Azure Metadata Service: Scheduled Events for Linux VMs (usługa podrzędna Scheduled Events dla maszyn wirtualnych z systemem Linux)
Dotyczy: ✔️ Maszyny wirtualne z systemem Linux — elastyczne zestawy ✔️ ✔️ skalowania jednolite zestawy skalowania
Usługa Scheduled Events to usługa podrzędna usługi Azure Metadata Service, która zapewnia aplikacji czas na przygotowanie się do konserwacji maszyny wirtualnej. Udostępnia informacje o nadchodzących zdarzeniach konserwacji (na przykład ponownym rozruchu), dzięki czemu aplikacja może przygotować się do nich i ograniczyć przerwy w działaniu. Jest dostępna dla wszystkich typów usługi Azure Virtual Machines, w tym PaaS i IaaS, zarówno w systemie Windows, jak i Linux.
Aby uzyskać informacje o zaplanowanych zdarzeniach w systemie Windows, zobacz Zaplanowane zdarzenia dla maszyn wirtualnych z systemem Windows.
Zaplanowane zdarzenia zapewniają proaktywne powiadomienia dotyczące nadchodzących zdarzeń, aby uzyskać reaktywne informacje o zdarzeniach, które już wystąpiły, zobacz informacje o dostępności maszyny wirtualnej w usłudze Azure Resource Graph i Utwórz regułę alertu dotyczącego dostępności dla maszyny wirtualnej platformy Azure.
Uwaga
Zaplanowane zdarzenia są ogólnie dostępne we wszystkich regionach świadczenia usługi Azure. Zobacz Dostępność wersji i regionu , aby uzyskać najnowsze informacje o wersji.
Dlaczego warto używać zaplanowanych zdarzeń?
Wiele aplikacji może czerpać korzyści z czasu na przygotowanie się do konserwacji maszyny wirtualnej. Czas może służyć do wykonywania zadań specyficznych dla aplikacji, które zwiększają dostępność, niezawodność i możliwości obsługi, w tym:
- Tworzenie punktu kontrolnego i przywracanie.
- Opróżnianie połączenia.
- Przełączanie repliki podstawowej w tryb failover.
- Usuwanie z puli modułu równoważenia obciążenia.
- Rejestrowanie zdarzeń.
- Bezpieczne zamknięcie.
Dzięki usłudze Scheduled Events aplikacja może wykryć, kiedy nastąpi konserwacja, i wyzwolić zadania, aby ograniczyć jej wpływ.
Usługa Scheduled Events udostępnia zdarzenia w następujących przypadkach użycia:
- Zainicjowana konserwacja platformy (na przykład ponowne uruchomienie maszyny wirtualnej, migracja na żywo lub ochrona pamięci dla hosta).
- Maszyna wirtualna działa na obniżonej wydajności sprzętu hosta, który wkrótce się nie powiedzie.
- Maszyna wirtualna była uruchomiona na hoście, który doznał awarii sprzętu.
- Konserwacja zainicjowana przez użytkownika (na przykład ponowne uruchomienie lub ponowne wdrożenie maszyny wirtualnej przez użytkownika).
- Wykluczenia wystąpień maszyn wirtualnych typu spot i zestawów skalowania maszyn wirtualnych typu spot.
Podstawy
Usługa Metadata Service udostępnia informacje o uruchamianiu maszyn wirtualnych przy użyciu punktu końcowego REST dostępnego z poziomu maszyny wirtualnej. Te informacje są dostępne za pośrednictwem niekondacyjnego adresu IP i nie są uwidocznione poza maszyną wirtualną.
Scope
Zaplanowane zdarzenia są dostarczane i mogą być potwierdzane przez:
- Autonomiczne maszyny wirtualne.
- Wszystkie maszyny wirtualne w usłudze w chmurze platformy Azure (wersja klasyczna)
- Wszystkie maszyny wirtualne w zestawie dostępności.
- Wszystkie maszyny wirtualne w grupie umieszczania zestawu skalowania.
Zaplanowane zdarzenia dla wszystkich maszyn wirtualnych w całym zestawie dostępności lub grupie umieszczania dla zestawu skalowania maszyn wirtualnych są dostarczane do wszystkich innych maszyn wirtualnych w tej samej grupie lub ustawionej niezależnie od użycia strefy dostępności.
W związku z tym sprawdź Resources pole w zdarzeniu, aby określić, na które maszyny wirtualne mają wpływ.
Uwaga
Maszyny wirtualne przyspieszone przez procesor GPU w zestawie skalowania przy użyciu domeny błędów 1 (FD = 1) będą otrzymywać tylko zaplanowane zdarzenia dla zasobu, na który ma to wpływ. Zdarzenia nie będą emitowane do wszystkich maszyn wirtualnych w tej samej grupie umieszczania.
Odnajdywanie punktów końcowych
W przypadku maszyn wirtualnych z włączoną siecią wirtualną usługa metadanych jest dostępna na podstawie statycznego niekondycyjnego adresu IP, 169.254.169.254. Pełny punkt końcowy dla najnowszej wersji zaplanowanych zdarzeń to:
http://169.254.169.254/metadata/scheduledevents?api-version=2020-07-01
Jeśli maszyna wirtualna nie została utworzona w ramach sieci wirtualnej, domyślne przypadki usług w chmurze i klasycznych maszyn wirtualnych wymagają dodatkowej logiki w celu odnalezienia adresu IP do użycia. Aby dowiedzieć się, jak odnaleźć punkt końcowy hosta, zobacz ten przykład.
Dostępność wersji i regionu
Usługa Zaplanowane zdarzenia jest wersjonowana. Wersje są obowiązkowe; bieżąca wersja to 2020-07-01.
| Wersja | Typy wycieków | Regiony | Informacje o wersji |
|---|---|---|---|
| 2020-07-01 | Ogólna dostępność | wszystkie | |
| 2019-08-01 | Ogólna dostępność | wszystkie | |
| 2019-04-01 | Ogólna dostępność | wszystkie | |
| 2019-01-01 | Ogólna dostępność | wszystkie | |
| 2017-11-01 | Ogólna dostępność | wszystkie | |
| 2017-08-01 | Ogólna dostępność | wszystkie | |
| 2017-03-01 | Podgląd | wszystkie |
Uwaga
Poprzednie wersje zapoznawcza zdarzeń zaplanowanych obsługiwane przez użytkownika {latest} jako wersja interfejsu API. Ten format nie jest już obsługiwany i będzie przestarzały w przyszłości.
Włączanie i wyłączanie zaplanowanych zdarzeń
Zaplanowane zdarzenia są włączone dla usługi przy pierwszym żądaniu zdarzeń. Należy oczekiwać opóźnionej odpowiedzi w pierwszym wywołaniu do dwóch minut i rozpoczniesz odbieranie zdarzeń w ciągu 5 minut. Zaplanowane zdarzenia są wyłączone dla usługi, jeśli nie wysyła żądania do punktu końcowego przez 24 godziny.
Konserwacja inicjowana przez użytkownika
Konserwacja maszyny wirtualnej zainicjowana przez użytkownika za pośrednictwem witryny Azure Portal, interfejsu API, interfejsu wiersza polecenia lub programu PowerShell powoduje wystąpienie zaplanowanego zdarzenia. Następnie można przetestować logikę przygotowywania konserwacji w aplikacji, a aplikacja może przygotować się do konserwacji zainicjowanej przez użytkownika.
Jeśli uruchomisz ponownie maszynę wirtualną, zaplanowane jest zdarzenie o typie Reboot . Jeśli ponownie wdrożysz maszynę wirtualną, zaplanowane jest zdarzenie o typie Redeploy . Zazwyczaj zdarzenia ze źródłem zdarzeń użytkownika można natychmiast zatwierdzić, aby uniknąć opóźnień w akcjach inicjowanych przez użytkownika. Zalecamy komunikację podstawowej i pomocniczej maszyny wirtualnej oraz zatwierdzanie zaplanowanych zdarzeń generowanych przez użytkownika w przypadku, gdy podstawowa maszyna wirtualna przestanie odpowiadać. Natychmiastowe zatwierdzanie zdarzeń zapobiega opóźnieniom odzyskiwania aplikacji z powrotem do dobrego stanu.
Zaplanowane zdarzenia dla uaktualnień systemu operacyjnego gościa lub obrazów systemu operacyjnego gościa zestawów skalowania maszyn wirtualnych ogólnego przeznaczenia są obsługiwane w przypadku rozmiarów maszyn wirtualnych ogólnego przeznaczenia, które obsługują tylko zachowywanie aktualizacji w pamięci. Nie działa w przypadku serii G, M, N i H. Zaplanowane zdarzenia dotyczące uaktualnień systemu operacyjnego gościa zestawów skalowania maszyn wirtualnych i obrazów są domyślnie wyłączone. Aby włączyć zaplanowane zdarzenia dla tych operacji na obsługiwanych rozmiarach maszyn wirtualnych, najpierw włącz je przy użyciu pliku OSImageNotificationProfile.
Używanie interfejsu API
Omówienie wysokiego poziomu
Istnieją dwa główne składniki do obsługi zaplanowanych zdarzeń, przygotowania i odzyskiwania. Wszystkie bieżące zaplanowane zdarzenia wpływające na maszynę wirtualną są dostępne do odczytu za pośrednictwem punktu końcowego zaplanowanych zdarzeń USŁUGI IMDS. Po osiągnięciu stanu terminalu zdarzenie zostanie usunięte z listy zdarzeń. Na poniższym diagramie przedstawiono różne przejścia stanu, które może wystąpić pojedyncze zaplanowane zdarzenie:
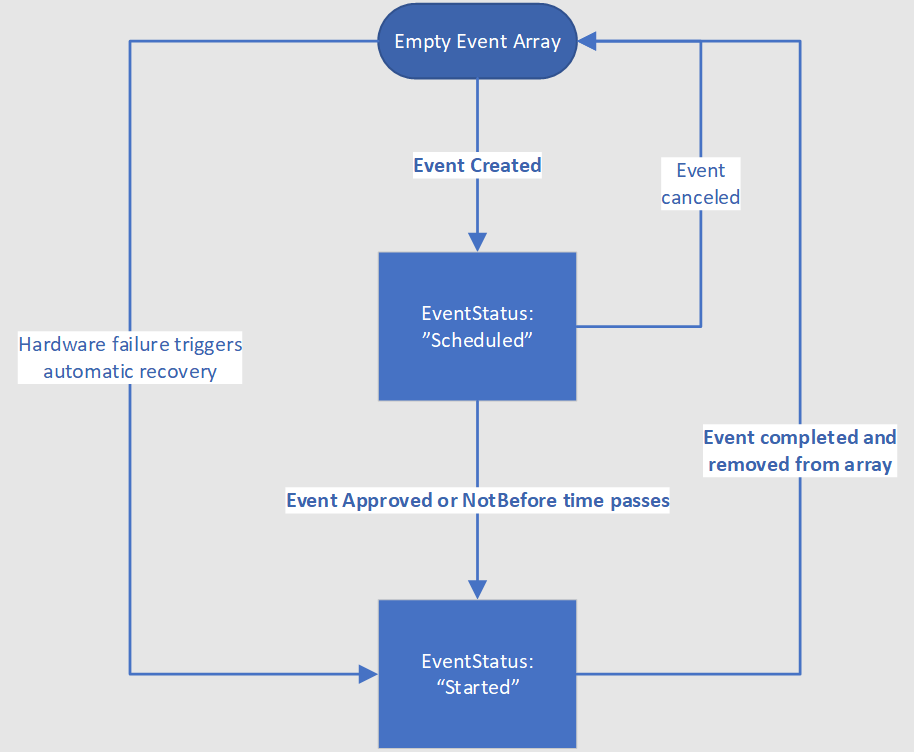
W przypadku zdarzeń w stanie EventStatus:"Scheduled" należy wykonać kroki w celu przygotowania obciążenia. Po zakończeniu przygotowania należy zatwierdzić zdarzenie przy użyciu interfejsu API zaplanowanego zdarzenia. W przeciwnym razie zdarzenie zostanie automatycznie zatwierdzone po osiągnięciu czasu NotBefore. Jeśli maszyna wirtualna znajduje się w udostępnionej infrastrukturze, system będzie czekać na wszystkich innych dzierżawców na tym samym sprzęcie, aby również zatwierdzić zadanie lub przekroczenie limitu czasu. Po zebraniu zatwierdzeń ze wszystkich maszyn wirtualnych, których to dotyczy, lub czasu NotBefore zostanie osiągnięty, platforma Azure wygeneruje nowy zaplanowany ładunek zdarzeń z zdarzeniem EventStatus:"Started" i wyzwala rozpoczęcie zdarzenia konserwacji. Po osiągnięciu stanu terminalu zdarzenie zostanie usunięte z listy zdarzeń. Służy to jako sygnał dla klienta w celu odzyskania maszyn wirtualnych.
Poniżej znajduje się kod psudeo demonstrujący proces odczytywania zaplanowanych zdarzeń w aplikacji i zarządzania nimi:
current_list_of_scheduled_events = get_latest_from_se_endpoint()
#prepare for new events
for each event in current_list_of_scheduled_events:
if event not in previous_list_of_scheduled_events:
prepare_for_event(event)
#recover from completed events
for each event in previous_list_of_scheduled_events:
if event not in current_list_of_scheduled_events:
receover_from_event(event)
#prepare for future jobs
previous_list_of_scheduled_events = current_list_of_scheduled_events
Ponieważ zaplanowane zdarzenia są często używane dla aplikacji z wymaganiami dotyczącymi wysokiej dostępności, istnieje kilka wyjątkowych przypadków, które należy wziąć pod uwagę:
- Po zakończeniu zaplanowanego zdarzenia i usunięciu z tablicy nie będzie żadnych dalszych skutków bez nowego zdarzenia, w tym innego zdarzenia EventStatus:"Scheduled"
- Platforma Azure monitoruje operacje konserwacji całej floty i w rzadkich okolicznościach określa, że operacja konserwacji jest zbyt wysokie, aby zastosować. W takim przypadku zaplanowane zdarzenie przejdzie bezpośrednio z "Zaplanowane" do usunięcia z tablicy zdarzeń
- W przypadku awarii sprzętu platforma Azure pomija stan "Zaplanowane" i natychmiast przechodzi do stanu EventStatus:"Started".
- Mimo że zdarzenie jest nadal w stanie EventStatus:"Started", może istnieć inny wpływ krótszy czas trwania niż to, co zostało anonsowane w zaplanowanym zdarzeniu.
W ramach gwarancji dostępności platformy Azure maszyny wirtualne w różnych domenach błędów nie będą mieć wpływu na rutynowe operacje konserwacji w tym samym czasie. Jednak mogą one mieć operacje serializowane jeden po drugim. Maszyny wirtualne w jednej domenie błędów mogą odbierać zaplanowane zdarzenia z zdarzeniem EventStatus:"Scheduled" wkrótce po zakończeniu konserwacji innej domeny błędów. Niezależnie od wybranej architektury zawsze sprawdzaj, czy nowe zdarzenia oczekują na maszyny wirtualne.
Mimo że dokładne chronometraż zdarzeń różnią się, na poniższym diagramie przedstawiono przybliżone wskazówki dotyczące tego, jak przebiega typowa operacja konserwacji:
- EventStatus:"Scheduled" do limitu czasu zatwierdzenia: 15 minut
- Czas trwania wpływu: 7 sekund
- EventStatus:"Started" to Completed (zdarzenie usunięte z tablicy zdarzeń): 10 minut
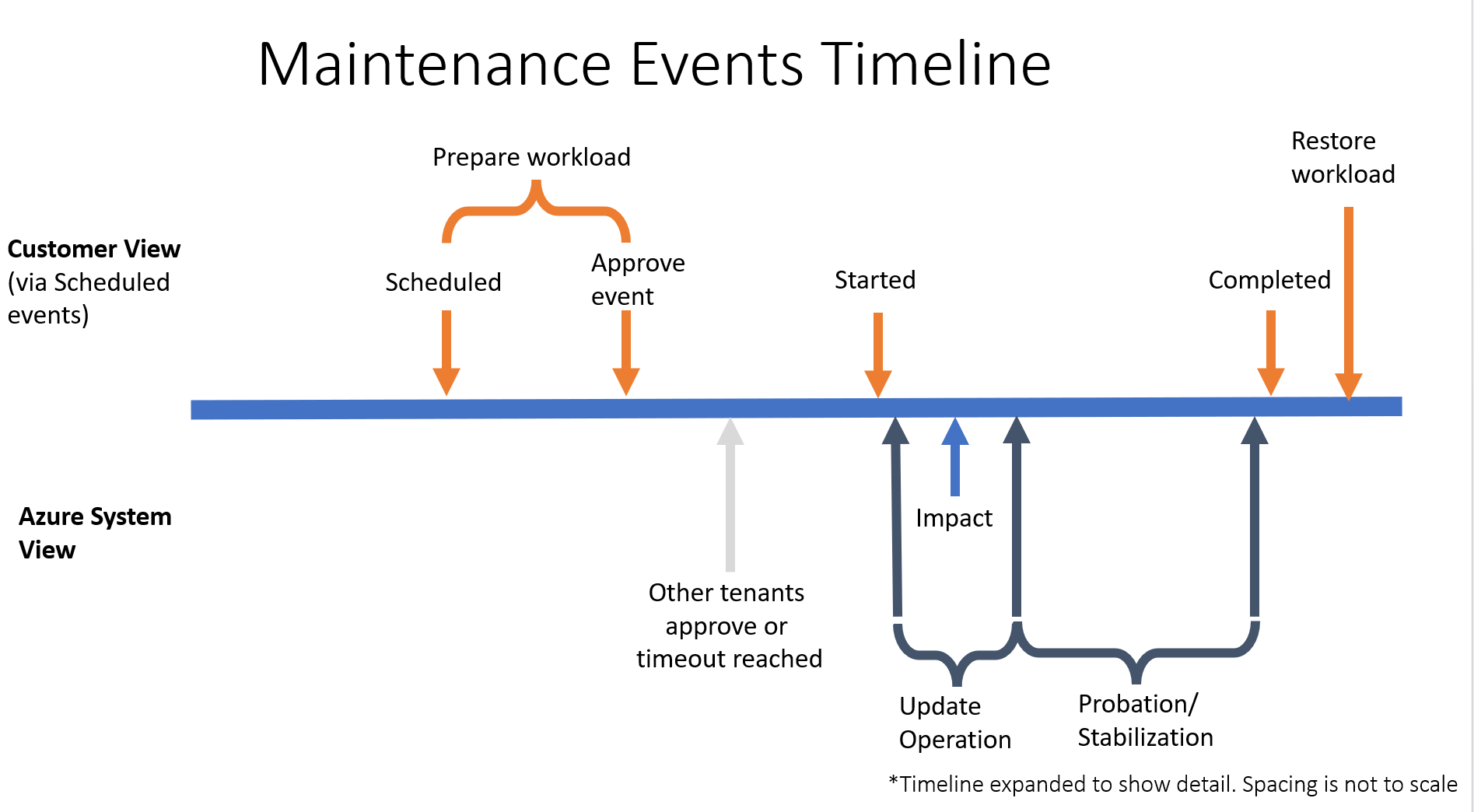
Wszystkie operacje wpływające na dostępność maszyny wirtualnej spowodują zaplanowane zdarzenie, jednak nie wszystkie zaplanowane zdarzenia będą wyświetlane na innych powierzchniach platformy Azure, takich jak dzienniki aktywności platformy Azure lub kondycja zasobów. Regularne sprawdzanie zaplanowanych zdarzeń zapewni, że masz najbardziej aktualne informacje o nadchodzących wpływach na maszyny wirtualne.
Nagłówki
Podczas wykonywania zapytania w usłudze Metadata Service należy podać nagłówek Metadata:true , aby upewnić się, że żądanie nie zostało przypadkowo przekierowane. Nagłówek Metadata:true jest wymagany dla wszystkich żądań zaplanowanych zdarzeń. Niepowodzenie uwzględnienia nagłówka w żądaniu powoduje zwrócenie odpowiedzi "Nieprawidłowe żądanie" z usługi Metadata Service.
Wykonywanie zapytań dotyczących zdarzeń
Możesz wykonywać zapytania dotyczące zaplanowanych zdarzeń, wykonując następujące wywołanie:
Przykład powłoki Bash
curl -H Metadata:true http://169.254.169.254/metadata/scheduledevents?api-version=2020-07-01
Przykładowy skrypt programu PowerShell
Invoke-RestMethod -Headers @{"Metadata"="true"} -Method GET -Uri "http://169.254.169.254/metadata/scheduledevents?api-version=2020-07-01" | ConvertTo-Json -Depth 64
Przykład języka Python
import json
import requests
metadata_url ="http://169.254.169.254/metadata/scheduledevents"
header = {'Metadata' : 'true'}
query_params = {'api-version':'2020-07-01'}
def get_scheduled_events():
resp = requests.get(metadata_url, headers = header, params = query_params)
data = resp.json()
return data
Odpowiedź zawiera tablicę zaplanowanych zdarzeń. Pusta tablica oznacza, że obecnie nie zaplanowano żadnych zdarzeń. W przypadku wystąpienia zaplanowanych zdarzeń odpowiedź zawiera tablicę zdarzeń.
{
"DocumentIncarnation": {IncarnationID},
"Events": [
{
"EventId": {eventID},
"EventType": "Reboot" | "Redeploy" | "Freeze" | "Preempt" | "Terminate",
"ResourceType": "VirtualMachine",
"Resources": [{resourceName}],
"EventStatus": "Scheduled" | "Started",
"NotBefore": {timeInUTC},
"Description": {eventDescription},
"EventSource" : "Platform" | "User",
"DurationInSeconds" : {timeInSeconds},
}
]
}
Właściwości zdarzenia
| Właściwości | opis |
|---|---|
| Wcielenie dokumentu | Liczba całkowita, która zwiększa się, gdy tablica zdarzeń zmienia się. Dokumenty z tym samym wcieleniem zawierają te same informacje o zdarzeniu, a wcielenie będzie zwiększane po zmianie zdarzenia. |
| EventId | Unikatowy identyfikator globalny dla tego zdarzenia. Przykład:
|
| EventType | Wpływ na to zdarzenie powoduje. Wartości:
|
| ResourceType | Typ zasobu, na który wpływa to zdarzenie. Wartości:
|
| Zasoby | Lista zasobów, które ma to wpływ na to zdarzenie. Przykład:
|
| EventStatus | Stan tego zdarzenia. Wartości:
Completed podano żadnego lub podobnego stanu. Zdarzenie nie jest już zwracane po zakończeniu zdarzenia. |
| Nie wcześniej niż | Godzina rozpoczęcia tego zdarzenia. Zdarzenie nie zostanie uruchomione przed tym czasem. Jeśli zdarzenie zostało już uruchomione, będzie puste Przykład:
|
| opis | Opis tego zdarzenia. Przykład:
|
| EventSource | Inicjator zdarzenia. Przykład:
|
| DurationInSeconds | Oczekiwany czas trwania przerwy spowodowanej przez zdarzenie. Może istnieć pomocniczy wpływ krótszego czasu trwania w oknie wpływu. Przykład:
|
Planowanie zdarzeń
Każde zdarzenie jest zaplanowane przez minimalny czas w przyszłości na podstawie typu zdarzenia. Tym razem jest odzwierciedlana we właściwości zdarzenia NotBefore .
| EventType | Powiadomienie minimalne |
|---|---|
| Zamrożenie | 15 min |
| Ponowne uruchamianie | 15 min |
| Wdróż ponownie | 10 min |
| Zakończ zatrudnienie | Konfigurowalny przez użytkownika: od 5 do 15 minut |
Oznacza to, że można wykryć przyszły harmonogram zdarzenia co najmniej o minimalny czas powiadomienia przed wystąpieniem zdarzenia. Po zaplanowaniu zdarzenia zostanie ono przeniesione do Started stanu po jego zatwierdzeniu lub upływie NotBefore czasu. Jednak w rzadkich przypadkach operacja zostanie anulowana przez platformę Azure przed rozpoczęciem. W takim przypadku zdarzenie zostanie usunięte z tablicy Zdarzenia, a wpływ nie wystąpi zgodnie z wcześniejszym harmonogramem.
Uwaga
W niektórych przypadkach platforma Azure może przewidzieć awarię hosta z powodu obniżonej wydajności sprzętu i podejmie próbę ograniczenia zakłóceń w usłudze przez zaplanowanie migracji. Maszyny wirtualne, których dotyczy problem, otrzymają zaplanowane zdarzenie z zdarzeniem NotBefore , które zwykle trwa kilka dni w przyszłości. Rzeczywisty czas różni się w zależności od przewidywanej oceny ryzyka awarii. Platforma Azure próbuje powiadomić o 7 dniach z wyprzedzeniem, gdy jest to możliwe, ale rzeczywisty czas jest różny i może być mniejszy, jeśli przewidywanie oznacza, że istnieje duże prawdopodobieństwo nieuchronnego niepowodzenia sprzętu. Aby zminimalizować ryzyko związane z usługą w przypadku awarii sprzętu przed migracją zainicjowaną przez system, zalecamy jak najszybsze ponowne wdrożenie maszyny wirtualnej.
Uwaga
W przypadku wystąpienia awarii węzła hosta platforma Azure pominą minimalny okres powiadomienia o natychmiastowym rozpoczęciu procesu odzyskiwania dla maszyn wirtualnych, których dotyczy problem. Skraca to czas odzyskiwania w przypadku, gdy maszyny wirtualne, których dotyczy problem, nie mogą odpowiedzieć. Podczas procesu odzyskiwania zostanie utworzone zdarzenie dla wszystkich maszyn wirtualnych, których dotyczy ten wpływ, z elementami EventType = Reboot i EventStatus = Started.
Częstotliwość sondowania
Punkt końcowy można sondować pod kątem aktualizacji tak często lub rzadko, jak chcesz. Jednak dłuższy czas między żądaniami, tym więcej czasu potencjalnie tracisz, aby reagować na nadchodzące zdarzenie. Większość zdarzeń ma od 5 do 15 minut powiadomienia z wyprzedzeniem, chociaż w niektórych przypadkach powiadomienie z wyprzedzeniem może być nawet 30 sekund. Aby upewnić się, że masz jak najwięcej czasu na podjęcie działań korygujących, zalecamy sondowanie usługi raz na sekundę.
Uruchamianie zdarzenia
Po zapoznaniu się z nadchodzącym wydarzeniem i zakończeniu logiki bezpiecznego zamykania możesz zatwierdzić zaległe zdarzenie, wywołując usługę POST Metadata Service za pomocą polecenia EventId. To wywołanie wskazuje na platformę Azure, że może skrócić minimalny czas powiadomienia (jeśli to możliwe). Zdarzenie może nie rozpoczynać się natychmiast po zatwierdzeniu, w niektórych przypadkach platforma Azure wymaga zatwierdzenia wszystkich maszyn wirtualnych hostowanych w węźle przed kontynuowaniem zdarzenia.
W treści żądania oczekiwano następującego przykładu POST JSON. Żądanie powinno zawierać listę StartRequests. Każda StartRequest z nich zawiera EventId zdarzenie, które chcesz przyspieszyć:
{
"StartRequests" : [
{
"EventId": {EventId}
}
]
}
Usługa zawsze zwraca kod powodzenia 200, jeśli został przekazany prawidłowy identyfikator zdarzenia, nawet jeśli inna maszyna wirtualna już zatwierdziła zdarzenie. Kod błędu 400 wskazuje, że nagłówek lub ładunek żądania został źle sformułowany.
Uwaga
Zdarzenia nie będą kontynuowane, chyba że zostaną zatwierdzone za pośrednictwem komunikatu POST lub czasu NotBefore upłynie. Obejmuje to zdarzenia wyzwalane przez użytkownika, takie jak ponowne uruchomienia maszyny wirtualnej w witrynie Azure Portal.
Przykład powłoki Bash
curl -H Metadata:true -X POST -d '{"StartRequests": [{"EventId": "f020ba2e-3bc0-4c40-a10b-86575a9eabd5"}]}' http://169.254.169.254/metadata/scheduledevents?api-version=2020-07-01
Przykładowy skrypt programu PowerShell
Invoke-RestMethod -Headers @{"Metadata" = "true"} -Method POST -body '{"StartRequests": [{"EventId": "5DD55B64-45AD-49D3-BBC9-F57D4EA97BD7"}]}' -Uri http://169.254.169.254/metadata/scheduledevents?api-version=2020-07-01 | ConvertTo-Json -Depth 64
Przykład języka Python
import json
import requests
def confirm_scheduled_event(event_id):
# This payload confirms a single event with id event_id
payload = json.dumps({"StartRequests": [{"EventId": event_id }]})
response = requests.post("http://169.254.169.254/metadata/scheduledevents",
headers = {'Metadata' : 'true'},
params = {'api-version':'2020-07-01'},
data = payload)
return response.status_code
Uwaga
Potwierdzenie zdarzenia umożliwia kontynuowanie zdarzenia dla wszystkich Resources zdarzeń, a nie tylko maszyny wirtualnej, która potwierdza zdarzenie. W związku z tym możesz wybrać lidera, aby koordynować potwierdzenie, co może być tak proste, jak pierwsza maszyna w Resources polu.
Przykładowe odpowiedzi
Następujące zdarzenia to przykład, który był widziany przez dwie maszyny wirtualne, które zostały na żywo zmigrowane do innego węzła.
Funkcja DocumentIncarnation zmienia się za każdym razem, gdy w pliku znajdują się nowe informacje.Events Zatwierdzenie zdarzenia pozwoliłoby na kontynuowanie blokowania zarówno dla WestNO_0, jak i WestNO_1. Wartość DurationInSeconds -1 wskazuje, że platforma nie wie, jak długo potrwa operacja.
{
"DocumentIncarnation": 1,
"Events": [
]
}
{
"DocumentIncarnation": 2,
"Events": [
{
"EventId": "C7061BAC-AFDC-4513-B24B-AA5F13A16123",
"EventStatus": "Scheduled",
"EventType": "Freeze",
"ResourceType": "VirtualMachine",
"Resources": [
"WestNO_0",
"WestNO_1"
],
"NotBefore": "Mon, 11 Apr 2022 22:26:58 GMT",
"Description": "Virtual machine is being paused because of a memory-preserving Live Migration operation.",
"EventSource": "Platform",
"DurationInSeconds": 5
}
]
}
{
"DocumentIncarnation": 3,
"Events": [
{
"EventId": "C7061BAC-AFDC-4513-B24B-AA5F13A16123",
"EventStatus": "Started",
"EventType": "Freeze",
"ResourceType": "VirtualMachine",
"Resources": [
"WestNO_0",
"WestNO_1"
],
"NotBefore": "",
"Description": "Virtual machine is being paused because of a memory-preserving Live Migration operation.",
"EventSource": "Platform",
"DurationInSeconds": 5
}
]
}
{
"DocumentIncarnation": 4,
"Events": [
]
}
Przykład języka Python
Następujące przykładowe zapytania usługi Metadata Service dotyczące zaplanowanych zdarzeń i zatwierdza każde zaległe zdarzenie:
#!/usr/bin/python
import json
import requests
from time import sleep
# The URL to access the metadata service
metadata_url ="http://169.254.169.254/metadata/scheduledevents"
# This must be sent otherwise the request will be ignored
header = {'Metadata' : 'true'}
# Current version of the API
query_params = {'api-version':'2020-07-01'}
def get_scheduled_events():
resp = requests.get(metadata_url, headers = header, params = query_params)
data = resp.json()
return data
def confirm_scheduled_event(event_id):
# This payload confirms a single event with id event_id
# You can confirm multiple events in a single request if needed
payload = json.dumps({"StartRequests": [{"EventId": event_id }]})
response = requests.post(metadata_url,
headers= header,
params = query_params,
data = payload)
return response.status_code
def log(event):
# This is an optional placeholder for logging events to your system
print(event["Description"])
return
def advanced_sample(last_document_incarnation):
# Poll every second to see if there are new scheduled events to process
# Since some events may have necessarily short warning periods, it is
# recommended to poll frequently
found_document_incarnation = last_document_incarnation
while (last_document_incarnation == found_document_incarnation):
sleep(1)
payload = get_scheduled_events()
found_document_incarnation = payload["DocumentIncarnation"]
# We recommend processing all events in a document together,
# even if you won't be actioning on them right away
for event in payload["Events"]:
# Events that have already started, logged for tracking
if (event["EventStatus"] == "Started"):
log(event)
# Approve all user initiated events. These are typically created by an
# administrator and approving them immediately can help to avoid delays
# in admin actions
elif (event["EventSource"] == "User"):
confirm_scheduled_event(event["EventId"])
# For this application, freeze events less that 9 seconds are considered
# no impact. This will immediately approve them
elif (event["EventType"] == "Freeze" and
int(event["DurationInSeconds"]) >= 0 and
int(event["DurationInSeconds"]) < 9):
confirm_scheduled_event(event["EventId"])
# Events that may be impactful (for example, reboot or redeploy) may need custom
# handling for your application
else:
#TODO Custom handling for impactful events
log(event)
print("Processed events from document: " + str(found_document_incarnation))
return found_document_incarnation
def main():
# This will track the last set of events seen
last_document_incarnation = "-1"
input_text = "\
Press 1 to poll for new events \n\
Press 2 to exit \n "
program_exit = False
while program_exit == False:
user_input = input(input_text)
if (user_input == "1"):
last_document_incarnation = advanced_sample(last_document_incarnation)
elif (user_input == "2"):
program_exit = True
if __name__ == '__main__':
main()
Następne kroki
- Zapoznaj się z przykładami kodu zaplanowanych zdarzeń w repozytorium GitHub zaplanowanych zdarzeń wystąpienia platformy Azure.
- Zapoznaj się z przykładami kodu zaplanowanych zdarzeń Node.js w repozytorium GitHub Przykłady platformy Azure.
- Przeczytaj więcej na temat interfejsów API, które są dostępne w usłudze metadanych wystąpienia.
- Dowiedz się więcej o planowanej konserwacji maszyn wirtualnych z systemem Linux na platformie Azure.
- Dowiedz się, jak rejestrować zaplanowane zdarzenia przy użyciu usługi Azure Event Hubs w repozytorium GitHub przykładów platformy Azure.