Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W tym przewodniku krok po kroku pokazano, jak używać języka C++ AMP w celu przyspieszenia wykonywania mnożenia macierzy. Prezentowane są dwa algorytmy: jeden bez użycia techniki tilingu i jeden z jej użyciem.
Wymagania wstępne
Przed rozpoczęciem:
- Przeczytaj C++ AMP Overview.
- Odczytywanie przy użyciu kafelków.
- Upewnij się, że używasz co najmniej systemu Windows 7 lub Windows Server 2008 R2.
Uwaga / Notatka
Nagłówki C++ AMP są przestarzałe, począwszy od programu Visual Studio 2022 w wersji 17.0.
Dołączenie wszystkich nagłówków AMP spowoduje wygenerowanie błędów kompilacji. Zdefiniuj _SILENCE_AMP_DEPRECATION_WARNINGS przed dołączeniem jakichkolwiek nagłówków AMP, aby wyciszyć ostrzeżenia.
Aby utworzyć projekt
Instrukcje dotyczące tworzenia nowego projektu różnią się w zależności od zainstalowanej wersji programu Visual Studio. Aby zapoznać się z dokumentacją preferowanej wersji programu Visual Studio, użyj kontrolki selektora wersji . Znajduje się on w górnej części spisu treści na tej stronie.
Aby utworzyć projekt w programie Visual Studio
Na pasku menu wybierz Plik>Nowy>Projekt, aby otworzyć okno dialogowe Utwórz Nowy Projekt.
W górnej części okna dialogowego ustaw wartość Language na C++, ustaw wartość Platforma na Windows, a następnie ustaw wartość Project type (Typ projektu) na Console (Konsola).
Z filtrowanej listy typów projektów wybierz pozycję Pusty projekt , a następnie wybierz pozycję Dalej. Na następnej stronie wprowadź wartość MatrixMultiply w polu Nazwa , aby określić nazwę projektu i w razie potrzeby określić lokalizację projektu.
Wybierz przycisk Utwórz, aby utworzyć projekt klienta.
W Eksploratorze rozwiązań otwórz menu skrótów dla Plików źródłowych, a następnie wybierz pozycję Dodaj>Nowy element.
W oknie dialogowym Dodawanie nowego elementu wybierz pozycję Plik C++ (.cpp), wprowadź MatrixMultiply.cpp w polu Nazwa, a następnie wybierz przycisk Dodaj.
Mnożenie bez tilingu
W tej sekcji rozważ mnożenie dwóch macierzy, A i B, które są zdefiniowane w następujący sposób:
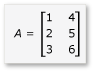

A jest macierzą 3 po 2, a B jest macierzą 2 po 3. Pomnożenie A przez B jest następującą macierzą 3-do-3. Produkt oblicza się przez pomnożenie wierszy A przez kolumny B element po elemencie.

Mnożenie bez użycia języka C++ AMP
Otwórz MatrixMultiply.cpp i użyj następującego kodu, aby zastąpić istniejący kod.
#include <iostream> void MultiplyWithOutAMP() { int aMatrix[3][2] = {{1, 4}, {2, 5}, {3, 6}}; int bMatrix[2][3] = {{7, 8, 9}, {10, 11, 12}}; int product[3][3] = {{0, 0, 0}, {0, 0, 0}, {0, 0, 0}}; for (int row = 0; row < 3; row++) { for (int col = 0; col < 3; col++) { // Multiply the row of A by the column of B to get the row, column of product. for (int inner = 0; inner < 2; inner++) { product[row][col] += aMatrix[row][inner] * bMatrix[inner][col]; } std::cout << product[row][col] << " "; } std::cout << "\n"; } } int main() { MultiplyWithOutAMP(); getchar(); }Algorytm jest prostą implementacją definicji mnożenia macierzy. Nie używa żadnych algorytmów równoległych ani wątkowych w celu skrócenia czasu obliczeń.
Na pasku menu wybierz pozycję Plik>Zapisz wszystko.
Wybierz skrót klawiaturowy F5 , aby rozpocząć debugowanie i sprawdzić, czy dane wyjściowe są poprawne.
Wybierz Enter , aby zamknąć aplikację.
Aby pomnożyć używając C++ AMP
W pliku MatrixMultiply.cpp dodaj następujący kod przed metodą
main.void MultiplyWithAMP() { int aMatrix[] = { 1, 4, 2, 5, 3, 6 }; int bMatrix[] = { 7, 8, 9, 10, 11, 12 }; int productMatrix[] = { 0, 0, 0, 0, 0, 0, 0, 0, 0 }; array_view<int, 2> a(3, 2, aMatrix); array_view<int, 2> b(2, 3, bMatrix); array_view<int, 2> product(3, 3, productMatrix); parallel_for_each(product.extent, [=] (index<2> idx) restrict(amp) { int row = idx[0]; int col = idx[1]; for (int inner = 0; inner <2; inner++) { product[idx] += a(row, inner)* b(inner, col); } }); product.synchronize(); for (int row = 0; row <3; row++) { for (int col = 0; col <3; col++) { //std::cout << productMatrix[row*3 + col] << " "; std::cout << product(row, col) << " "; } std::cout << "\n"; } }Kod AMP przypomina kod inny niż AMP. Wywołanie
parallel_for_eachuruchamia jeden wątek dla każdego elementu wproduct.extenti zastępuje pętlefordla wierszy i kolumn. Wartość komórki w wierszu i kolumnie jest dostępna w plikuidx. Dostęp do elementówarray_viewobiektu można uzyskać przy użyciu[]operatora i zmiennej indeksu albo()operatora oraz zmiennych wierszy i kolumn. W przykładzie przedstawiono obie metody. Metodaarray_view::synchronizekopiuje wartości zmiennejproductz powrotem do zmiennejproductMatrix.Dodaj następujące instrukcje
includeiusingna początku MatrixMultiply.cpp.#include <amp.h> using namespace concurrency;Zmodyfikuj metodę ,
mainaby wywołać metodęMultiplyWithAMP.int main() { MultiplyWithOutAMP(); MultiplyWithAMP(); getchar(); }Naciśnij skrót klawiaturowy Ctrl+F5, aby rozpocząć debugowanie i sprawdzić, czy dane wyjściowe są poprawne.
Naciśnij spację, aby zamknąć aplikację.
Mnożenie z kafelkowaniem
Tiling to technika, w której dzielisz dane na podzestawy o równym rozmiarze, które są nazywane kafelkami. Trzy rzeczy zmieniają się podczas korzystania z tilingu.
Można tworzyć
tile_staticzmienne. Dostęp do danych wtile_staticprzestrzeni może być wielokrotnie szybszy niż dostęp do danych w przestrzeni globalnej. Dla każdej kafli tworzone jest wystąpienie zmiennejtile_static, a wszystkie wątki w kafli mają dostęp do zmiennej. Główną zaletą kafelkowania jest wzrost wydajności ze względu natile_staticdostęp.Możesz wywołać metodę tile_barrier::wait , aby zatrzymać wszystkie wątki w jednym kafelku w określonym wierszu kodu. Nie można zagwarantować kolejności uruchamiania wątków; można tylko zapewnić, że wszystkie wątki w jednym kafelku zatrzymają się przy wywołaniu
tile_barrier::waitzanim będą mogły kontynuować wykonywanie.Masz dostęp do indeksu wątku w odniesieniu do całego obiektu
array_vieworaz indeksu względem kafelka. Korzystając z indeksu lokalnego, możesz ułatwić odczytywanie i debugowanie kodu.
Aby móc korzystać z podziału na podmacierze w mnożeniu macierzy, algorytm musi podzielić macierz na podmacierze, a następnie skopiować dane z podmacierzy do zmiennych tile_static, aby przyspieszyć dostęp. W tym przykładzie macierz jest podzielona na submacierze o równym rozmiarze. Produkt można znaleźć przez pomnożenie podmatry. Dwa macierze i ich produkt w tym przykładzie to:
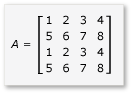
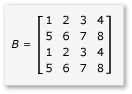
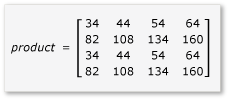
Macierze są podzielone na cztery macierze 2x2, które są zdefiniowane w następujący sposób:


Produkt A i B można teraz napisać i obliczyć w następujący sposób:
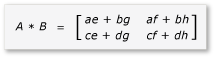
Ponieważ macierze a przez h to macierze 2x2, wszystkie ich iloczyny i sumy są również macierzami 2x2. Z tego również wynika, że produkt A i B jest macierzą 4x4, zgodnie z oczekiwaniami. Aby szybko sprawdzić algorytm, oblicz wartość elementu w pierwszym wierszu, pierwszą kolumnę w produkcie. W tym przykładzie będzie to wartość elementu w pierwszym wierszu i pierwszej kolumnie .ae + bg Musisz obliczyć tylko pierwszą kolumnę, pierwszy wiersz ae i bg dla każdego terminu. Ta wartość dla ae parametru to (1 * 1) + (2 * 5) = 11. Wartość parametru bg to (3 * 1) + (4 * 5) = 23. Końcowa wartość to 11 + 23 = 34, która jest poprawna.
Aby zaimplementować ten algorytm, kod:
Używa obiektu
tiled_extentzamiast obiektuextentw wywołaniuparallel_for_each.Używa obiektu
tiled_indexzamiast obiektuindexw wywołaniuparallel_for_each.Tworzy zmienne
tile_staticdo przechowywania submacierzy.Używa metody
tile_barrier::wait, aby zatrzymać wątki na potrzeby obliczania produktów podmacierzy.
Aby pomnożyć przy użyciu AMP i kafelkowania
W pliku MatrixMultiply.cpp dodaj następujący kod przed metodą
main.void MultiplyWithTiling() { // The tile size is 2. static const int TS = 2; // The raw data. int aMatrix[] = { 1, 2, 3, 4, 5, 6, 7, 8, 1, 2, 3, 4, 5, 6, 7, 8 }; int bMatrix[] = { 1, 2, 3, 4, 5, 6, 7, 8, 1, 2, 3, 4, 5, 6, 7, 8 }; int productMatrix[] = { 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 }; // Create the array_view objects. array_view<int, 2> a(4, 4, aMatrix); array_view<int, 2> b(4, 4, bMatrix); array_view<int, 2> product(4, 4, productMatrix); // Call parallel_for_each by using 2x2 tiles. parallel_for_each(product.extent.tile<TS, TS>(), [=] (tiled_index<TS, TS> t_idx) restrict(amp) { // Get the location of the thread relative to the tile (row, col) // and the entire array_view (rowGlobal, colGlobal). int row = t_idx.local[0]; int col = t_idx.local[1]; int rowGlobal = t_idx.global[0]; int colGlobal = t_idx.global[1]; int sum = 0; // Given a 4x4 matrix and a 2x2 tile size, this loop executes twice for each thread. // For the first tile and the first loop, it copies a into locA and e into locB. // For the first tile and the second loop, it copies b into locA and g into locB. for (int i = 0; i < 4; i += TS) { tile_static int locA[TS][TS]; tile_static int locB[TS][TS]; locA[row][col] = a(rowGlobal, col + i); locB[row][col] = b(row + i, colGlobal); // The threads in the tile all wait here until locA and locB are filled. t_idx.barrier.wait(); // Return the product for the thread. The sum is retained across // both iterations of the loop, in effect adding the two products // together, for example, a*e. for (int k = 0; k < TS; k++) { sum += locA[row][k] * locB[k][col]; } // All threads must wait until the sums are calculated. If any threads // moved ahead, the values in locA and locB would change. t_idx.barrier.wait(); // Now go on to the next iteration of the loop. } // After both iterations of the loop, copy the sum to the product variable by using the global location. product[t_idx.global] = sum; }); // Copy the contents of product back to the productMatrix variable. product.synchronize(); for (int row = 0; row <4; row++) { for (int col = 0; col <4; col++) { // The results are available from both the product and productMatrix variables. //std::cout << productMatrix[row*3 + col] << " "; std::cout << product(row, col) << " "; } std::cout << "\n"; } }Ten przykład znacznie różni się od przykładu bez kafelkowania. Kod używa następujących kroków koncepcyjnych:
Skopiuj elementy z kafelka[0,0]
adolocA. Skopiuj elementy z kafelka[0,0]bdolocB. Zwróć uwagę, żeproductjest kafelkowany, a nie aniaanib. W związku z tym, należy używać globalnych indeksów do uzyskiwania dostępu doa, borazproduct. Wezwanie dotile_barrier::waitjest niezbędne. Spowoduje to zatrzymanie wszystkich wątków na kafelku, dopóki zarównolocA, jak ilocBnie zostaną wypełnione.Pomnóż
locAilocBumieść wyniki w plikuproduct.Skopiuj elementy kafelka[0,1] z
adolocA. Skopiuj elementy kafelka [1,0] zbdolocB.Pomnóż
locAilocB, a następnie dodaj je do wyników, które znajdują się już wproduct.Mnożenie kafelka[0,0] zostało ukończone.
Powtórz dla pozostałych czterech kafelków. Nie ma indeksowania specjalnie dla kafelków, a wątki mogą być wykonywane w dowolnej kolejności. Podczas wykonywania każdego wątku, zmienne
tile_staticsą odpowiednio tworzone dla każdego kafelka, a wywołanietile_barrier::wait, które steruje przepływem programu.Podczas dokładnego badania algorytmu zwróć uwagę, że każdy podmatrix jest ładowany do
tile_staticpamięci dwa razy. Transfer danych zajmuje trochę czasu. Jednak gdy dane są wtile_staticpamięci, dostęp do danych jest znacznie szybszy. Ponieważ obliczanie produktów wymaga wielokrotnego dostępu do wartości w podmatrych, istnieje ogólny wzrost wydajności. W przypadku każdego algorytmu eksperymentowanie jest wymagane do znalezienia optymalnego algorytmu i rozmiaru kafelka.
W przykładach innych niż AMP i innych niż kafelki każdy element A i B jest dostępny cztery razy z pamięci globalnej w celu obliczenia produktu. W przykładzie kafelka każdy element jest odczytywany dwa razy z pamięci globalnej i cztery razy z pamięci
tile_static. To nie jest znaczący wzrost wydajności. Jeśli jednak macierze A i B były 1024x1024, a rozmiar kafelka był 16, byłby znaczący wzrost wydajności. W takim przypadku każdy element zostanie skopiowany dotile_staticpamięci tylko 16 razy i uzyskiwany do nich dostęp ztile_staticpamięci 1024 razy.Zmodyfikuj metodę main, aby wywołać metodę
MultiplyWithTiling, jak pokazano poniżej.int main() { MultiplyWithOutAMP(); MultiplyWithAMP(); MultiplyWithTiling(); getchar(); }Naciśnij skrót klawiaturowy Ctrl+F5, aby rozpocząć debugowanie i sprawdzić, czy dane wyjściowe są poprawne.
Naciśnij pasek spacji, aby zamknąć aplikację.
Zobacz także
C++ AMP (C++ Accelerated Massive Parallelism)
Przewodnik: debugowanie aplikacji C++ AMP