Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W tym artykule pokazano, jak debugować aplikację korzystającą z Przyspieszonego Przetwarzania Równoległego C++ (C++ AMP) w celu wykorzystania procesora graficznego (GPU). Używa on programu redukcji równoległej, który sumuje dużą tablicę liczb całkowitych. W instruktażu przedstawiono następujące zagadnienia:
- Uruchamianie debugera procesora GPU.
- Sprawdzanie wątków GPU w oknie Wątki GPU.
- Korzystając z okna Stosy równoległe, można jednocześnie obserwować stosy wywołań wielu wątków procesora GPU.
- Korzyścią z korzystania z okna Obserwacji Równoległej jest możliwość sprawdzenia wartości pojedynczego wyrażenia w wielu wątkach jednocześnie.
- Flagowanie, zamrażanie, rozmrażanie i grupowanie wątków procesora GPU.
- Uruchamianie wszystkich wątków kafelka w określone miejsce w kodzie.
Wymagania wstępne
Przed rozpoczęciem tego przewodnika:
Uwaga / Notatka
Nagłówki C++ AMP są przestarzałe, począwszy od programu Visual Studio 2022 w wersji 17.0.
Dołączenie wszystkich nagłówków AMP spowoduje wygenerowanie błędów kompilacji. Zdefiniuj _SILENCE_AMP_DEPRECATION_WARNINGS przed dołączeniem jakichkolwiek nagłówków AMP, aby wyciszyć ostrzeżenia.
- Przeczytaj C++ AMP Overview.
- Upewnij się, że numery wierszy są wyświetlane w edytorze tekstów. Aby uzyskać więcej informacji, zobacz How to: Display line numbers in the editor (Instrukcje: wyświetlanie numerów wierszy w edytorze).
- Upewnij się, że używasz co najmniej systemu Windows 8 lub Windows Server 2012 do obsługi debugowania w emulatorze oprogramowania.
Uwaga / Notatka
Na komputerze mogą być wyświetlane różne nazwy lub lokalizacje niektórych elementów interfejsu użytkownika programu Visual Studio w poniższych instrukcjach. Edycja Visual Studio, którą posiadasz, oraz ustawienia, których używasz, określają te elementy. Aby uzyskać więcej informacji, zobacz Personalizowanie środowiska IDE.
Aby utworzyć przykładowy projekt
Instrukcje dotyczące tworzenia projektu różnią się w zależności od używanej wersji programu Visual Studio. Upewnij się, że masz wybraną poprawną wersję dokumentacji powyżej spisu treści na tej stronie.
Aby utworzyć przykładowy projekt w programie Visual Studio
Na pasku menu wybierz Plik>Nowy>Projekt, aby otworzyć okno dialogowe Utwórz Nowy Projekt.
W górnej części okna dialogowego ustaw wartość Language na C++, ustaw wartość Platforma na Windows, a następnie ustaw wartość Project type (Typ projektu) na Console (Konsola).
Z filtrowanej listy typów projektów wybierz pozycję Aplikacja konsolowa, a następnie wybierz pozycję Dalej. Na następnej stronie wprowadź
AMPMapReducew polu Nazwa , aby określić nazwę projektu i określić lokalizację projektu, jeśli chcesz użyć innej.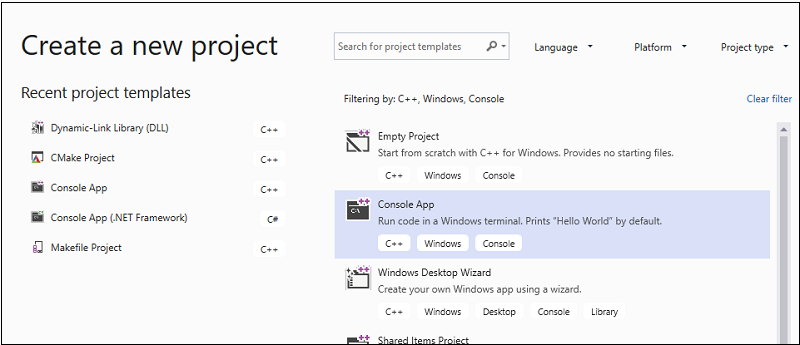
Wybierz przycisk Utwórz, aby utworzyć projekt klienta.
Następny:
Otwórz AMPMapReduce.cpp i zastąp jego zawartość następującym kodem.
// AMPMapReduce.cpp defines the entry point for the program. // The program performs a parallel-sum reduction that computes the sum of an array of integers. #include <stdio.h> #include <tchar.h> #include <amp.h> const int BLOCK_DIM = 32; using namespace concurrency; void sum_kernel_tiled(tiled_index<BLOCK_DIM> t_idx, array<int, 1> &A, int stride_size) restrict(amp) { tile_static int localA[BLOCK_DIM]; index<1> globalIdx = t_idx.global * stride_size; index<1> localIdx = t_idx.local; localA[localIdx[0]] = A[globalIdx]; t_idx.barrier.wait(); // Aggregate all elements in one tile into the first element. for (int i = BLOCK_DIM / 2; i > 0; i /= 2) { if (localIdx[0] < i) { localA[localIdx[0]] += localA[localIdx[0] + i]; } t_idx.barrier.wait(); } if (localIdx[0] == 0) { A[globalIdx] = localA[0]; } } int size_after_padding(int n) { // The extent might have to be slightly bigger than num_stride to // be evenly divisible by BLOCK_DIM. You can do this by padding with zeros. // The calculation to do this is BLOCK_DIM * ceil(n / BLOCK_DIM) return ((n - 1) / BLOCK_DIM + 1) * BLOCK_DIM; } int reduction_sum_gpu_kernel(array<int, 1> input) { int len = input.extent[0]; //Tree-based reduction control that uses the CPU. for (int stride_size = 1; stride_size < len; stride_size *= BLOCK_DIM) { // Number of useful values in the array, given the current // stride size. int num_strides = len / stride_size; extent<1> e(size_after_padding(num_strides)); // The sum kernel that uses the GPU. parallel_for_each(extent<1>(e).tile<BLOCK_DIM>(), [&input, stride_size] (tiled_index<BLOCK_DIM> idx) restrict(amp) { sum_kernel_tiled(idx, input, stride_size); }); } array_view<int, 1> output = input.section(extent<1>(1)); return output[0]; } int cpu_sum(const std::vector<int> &arr) { int sum = 0; for (size_t i = 0; i < arr.size(); i++) { sum += arr[i]; } return sum; } std::vector<int> rand_vector(unsigned int size) { srand(2011); std::vector<int> vec(size); for (size_t i = 0; i < size; i++) { vec[i] = rand(); } return vec; } array<int, 1> vector_to_array(const std::vector<int> &vec) { array<int, 1> arr(vec.size()); copy(vec.begin(), vec.end(), arr); return arr; } int _tmain(int argc, _TCHAR* argv[]) { std::vector<int> vec = rand_vector(10000); array<int, 1> arr = vector_to_array(vec); int expected = cpu_sum(vec); int actual = reduction_sum_gpu_kernel(arr); bool passed = (expected == actual); if (!passed) { printf("Actual (GPU): %d, Expected (CPU): %d", actual, expected); } printf("sum: %s\n", passed ? "Passed!" : "Failed!"); getchar(); return 0; }Na pasku menu wybierz pozycję Plik>Zapisz wszystko.
W Eksploratorze rozwiązań otwórz menu kontekstowe AMPMapReduce, a następnie wybierz pozycję Właściwości.
W oknie dialogowym Strony właściwości, w obszarze Właściwości konfiguracji, wybierz C/C++>Precompiled Headers.
Dla właściwości Prekompilowany nagłówek wybierz Nieużywanie prekompilowanych nagłówków, a następnie wybierz przycisk OK .Na pasku menu wybierz Buduj>Buduj rozwiązanie.
Debugowanie kodu procesora CPU
W tej procedurze użyjesz lokalnego debugera systemu Windows, aby upewnić się, że kod procesora CPU w tej aplikacji jest poprawny. Szczególnie interesującym segmentem kodu CPU w tej aplikacji jest pętla for w funkcji reduction_sum_gpu_kernel. Steruje drzewiastą redukcją równoległą wykonywaną na GPU.
Aby debugować kod CPU
W Eksploratorze rozwiązań otwórz menu kontekstowe AMPMapReduce, a następnie wybierz pozycję Właściwości.
W oknie dialogowym Strony właściwości, w obszarze Właściwości konfiguracji, wybierz pozycję Debugowanie. Upewnij się, że Lokalny debuger systemu Windows jest wybrany na liście Debuger do uruchomienia.
Wróć do Edytora kodu.
Ustaw punkty przerwania w wierszach kodu pokazanych na poniższej ilustracji (około wiersze 67 wierszy 70).

Punkty przerwania CPUNa pasku menu wybierz pozycję Debuguj>Rozpocznij debugowanie.
W oknie Lokals zwróć uwagę na wartość aż do momentu osiągnięcia punktu przerwania w wierszu 70.
Na pasku menu wybierz Debug>Zatrzymaj debugowanie.
Debugowanie kodu procesora GPU
W tej sekcji pokazano, jak debugować kod procesora GPU, który jest kodem zawartym w sum_kernel_tiled funkcji. Kod procesora GPU oblicza sumę liczb całkowitych dla każdego "bloku" równolegle.
Aby debugować kod procesora GPU
W Eksploratorze rozwiązań otwórz menu kontekstowe AMPMapReduce, a następnie wybierz pozycję Właściwości.
W oknie dialogowym Strony właściwości, w obszarze Właściwości konfiguracji, wybierz pozycję Debugowanie.
Na liście Debuger do uruchomienia wybierz pozycję Lokalny debuger systemu Windows.
Na liście Typ debugera sprawdź, czy wybrano opcję Auto.
Auto jest wartością domyślną. W wersjach wcześniejszych niż Windows 10 wartość GPU Only jest wymaganą wartością zamiast Auto.
Wybierz przycisk OK.
Ustaw punkt przerwania w wierszu 30, jak pokazano na poniższej ilustracji.

Punkt przerwania procesora GPUNa pasku menu wybierz pozycję Debuguj>Rozpocznij debugowanie. Punkty przerwania w kodzie procesora w wierszach 67 i 70 nie są wykonywane podczas debugowania na GPU, ponieważ te wiersze kodu działają na procesorze CPU.
Aby użyć okna Wątki GPU
Aby otworzyć okno Wątki procesora GPU, na pasku menu wybierz pozycję Debugujwątki> procesora GPU systemu Windows.>
Możesz sprawdzić stan wątków procesora GPU w wyświetlonym oknie Wątki procesora GPU.
Zadokuj okno Wątki GPU w dolnej części programu Visual Studio. Wybierz przycisk Rozwiń przełącznik wątku, aby wyświetlić pola tekstowe kafelka i wątku. W oknie Wątki GPU wyświetlana jest łączna liczba aktywnych i zablokowanych wątków GPU, jak pokazano na poniższej ilustracji.

Okno Wątki GPU313 kafelków zostanie przydzielonych do tego obliczenia. Każdy kafelek zawiera 32 wątki. Ponieważ lokalne debugowanie procesora GPU odbywa się w emulatorze oprogramowania, istnieją cztery aktywne wątki procesora GPU. Cztery wątki wykonują instrukcje jednocześnie, a następnie przechodzą razem do następnej instrukcji.
W oknie Wątki GPU aktywne są cztery wątki GPU, a 28 wątków jest zablokowanych w instrukcji tile_barrier::wait, zdefiniowanej w okolicach wiersza 21 (
t_idx.barrier.wait();). Wszystkie 32 wątki GPU należą do pierwszego kafelka,tile[0]. Strzałka wskazuje wiersz zawierający bieżący wątek. Aby przełączyć się na inny wątek, użyj jednej z następujących metod:W wierszu wątku, na który chcesz przełączyć się w oknie Wątków procesora GPU, otwórz menu skrótów i wybierz pozycję Przełącz do wątku. Jeśli wiersz reprezentuje więcej niż jeden wątek, przełączysz się do pierwszego wątku zgodnie ze współrzędnymi wątku.
Wprowadź wartości wątku i kafelka w odpowiednich polach tekstowych, a następnie wybierz przycisk Przełącz Wątek.
W oknie Stosu wywołań zostanie wyświetlony stos wywołań bieżącego wątku GPU.
Aby użyć okna stosów równoległych
Aby otworzyć okno Stosy równoległe, na pasku menu wybierz Debug>Windows>Stosy równoległe.
Możesz użyć okna Stosy równoległe, aby jednocześnie sprawdzić ramki stosu dla wielu wątków GPU.
Zadokuj okno Stosy równoległe w dolnej części programu Visual Studio.
Upewnij się, że na liście w lewym górnym rogu wybrano Wątki. Na poniższej ilustracji w oknie Stosy równoległe przedstawiono widok skoncentrowany na stosie wywołań wątków procesora GPU, które można zobaczyć w oknie Wątki procesora GPU.

Okno Stosów równoległych32 wątki przeszły z
_kernel_stubdo instrukcji lambda w wywołaniu funkcjiparallel_for_each, a następnie do funkcjisum_kernel_tiled, gdzie następuje redukowanie równoległe. 28 z 32 wątków dotarły do instrukcjitile_barrier::waiti pozostają zablokowane na wierszu 22, podczas gdy pozostałe cztery wątki pozostają aktywne w funkcjisum_kernel_tiledna wierszu 30.Możesz sprawdzić właściwości wątku GPU. Są one dostępne w oknie Wątki GPU w rozbudowanej etykietce danych okna Stosów Równoległych. Aby je zobaczyć, umieść wskaźnik na ramce stosu
sum_kernel_tiled. Na poniższej ilustracji przedstawiono DataTip.")
Etykietka danych wątku procesora GPUAby uzyskać więcej informacji na temat okna stosów równoległych, zobacz Korzystanie z okna stosów równoległych.
Aby użyć okna Zegarek Równoległy
Aby otworzyć okno Równoległa obserwacja, na pasku menu wybierz pozycję Debugowanie>Windows>Równoległa obserwacja>Równoległa obserwacja 1.
Możesz użyć okna Obserwatora równoległego, aby sprawdzić wartości wyrażenia w wielu wątkach.
Zadokuj okno Parallel Watch 1 do dołu programu Visual Studio. W tabeli okna Równoległego obserwowania znajdują się 32 wiersze. Każdy odpowiada wątkowi procesora GPU, który pojawił się zarówno w oknie Wątki procesora GPU, jak i w oknie Stosy równoległe . Teraz możesz wprowadzić wyrażenia, których wartości chcesz sprawdzić we wszystkich 32 wątkach procesora GPU.
Wybierz nagłówek kolumny Dodaj zegarek, wprowadź
localIdx, a następnie naciśnij Enter.Ponownie wybierz nagłówek kolumny Dodaj zegarek, wpisz
globalIdx, a następnie wybierz Enter.Ponownie wybierz nagłówek kolumny Dodaj zegarek, wpisz
localA[localIdx[0]], a następnie wybierz Enter.Można sortować według określonego wyrażenia, wybierając odpowiedni nagłówek kolumny.
Wybierz nagłówek kolumny localA[localIdx[0]], aby posortować kolumnę. Poniższa ilustracja przedstawia wyniki sortowania według localA[localIdx[0]].

Wyniki sortowaniaZawartość można wyeksportować w oknie Parallel Watch do programu Excel, wybierając przycisk programu Excel , a następnie wybierając pozycję Otwórz w programie Excel. Jeśli program Excel jest zainstalowany na komputerze dewelopera, przycisk otwiera arkusz programu Excel zawierający zawartość.
W prawym górnym rogu okna Parallel Watch znajduje się kontrolka filtru, które można użyć do filtrowania zawartości przy użyciu wyrażeń logicznych. Wprowadź
localA[localIdx[0]] > 20000w polu tekstowym kontrolki filtru, a następnie wybierz Enter .Okno zawiera teraz tylko wątki, na których
localA[localIdx[0]]wartość jest większa niż 20000. Zawartość jest nadal sortowana wedługlocalA[localIdx[0]]kolumny, czyli wybranej wcześniej akcji sortowania.
Flagowanie wątków procesora GPU
Określone wątki GPU można oznaczyć, flagując je w oknie Wątki GPU, w oknie Równoległe śledzenie lub w podpowiedzi danych w oknie Stosy równoległe. Jeśli wiersz w oknie wątki GPU zawiera więcej niż jeden wątek, oznaczenie tego wiersza powoduje oznaczenie wszystkich wątków zawartych w tym wierszu.
Aby oznaczyć wątki GPU
Wybierz nagłówek kolumny [Thread] w oknie Parallel Watch 1, aby sortować według indeksu kafelka i indeksu wątku.
Na pasku menu wybierz pozycję Debuguj>kontynuuj, co powoduje, że cztery aktywne wątki przechodzą do następnej bariery (zdefiniowanej w wierszu 32 AMPMapReduce.cpp).
Wybierz symbol flagi po lewej stronie wiersza, który zawiera cztery wątki, które są teraz aktywne.
Na poniższej ilustracji przedstawiono cztery aktywne wątki oznaczone w oknie Wątki GPU.

Aktywne wątki w oknie Wątki GPUOkno Obserwacja równoległa i dymek danych okna Stosów równoległych wskazują oflagowane wątki.
Jeśli chcesz skupić się na czterech oflagowanych wątkach, możesz wybrać wyświetlanie tylko oflagowanych wątków. Ogranicza to, co widzisz w oknach Wątki GPU, Zegar równoległy i Stosy równoległe.
Wybierz przycisk Pokaż tylko oznaczone na dowolnym z okien lub na pasku narzędzi Debugowanie. Poniższa ilustracja przedstawia przycisk Pokaż tylko oflagowane na pasku narzędzi debugowania lokalizacji.

Pokaż tylko oflagowaneTeraz okna Wątki GPU, Równoległy zegar i Równoległe stosy wyświetlają tylko oflagowane wątki.
Zamrażanie i odmrażanie wątków procesora GPU
Możesz zamrozić (wstrzymać) i odmrozić (wznowić) wątki GPU z okna Wątki GPU lub Równoległe Śledzenie. Można zablokować i odblokować wątki procesora w taki sam sposób; aby uzyskać informacje, zobacz Jak używać okna Wątki.
Aby zablokować i rozmrozić wątki procesora GPU
Wybierz przycisk Pokaż tylko oflagowane, aby wyświetlić tylko oflagowane wątki.
Na pasku menu wybierz pozycję Debuguj>kontynuuj.
Otwórz menu skrótów dla aktywnego wiersza, a następnie wybierz pozycję Blokuj.
Poniższa ilustracja okna Wątki GPU pokazuje, że wszystkie cztery wątki są zamrożone.

Zamrożone wątki GPU w oknie WątkówPodobnie okno Parallel Watch pokazuje, że wszystkie cztery wątki są zamrożone.
Na pasku menu wybierz
Debug Kontynuuj , aby pozwolić następnym czterem wątkom GPU przejść przez barierę w wierszu 22 i dotrzeć do punktu przerwania w wierszu 30. Okno Wątki GPU pokazuje, że cztery wcześniej zamrożone wątki pozostają zamrożone i są aktywne.Na pasku menu wybierz pozycję Debuguj, Kontynuuj.
W oknie Parallel Watch można również rozmrozić poszczególne lub wiele wątków GPU.
Aby zgrupować wątki procesora GPU
W menu skrótów dla jednego z wątków w oknie Wątki GPU wybierz Grupuj według, Adres.
Wątki w oknie Wątki GPU są pogrupowane według adresu. Adres odpowiada instrukcji w dekompilacji, w której znajduje się każda grupa wątków. 24 wątki znajdują się w wierszu 22, gdzie wykonuje się metoda tile_barrier::wait. 12 wątków znajdują się w instrukcji dla bariery w wierszu 32. Cztery z tych wątków są oflagowane. Osiem wątków znajdują się w punkcie przerwania w wierszu 30. Cztery z tych wątków są zamrożone. Na poniższej ilustracji przedstawiono pogrupowane wątki w oknie Wątki GPU.

Pogrupowane wątki w oknie Wątków GPUMożesz również wykonać operację Group By, otwierając menu kontekstowe dla siatki danych okna Parallel Watch. Wybierz pozycję Grupuj według, a następnie wybierz element menu odpowiadający sposobom grupowania wątków.
Uruchamianie wszystkich wątków do określonej lokalizacji w kodzie
Uruchamiasz wszystkie wątki w danym kafelku do wiersza zawierającego kursor za pomocą Uruchom bieżący kafelek do kursora.
Aby doprowadzić wszystkie wątki do lokalizacji oznaczonej kursorem
W menu skrótów dla zamrożonych wątków wybierz pozycję Thaw.
W Edytorze kodu umieść kursor w wierszu 30.
W menu skrótów dla Edytora Kodów wybierz pozycję Uruchom bieżący blok do kursora.
24 wątki, które zostały wcześniej zablokowane w barierze na linii 21, postępują do linii 32. Jest on wyświetlany w oknie Wątki GPU.
Zobacz także
Omówienie C++ AMP
Debugowanie kodu procesora GPU
Instrukcje: korzystanie z okna wątków GPU
Jak używać okna równoległego podglądu
Analizowanie kodu C++ AMP za pomocą wizualizatora współbieżności