zdrowotne z usługi Traffic Manager z częstszą częstotliwością niż ustawienie interwału sondowania.
Uwaga
W przypadku protokołu monitorowania HTTP lub HTTPS typowym rozwiązaniem po stronie punktu końcowego jest zaimplementowanie niestandardowej strony w aplikacji — na przykład /health.aspx. Korzystając z tej ścieżki do monitorowania, można przeprowadzić kontrole specyficzne dla aplikacji, takie jak sprawdzanie liczników wydajności lub weryfikowanie dostępności bazy danych. Na podstawie tych testów niestandardowych strona zwraca odpowiedni kod stanu HTTP.
Wszystkie punkty końcowe w profilu usługi Traffic Manager udostępniają ustawienia monitorowania. Jeśli chcesz użyć różnych ustawień monitorowania dla różnych punktów końcowych, możesz utworzyć zagnieżdżone profile usługi Traffic Manager.
Status punktu końcowego i profilu
Możesz włączać i wyłączać profile i punkty końcowe usługi Traffic Manager. Jednak zmiana stanu punktu końcowego może również wystąpić z powodu zautomatyzowanych ustawień i procesów usługi Traffic Manager.
Stan punktu końcowego
Możesz włączyć lub wyłączyć określony punkt końcowy. Nie ma to wpływu na podstawową usługę, która może być nadal w dobrej kondycji. Zmiana stanu punktu końcowego kontroluje dostępność punktu końcowego w profilu usługi Traffic Manager. Gdy stan punktu końcowego jest wyłączony, usługa Traffic Manager nie sprawdza kondycji, a punkt końcowy nie jest uwzględniony w odpowiedzi DNS.
Stan profilu
Za pomocą ustawienia stanu profilu można włączyć lub wyłączyć określony profil. Stan punktu końcowego ma wpływ na pojedynczy punkt końcowy, ale stan profilu wpływa na cały profil, w tym wszystkie punkty końcowe. Po wyłączeniu profilu punkty końcowe nie są sprawdzane pod kątem kondycji i żadne punkty końcowe nie są uwzględniane w odpowiedzi DNS. Kod odpowiedzi NXDOMAIN jest zwracany dla zapytania DNS.
Stan monitora punktu końcowego
Stan monitora punktu końcowego to wartość wygenerowana przez usługę Traffic Manager, która pokazuje stan punktu końcowego. Nie można ręcznie zmienić tego ustawienia. Stan monitora punktu końcowego jest kombinacją wyników monitorowania punktu końcowego i skonfigurowanego stanu punktu końcowego. Możliwe wartości stanu monitora punktu końcowego przedstawiono w poniższej tabeli:
| Stan profilu | Stan punktu końcowego | Stan monitora punktu końcowego | Uwagi |
|---|---|---|---|
| Wyłączony | Włączony | Nieaktywny | Profil został wyłączony. Mimo że stan punktu końcowego to Włączone, stan profilu (Wyłączone) ma pierwszeństwo. Punkty końcowe w profilach wyłączonych nie są monitorowane. Kod odpowiedzi NXDOMAIN jest zwracany dla zapytania DNS. |
| <jakikolwiek> | Wyłączony | Wyłączony | Punkt końcowy został wyłączony. Wyłączone punkty końcowe nie są monitorowane. Punkt końcowy nie jest uwzględniany w odpowiedziach DNS, w związku z tym nie otrzymuje ruchu. |
| Włączony | Włączony | Online | Punkt końcowy jest monitorowany i jest w dobrej kondycji. Jest on uwzględniony w odpowiedziach DNS i może odbierać ruch. |
| Włączony | Włączony | Zdegradowany | Kontrole stanu punktu końcowego kończą się niepowodzeniem. Punkt końcowy nie jest uwzględniany w odpowiedziach DNS i nie odbiera ruchu. Wyjątek występuje, gdy wszystkie punkty końcowe są obniżone. W tym przypadku wszystkie uznawane są za zawarte w odpowiedzi zapytania. |
| Włączony | Włączony | Sprawdzanie punktu końcowego | Punkt końcowy jest monitorowany, ale wyniki pierwszej sondy nie zostały jeszcze odebrane. CheckingEndpoint to stan tymczasowy, który zwykle występuje natychmiast po dodaniu lub włączeniu punktu końcowego w profilu. Punkt końcowy w tym stanie jest uwzględniony w odpowiedziach DNS i może odbierać ruch. |
| Włączony | Włączony | Zatrzymana | Aplikacja internetowa, do którego wskazuje punkt końcowy, nie jest uruchomiona. Sprawdź ustawienia aplikacji internetowej. Ten stan może również wystąpić, jeśli punkt końcowy ma typ zagnieżdżonego punktu końcowego, a profil podrzędny zostanie wyłączony lub jest nieaktywny. Punkt końcowy ze stanem Zatrzymano nie jest monitorowany. Nie jest ona uwzględniana w odpowiedziach DNS i nie odbiera ruchu. Wyjątek występuje, gdy wszystkie punkty końcowe są obniżone. W tym przypadku wszystkie z nich są uważane za zwracane w odpowiedzi zapytania. |
| Włączony | Włączony | Niemonitorowane | Punkt końcowy jest skonfigurowany do zawsze obsługiwania ruchu. Kontrole kondycji nie są włączone. |
Aby uzyskać szczegółowe informacje na temat sposobu obliczania stanu monitora punktu końcowego dla zagnieżdżonych punktów końcowych, zobacz Zagnieżdżone profile usługi Traffic Manager.
Uwaga
Stan zatrzymanego monitora punktu końcowego może wystąpić w usłudze App Service, jeśli aplikacja internetowa nie jest uruchomiona w warstwie Standardowa lub nowszej. Aby uzyskać więcej informacji, zobacz Integracja usługi Traffic Manager z usługą App Service.
Stan monitora profilu
Stan monitora profilu jest kombinacją skonfigurowanego stanu profilu i wartości stanu monitorowania punktu końcowego dla wszystkich punktów końcowych. Możliwe wartości zostały opisane w poniższej tabeli:
| Stan profilu (zgodnie z konfiguracją) | Stan monitora punktu końcowego | Stan monitora profilu | Uwagi |
|---|---|---|---|
| Wyłączony | <dowolny> profil, który nie ma zdefiniowanych punktów końcowych. | Wyłączony | Profil został wyłączony. |
| Włączony | Stan co najmniej jednego punktu końcowego jest pogorszony. | Zdegradowany | Przejrzyj poszczególne wartości stanu punktu końcowego, aby określić, które punkty końcowe wymagają dalszej uwagi. |
| Włączony | Stan co najmniej jednego punktu końcowego to Online. Żadne punkty końcowe nie mają obniżonego statusu. | Online | Usługa akceptuje ruch. Nie są wymagane żadne dalsze działania. |
| Włączony | Stan co najmniej jednego punktu końcowego to „CheckingEndpoint”. Żadne punkty końcowe nie mają stanu Online lub zdegradowany. | Sprawdzanie Punktów Końcowych | Ten stan przejścia występuje, gdy profil zostanie utworzony lub włączony. Kondycja punktu końcowego jest sprawdzana po raz pierwszy. |
| Włączony | Stany wszystkich punktów końcowych w profilu to Wyłączone lub Zatrzymane albo profil nie ma zdefiniowanych punktów końcowych. | Nieaktywny | Żadne punkty końcowe nie są aktywne, ale profil jest nadal włączony. |
Przełączanie awaryjne i odzyskiwanie punktu końcowego
Usługa Traffic Manager okresowo sprawdza kondycję każdego punktu końcowego, w tym punkty końcowe w złej kondycji. Usługa Traffic Manager wykrywa, kiedy punkt końcowy staje się w dobrej kondycji i przywraca go do rotacji.
Punkt końcowy nie działa prawidłowo, gdy wystąpi jedno z następujących zdarzeń:
- Jeśli protokół monitorowania to HTTP lub HTTPS:
- Odpowiedź inna niż 200 lub odpowiedź, która nie zawiera zakresu kodów stanu określonego w ustawieniu Oczekiwany zakres kodów stanu, została odebrana. (W tym inny kod 2xx lub przekierowanie 301/302).
- Jeśli protokół monitorowania to TCP:
- Odpowiedź inna niż ACK lub SYN-ACK jest odbierana w odpowiedzi na żądanie SYN wysłane przez Traffic Managera w celu spróbowania nawiązania połączenia.
- Limit czasu.
- Wszelkie inne problemy z połączeniem powodujące, że punkt końcowy jest niedostępny.
Aby uzyskać więcej informacji na temat rozwiązywania problemów z nieudanym sprawdzaniem, zobacz Rozwiązywanie problemów ze stanem obniżonej wydajności w usłudze Azure Traffic Manager.
Oś czasu na poniższej ilustracji to szczegółowy opis procesu monitorowania punktu końcowego usługi Traffic Manager, który ma następujące ustawienia:
- Protokół monitorowania to HTTP.
- Interwał sondowania wynosi 30 sekund.
- Liczba tolerowanych awarii wynosi 3.
- Wartość limitu czasu wynosi 10 sekund.
- Czas TTL dla DNS wynosi 30 sekund.
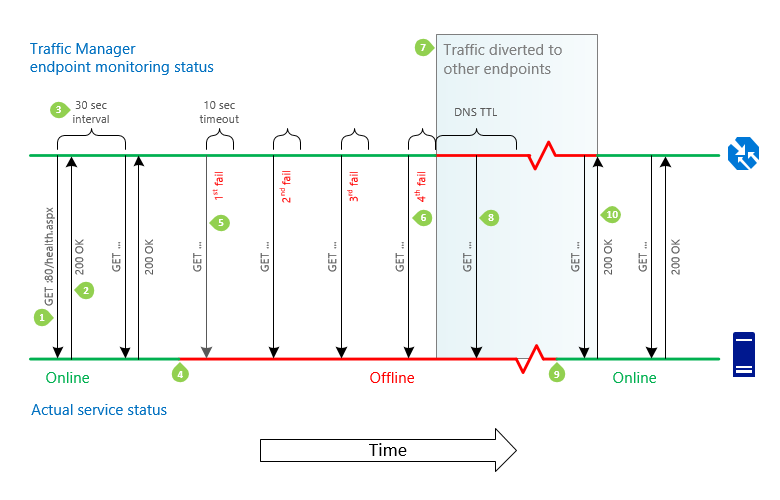 Rysunek: Przechodzenie do trybu failover i sekwencja odzyskiwania punktu końcowego usługi Traffic Manager
Rysunek: Przechodzenie do trybu failover i sekwencja odzyskiwania punktu końcowego usługi Traffic Manager
GET. Dla każdego punktu końcowego system monitorowania usługi Traffic Manager wykonuje żądanie GET na ścieżce określonej w ustawieniach monitorowania.
200 OK lub niestandardowy zakres kodów określony w ustawieniach monitorowania profilu Traffic Manager. System monitorowania oczekuje, że kod HTTP 200 OK lub kod stanu w zakresie określonym w ustawieniach monitorowania zostanie zwrócony w ciągu 10 sekund. Gdy otrzyma tę odpowiedź, rozpoznaje, że usługa jest dostępna.
30 sekund między kontrolami. Sprawdzanie kondycji punktu końcowego jest powtarzane co 30 sekund.
Usługa jest niedostępna. Usługa staje się niedostępna. Usługa Traffic Manager nie będzie wiedziała, dopóki nie nastąpi następne sprawdzenie kondycji.
Próbuje uzyskać dostęp do ścieżki monitorowania. System monitorowania wykonuje żądanie GET, ale nie otrzymuje odpowiedzi w przedziale czasu 10 sekund. Następnie próbuje trzy razy, w 30-sekundowych odstępach czasu. Jeśli jedna z prób zakończy się pomyślnie, liczba prób zostanie zresetowana.
Stan ustawiony na Obniżona wydajność. Po czwartej kolejnej awarii system monitorowania oznacza stan niedostępnego punktu końcowego jako Obniżona wydajność.
Ruch jest przekierowywany do innych punktów końcowych. Serwery nazw DNS usługi Traffic Manager są aktualizowane, a usługa Traffic Manager nie zwraca już punktu końcowego w odpowiedzi na zapytania DNS. Nowe połączenia są kierowane do innych, dostępnych punktów końcowych. Jednak poprzednie odpowiedzi DNS, które obejmują ten punkt końcowy, mogą być nadal buforowane przez cykliczne serwery DNS i klientów DNS. Klienci nadal używają punktu końcowego do momentu wygaśnięcia pamięci podręcznej DNS. Gdy pamięć podręczna DNS wygaśnie, klienci tworzą nowe zapytania DNS i są kierowani do różnych punktów końcowych. Czas przechowywania w pamięci podręcznej jest kontrolowany przez ustawienie TTL w profilu Traffic Manager, na przykład 30 sekund.
Testy kondycji są kontynuowane. Usługa Traffic Manager nadal monitoruje kondycję punktu końcowego, gdy ma stan pogorszony. Usługa Traffic Manager wykrywa, kiedy punkt końcowy powróci do kondycji.
Usługa wraca do trybu online. Usługa stanie się dostępna. Punkt końcowy zachowuje stan obniżonej wydajności w usłudze Traffic Manager, dopóki system monitorowania nie wykona kolejnego sprawdzenia kondycji.
Ruch do usługi jest wznawiany. Usługa Traffic Manager wysyła żądanie GET i otrzymuje odpowiedź ze statusem 200 OK. Usługa wróciła do stanu dobrej kondycji. Serwery nazw usługi Traffic Manager są aktualizowane i zaczynają rozdać nazwę DNS usługi w odpowiedziach DNS. Ruch wraca do punktu końcowego w miarę jak wygasają buforowane odpowiedzi DNS dotyczące innych punktów końcowych, a istniejące połączenia z tymi punktami wygasają.
Ważne
Usługa Traffic Manager wdraża wiele sond z wielu lokalizacji dla każdego punktu końcowego. Wiele sond zwiększa odporność w monitorowaniu punktów końcowych. Usługa Traffic Manager agreguje uśredniony stan sond zamiast polegać na pojedynczym wystąpieniu sondy. Redundancja systemu sondowania jest zamierzona. Wartości punktów końcowych powinny być analizowane całościowo, a nie na poziomie poszczególnych sond. Wyświetlana liczba dotycząca kondycji sondy stanowi średnią. Stan powinien być problemem tylko wtedy, gdy mniej niż 50% (0,5) sond publikuje stan UP.
Uwaga
Ponieważ usługa Traffic Manager działa na poziomie DNS, nie może mieć wpływu na istniejące połączenia z żadnym punktem końcowym. Gdy kieruje ruch między punktami końcowymi (przez zmienione ustawienia profilu lub podczas działania trybu failover lub powrotu po awarii), usługa Traffic Manager kieruje nowe połączenia do dostępnych punktów końcowych. Inne punkty końcowe mogą nadal odbierać ruch za pośrednictwem istniejących połączeń do momentu zakończenia tych sesji. Aby umożliwić opróżnianie ruchu z istniejących połączeń, aplikacje powinny ograniczyć czas trwania sesji używany dla każdego punktu końcowego.
Metody routingu ruchu
Gdy punkt końcowy ma stan Obniżona wydajność , nie jest już zwracany w odpowiedzi na zapytania DNS. Zamiast tego jest wybierany i zwracany alternatywny punkt końcowy. Metoda routingu ruchu skonfigurowana w profilu określa sposób wyboru alternatywnego punktu końcowego.
- Priorytet. Punkty końcowe określają priorytetową listę. Pierwszy dostępny punkt końcowy na liście jest zawsze zwracany. Jeśli stan punktu końcowego jest obniżony, zostanie zwrócony następny dostępny punkt końcowy.
- Ważone. Wszystkie dostępne punkty końcowe są wybierane losowo na podstawie przypisanych wag i wag innych dostępnych punktów końcowych.
- Wydajność. Punkt końcowy najbliżej użytkownika końcowego jest zwracany. Jeśli ten punkt końcowy jest niedostępny, usługa Traffic Manager przenosi ruch do punktów końcowych w następnym najbliższym regionie świadczenia usługi Azure. Możesz skonfigurować alternatywne plany trybu failover na potrzeby routingu ruchu związanego z wydajnością przy użyciu zagnieżdżonych profilów usługi Traffic Manager.
- Geograficzne. Punkt końcowy zamapowany na obsługę lokalizacji geograficznej (na podstawie adresów IP żądania zapytania) jest zwracany. Jeśli ten punkt końcowy jest niedostępny, nie zostanie wybrany inny punkt końcowy do przełączenia, ponieważ lokalizacja geograficzna może być przypisana tylko do jednego punktu końcowego w profilu. (Więcej szczegółów znajduje się w temacie Często zadawane pytania). Najlepszym rozwiązaniem jest użycie routingu geograficznego, dlatego zalecamy klientom używanie zagnieżdżonych profilów usługi Traffic Manager z więcej niż jednym punktem końcowym jako punktami końcowymi profilu.
- MultiValue Zwracane są wiele punktów końcowych mapowane na adresy IPv4/IPv6. Po odebraniu zapytania dla tego profilu punkty końcowe w dobrej kondycji są zwracane na podstawie maksymalnej liczby rekordów w podanej wartości odpowiedzi . Domyślna liczba odpowiedzi to dwa punkty końcowe.
- Podsieć Punkt końcowy, który jest zamapowany na zestaw zakresów adresów IP, jest zwracany. Po odebraniu żądania z tego adresu IP zwracany jest punkt końcowy zamapowany na ten adres IP.
Aby uzyskać więcej informacji, zobacz Metody routingu ruchu w usłudze Traffic Manager.
Uwaga
Jeden wyjątek od normalnego zachowania routingu ruchu występuje, gdy wszystkie kwalifikujące się punkty końcowe mają obniżony status. Usługa Traffic Manager podejmuje „najlepszą próbę” i reaguje tak, jakby wszystkie punkty końcowe o obniżonej wydajności rzeczywiście były w stanie online. To zachowanie jest preferowane od alternatywy, która polegałaby na niezwracaniu żadnego punktu końcowego w odpowiedzi DNS. Wyłączone lub zatrzymane punkty końcowe nie są monitorowane, dlatego nie są uznawane za kwalifikujące się do ruchu.
Ten warunek jest często spowodowany niewłaściwą konfiguracją usługi, na przykład:
- Lista kontroli dostępu [ACL] blokuje kontrole kondycji usługi Traffic Manager.
- Niewłaściwa konfiguracja portu lub protokołu monitorowania w profilu usługi Traffic Manager.
Konsekwencją tego zachowania jest to, że jeśli testy kondycji usługi Traffic Manager nie są poprawnie skonfigurowane, może się wydawać z routingu ruchu, tak jakby usługa Traffic Manager działała prawidłowo. Jednak w tym przypadku przełączenie w tryb awaryjny punktu końcowego nie może nastąpić, co wpływa na ogólną dostępność aplikacji. Należy sprawdzić, czy profil ma status Online, a nie status Pogorszony. Status Online wskazuje, że testy kondycji usługi Traffic Manager działają zgodnie z oczekiwaniami.
Aby uzyskać więcej informacji na temat rozwiązywania problemów z nieudaną kontrolą kondycji, zobacz Rozwiązywanie problemów ze stanem obniżonej wydajności w usłudze Azure Traffic Manager.
Włączanie lub wyłączanie kontroli kondycji
Usługa Azure Traffic Manager umożliwia również konfigurowanie kontroli kondycji punktu końcowego w celu włączenia lub wyłączenia. Aby wyłączyć monitorowanie, wybierz opcję Zawsze kierować ruchem.
Istnieją dwa dostępne ustawienia kontroli kondycji:
- Włącz (kontrole kondycji). Ruch jest kierowany do punktu końcowego na podstawie stanu zdrowia. Jest to ustawienie domyślne.
- Zawsze obsługuj ruch. To ustawienie powoduje wyłączenie kontroli kondycji.
Zawsze służ
Gdy wybierzesz opcję Zawsze wysyłaj ruch, monitorowanie jest pomijane, a ruch zawsze jest wysyłany do punktu końcowego. Status monitora punktu końcowego wyświetlany to Niemonitorowane.
Aby włączyć funkcję Always Serve:
- Wybierz Punkty końcowe w Ustawienia bloku profilu usługi Traffic Manager.
- Wybierz punkt końcowy, który chcesz skonfigurować.
- W obszarze Kontrole kondycji wybierz pozycję Zawsze obsługuj ruch.
- Wybierz pozycję Zapisz.
Zobacz poniższy przykład:

Uwaga
- Nie można wyłączyć testów zdrowia w zagnieżdżonych profilach usługi Traffic Manager.
- Aby skonfigurować kontrole kondycji, należy włączyć punkt końcowy.
- Włączenie i wyłączenie punktu końcowego nie powoduje zresetowania konfiguracji kontroli zdrowotnych.
- Punkty końcowe skonfigurowane zawsze do obsługi ruchu są obciążane kosztami podstawowych kontroli kondycji.
Często zadawane pytania
- Czy usługa Traffic Manager jest odporna na błędy regionów świadczenia usługi Azure?
- W jaki sposób wybór lokalizacji grupy zasobów wpływa na usługę Traffic Manager?
- Jak mogę określić bieżącą kondycję każdego punktu końcowego?
- Czy mogę monitorować punkty końcowe HTTPS?
- Czy używam adresu IP lub nazwy DNS podczas dodawania punktu końcowego?
- Jakiego typu adresy IP można używać podczas dodawania punktu końcowego?
- Czy mogę używać różnych typów adresowania punktów końcowych w ramach jednego profilu?
- Co się stanie, gdy typ rekordu zapytania przychodzącego różni się od typu rekordu skojarzonego z typem adresowania punktów końcowych?
- Czy mogę użyć profilu z punktami końcowymi adresowanymi przez IPv4/IPv6 w profilu zagnieżdżonym?
- Zatrzymałem punkt końcowy aplikacji internetowej w moim profilu Traffic Manager, ale nie otrzymuję żadnego ruchu, nawet po ponownym uruchomieniu aplikacji. Jak rozwiązać ten problem?
- Czy mogę używać usługi Traffic Manager, nawet jeśli moja aplikacja nie ma obsługi protokołu HTTP lub HTTPS?
- Jakie konkretne odpowiedzi są wymagane z punktu końcowego podczas korzystania z monitorowania TCP?
- Jak szybko usługa Traffic Manager przenosi użytkowników z punktu końcowego w złej kondycji?
- Jak określić różne ustawienia monitorowania dla różnych punktów końcowych w profilu?
- Jak przypisać nagłówki HTTP do kontroli kondycji usługi Traffic Manager dotyczących moich punktów końcowych?
- Jakiego nagłówka hosta używają testy kondycji punktu końcowego?
- Jakie są adresy IP, z których pochodzą kontrole kondycji?
- Ile kontroli kondycji punktu końcowego mogę oczekiwać od usługi Traffic Manager?
- Jak otrzymywać powiadomienia, jeśli jeden z moich punktów końcowych ulegnie awarii?
Następne kroki
- Dowiedz się , jak działa usługa Traffic Manager
- Dowiedz się więcej o metodach routingu ruchu obsługiwanych przez usługę Traffic Manager
- Dowiedz się, jak utworzyć profil usługi Traffic Manager
- Rozwiązywanie problemów ze stanem 'Degraded' na punkcie końcowym Traffic Managera