Wysoka dostępność oprogramowania SAP HANA na maszynach wirtualnych platformy Azure w systemie Red Hat Enterprise Linux
W przypadku programowania lokalnego można użyć replikacji systemu HANA lub magazynu udostępnionego w celu ustanowienia wysokiej dostępności dla platformy SAP HANA. W usłudze Azure Virtual Machines replikacja systemu HANA na platformie Azure jest obecnie jedyną obsługiwaną funkcją wysokiej dostępności.
Replikacja SAP HANA składa się z jednego węzła podstawowego i co najmniej jednego węzła pomocniczego. Zmiany danych w węźle podstawowym są replikowane synchronicznie lub asynchronicznie do węzła pomocniczego.
W tym artykule opisano sposób wdrażania i konfigurowania maszyn wirtualnych, instalowania struktury klastra oraz instalowania i konfigurowania replikacji systemu SAP HANA.
W przykładowych konfiguracjach używane są polecenia instalacji, numer wystąpienia 03 i identyfikator systemu HANA HN1 .
Wymagania wstępne
Najpierw przeczytaj następujące uwagi i dokumenty SAP:
- 1928533 sap Note, które mają następujące elementy:
- Lista rozmiarów maszyn wirtualnych platformy Azure obsługiwanych na potrzeby wdrażania oprogramowania SAP.
- Ważne informacje o pojemności dla rozmiarów maszyn wirtualnych platformy Azure.
- Obsługiwane kombinacje oprogramowania SAP i systemu operacyjnego (OS) i bazy danych.
- Wymagana wersja jądra SAP dla systemów Windows i Linux na platformie Microsoft Azure.
- Program SAP Note 2015553 zawiera listę wymagań wstępnych dotyczących wdrożeń oprogramowania SAP obsługiwanych przez oprogramowanie SAP na platformie Azure.
- Program SAP Note 2002167 ma zalecane ustawienia systemu operacyjnego dla systemu Red Hat Enterprise Linux.
- Oprogramowanie SAP Note 2009879 zawiera wytyczne dotyczące oprogramowania SAP HANA dla systemu Red Hat Enterprise Linux.
- Program SAP Note 3108302 zawiera wytyczne dotyczące oprogramowania SAP HANA dla systemu Red Hat Enterprise Linux 9.x.
- Program SAP Note 2178632 zawiera szczegółowe informacje o wszystkich metrykach monitorowania zgłoszonych dla oprogramowania SAP na platformie Azure.
- Program SAP Note 2191498 ma wymaganą wersję agenta hosta SAP dla systemu Linux na platformie Azure.
- Program SAP Note 2243692 zawiera informacje o licencjonowaniu oprogramowania SAP w systemie Linux na platformie Azure.
- Program SAP Note 1999351 zawiera więcej informacji dotyczących rozwiązywania problemów z rozszerzeniem rozszerzonego monitorowania platformy Azure dla oprogramowania SAP.
- Witryna WIKI sap Community zawiera wszystkie wymagane uwagi SAP dla systemu Linux.
- Planowanie i implementacja usługi Azure Virtual Machines dla oprogramowania SAP w systemie Linux
- Wdrażanie usługi Azure Virtual Machines dla oprogramowania SAP w systemie Linux (ten artykuł)
- Wdrażanie systemu SAP w systemie Linux w usłudze Azure Virtual Machines DBMS
- Replikacja systemu SAP HANA w klastrze Pacemaker
- Ogólna dokumentacja systemu RHEL:
- Dokumentacja systemu RHEL specyficzna dla platformy Azure:
- Zasady obsługi klastrów wysokiej dostępności RHEL — Maszyny wirtualne platformy Microsoft Azure jako elementy członkowskie klastra
- Instalowanie i konfigurowanie klastra wysokiej dostępności systemu Red Hat Enterprise Linux 7.4 (i nowszych) na platformie Microsoft Azure
- Instalowanie oprogramowania SAP HANA w systemie Red Hat Enterprise Linux do użycia na platformie Microsoft Azure
Omówienie
Aby uzyskać wysoką dostępność, platforma SAP HANA jest zainstalowana na dwóch maszynach wirtualnych. Dane są replikowane przy użyciu replikacji systemu HANA.
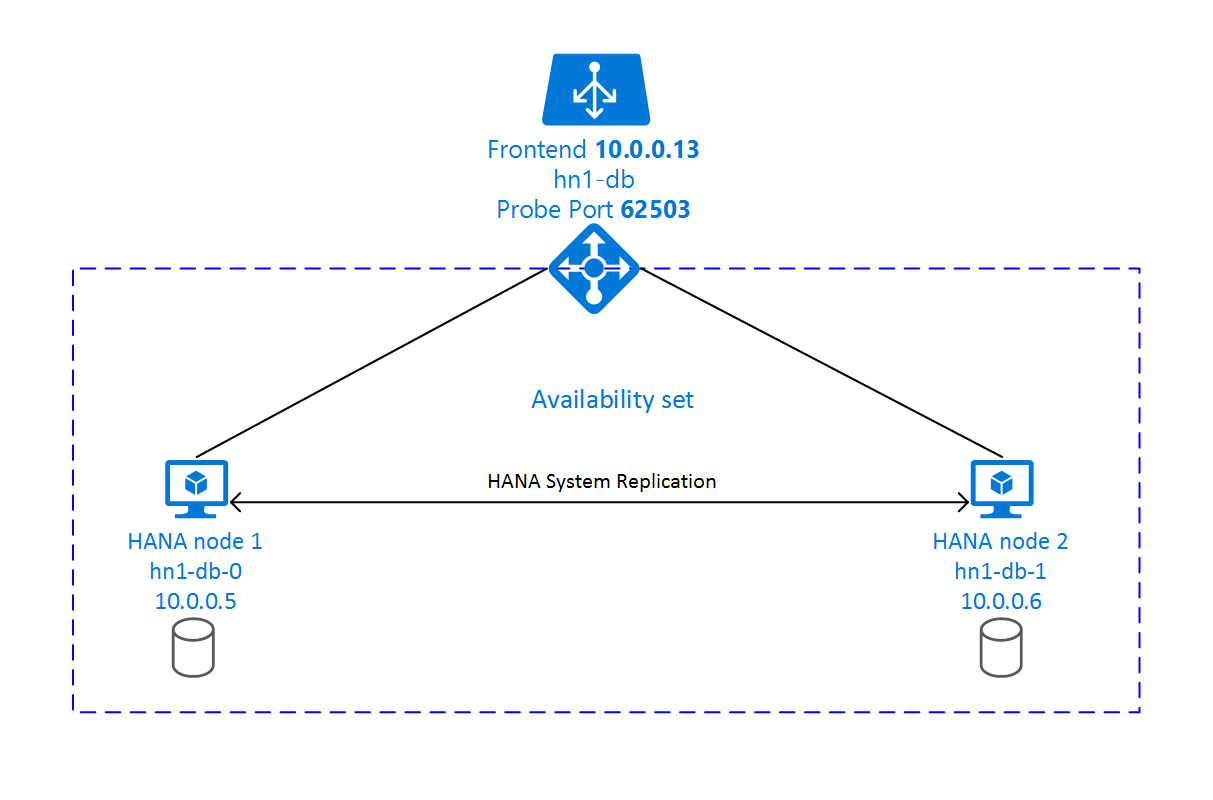
Konfiguracja replikacji systemu SAP HANA używa dedykowanej wirtualnej nazwy hosta i wirtualnych adresów IP. Na platformie Azure moduł równoważenia obciążenia jest wymagany do korzystania z wirtualnego adresu IP. Przedstawiona konfiguracja przedstawia moduł równoważenia obciążenia z:
- Adres IP frontonu: 10.0.0.13 dla hn1-db
- Port sondy: 62503
Przygotowywanie infrastruktury
Witryna Azure Marketplace zawiera obrazy kwalifikowane dla platformy SAP HANA z dodatkiem wysokiej dostępności, którego można użyć do wdrażania nowych maszyn wirtualnych przy użyciu różnych wersji oprogramowania Red Hat.
Ręczne wdrażanie maszyn wirtualnych z systemem Linux za pośrednictwem witryny Azure Portal
W tym dokumencie założono, że grupa zasobów, sieć wirtualna platformy Azure i podsieć zostały już wdrożone.
Wdrażanie maszyn wirtualnych dla platformy SAP HANA. Wybierz odpowiedni obraz systemu RHEL obsługiwany przez system HANA. Maszynę wirtualną można wdrożyć w dowolnej z opcji dostępności: zestawu skalowania maszyn wirtualnych, strefy dostępności lub zestawu dostępności.
Ważne
Upewnij się, że wybrany system operacyjny ma certyfikat SAP dla platformy SAP HANA na określonych typach maszyn wirtualnych, które mają być używane we wdrożeniu. Możesz wyszukać typy maszyn wirtualnych z certyfikatem SAP HANA i ich wersje systemu operacyjnego na platformach IaaS certyfikowanych na platformie SAP HANA. Upewnij się, że zapoznasz się ze szczegółami typu maszyny wirtualnej, aby uzyskać pełną listę wersji systemu operacyjnego obsługiwanych przez platformę SAP HANA dla określonego typu maszyny wirtualnej.
Konfigurowanie modułu równoważenia obciążenia platformy Azure
Podczas konfigurowania maszyny wirtualnej masz możliwość utworzenia lub wybrania wyjścia z modułu równoważenia obciążenia w sekcji dotyczącej sieci. Wykonaj poniższe kroki, aby skonfigurować standardowy moduł równoważenia obciążenia na potrzeby konfiguracji bazy danych HANA o wysokiej dostępności.
Wykonaj kroki opisane w temacie Tworzenie modułu równoważenia obciążenia, aby skonfigurować standardowy moduł równoważenia obciążenia dla systemu SAP o wysokiej dostępności przy użyciu witryny Azure Portal. Podczas konfigurowania modułu równoważenia obciążenia należy wziąć pod uwagę następujące kwestie:
- Konfiguracja adresu IP frontonu: utwórz adres IP frontonu. Wybierz tę samą sieć wirtualną i nazwę podsieci co maszyny wirtualne bazy danych.
- Pula zaplecza: utwórz pulę zaplecza i dodaj maszyny wirtualne bazy danych.
- Reguły ruchu przychodzącego: utwórz regułę równoważenia obciążenia. Wykonaj te same kroki dla obu reguł równoważenia obciążenia.
- Adres IP frontonu: wybierz adres IP frontonu.
- Pula zaplecza: wybierz pulę zaplecza.
- Porty wysokiej dostępności: wybierz tę opcję.
- Protokół: wybierz pozycję TCP.
- Sonda kondycji: utwórz sondę kondycji z następującymi szczegółami:
- Protokół: wybierz pozycję TCP.
- Port: na przykład 625<instance-no.>.
- Interwał: wprowadź wartość 5.
- Próg sondy: wprowadź wartość 2.
- Limit czasu bezczynności (w minutach): wprowadź wartość 30.
- Włącz pływający adres IP: wybierz tę opcję.
Uwaga
Właściwość numberOfProbeskonfiguracji sondy kondycji , inaczej znana jako próg złej kondycji w portalu, nie jest uwzględniana. Aby kontrolować liczbę pomyślnych lub zakończonych niepowodzeniem kolejnych sond, ustaw właściwość probeThreshold na 2wartość . Obecnie nie można ustawić tej właściwości przy użyciu witryny Azure Portal, dlatego użyj interfejsu wiersza polecenia platformy Azure lub polecenia programu PowerShell.
Aby uzyskać więcej informacji na temat wymaganych portów dla platformy SAP HANA, przeczytaj rozdział Połączenia z bazami danych dzierżawy w przewodniku Bazy danych dzierżaw sap HANA lub Uwaga sap 2388694.
Uwaga
Jeśli maszyny wirtualne bez publicznych adresów IP są umieszczane w puli zaplecza wystąpienia wewnętrznego (bez publicznego adresu IP) usługi Azure Load Balancer w warstwie Standardowa, nie ma wychodzącej łączności z Internetem, chyba że zostanie wykonana więcej konfiguracji, aby umożliwić routing do publicznych punktów końcowych. Aby uzyskać więcej informacji na temat uzyskiwania łączności wychodzącej, zobacz Publiczna łączność punktów końcowych dla maszyn wirtualnych korzystających z usługi Azure usługa Load Balancer w warstwie Standardowa w scenariuszach wysokiej dostępności oprogramowania SAP.
Ważne
Nie włączaj sygnatur czasowych PROTOKOŁU TCP na maszynach wirtualnych platformy Azure umieszczonych za usługą Azure Load Balancer. Włączenie sygnatur czasowych protokołu TCP może spowodować niepowodzenie sond kondycji. Ustaw parametr net.ipv4.tcp_timestamps na 0. Aby uzyskać więcej informacji, zobacz Load Balancer health probes (Sondy kondycji usługi Load Balancer) i SAP Note 2382421.
Instalowanie platformy SAP HANA
Kroki opisane w tej sekcji korzystają z następujących prefiksów:
- [A]: Krok dotyczy wszystkich węzłów.
- [1]: Krok dotyczy tylko węzła 1.
- [2]: Krok dotyczy tylko węzła 2 klastra Pacemaker.
[A] Skonfiguruj układ dysku: Menedżer woluminów logicznych (LVM).
Zalecamy używanie lvm dla woluminów, które przechowują dane i pliki dziennika. W poniższym przykładzie przyjęto założenie, że maszyny wirtualne mają dołączone cztery dyski danych, które są używane do tworzenia dwóch woluminów.
Wyświetl listę wszystkich dostępnych dysków:
ls /dev/disk/azure/scsi1/lun*Przykładowe wyjście:
/dev/disk/azure/scsi1/lun0 /dev/disk/azure/scsi1/lun1 /dev/disk/azure/scsi1/lun2 /dev/disk/azure/scsi1/lun3Utwórz woluminy fizyczne dla wszystkich dysków, których chcesz użyć:
sudo pvcreate /dev/disk/azure/scsi1/lun0 sudo pvcreate /dev/disk/azure/scsi1/lun1 sudo pvcreate /dev/disk/azure/scsi1/lun2 sudo pvcreate /dev/disk/azure/scsi1/lun3Utwórz grupę woluminów dla plików danych. Użyj jednej grupy woluminów dla plików dziennika i jednego katalogu udostępnionego platformy SAP HANA:
sudo vgcreate vg_hana_data_HN1 /dev/disk/azure/scsi1/lun0 /dev/disk/azure/scsi1/lun1 sudo vgcreate vg_hana_log_HN1 /dev/disk/azure/scsi1/lun2 sudo vgcreate vg_hana_shared_HN1 /dev/disk/azure/scsi1/lun3Utwórz woluminy logiczne. Wolumin liniowy jest tworzony podczas używania
lvcreatebez przełącznika-i. Zalecamy utworzenie woluminu rozłożonego w celu uzyskania lepszej wydajności operacji we/wy. Wyrównuj rozmiary pasków do wartości opisanych w konfiguracjach magazynu maszyn wirtualnych SAP HANA. Argument-ipowinien być liczbą bazowych woluminów fizycznych, a-Iargumentem jest rozmiar paska.W tym dokumencie dla woluminu danych są używane dwa woluminy fizyczne, więc argument przełącznika
-ijest ustawiony na 2. Rozmiar paska dla woluminu danych to 256KiB. Jeden wolumin fizyczny jest używany dla woluminu dziennika, więc żadne przełączniki nie-i-Isą jawnie używane dla poleceń woluminu dziennika.Ważne
Użyj przełącznika
-ii ustaw go na liczbę woluminu fizycznego, jeśli używasz więcej niż jednego woluminu fizycznego dla każdego woluminu danych, dziennika lub udostępnionych woluminów. Użyj przełącznika-I, aby określić rozmiar paska podczas tworzenia woluminu rozłożonego. Zobacz Konfiguracje magazynu maszyn wirtualnych SAP HANA, aby uzyskać zalecane konfiguracje magazynu, w tym rozmiary stripe i liczbę dysków. Poniższe przykłady układu nie muszą spełniać wytycznych dotyczących wydajności dla określonego rozmiaru systemu. Są one przeznaczone tylko do ilustracji.sudo lvcreate -i 2 -I 256 -l 100%FREE -n hana_data vg_hana_data_HN1 sudo lvcreate -l 100%FREE -n hana_log vg_hana_log_HN1 sudo lvcreate -l 100%FREE -n hana_shared vg_hana_shared_HN1 sudo mkfs.xfs /dev/vg_hana_data_HN1/hana_data sudo mkfs.xfs /dev/vg_hana_log_HN1/hana_log sudo mkfs.xfs /dev/vg_hana_shared_HN1/hana_sharedNie należy instalować katalogów, wydając polecenia instalacji. Zamiast tego wprowadź konfiguracje w pliku
fstabi wydaj ostatecznemount -apolecenie, aby zweryfikować składnię. Zacznij od utworzenia katalogów instalacji dla każdego woluminu:sudo mkdir -p /hana/data sudo mkdir -p /hana/log sudo mkdir -p /hana/sharedNastępnie utwórz
fstabwpisy dla trzech woluminów logicznych, wstawiając następujące wiersze w/etc/fstabpliku:/dev/mapper/vg_hana_data_HN1-hana_data /hana/data xfs defaults,nofail 0 2 /dev/mapper/vg_hana_log_HN1-hana_log /hana/log xfs defaults,nofail 0 2 /dev/mapper/vg_hana_shared_HN1-hana_shared /hana/shared xfs defaults,nofail 0 2
Na koniec zainstaluj wszystkie nowe woluminy jednocześnie:
sudo mount -a[A] Skonfiguruj rozpoznawanie nazw hostów dla wszystkich hostów.
Możesz użyć serwera DNS lub zmodyfikować
/etc/hostsplik we wszystkich węzłach, tworząc wpisy dla wszystkich węzłów w następujący sposób:/etc/hosts10.0.0.5 hn1-db-0 10.0.0.6 hn1-db-1
[A] Wykonaj RHEL dla konfiguracji platformy HANA.
Skonfiguruj system RHEL zgodnie z opisem w następujących uwagach:
- 2447641 — dodatkowe pakiety wymagane do zainstalowania programu SAP HANA SPS 12 w systemie RHEL 7.X
- 2292690 — SAP HANA DB: zalecane ustawienia systemu operacyjnego dla RHEL 7
- 2777782 — SAP HANA DB: zalecane ustawienia systemu operacyjnego dla systemu RHEL 8
- 2455582 — Linux: uruchamianie aplikacji SAP skompilowanych przy użyciu biblioteki GCC 6.x
- 2593824 — Linux: uruchamianie aplikacji SAP skompilowanych przy użyciu biblioteki GCC 7.x
- 2886607 — Linux: uruchamianie aplikacji SAP skompilowanych przy użyciu biblioteki GCC 9.x
[A] Zainstaluj oprogramowanie SAP HANA, postępując zgodnie z dokumentacją systemu SAP.
[A] Skonfiguruj zaporę.
Utwórz regułę zapory dla portu sondy usługi Azure Load Balancer.
sudo firewall-cmd --zone=public --add-port=62503/tcp sudo firewall-cmd --zone=public --add-port=62503/tcp --permanent
Konfigurowanie replikacji systemu SAP HANA 2.0
Kroki opisane w tej sekcji korzystają z następujących prefiksów:
- [A]: Krok dotyczy wszystkich węzłów.
- [1]: Krok dotyczy tylko węzła 1.
- [2]: Krok dotyczy tylko węzła 2 klastra Pacemaker.
[A] Skonfiguruj zaporę.
Utwórz reguły zapory, aby zezwolić na replikację systemu HANA i ruch klienta. Wymagane porty są wyświetlane na liście portów TCP/IP wszystkich produktów SAP. Poniższe polecenia są tylko przykładem zezwalania na replikację systemu HANA 2.0 i ruch klienta do bazy danych SYSTEMDB, HN1 i NW1.
sudo firewall-cmd --zone=public --add-port={40302,40301,40307,40303,40340,30340,30341,30342}/tcp --permanent sudo firewall-cmd --zone=public --add-port={40302,40301,40307,40303,40340,30340,30341,30342}/tcp[1] Utwórz bazę danych dzierżawy.
Uruchom następujące polecenie jako <hanasid>adm:
hdbsql -u SYSTEM -p "[passwd]" -i 03 -d SYSTEMDB 'CREATE DATABASE NW1 SYSTEM USER PASSWORD "<passwd>"'[1] Konfigurowanie replikacji systemu w pierwszym węźle.
Tworzenie kopii zapasowej baz danych jako <adm hanasid>:
hdbsql -d SYSTEMDB -u SYSTEM -p "<passwd>" -i 03 "BACKUP DATA USING FILE ('initialbackupSYS')" hdbsql -d HN1 -u SYSTEM -p "<passwd>" -i 03 "BACKUP DATA USING FILE ('initialbackupHN1')" hdbsql -d NW1 -u SYSTEM -p "<passwd>" -i 03 "BACKUP DATA USING FILE ('initialbackupNW1')"Skopiuj systemowe pliki PKI do lokacji dodatkowej:
scp /usr/sap/HN1/SYS/global/security/rsecssfs/data/SSFS_HN1.DAT hn1-db-1:/usr/sap/HN1/SYS/global/security/rsecssfs/data/ scp /usr/sap/HN1/SYS/global/security/rsecssfs/key/SSFS_HN1.KEY hn1-db-1:/usr/sap/HN1/SYS/global/security/rsecssfs/key/Utwórz lokację główną:
hdbnsutil -sr_enable --name=SITE1[2] Konfigurowanie replikacji systemu w drugim węźle.
Zarejestruj drugi węzeł, aby rozpocząć replikację systemu. Uruchom następujące polecenie jako <hanasid>adm:
sapcontrol -nr 03 -function StopWait 600 10 hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=03 --replicationMode=sync --name=SITE2[2] Uruchom platformę HANA.
Uruchom następujące polecenie jako <hanasid>adm, aby uruchomić platformę HANA:
sapcontrol -nr 03 -function StartSystem[1] Sprawdź stan replikacji.
Sprawdź stan replikacji i poczekaj na zsynchronizowanie wszystkich baz danych. Jeśli stan pozostanie NIEZNANY, sprawdź ustawienia zapory.
sudo su - hn1adm -c "python /usr/sap/HN1/HDB03/exe/python_support/systemReplicationStatus.py" # | Database | Host | Port | Service Name | Volume ID | Site ID | Site Name | Secondary | Secondary | Secondary | Secondary | Secondary | Replication | Replication | Replication | # | | | | | | | | Host | Port | Site ID | Site Name | Active Status | Mode | Status | Status Details | # | -------- | -------- | ----- | ------------ | --------- | ------- | --------- | --------- | --------- | --------- | --------- | ------------- | ----------- | ----------- | -------------- | # | SYSTEMDB | hn1-db-0 | 30301 | nameserver | 1 | 1 | SITE1 | hn1-db-1 | 30301 | 2 | SITE2 | YES | SYNC | ACTIVE | | # | HN1 | hn1-db-0 | 30307 | xsengine | 2 | 1 | SITE1 | hn1-db-1 | 30307 | 2 | SITE2 | YES | SYNC | ACTIVE | | # | NW1 | hn1-db-0 | 30340 | indexserver | 2 | 1 | SITE1 | hn1-db-1 | 30340 | 2 | SITE2 | YES | SYNC | ACTIVE | | # | HN1 | hn1-db-0 | 30303 | indexserver | 3 | 1 | SITE1 | hn1-db-1 | 30303 | 2 | SITE2 | YES | SYNC | ACTIVE | | # # status system replication site "2": ACTIVE # overall system replication status: ACTIVE # # Local System Replication State # ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ # # mode: PRIMARY # site id: 1 # site name: SITE1
Tworzenie klastra Pacemaker
Wykonaj kroki opisane w temacie Konfigurowanie programu Pacemaker w systemie Red Hat Enterprise Linux na platformie Azure , aby utworzyć podstawowy klaster Pacemaker dla tego serwera HANA.
Ważne
Za pomocą systemowego programu SAP Startup Framework wystąpienia SAP HANA mogą być teraz zarządzane przez systemd. Minimalna wymagana wersja systemu Red Hat Enterprise Linux (RHEL) to RHEL 8 dla systemu SAP. Jak opisano w artykule SAP Note 3189534, wszelkie nowe instalacje oprogramowania SAP HANA SPS07 w wersji 70 lub nowszej albo aktualizacje systemów HANA do wersji HANA 2.0 SPS07 w wersji 70 lub nowszej, platforma SAP Startup framework zostanie automatycznie zarejestrowana w systemie.
W przypadku korzystania z rozwiązań wysokiej dostępności do zarządzania replikacją systemu SAP HANA w połączeniu z wystąpieniami sap HANA z obsługą systemu (zapoznaj się z artykułem SAP Note 3189534), należy wykonać dodatkowe kroki, aby zapewnić, że klaster wysokiej dostępności może zarządzać wystąpieniem SAP bez ingerencji systemu. Dlatego w przypadku systemu SAP HANA zintegrowanego z systemem dodatkowe kroki opisane w artykule Red Hat KBA 7029705 muszą być wykonywane we wszystkich węzłach klastra.
Implementowanie punktów zaczepienia replikacji systemu SAP HANA
Ten ważny krok optymalizuje integrację z klastrem i poprawia wykrywanie, gdy potrzebny jest tryb failover klastra. Prawidłowe działanie klastra jest obowiązkowe w celu włączenia haka SAPHanaSR. Zdecydowanie zalecamy skonfigurowanie zarówno punktów zaczepienia języka Python SAPHanaSR, jak i ChkSrv.
[A] Zainstaluj agentów zasobów SAP HANA na wszystkich węzłach. Upewnij się, że włączono repozytorium zawierające pakiet. Nie musisz włączać większej liczby repozytoriów, jeśli używasz obrazu z włączoną wysoką dostępnością lub systemem RHEL 8.x.
# Enable repository that contains SAP HANA resource agents sudo subscription-manager repos --enable="rhel-sap-hana-for-rhel-7-server-rpms" sudo dnf install -y resource-agents-sap-hanaUwaga
W przypadku systemów RHEL 8.x i RHEL 9.x sprawdź, czy zainstalowany pakiet resource-agents-sap-hana ma wersję 0.162.3-5 lub nowszą.
[A] Zainstaluj platformę HANA
system replication hooks. Konfiguracja punktów zaczepienia replikacji musi być zainstalowana w obu węzłach bazy danych HANA.Zatrzymaj platformę HANA w obu węzłach. Uruchom jako <identyfikator sid>adm.
sapcontrol -nr 03 -function StopSystemDostosuj w
global.inikażdym węźle klastra.[ha_dr_provider_SAPHanaSR] provider = SAPHanaSR path = /usr/share/SAPHanaSR/srHook execution_order = 1 [ha_dr_provider_chksrv] provider = ChkSrv path = /usr/share/SAPHanaSR/srHook execution_order = 2 action_on_lost = kill [trace] ha_dr_saphanasr = info ha_dr_chksrv = info
Jeśli wskażesz parametr
pathlokalizacji domyślnej/usr/share/SAPHanaSR/srHook, kod punktu zaczepienia języka Python zostanie automatycznie zaktualizowany za pośrednictwem aktualizacji systemu operacyjnego lub aktualizacji pakietów. Platforma HANA używa aktualizacji kodu zaczepienia po następnym ponownym uruchomieniu. W przypadku opcjonalnej własnej ścieżki, takiej jak/hana/shared/myHooks, można rozdzielić aktualizacje systemu operacyjnego z wersji punktu zaczepienia używanej przez platformę HANA.Zachowanie haka
ChkSrvmożna dostosować przy użyciu parametruaction_on_lost. Prawidłowe wartości to [ignore| |stopkill].[A] Klaster wymaga
sudoerskonfiguracji w każdym węźle klastra dla <identyfikatora SID>adm. W tym przykładzie jest to osiągane przez utworzenie nowego pliku. Użyj polecenia ,visudoaby edytować20-saphanaplik drop-in jakoroot.sudo visudo -f /etc/sudoers.d/20-saphanaWstaw następujące wiersze, a następnie zapisz:
Cmnd_Alias SITE1_SOK = /usr/sbin/crm_attribute -n hana_hn1_site_srHook_SITE1 -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SITE1_SFAIL = /usr/sbin/crm_attribute -n hana_hn1_site_srHook_SITE1 -v SFAIL -t crm_config -s SAPHanaSR Cmnd_Alias SITE2_SOK = /usr/sbin/crm_attribute -n hana_hn1_site_srHook_SITE2 -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SITE2_SFAIL = /usr/sbin/crm_attribute -n hana_hn1_site_srHook_SITE2 -v SFAIL -t crm_config -s SAPHanaSR hn1adm ALL=(ALL) NOPASSWD: SITE1_SOK, SITE1_SFAIL, SITE2_SOK, SITE2_SFAIL Defaults!SITE1_SOK, SITE1_SFAIL, SITE2_SOK, SITE2_SFAIL !requiretty[A] Uruchom platformę SAP HANA w obu węzłach. Uruchom jako <identyfikator sid>adm.
sapcontrol -nr 03 -function StartSystem[1] Sprawdź instalację haka SRHanaSR. Uruchom polecenie sid <>adm w aktywnej lokacji replikacji systemu HANA.
cdtrace awk '/ha_dr_SAPHanaSR.*crm_attribute/ \ { printf "%s %s %s %s\n",$2,$3,$5,$16 }' nameserver_*# 2021-04-12 21:36:16.911343 ha_dr_SAPHanaSR SFAIL # 2021-04-12 21:36:29.147808 ha_dr_SAPHanaSR SFAIL # 2021-04-12 21:37:04.898680 ha_dr_SAPHanaSR SOK[1] Sprawdź instalację haka ChkSrv. Uruchom polecenie sid <>adm w aktywnej lokacji replikacji systemu HANA.
cdtrace tail -20 nameserver_chksrv.trc
Aby uzyskać więcej informacji na temat implementacji punktów zaczepienia platformy SAP HANA, zobacz Włączanie haka programu SAP HANA srConnectionChanged() i Włączanie haka sap HANA srServiceStateChanged() dla akcji niepowodzenia procesu hdbindexserver (opcjonalnie).
Tworzenie zasobów klastra SAP HANA
Utwórz topologię platformy HANA. Uruchom następujące polecenia w jednym z węzłów klastra Pacemaker. W tych instrukcjach należy w razie potrzeby zastąpić numer wystąpienia, identyfikator systemu HANA, adresy IP i nazwy systemu.
sudo pcs property set maintenance-mode=true
sudo pcs resource create SAPHanaTopology_HN1_03 SAPHanaTopology SID=HN1 InstanceNumber=03 \
op start timeout=600 op stop timeout=300 op monitor interval=10 timeout=600 \
clone clone-max=2 clone-node-max=1 interleave=true
Następnie utwórz zasoby platformy HANA.
Uwaga
Ten artykuł zawiera odwołania do terminu, którego firma Microsoft już nie używa. Po usunięciu terminu z oprogramowania usuniemy go z tego artykułu.
Jeśli tworzysz klaster w systemie RHEL 7.x, użyj następujących poleceń:
sudo pcs resource create SAPHana_HN1_03 SAPHana SID=HN1 InstanceNumber=03 PREFER_SITE_TAKEOVER=true DUPLICATE_PRIMARY_TIMEOUT=7200 AUTOMATED_REGISTER=false \
op start timeout=3600 op stop timeout=3600 \
op monitor interval=61 role="Slave" timeout=700 \
op monitor interval=59 role="Master" timeout=700 \
op promote timeout=3600 op demote timeout=3600 \
master notify=true clone-max=2 clone-node-max=1 interleave=true
sudo pcs resource create vip_HN1_03 IPaddr2 ip="10.0.0.13"
sudo pcs resource create nc_HN1_03 azure-lb port=62503
sudo pcs resource group add g_ip_HN1_03 nc_HN1_03 vip_HN1_03
sudo pcs constraint order SAPHanaTopology_HN1_03-clone then SAPHana_HN1_03-master symmetrical=false
sudo pcs constraint colocation add g_ip_HN1_03 with master SAPHana_HN1_03-master 4000
sudo pcs resource defaults resource-stickiness=1000
sudo pcs resource defaults migration-threshold=5000
sudo pcs property set maintenance-mode=false
Jeśli tworzysz klaster w systemie RHEL 8.x/9.x, użyj następujących poleceń:
sudo pcs resource create SAPHana_HN1_03 SAPHana SID=HN1 InstanceNumber=03 PREFER_SITE_TAKEOVER=true DUPLICATE_PRIMARY_TIMEOUT=7200 AUTOMATED_REGISTER=false \
op start timeout=3600 op stop timeout=3600 \
op monitor interval=61 role="Slave" timeout=700 \
op monitor interval=59 role="Master" timeout=700 \
op promote timeout=3600 op demote timeout=3600 \
promotable notify=true clone-max=2 clone-node-max=1 interleave=true
sudo pcs resource create vip_HN1_03 IPaddr2 ip="10.0.0.13"
sudo pcs resource create nc_HN1_03 azure-lb port=62503
sudo pcs resource group add g_ip_HN1_03 nc_HN1_03 vip_HN1_03
sudo pcs constraint order SAPHanaTopology_HN1_03-clone then SAPHana_HN1_03-clone symmetrical=false
sudo pcs constraint colocation add g_ip_HN1_03 with master SAPHana_HN1_03-clone 4000
sudo pcs resource defaults update resource-stickiness=1000
sudo pcs resource defaults update migration-threshold=5000
sudo pcs property set maintenance-mode=false
Aby skonfigurować priority-fencing-delay oprogramowanie SAP HANA (dotyczy tylko programu pacemaker-2.0.4-6.el8 lub nowszego), należy wykonać następujące polecenia.
Uwaga
Jeśli masz klaster z dwoma węzłami, możesz skonfigurować właściwość klastra priority-fencing-delay . Ta właściwość wprowadza opóźnienie w ogrodzeniu węzła, który ma wyższy całkowity priorytet zasobu, gdy wystąpi scenariusz podziału mózgu. Aby uzyskać więcej informacji, zobacz Czy program Pacemaker ogrodzy węzeł klastra z najmniej uruchomionymi zasobami?.
Właściwość priority-fencing-delay ma zastosowanie do wersji pacemaker-2.0.4-6.el8 lub nowszej. Jeśli konfigurujesz priority-fencing-delay istniejący klaster, upewnij się, że opcja nie jest skonfigurowana pcmk_delay_max na urządzeniu ogrodzeniowym.
sudo pcs property set maintenance-mode=true
sudo pcs resource defaults update priority=1
sudo pcs resource update SAPHana_HN1_03-clone meta priority=10
sudo pcs property set priority-fencing-delay=15s
sudo pcs property set maintenance-mode=false
Ważne
Dobrym pomysłem jest ustawienie AUTOMATED_REGISTER falsewartości , gdy przeprowadzasz testy trybu failover, aby zapobiec automatycznemu zarejestrowaniu się jako pomocniczego wystąpienia podstawowego, które zakończyło się niepowodzeniem. Po przetestowaniu jako najlepsze rozwiązanie należy ustawić true wartość AUTOMATED_REGISTER tak, aby po przejęciu replikacja systemu mogła być wznawiana automatycznie.
Upewnij się, że stan klastra jest prawidłowy i że wszystkie zasoby zostały uruchomione. Węzeł, na którym działają zasoby, nie jest ważny.
Uwaga
Przekroczenia limitu czasu w poprzedniej konfiguracji to tylko przykłady i może być konieczne dostosowanie ich do określonej konfiguracji platformy HANA. Na przykład może być konieczne zwiększenie limitu czasu rozpoczęcia, jeśli uruchomienie bazy danych SAP HANA trwa dłużej.
Użyj polecenia sudo pcs status , aby sprawdzić stan utworzonych zasobów klastra:
# Online: [ hn1-db-0 hn1-db-1 ]
#
# Full list of resources:
#
# azure_fence (stonith:fence_azure_arm): Started hn1-db-0
# Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]
# Started: [ hn1-db-0 hn1-db-1 ]
# Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03]
# Masters: [ hn1-db-0 ]
# Slaves: [ hn1-db-1 ]
# Resource Group: g_ip_HN1_03
# nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-0
# vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-0
Konfigurowanie replikacji systemu z obsługą aktywnego/odczytu platformy HANA w klastrze Pacemaker
Począwszy od platformy SAP HANA 2.0 SPS 01, oprogramowanie SAP umożliwia aktywne/odczytu konfiguracje replikacji systemu SAP HANA, gdzie pomocnicze systemy replikacji systemu SAP HANA mogą być aktywnie używane do obsługi obciążeń intensywnie działających w trybie odczytu.
Aby obsługiwać taką konfigurację w klastrze, wymagany jest drugi wirtualny adres IP, który umożliwia klientom dostęp do pomocniczej bazy danych SAP HANA z obsługą odczytu. Aby upewnić się, że lokacja replikacji dodatkowej będzie nadal dostępna po przejęciu, klaster musi przenieść wirtualny adres IP wokół z pomocniczym zasobem SAPHana.
W tej sekcji opisano inne kroki wymagane do zarządzania replikacją systemu z obsługą aktywnego/odczytu platformy HANA w klastrze Red Hat HA z drugim wirtualnym adresem IP.
Przed kontynuowaniem upewnij się, że w pełni skonfigurowany klaster Red Hat HA zarządza bazą danych SAP HANA zgodnie z opisem w poprzednich segmentach dokumentacji.
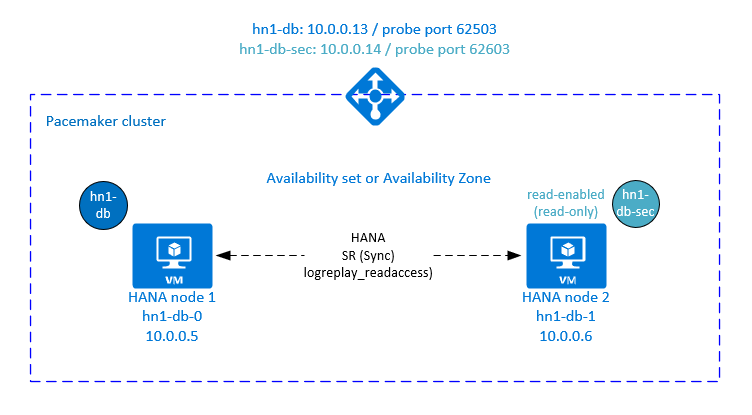
Dodatkowa konfiguracja w usłudze Azure Load Balancer na potrzeby konfiguracji z obsługą aktywnego/odczytu
Aby wykonać więcej kroków dotyczących aprowizacji drugiego wirtualnego adresu IP, upewnij się, że skonfigurowano usługę Azure Load Balancer zgodnie z opisem w sekcji Wdrażanie maszyn wirtualnych z systemem Linux ręcznie za pośrednictwem witryny Azure Portal .
W przypadku modułu równoważenia obciążenia w warstwie Standardowa wykonaj następujące kroki dla tego samego modułu równoważenia obciążenia utworzonego we wcześniejszej sekcji.
a. Utwórz drugą pulę adresów IP frontonu:
- Otwórz moduł równoważenia obciążenia, wybierz pulę adresów IP frontonu i wybierz pozycję Dodaj.
- Wprowadź nazwę drugiej puli adresów IP frontonu (na przykład hana-secondaryIP).
- Ustaw wartość Przypisanie na Statyczne i wprowadź adres IP (na przykład 10.0.0.14).
- Wybierz przycisk OK.
- Po utworzeniu nowej puli adresów IP frontonu zanotuj adres IP puli.
b. Utwórz sondę kondycji:
- Otwórz moduł równoważenia obciążenia, wybierz pozycję Sondy kondycji i wybierz pozycję Dodaj.
- Wprowadź nazwę nowej sondy kondycji (na przykład hana-secondaryhp).
- Wybierz tcp jako protokół i port 62603. Zachowaj wartość Interwał ustawioną na 5, a wartość progu złej kondycji ustawiona na 2.
- Wybierz przycisk OK.
c. Utwórz reguły równoważenia obciążenia:
- Otwórz moduł równoważenia obciążenia, wybierz pozycję Reguły równoważenia obciążenia, a następnie wybierz pozycję Dodaj.
- Wprowadź nazwę nowej reguły modułu równoważenia obciążenia (na przykład hana-secondarylb).
- Wybierz adres IP frontonu, pulę zaplecza i utworzoną wcześniej sondę kondycji (na przykład hana-secondaryIP, hana-backend i hana-secondaryhp).
- Wybierz pozycję Porty wysokiej dostępności.
- Upewnij się, że włączono pływający adres IP.
- Wybierz przycisk OK.
Konfigurowanie replikacji systemu z obsługą aktywnego/odczytu na platformie HANA
Kroki konfigurowania replikacji systemu HANA zostały opisane w sekcji Konfigurowanie replikacji systemu SAP HANA 2.0. Jeśli wdrażasz pomocniczy scenariusz z obsługą odczytu podczas konfigurowania replikacji systemu w drugim węźle, uruchom następujące polecenie jako hanasidadm:
sapcontrol -nr 03 -function StopWait 600 10
hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=03 --replicationMode=sync --name=SITE2 --operationMode=logreplay_readaccess
Dodawanie pomocniczego zasobu wirtualnego adresu IP dla konfiguracji z włączoną obsługą aktywnego/odczytu
Drugi wirtualny adres IP i odpowiednie ograniczenie kolokacji można skonfigurować za pomocą następujących poleceń:
pcs property set maintenance-mode=true
pcs resource create secvip_HN1_03 ocf:heartbeat:IPaddr2 ip="10.40.0.16"
pcs resource create secnc_HN1_03 ocf:heartbeat:azure-lb port=62603
pcs resource group add g_secip_HN1_03 secnc_HN1_03 secvip_HN1_03
pcs constraint location g_secip_HN1_03 rule score=INFINITY hana_hn1_sync_state eq SOK and hana_hn1_roles eq 4:S:master1:master:worker:master
pcs constraint location g_secip_HN1_03 rule score=4000 hana_hn1_sync_state eq PRIM and hana_hn1_roles eq 4:P:master1:master:worker:master
# Set the priority to primary IPaddr2 and azure-lb resource if priority-fencing-delay is configured
sudo pcs resource update vip_HN1_03 meta priority=5
sudo pcs resource update nc_HN1_03 meta priority=5
pcs property set maintenance-mode=false
Upewnij się, że stan klastra jest prawidłowy i że wszystkie zasoby są uruchomione. Drugi wirtualny adres IP działa w lokacji dodatkowej wraz z zasobem pomocniczym SAPHana.
sudo pcs status
# Online: [ hn1-db-0 hn1-db-1 ]
#
# Full List of Resources:
# rsc_hdb_azr_agt (stonith:fence_azure_arm): Started hn1-db-0
# Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]:
# Started: [ hn1-db-0 hn1-db-1 ]
# Clone Set: SAPHana_HN1_03-clone [SAPHana_HN1_03] (promotable):
# Masters: [ hn1-db-0 ]
# Slaves: [ hn1-db-1 ]
# Resource Group: g_ip_HN1_03:
# nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-0
# vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-0
# Resource Group: g_secip_HN1_03:
# secnc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-1
# secvip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
W następnej sekcji znajdziesz typowy zestaw testów trybu failover do uruchomienia.
Pamiętaj o drugim zachowaniu wirtualnego adresu IP podczas testowania klastra HANA skonfigurowanego z pomocniczym obsługą odczytu:
Podczas migracji zasobu klastra SAPHana_HN1_03 do lokacji dodatkowej hn1-db-1 drugi wirtualny adres IP będzie nadal działać w tej samej lokacji hn1-db-1. Jeśli ustawiono
AUTOMATED_REGISTER="true"dla zasobu, a replikacja systemu HANA jest rejestrowana automatycznie na serwerze hn1-db-0, drugi wirtualny adres IP zostanie również przeniesiony do hn1-db-0.Podczas testowania awarii serwera drugie zasoby wirtualnego adresu IP (secvip_HN1_03) i zasób portu usługi Azure Load Balancer (secnc_HN1_03) działają na serwerze podstawowym wraz z podstawowymi zasobami wirtualnego adresu IP. Dlatego do czasu, gdy serwer pomocniczy nie działa, aplikacje połączone z bazą danych HANA z włączoną obsługą odczytu łączą się z podstawową bazą danych HANA. Zachowanie jest oczekiwane, ponieważ nie chcesz, aby aplikacje połączone z bazą danych HANA z włączoną obsługą odczytu mogły być niedostępne do czasu niedostępności serwera pomocniczego.
Podczas pracy w trybie failover i powrotu drugiego wirtualnego adresu IP istniejące połączenia w aplikacjach używających drugiego wirtualnego adresu IP do nawiązania połączenia z bazą danych HANA mogą zostać przerwane.
Konfiguracja maksymalizuje czas przypisywania drugiego zasobu wirtualnego adresu IP do węzła, w którym uruchomiono wystąpienie oprogramowania SAP HANA w dobrej kondycji.
Testowanie konfiguracji klastra
W tej sekcji opisano sposób testowania konfiguracji. Przed rozpoczęciem testu upewnij się, że program Pacemaker nie ma żadnych nieudanych akcji (za pośrednictwem stanu pcs), nie ma żadnych nieoczekiwanych ograniczeń lokalizacji (na przykład pozostawienia testu migracji) i że platforma HANA jest w stanie synchronizacji, na przykład za pomocą polecenia systemReplicationStatus.
sudo su - hn1adm -c "python /usr/sap/HN1/HDB03/exe/python_support/systemReplicationStatus.py"
Testowanie migracji
Stan zasobu przed rozpoczęciem testu:
Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03]
Masters: [ hn1-db-0 ]
Slaves: [ hn1-db-1 ]
Resource Group: g_ip_HN1_03
nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-0
vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-0
Aby przeprowadzić migrację węzła głównego sap HANA, uruchom następujące polecenie jako katalog główny:
# On RHEL 7.x
pcs resource move SAPHana_HN1_03-master
# On RHEL 8.x
pcs resource move SAPHana_HN1_03-clone --master
Klaster przeprowadzi migrację węzła głównego platformy SAP HANA i grupy zawierającej wirtualny adres IP do hn1-db-1.
Po zakończeniu sudo pcs status migracji dane wyjściowe wyglądają następująco:
Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03]
Masters: [ hn1-db-1 ]
Stopped: [ hn1-db-0 ]
Resource Group: g_ip_HN1_03
nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-1
vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
W przypadku AUTOMATED_REGISTER="false"klastra nie można ponownie uruchomić bazy danych HANA, która zakończyła się niepowodzeniem, ani zarejestrować jej względem nowej bazy podstawowej w systemie hn1-db-0. W takim przypadku skonfiguruj wystąpienie HANA jako pomocnicze, uruchamiając następujące polecenia jako hn1adm:
sapcontrol -nr 03 -function StopWait 600 10
hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=03 --replicationMode=sync --name=SITE1
Migracja tworzy ograniczenia lokalizacji, które należy usunąć ponownie. Uruchom następujące polecenie jako katalog główny lub za pomocą polecenia sudo:
pcs resource clear SAPHana_HN1_03-master
Monitoruj stan zasobu platformy HANA przy użyciu polecenia pcs status. Po uruchomieniu platformy hn1-db-0HANA dane wyjściowe powinny wyglądać następująco:
Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03]
Masters: [ hn1-db-1 ]
Slaves: [ hn1-db-0 ]
Resource Group: g_ip_HN1_03
nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-1
vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
Blokuj komunikację sieci
Stan zasobu przed rozpoczęciem testu:
Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03]
Masters: [ hn1-db-1 ]
Slaves: [ hn1-db-0 ]
Resource Group: g_ip_HN1_03
nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-1
vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
Uruchom regułę zapory, aby zablokować komunikację w jednym z węzłów.
# Execute iptable rule on hn1-db-1 (10.0.0.6) to block the incoming and outgoing traffic to hn1-db-0 (10.0.0.5)
iptables -A INPUT -s 10.0.0.5 -j DROP; iptables -A OUTPUT -d 10.0.0.5 -j DROP
Gdy węzły klastra nie mogą komunikować się ze sobą, istnieje ryzyko scenariusza podzielonego mózgu. W takich sytuacjach węzły klastra starają się jednocześnie ogrodzenia, co powoduje wyścig ogrodzenia. Aby uniknąć takiej sytuacji, zalecamy ustawienie właściwości priority-fencing-delay w konfiguracji klastra (dotyczy tylko pacemaker-2.0.4-6.el8 lub nowszej).
Po włączeniu priority-fencing-delay właściwości klaster wprowadza opóźnienie w akcji ogrodzenia w szczególności w węźle hostujący zasób główny HANA, dzięki czemu węzeł może wygrać wyścig ogrodzenia.
Uruchom następujące polecenie, aby usunąć regułę zapory:
# If the iptables rule set on the server gets reset after a reboot, the rules will be cleared out. In case they have not been reset, please proceed to remove the iptables rule using the following command.
iptables -D INPUT -s 10.0.0.5 -j DROP; iptables -D OUTPUT -d 10.0.0.5 -j DROP
Testowanie agenta ogrodzenia platformy Azure
Uwaga
Ten artykuł zawiera odwołania do terminu, którego firma Microsoft już nie używa. Po usunięciu terminu z oprogramowania usuniemy go z tego artykułu.
Stan zasobu przed rozpoczęciem testu:
Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03]
Masters: [ hn1-db-1 ]
Slaves: [ hn1-db-0 ]
Resource Group: g_ip_HN1_03
nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-1
vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
Konfigurację agenta ogrodzenia platformy Azure można przetestować, wyłączając interfejs sieciowy w węźle, w którym platforma SAP HANA jest uruchomiona jako główny. Opis sposobu symulowania awarii sieci można znaleźć w artykule 79523 z bazy wiedzy Red Hat.
W tym przykładzie używamy skryptu net_breaker jako katalogu głównego, aby zablokować cały dostęp do sieci:
sh ./net_breaker.sh BreakCommCmd 10.0.0.6
Maszyna wirtualna powinna teraz zostać ponownie uruchomiona lub zatrzymana w zależności od konfiguracji klastra.
Jeśli ustawisz stonith-action ustawienie na off, maszyna wirtualna zostanie zatrzymana, a zasoby zostaną zmigrowane do uruchomionej maszyny wirtualnej.
Po ponownym uruchomieniu maszyny wirtualnej zasób SAP HANA nie może uruchomić się jako pomocniczy, jeśli ustawiono wartość AUTOMATED_REGISTER="false". W takim przypadku skonfiguruj wystąpienie platformy HANA jako pomocnicze, uruchamiając to polecenie jako użytkownik hn1adm :
sapcontrol -nr 03 -function StopWait 600 10
hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=03 --replicationMode=sync --name=SITE2
Wróć do katalogu głównego i wyczyść stan niepowodzenia:
# On RHEL 7.x
pcs resource cleanup SAPHana_HN1_03-master
# On RHEL 8.x
pcs resource cleanup SAPHana_HN1_03 node=<hostname on which the resource needs to be cleaned>
Stan zasobu po teście:
Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03]
Masters: [ hn1-db-0 ]
Slaves: [ hn1-db-1 ]
Resource Group: g_ip_HN1_03
nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-0
vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-0
Testowanie ręcznego przejścia w tryb failover
Stan zasobu przed rozpoczęciem testu:
Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03]
Masters: [ hn1-db-0 ]
Slaves: [ hn1-db-1 ]
Resource Group: g_ip_HN1_03
nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-0
vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-0
Ręczne przejście w tryb failover można przetestować, zatrzymując klaster w węźle hn1-db-0 jako katalog główny:
pcs cluster stop
Po przejściu w tryb failover można ponownie uruchomić klaster. Jeśli ustawisz wartość AUTOMATED_REGISTER="false", zasób SAP HANA w węźle hn1-db-0 nie może uruchomić się jako pomocniczy. W takim przypadku skonfiguruj wystąpienie platformy HANA jako pomocnicze, uruchamiając to polecenie jako katalog główny:
pcs cluster start
Uruchom następujące polecenie jako hn1adm:
sapcontrol -nr 03 -function StopWait 600 10
hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=03 --replicationMode=sync --name=SITE1
Następnie jako katalog główny:
# On RHEL 7.x
pcs resource cleanup SAPHana_HN1_03-master
# On RHEL 8.x
pcs resource cleanup SAPHana_HN1_03 node=<hostname on which the resource needs to be cleaned>
Stan zasobu po teście:
Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03]
Masters: [ hn1-db-1 ]
Slaves: [ hn1-db-0 ]
Resource Group: g_ip_HN1_03
nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-1
vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-1