Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Napiwek
Ta zawartość jest fragmentem książki eBook, Architekting Cloud Native .NET Applications for Azure, dostępnej na platformie .NET Docs lub jako bezpłatny plik PDF do pobrania, który można odczytać w trybie offline.

Relacyjne (SQL) i nierelacyjne (NoSQL) to dwa typy systemów baz danych, które są często implementowane w aplikacjach natywnych dla chmury. Są one tworzone inaczej, przechowują dane inaczej i uzyskują do nich dostęp w inny sposób. W tej sekcji przyjrzymy się obu. W dalszej części tego rozdziału przyjrzymy się nowej technologii bazy danych o nazwie NewSQL.
Relacyjne bazy danych są powszechną technologią od dziesięcioleci. Są dojrzałe, sprawdzone i szeroko zaimplementowane. Konkurencyjne produkty bazy danych, narzędzia i wiedza specjalistyczna obfitują. Relacyjne bazy danych zapewniają magazyn powiązanych tabel danych. Te tabele mają stały schemat, używają języka SQL (Structured Query Language) do zarządzania danymi i obsługują gwarancje ACID: niepodzielność, spójność, izolacja i trwałość.
Bazy danych NoSQL odnoszą się do magazynów danych o wysokiej wydajności, nierelacyjnych. Doskonale sprawdzają się w swoich cechach łatwości użycia, skalowalności, odporności i dostępności. Zamiast dołączać tabele znormalizowanych danych, program NoSQL przechowuje dane bez struktury lub częściowo ustrukturyzowane, często w parach klucz-wartość lub dokumentach JSON. Bazy danych NoSQL zwykle nie zapewniają gwarancji ACID poza zakresem pojedynczej partycji bazy danych. Usługi o dużej ilości, które wymagają czasu drugiej odpowiedzi, faworyzują magazyny danych NoSQL.
Nie można przecenić wpływu technologii NoSQL dla rozproszonych systemów natywnych dla chmury. Rozprzestrzenianie nowych technologii danych w tej przestrzeni zakłóciło rozwiązania, które kiedyś polegały wyłącznie na relacyjnych bazach danych.
Bazy danych NoSQL obejmują kilka różnych modeli uzyskiwania dostępu do danych i zarządzania nimi, z których każda jest odpowiednia do konkretnych przypadków użycia. Rysunek 5–9 przedstawia cztery typowe modele.
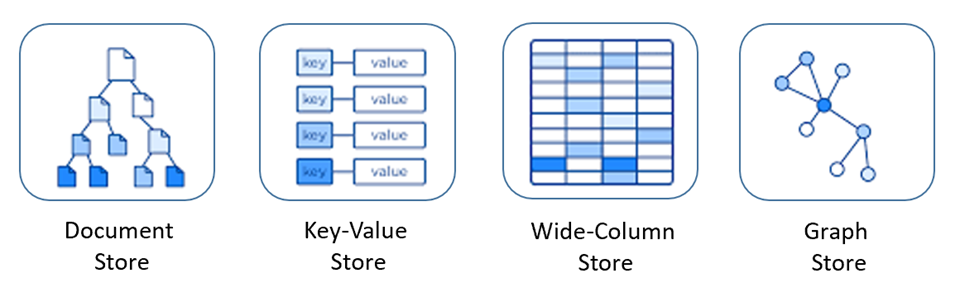
Rysunek 5–9. Modele danych dla baz danych NoSQL
| Model | Charakterystyki |
|---|---|
| Magazyn dokumentów | Dane i metadane są przechowywane hierarchicznie w dokumentach opartych na formacie JSON w bazie danych. |
| Magazyn wartości klucza | Najprostsze bazy danych NoSQL są reprezentowane jako kolekcja par klucz-wartość. |
| Magazyn szerokich kolumn | Powiązane dane są przechowywane jako zestaw par zagnieżdżonych klucz/wartość w jednej kolumnie. |
| Magazyn grafowy | Dane są przechowywane w strukturze grafu jako właściwości węzła, krawędzi i danych. |
Twierdzenie CAP i PACELC
Aby zrozumieć różnice między tymi typami baz danych, należy wziąć pod uwagę twierdzenie CAP, zestaw zasad stosowanych do systemów rozproszonych, które przechowują stan. Rysunek 5–10 przedstawia trzy właściwości twierdzenia CAP.
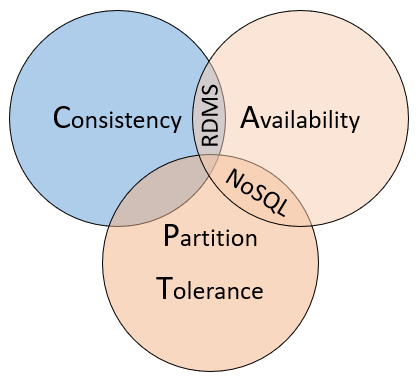
Rysunek 5–10. Twierdzenie CAP
Twierdzenie stwierdza, że rozproszone systemy danych oferują kompromis między spójnością, dostępnością i tolerancją partycji. Ponadto każda baza danych może zagwarantować tylko dwie z trzech właściwości:
Spójność. Każdy węzeł w klastrze odpowiada najnowszymi danymi, nawet jeśli system musi zablokować żądanie do momentu zaktualizowania wszystkich replik. Jeśli wykonasz zapytanie dotyczące "spójnego systemu" dla elementu, który jest obecnie aktualizowany, poczekasz na odpowiedź, aż wszystkie repliki zostaną pomyślnie zaktualizowane. Otrzymasz jednak najbardziej aktualne dane. Należy rozumieć, że termin "spójność", który jest używany w kontekście twierdzenia CAP, ma znaczenie techniczne, które różni się od sposobu definiowania "spójności" w kontekście gwarancji ACID.
Dostępność. Każde żądanie odebrane przez węzeł, który nie kończy się niepowodzeniem w systemie, musi spowodować odpowiedź. Mówiąc po prostu, jeśli wykonasz zapytanie o "dostępny system" dla elementu, który jest aktualizowany, uzyskasz najlepszą możliwą odpowiedź, którą usługa może dostarczyć w tej chwili. Należy jednak pamiętać, że "dostępność" zdefiniowana przez twierdzenie CAP różni się technicznie od "wysokiej dostępności", ponieważ jest ona tradycyjnie znana z systemów rozproszonych.
Tolerancja partycji. Gwarantuje, że system nadal działa, nawet jeśli zreplikowany węzeł danych ulegnie awarii lub utraci łączność z innymi replikowanymi węzłami danych.
Twierdzenie CAP wyjaśnia kompromisy związane z zarządzaniem spójnością i dostępnością podczas partycji sieciowej; jednak kompromisy w zakresie spójności i wydajności również występują z brakiem partycji sieciowej.
Uwaga
Nawet jeśli wybierzesz dostępność w ramach spójności, w czasach partycji sieciowej dostępność będzie cierpieć. Dostępny system CAP jest bardziej dostępny dla niektórych swoich klientów, ale niekoniecznie jest "wysoce dostępny" dla wszystkich swoich klientów.
Twierdzenie CAP jest często dalej rozszerzane na PACELC , aby wyjaśnić kompromisy bardziej kompleksowo. Twierdzenie CAP jest szczególnie istotne w sporadycznie połączonych środowiskach, takich jak te związane z Internetem rzeczy (IoT), monitorowanie środowiska i aplikacje mobilne. W tych kontekstach urządzenia mogą zostać odizolowane z powodu trudnych warunków fizycznych, takich jak przerwy w zasilaniu lub gdy wchodzą do zamkniętych przestrzeni, takich jak windy. W przypadku systemów rozproszonych, takich jak aplikacje w chmurze, bardziej odpowiednie jest użycie twierdzenia PACELC, który jest bardziej kompleksowy i uwzględnia kompromisy, takie jak opóźnienia i spójność nawet w przypadku braku partycji sieciowych.
Relacyjne bazy danych zwykle zapewniają spójność i dostępność, ale nie tolerancję partycji. Zazwyczaj są one aprowidowane na jednym serwerze i skalowane w pionie przez dodanie większej liczby zasobów do maszyny.
Wiele systemów relacyjnych baz danych obsługuje wbudowane funkcje replikacji, w których kopie podstawowej bazy danych mogą być tworzone do innych wystąpień serwera pomocniczego. Operacje zapisu są wykonywane w wystąpieniu podstawowym i replikowane do każdego z serwerów pomocniczych. Po awarii wystąpienie podstawowe może przejść w tryb failover do pomocniczej, aby zapewnić wysoką dostępność. Pomocniczych można również użyć do dystrybucji operacji odczytu. Podczas gdy operacje zapisu zawsze są wykonywane względem repliki podstawowej, operacje odczytu można kierować do dowolnego z pomocniczych obiektów w celu zmniejszenia obciążenia systemu.
Dane mogą być również partycjonowane w poziomie w wielu węzłach, na przykład przy użyciu fragmentowania. Jednak fragmentowanie znacznie zwiększa nakład pracy operacyjnej, plując dane między wieloma elementami, które nie mogą łatwo komunikować się. Zarządzanie może być kosztowne i czasochłonne. Funkcje relacyjne, które obejmują sprzężenia tabeli, transakcje i integralność referencyjną, wymagają stromych kar za wydajność we wdrożeniach podzielonych na fragmenty.
Spójność replikacji i cele punktu odzyskiwania można dostosować, konfigurując, czy replikacja odbywa się synchronicznie, czy asynchronicznie. Gdyby repliki danych utraciły łączność sieciową w klastrze "wysoce spójnym" lub synchronicznym relacyjnym klastrze bazy danych, nie będzie można zapisywać w bazie danych. System odrzuci operację zapisu, ponieważ nie może replikować tej zmiany do innego repliki danych. Każda replika danych musi być aktualizowana przed ukończeniem transakcji.
Bazy danych NoSQL zwykle obsługują wysoką dostępność i tolerancję partycji. Są one skalowane w poziomie, często na serwerach towarowych. Takie podejście zapewnia ogromną dostępność zarówno w regionach geograficznych, jak i w różnych regionach geograficznych przy obniżonych kosztach. Partycjonujesz i replikujesz dane na tych maszynach lub węzłach, zapewniając nadmiarowość i odporność na uszkodzenia. Spójność jest zwykle dostrojona za pomocą protokołów konsensusu lub mechanizmów kworum. Zapewniają one większą kontrolę podczas nawigowania po kompromisach między dostrajaniem synchronicznej a asynchronicznej replikacji w systemach relacyjnych.
Jeśli repliki danych utraciły łączność w klastrze bazy danych NoSQL o wysokiej dostępności, nadal można ukończyć operację zapisu w bazie danych. Klaster bazy danych zezwoli na operację zapisu i zaktualizuje każdą replikę danych, gdy stanie się dostępna. Bazy danych NoSQL, które obsługują wiele replik zapisywalnych, mogą dodatkowo zwiększyć wysoką dostępność, unikając konieczności przejścia w tryb failover podczas optymalizowania celu czasu odzyskiwania.
Nowoczesne bazy danych NoSQL zwykle implementują możliwości partycjonowania jako cechę projektu systemu. Zarządzanie partycjami jest często wbudowane w bazę danych, a routing jest osiągany za pomocą wskazówek dotyczących umieszczania — często nazywanych kluczami partycji. Elastyczne modele danych umożliwiają bazom danych NoSQL obniżenie obciążenia zarządzania schematami i zwiększenie dostępności podczas wdrażania aktualizacji aplikacji, które wymagają zmian modelu danych.
Wysoka dostępność i ogromna skalowalność są często bardziej krytyczne dla firmy niż sprzężenia tabeli relacyjnej i integralność referencyjna. Deweloperzy mogą implementować techniki i wzorce, takie jak Sagas, CQRS i asynchroniczne komunikaty, aby objąć spójność ostateczną.
W dzisiejszych czasach należy wziąć pod uwagę ograniczenia twierdzenia CAP. Pojawił się nowy typ bazy danych o nazwie NewSQL, który rozszerza aparat relacyjnej bazy danych na obsługę zarówno skalowalności poziomej, jak i skalowalnej wydajności systemów NoSQL.
Zagadnienia dotyczące systemów relacyjnych a NoSQL
Na podstawie określonych wymagań dotyczących danych mikrousługa oparta na chmurze może implementować relacyjny magazyn danych NoSQL lub oba te elementy.
| Rozważ magazyn danych NoSQL, gdy: | Rozważmy relacyjną bazę danych, gdy: |
|---|---|
| Masz duże obciążenia, które wymagają przewidywalnego opóźnienia na dużą skalę (na przykład opóźnienia mierzone w milisekundach podczas wykonywania milionów transakcji na sekundę) | Wolumin obciążenia zazwyczaj mieści się w tysiącach transakcji na sekundę |
| Dane są dynamiczne i często zmieniają się | Dane są wysoce ustrukturyzowane i wymagają integralności referencyjnej |
| Relacje mogą być znormalizowanymi modelami danych | Relacje są wyrażane za pomocą sprzężeń tabeli w znormalizowanych modelach danych |
| Pobieranie danych jest proste i wyrażone bez sprzężeń tabeli | Pracujesz z złożonymi zapytaniami i raportami |
| Dane są zwykle replikowane w różnych lokalizacjach geograficznych i wymagają bardziej precyzyjnej kontroli nad spójnością, dostępnością i wydajnością | Dane są zwykle scentralizowane lub mogą być replikowane asynchronicznie |
| Aplikacja zostanie wdrożona na sprzęcie towarów, takim jak w chmurach publicznych | Aplikacja zostanie wdrożona na dużym sprzęcie wysokiej klasy |
W następnych sekcjach zapoznamy się z opcjami dostępnymi w chmurze platformy Azure na potrzeby przechowywania danych natywnych dla chmury i zarządzania nimi.
Baza danych jako usługa
Aby rozpocząć, możesz aprowizować maszynę wirtualną platformy Azure i zainstalować wybraną bazę danych dla każdej usługi. Chociaż masz pełną kontrolę nad środowiskiem, możesz zająć się wieloma wbudowanymi funkcjami platformy w chmurze. Odpowiadasz również za zarządzanie maszyną wirtualną i bazą danych dla każdej usługi. Takie podejście może szybko stać się czasochłonne i kosztowne.
Zamiast tego aplikacje natywne dla chmury faworyzują usługi danych udostępniane jako baza danych jako usługa (DBaaS). W pełni zarządzane przez dostawcę usług w chmurze te usługi zapewniają wbudowane zabezpieczenia, skalowalność i monitorowanie. Zamiast być właścicielem usługi, po prostu używasz jej jako usługi zapasowej. Dostawca obsługuje zasób na dużą skalę i ponosi odpowiedzialność za wydajność i konserwację.
Można je skonfigurować w różnych strefach dostępności chmury i regionach w celu zapewnienia wysokiej dostępności. Wszystkie obsługują pojemność just in time i model płatności zgodnie z rzeczywistym użyciem. Platforma Azure oferuje różne rodzaje opcji usługi danych zarządzanych, z których każda ma określone korzyści.
Najpierw przyjrzymy się usługom relacyjnym DBaaS dostępnym na platformie Azure. Zobaczysz, że flagowa baza danych programu SQL Server firmy Microsoft jest dostępna wraz z kilkoma opcjami typu open source. Następnie omówimy usługi danych NoSQL na platformie Azure.
Relacyjne bazy danych platformy Azure
W przypadku mikrousług natywnych dla chmury, które wymagają danych relacyjnych, platforma Azure oferuje cztery zarządzane relacyjne bazy danych jako usługę (DBaaS) przedstawione na rysunku 5–11.

Rysunek 5–11. Zarządzane relacyjne bazy danych dostępne na platformie Azure
Na poprzedniej ilustracji zwróć uwagę na to, jak każda z nich znajduje się na wspólnej infrastrukturze DBaaS, która oferuje kluczowe możliwości bez dodatkowych kosztów.
Te funkcje są szczególnie ważne dla organizacji, które udostępniają dużą liczbę baz danych, ale mają ograniczone zasoby do ich administrowania. Bazę danych platformy Azure można aprowizować w ciągu kilku minut, wybierając ilość rdzeni przetwarzania, pamięci i magazynu bazowego. Bazę danych można skalować na bieżąco i dynamicznie dostosowywać zasoby bez przestojów.
Azure SQL Database
Zespoły programistyczne z wiedzą specjalistyczną w programie Microsoft SQL Server powinny rozważyć usługę Azure SQL Database. Jest to w pełni zarządzana relacyjna baza danych jako usługa (DBaaS) oparta na aucie bazy danych programu Microsoft SQL Server. Usługa udostępnia wiele funkcji znalezionych w lokalnej wersji programu SQL Server i uruchamia najnowszą stabilną wersję aparatu bazy danych programu SQL Server.
Do użycia z mikrousługą natywną dla chmury usługa Azure SQL Database jest dostępna z trzema opcjami wdrażania:
Pojedyncza baza danych reprezentuje w pełni zarządzaną usługę SQL Database działającą na serwerze usługi Azure SQL Database w chmurze platformy Azure. Baza danych jest uważana za zawartą , ponieważ nie ma zależności konfiguracji na bazowym serwerze bazy danych.
Wystąpienie zarządzane to w pełni zarządzane wystąpienie aparatu bazy danych programu Microsoft SQL Server, które zapewnia niemal 100% zgodność z lokalnym programem SQL Server. Ta opcja obsługuje większe bazy danych do 35 TB i jest umieszczana w sieci wirtualnej platformy Azure w celu uzyskania lepszej izolacji.
Bezserwerowa usługa Azure SQL Database to warstwa obliczeniowa dla pojedynczej bazy danych, która automatycznie skaluje się na podstawie zapotrzebowania na obciążenie. Opłaty są naliczane tylko za ilość używanej mocy obliczeniowej na sekundę. Usługa jest odpowiednia dla obciążeń ze sporadycznymi, nieprzewidywalnymi wzorcami użycia, sporadycznymi okresami braku aktywności. Warstwa obliczeniowa bezserwerowa automatycznie wstrzymuje również bazy danych w okresach nieaktywnych, aby naliczane są tylko opłaty za magazyn. Zostanie ona automatycznie wznowione po powrocie działania.
Poza tradycyjnym stosem programu Microsoft SQL Server platforma Azure oferuje również zarządzane wersje trzech popularnych baz danych typu open source.
Bazy danych typu open source na platformie Azure
Relacyjne bazy danych typu open source stały się popularnym wyborem dla aplikacji natywnych dla chmury. Wiele przedsiębiorstw faworyzuje je w odniesieniu do komercyjnych produktów baz danych, zwłaszcza w przypadku oszczędności kosztów. Wiele zespołów programistycznych cieszy się elastycznością, programowaniem wspieranym przez społeczność oraz ekosystemem narzędzi i rozszerzeń. Bazy danych typu open source można wdrażać u wielu dostawców usług w chmurze, co pomaga zminimalizować obawy związane z "blokadą dostawcy".
Deweloperzy mogą łatwo samodzielnie hostować dowolną bazę danych typu open source na maszynie wirtualnej platformy Azure. Zapewniając pełną kontrolę, takie podejście stawia Cię na haku na potrzeby zarządzania, monitorowania i konserwacji bazy danych i maszyny wirtualnej.
Jednak firma Microsoft nadal zobowiązuje się do utrzymania "otwartej platformy" platformy Azure, oferując kilka popularnych baz danych typu open source jako w pełni zarządzane usługi DBaaS.
Baza Danych Azure dla MySQL
MySQL to relacyjna baza danych typu open source i filar aplikacji oparty na stosie oprogramowania LAMP. Powszechnie wybierany do odczytu dużych obciążeń, jest używany przez wiele dużych organizacji, w tym Facebook, Twitter i YouTube. Wersja community jest dostępna bezpłatnie, a wersja Enterprise wymaga zakupu licencji. Pierwotnie utworzony w 1995 roku, produkt został zakupiony przez Sun Microsystems w 2008 roku. Firma Oracle nabyła oprogramowanie Sun i MySQL w 2010 roku.
Azure Database for MySQL to zarządzana usługa relacyjnej bazy danych oparta na a aparatu serwera MySQL typu open source. Korzysta z programu MySQL Community Edition. Serwer Azure MySQL jest punktem administracyjnym dla usługi. Jest to ten sam aparat serwera MySQL używany do wdrożeń lokalnych. Aparat może utworzyć pojedynczą bazę danych na serwer lub wiele baz danych na serwer, który współużytkuje zasoby. Możesz nadal zarządzać danymi przy użyciu tych samych narzędzi typu open source bez konieczności uczenia się nowych umiejętności ani zarządzania maszynami wirtualnymi.
Baza danych Azure dla MariaDB
Serwer MariaDB to inny popularny serwer bazy danych typu open source. Został on utworzony jako rozwidlenie bazy danych MySQL, gdy firma Oracle kupiła sun microsystems, który posiadał program MySQL. Celem było zapewnienie, że mariaDB pozostał open source. Ponieważ mariaDB jest rozwidleniem bazy danych MySQL, definicje danych i tabel są zgodne, a protokoły klienta, struktury i interfejsy API są bliskie dzianiny.
MariaDB ma silną społeczność i jest używana przez wiele dużych przedsiębiorstw. Chociaż firma Oracle nadal utrzymuje, ulepsza i obsługuje program MySQL, fundacja MariaDB zarządza bazą danych MariaDB, umożliwiając publiczne współtworzenie produktu i dokumentacji.
Azure Database for MariaDB to w pełni zarządzana relacyjna baza danych jako usługa w chmurze platformy Azure. Usługa jest oparta na aparacie serwera MariaDB Community Edition. Może obsługiwać obciążenia o krytycznym znaczeniu z przewidywalną wydajnością i dynamiczną skalowalnością.
Baza danych Azure dla PostgreSQL
PostgreSQL to relacyjna baza danych typu open source z ponad 30 lat aktywnego programowania. Usługa PostgreSQL ma silną reputację niezawodności i integralności danych. Jest to funkcja bogata, zgodna ze standardem SQL i bardziej wydajna niż MySQL — szczególnie w przypadku obciążeń ze złożonymi zapytaniami i dużymi zapisami. Wiele dużych przedsiębiorstw, w tym Apple, Red Hat i Fuji, zbudowało produkty korzystające z bazy danych PostgreSQL.
Azure Database for PostgreSQL to w pełni zarządzana usługa relacyjnej bazy danych oparta na aucie bazy danych Postgres typu open source. Usługa obsługuje wiele platform programistycznych, w tym C++, Java, Python, Node, C# i PHP. Bazy danych PostgreSQL można migrować do niej przy użyciu narzędzia interfejsu wiersza polecenia lub usługi Azure Data Migration Service.
Usługa Azure Database for PostgreSQL jest dostępna z dwiema opcjami wdrażania:
Opcja wdrażania pojedynczego serwera to centralny punkt administracyjny dla wielu baz danych, w których można wdrożyć wiele baz danych. Ceny są ustrukturyzowane na serwerze na podstawie rdzeni i magazynu.
Opcja Hiperskala (Citus) jest obsługiwana przez technologię Citus Data. Umożliwia wysoką wydajność przez skalowanie w poziomie pojedynczej bazy danych w setkach węzłów w celu zapewnienia szybkiej wydajności i skalowania. Ta opcja umożliwia aparatowi szybsze dopasowanie większej ilości danych do pamięci, równoległe wykonywanie zapytań w setkach węzłów i szybsze indeksowanie danych.
Dane NoSQL na platformie Azure
Cosmos DB to w pełni zarządzana globalnie rozproszona usługa bazy danych NoSQL w chmurze platformy Azure. Została przyjęta przez wiele dużych firm na całym świecie, w tym Coca-Cola, Skype, ExxonMobil i Liberty Mutual.
Jeśli usługi wymagają szybkiej reakcji z dowolnego miejsca na świecie, wysokiej dostępności lub elastycznej skalowalności, usługa Cosmos DB jest doskonałym wyborem. Rysunek 5–12 przedstawia usługę Cosmos DB.
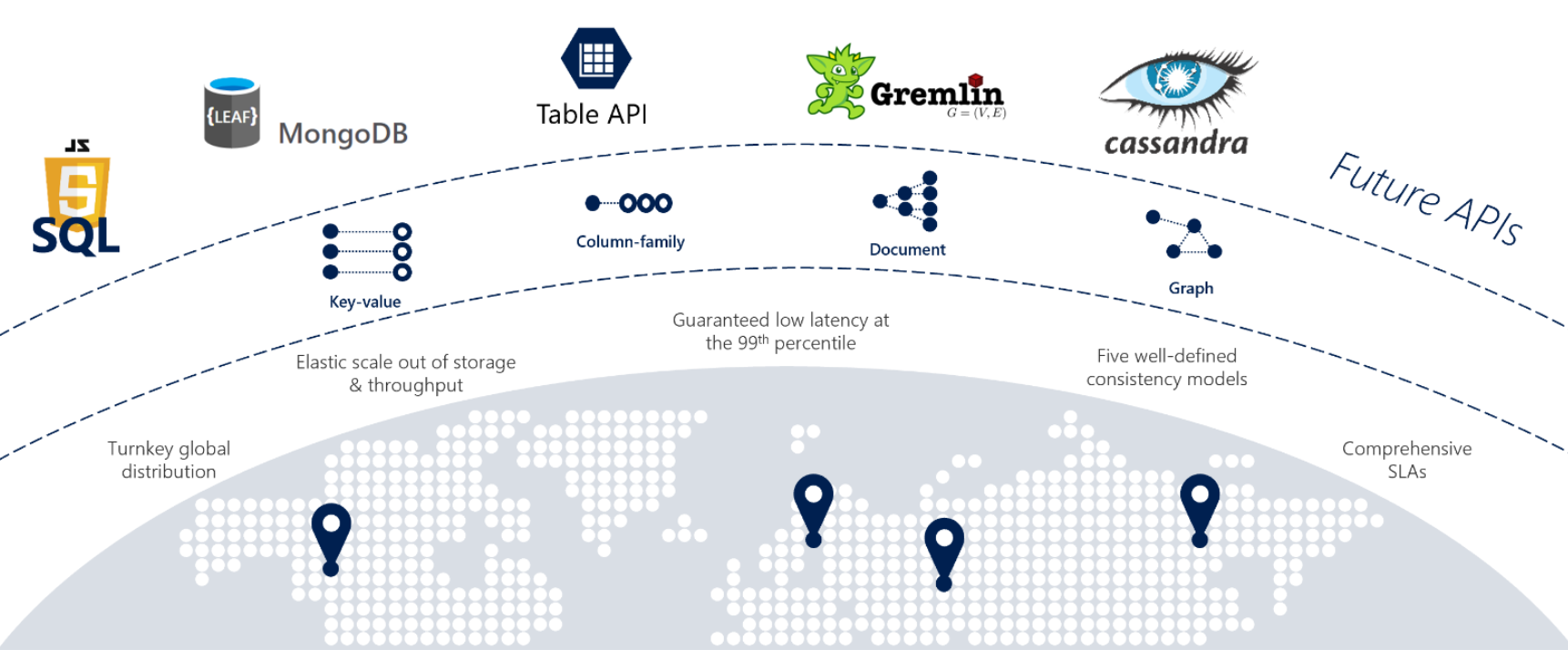
Rysunek 5–12. Omówienie usługi Azure Cosmos DB
Na poprzedniej ilustracji przedstawiono wiele wbudowanych funkcji natywnych dla chmury dostępnych w usłudze Cosmos DB. W tej sekcji przyjrzymy się im bliżej.
Wsparcie globalne
Aplikacje natywne dla chmury często mają odbiorców globalnych i wymagają skali globalnej.
Bazy danych usługi Cosmos można dystrybuować w różnych regionach lub na całym świecie, umieszczając dane blisko użytkowników, skracając czas odpowiedzi i zmniejszając opóźnienie. Bazę danych można dodać lub usunąć z regionu bez wstrzymania lub ponownego wdrażania usług. W tle usługa Cosmos DB w sposób przezroczysty replikuje dane do każdego ze skonfigurowanych regionów.
Usługa Cosmos DB obsługuje aktywne/aktywne klastrowanie na poziomie globalnym, umożliwiając skonfigurowanie dowolnego z regionów bazy danych w celu obsługi zarówno zapisów, jak i odczytów.
Protokół zapisu w wielu regionach jest ważną funkcją w usłudze Cosmos DB, która umożliwia korzystanie z następujących funkcji:
Nieograniczona elastyczna skalowalność zapisu i odczytu.
Dostępność odczytu i zapisu na całym świecie wynosi 99,999%.
Gwarantowane odczyty i zapisy obsługiwane w mniej niż 10 milisekundach w 99. percentylu.
Dzięki interfejsom API multi-homing usługi Cosmos DB mikrousługa jest automatycznie świadoma najbliższego regionu platformy Azure i wysyła do niego żądania. Najbliższy region jest identyfikowany przez usługę Cosmos DB bez żadnych zmian konfiguracji. Jeśli region stanie się niedostępny, funkcja Multi-Homing automatycznie będzie kierować żądania do następnego najbliższego dostępnego regionu.
Obsługa wielu modeli
Podczas ponownego łączenia aplikacji monolitycznych z architekturą natywną dla chmury zespoły programistyczne czasami muszą migrować magazyny danych NoSQL typu open source. Usługa Cosmos DB może pomóc w zachowaniu inwestycji w te magazyny danych NoSQL za pomocą wielomodelowej platformy danych. W poniższej tabeli przedstawiono obsługiwane interfejsy API zgodności noSQL.
| Dostawca | opis |
|---|---|
| Interfejs API NoSQL | Interfejs API dla noSQL przechowuje dane w formacie dokumentu |
| Interfejs API usługi Mongo DB | Obsługuje interfejsy API bazy danych Mongo DB i dokumenty JSON |
| Interfejs API języka Gremlin | Obsługuje interfejs API języka Gremlin z węzłami opartymi na grafach i reprezentacjami danych brzegowych |
| Interfejs API rozwiązania Cassandra | Obsługuje interfejs API Casandra na potrzeby reprezentacji danych w całej kolumnie |
| Interfejs API tabel | Obsługuje usługę Azure Table Storage z ulepszeniami w warstwie Premium |
| PostgreSQL API | Usługa zarządzana do uruchamiania bazy danych PostgreSQL na dowolnej skali |
Zespoły programistyczne mogą migrować istniejące bazy danych Mongo, Gremlin lub Cassandra do usługi Cosmos DB z minimalnymi zmianami w danych lub kodzie. W przypadku nowych aplikacji zespoły programistyczne mogą wybierać opcje open source lub wbudowany model interfejsu API SQL.
Wewnętrznie usługa Cosmos przechowuje dane w prostym formacie struktury składającym się z typów danych pierwotnych. Dla każdego żądania aparat bazy danych tłumaczy dane pierwotne na wybraną reprezentację modelu.
W poprzedniej tabeli zwróć uwagę na opcję Interfejs API tabel. Ten interfejs API to ewolucja usługi Azure Table Storage. Oba współdzielą ten sam podstawowy model tabeli, ale interfejs API tabel usługi Cosmos DB dodaje ulepszenia w warstwie Premium niedostępne w interfejsie API usługi Azure Storage. Poniższa tabela kontrastuje z funkcjami.
| Funkcja | Azure Table Storage (usługa przechowywania danych w tabelach) | Azure Cosmos DB (Usługa bazodanowa firmy Microsoft) |
|---|---|---|
| Opóźnienie | Szybkie przetwarzanie | Jednocyfrowe opóźnienie milisekund dla operacji odczytu i zapisu w dowolnym miejscu na świecie |
| Produktywność | Limit 20 000 operacji na tabelę | Nieograniczone operacje na tabelę |
| Dystrybucja globalna | Pojedynczy region z opcjonalnym pojedynczym pomocniczym regionem odczytu | Gotowe dystrybucje do wszystkich regionów z automatycznym trybem failover |
| Indeksowanie | Dostępne tylko dla właściwości partycji i klucza wiersza | Automatyczne indeksowanie wszystkich właściwości |
| Cennik | Zoptymalizowane pod kątem zimnych obciążeń (niska przepływność: stosunek magazynu) | Zoptymalizowane pod kątem gorących obciążeń (wysoka przepływność: współczynnik magazynowania) |
Mikrousługi, które korzystają z usługi Azure Table Storage, mogą łatwo migrować do interfejsu API tabel usługi Cosmos DB. Nie są wymagane żadne zmiany kodu.
Dostosowywana spójność
Wcześniej w sekcji Relational vs. NoSQL omówiliśmy temat spójności danych. Spójność danych odnosi się do integralności danych. Usługi natywne dla chmury z rozproszonymi danymi polegają na replikacji i muszą mieć fundamentalny kompromis między spójnością odczytu, dostępnością i opóźnieniami.
Większość rozproszonych baz danych umożliwia deweloperom wybór między dwoma modelami spójności: silną spójnością i spójnością ostateczną. Silna spójność to złoty standard programowalności danych. Gwarantuje to, że zapytanie zawsze zwróci najbardziej aktualne dane — nawet jeśli system musi spowodować opóźnienie oczekiwania na replikowanie aktualizacji we wszystkich kopiach bazy danych. Podczas gdy baza danych skonfigurowana pod kątem spójności ostatecznej zwróci dane natychmiast, nawet jeśli te dane nie są najnowszą kopią. Ta ostatnia opcja zapewnia większą dostępność, większą skalę i zwiększoną wydajność.
Usługa Azure Cosmos DB oferuje pięć dobrze zdefiniowanych modeli spójności przedstawionych na rysunku 5–13.

Rysunek 5–13. Poziomy spójności usługi Cosmos DB
Te opcje umożliwiają dokonanie precyzyjnych wyborów i szczegółowych kompromisów w celu zapewnienia spójności, dostępności i wydajności danych. Poziomy przedstawiono w poniższej tabeli.
| Poziom spójności | opis |
|---|---|
| Ostateczne | Brak gwarancji porządkowania odczytów. Repliki zostaną ostatecznie zbieżne. |
| Prefiks stałej | Operacje odczytu są nadal ostateczne, ale dane są zwracane w kolejności zapisywania. |
| Sesja | Gwarancje, że można odczytać dowolne dane zapisane podczas bieżącej sesji. Jest to domyślny poziom spójności. |
| Powiązana Nieaktualność | Odczytuje zapisy dziennika według określonego interwału. |
| Silna | Operacje odczytu mają gwarancję zwrócenia najnowszej zatwierdzonej wersji elementu. Klient nigdy nie widzi niezatwierdzonego lub częściowego odczytu. |
W artykule Getting Behind the 9-Ball: Cosmos DB Consistency Levels Explained, Microsoft Program Manager Jeremy Likness zawiera doskonałe wyjaśnienie pięciu modeli.
Partycjonowanie
Usługa Azure Cosmos DB obejmuje automatyczne partycjonowanie w celu skalowania bazy danych w celu spełnienia wymagań dotyczących wydajności usług natywnych dla chmury.
Dane w usłudze Cosmos DB można zarządzać, tworząc bazy danych, kontenery i elementy.
Kontenery znajdują się w bazie danych usługi Cosmos DB i reprezentują niezależne od schematu grupowanie elementów. Elementy to dane dodawane do kontenera. Są one reprezentowane jako dokumenty, wiersze, węzły lub krawędzie. Wszystkie elementy dodane do kontenera są automatycznie indeksowane.
Aby podzielić kontener na partycje, elementy są podzielone na odrębne podzestawy nazywane partycjami logicznymi. Partycje logiczne są wypełniane na podstawie wartości klucza partycji skojarzonego z każdym elementem w kontenerze. Rysunek 5–14 przedstawia dwa kontenery z partycją logiczną na podstawie wartości klucza partycji.
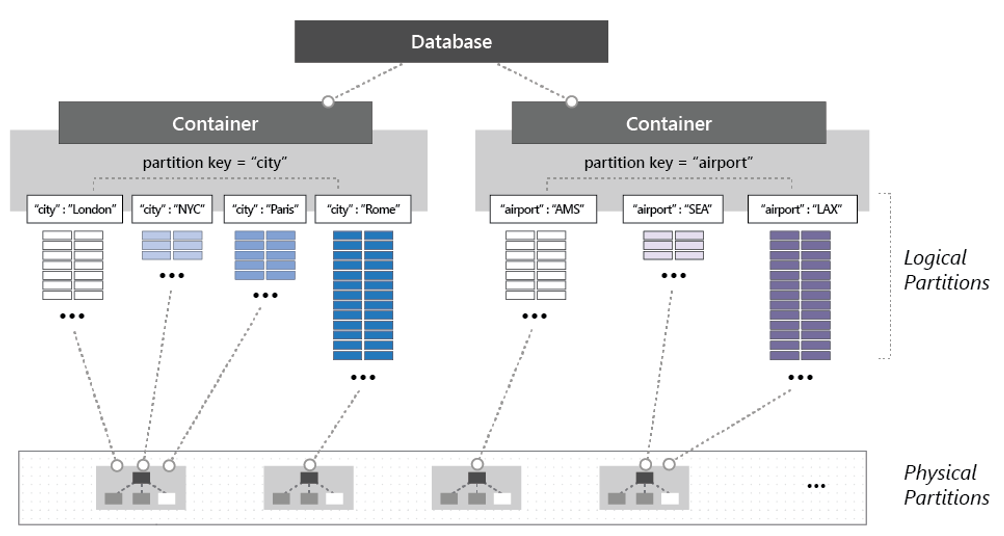
Rysunek 5–14. Mechanika partycjonowania usługi Cosmos DB
Zwróć uwagę na to, jak każdy element zawiera klucz partycji "miasto" lub "lotnisko". Klucz określa partycję logiczną elementu. Elementy z kodem miasta są przypisywane do kontenera po lewej stronie, a elementy z kodem lotniska do kontenera po prawej stronie. Połączenie wartości klucza partycji z wartością ID powoduje utworzenie indeksu elementu, który jednoznacznie identyfikuje element.
Wewnętrznie usługa Cosmos DB automatycznie zarządza umieszczaniem partycji logicznych na partycjach fizycznych w celu zaspokojenia potrzeb związanych ze skalowalnością i wydajnością kontenera. W miarę zwiększania się wymagań dotyczących przepływności aplikacji i magazynu usługa Azure Cosmos DB redystrybuuje partycje logiczne na większej liczbie serwerów. Operacje redystrybucji są zarządzane przez usługę Cosmos DB i wywoływane bez przerw lub przestojów.
Bazy danych SQL
NewSQL to nowa technologia bazy danych, która łączy rozproszoną skalowalność noSQL z gwarancjami ACID relacyjnej bazy danych. Bazy danych NewSQL są ważne dla systemów biznesowych, które muszą przetwarzać duże ilości danych w środowiskach rozproszonych z pełną obsługą transakcyjną i zgodnością ACID. Baza danych NoSQL może zapewnić ogromną skalowalność, ale nie gwarantuje spójności danych. Sporadyczne problemy z niespójnymi danymi mogą stanowić obciążenie dla zespołu deweloperów. Deweloperzy muszą tworzyć zabezpieczenia w kodzie mikrousług, aby zarządzać problemami spowodowanymi niespójnymi danymi.
Program Cloud Native Computing Foundation (CNCF) oferuje kilka projektów bazy danych NewSQL.
| Projekt | Charakterystyki |
|---|---|
| Karacz db | Zgodna ze standardem ACID relacyjna baza danych, która skaluje się globalnie. Dodanie nowego węzła do klastra i bazy danych w celu równoważenia danych między wystąpieniami i lokalizacjami geograficznymi. Tworzy repliki, zarządza nimi i dystrybuuje je w celu zapewnienia niezawodności. Jest ona typu open source i jest bezpłatnie dostępna. |
| TiDB | Baza danych typu open source, która obsługuje obciążenia hybrydowego przetwarzania transakcyjnego i analitycznego (HTAP). Jest on zgodny z bazą danych MySQL i oferuje skalowalność w poziomie, silną spójność i wysoką dostępność. TiDB działa jak serwer MySQL. Możesz nadal używać istniejących bibliotek klienckich MySQL bez konieczności wprowadzania rozbudowanych zmian kodu w aplikacji. |
| YugabyteDB | Rozproszona baza danych SQL typu open source o wysokiej wydajności. Obsługuje małe opóźnienia zapytań, odporność na awarie i globalną dystrybucję danych. Baza danych YugabyteDB jest zgodna z bazą danych PostgreSQL i obsługuje skalowane w poziomie obciążenia RDBMS i OLTP w skali internetowej. Produkt obsługuje również program NoSQL i jest zgodny z rozwiązaniem Cassandra. |
| Vitess | Vitess to rozwiązanie bazy danych do wdrażania, skalowania i zarządzania dużymi klastrami wystąpień programu MySQL. Może działać w architekturze chmury publicznej lub prywatnej. Vitess łączy i rozszerza wiele ważnych funkcji mySQL i funkcji zarówno obsługi fragmentowania pionowego, jak i poziomego. Pochodzi z YouTube, Vitess obsługuje cały ruch bazy danych YouTube od 2011 roku. |
Projekty open-source na poprzedniej ilustracji są dostępne z Cloud Native Computing Foundation. Trzy z ofert są pełnymi produktami baz danych, które obejmują obsługę platformy .NET. Druga, Vitess, jest systemem klastrowania bazy danych, który w poziomie skaluje duże klastry wystąpień MySQL.
Kluczowym celem projektowania dla baz danych NewSQL jest praca natywnie na platformie Kubernetes, wykorzystując odporność i skalowalność platformy.
Bazy danych NewSQL są przeznaczone do rozwoju w efemerycznych środowiskach w chmurze, w których bazowe maszyny wirtualne można uruchomić ponownie lub ponownie zaplanowane w momencie powiadomienia. Bazy danych zostały zaprojektowane tak, aby przetrwać awarie węzłów bez utraty danych ani przestoju. Na przykład w bazie danych OSDB można przetrwać utratę maszyny, utrzymując trzy spójne repliki wszystkich danych w węzłach w klastrze.
Platforma Kubernetes używa konstrukcji usług, aby umożliwić klientowi adresowanie grupy identycznych procesów baz danych NewSQL z pojedynczego wpisu DNS. Oddzielenie wystąpień bazy danych od adresu usługi, z którą jest skojarzona, można skalować bez zakłócania istniejących wystąpień aplikacji. Wysłanie żądania do dowolnej usługi w danym momencie zawsze zwróci ten sam wynik.
W tym scenariuszu wszystkie wystąpienia bazy danych są równe. Nie ma żadnych relacji podstawowych ani pomocniczych. Techniki, takie jak replikacja konsensusu znaleziona w bazie danych w bazie danych, umożliwiają każdemu węzłowi bazy danych obsługę dowolnego żądania. Jeśli węzeł, który odbiera żądanie o zrównoważonym obciążeniu, zawiera dane, których potrzebuje lokalnie, natychmiast odpowiada. Jeśli nie, węzeł staje się bramą i przekazuje żądanie do odpowiednich węzłów, aby uzyskać poprawną odpowiedź. Z perspektywy klienta każdy węzeł bazy danych jest taki sam: są one wyświetlane jako pojedyncza logiczna baza danych z gwarancjami spójności systemu pojedynczego komputera, mimo że w tle działają dziesiątki lub nawet setki węzłów.
Aby uzyskać szczegółowe informacje na temat mechaniki baz danych NewSQL, zobacz artykuł DASH: Four Properties of Kubernetes-Native Databases (Dash: Four Properties of Kubernetes-Native Databases ).
Migracja danych do chmury
Jednym z bardziej czasochłonnych zadań jest migrowanie danych z jednej platformy danych do innej. Usługa Azure Data Migration Service może pomóc przyspieszyć takie wysiłki. Może migrować dane z kilku zewnętrznych źródeł baz danych do platform danych Azure z minimalnym przestojem. Platformy docelowe obejmują następujące usługi:
- Azure SQL Database
- Baza Danych Azure dla MySQL
- Baza danych Azure dla MariaDB
- Baza danych Azure dla PostgreSQL
- Azure Cosmos DB (Usługa bazodanowa firmy Microsoft)
Usługa udostępnia zalecenia umożliwiające przeprowadzenie migracji przez zmiany wymagane do przeprowadzenia migracji zarówno małych, jak i dużych.
Współpracuj z nami w serwisie GitHub
Źródło tej zawartości można znaleźć w witrynie GitHub, gdzie można również tworzyć i przeglądać problemy i żądania ściągnięcia. Więcej informacji znajdziesz w naszym przewodniku dla współtwórców.