Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Wskazówka
Ta treść jest fragmentem eBooka "Architektura mikrousług .NET dla konteneryzowanych aplikacji .NET", dostępnego na .NET Docs lub jako bezpłatny plik PDF do pobrania i czytania w trybie offline.

W aplikacji monolitycznej działającej w jednym procesie składniki wywołują się nawzajem przy użyciu metody lub wywołań funkcji na poziomie języka. Mogą one być silnie powiązane, jeśli tworzysz obiekty z kodem (na przykład new ClassName()), lub można je wywołać w sposób oddzielony, jeśli używasz wstrzykiwania zależności, odwołując się do abstrakcji, a nie do konkretnych wystąpień obiektów. Tak czy inaczej obiekty są uruchamiane w ramach tego samego procesu. Największym wyzwaniem podczas zmiany aplikacji monolitycznej na aplikację opartą na mikrousługach jest zmiana mechanizmu komunikacji. Bezpośrednia konwersja wywołań metod w procesie na wywołania RPC do usług spowoduje hałaśliwą i niewydajną komunikację, która nie będzie dobrze funkcjonować w środowiskach rozproszonych. Wyzwania związane z odpowiednim projektowaniem systemów rozproszonych są wystarczająco dobrze znane, że istnieje nawet lista znana jako Błędy rozproszonego przetwarzania, która wymienia założenia, które deweloperzy często robią podczas przechodzenia od monolitycznego do rozproszonego projektowania.
Nie ma jednego rozwiązania, ale kilku. Jedno rozwiązanie polega na izolowaniu mikrousług biznesowych tak bardzo, jak to możliwe. Następnie należy użyć komunikacji asynchronicznej między wewnętrznymi mikrousługami i zastąpić komunikację o drobnych szczegółach typową dla komunikacji wewnątrzprocesowej między obiektami z komunikacją o większej ziarnistości. Można to zrobić, grupując wywołania i zwracając dane, które agregują wyniki wielu wywołań wewnętrznych, do klienta.
Aplikacja oparta na mikrousługach to rozproszony system działający na wielu procesach lub usługach, zwykle nawet na wielu serwerach lub hostach. Każde wystąpienie usługi jest zazwyczaj procesem. W związku z tym usługi muszą korzystać z protokołu komunikacyjnego między procesami, takiego jak HTTP, AMQP lub protokół binarny, taki jak TCP, w zależności od charakteru każdej usługi.
Społeczność mikrousług promuje filozofię "inteligentnych punktów końcowych i głupich potoków". To hasło zachęca do projektowania, które jest tak oddzielone, jak to możliwe między mikrousługami, i tak spójne, jak to możliwe w ramach jednej mikrousługi. Jak wyjaśniono wcześniej, każda mikrousługa jest właścicielem własnych danych i własnej logiki domeny. Jednak mikrousługi tworzące kompleksową aplikację są zazwyczaj po prostu choreografowane przy użyciu komunikacji REST, zamiast złożonych protokołów, takich jak WS-*, a elastyczna, sterowana zdarzeniami komunikacja jest używana zamiast scentralizowanych orkiestratorów procesów biznesowych.
Dwa najczęściej używane protokoły to żądanie/odpowiedź HTTP z interfejsami API zasobów (w przypadku wykonywania zapytań przede wszystkim) i uproszczone komunikaty asynchroniczne podczas komunikowania aktualizacji w wielu mikrousługach. Bardziej szczegółowo opisano je w poniższych sekcjach.
Typy komunikacji
Klient i usługi mogą komunikować się za pośrednictwem wielu różnych typów komunikacji, z których każdy jest przeznaczony dla innego scenariusza i celów. Początkowo tego typu komunikację można sklasyfikować na dwóch osiach.
Pierwsza oś określa, czy protokół jest synchroniczny lub asynchroniczny:
Protokół synchroniczny. HTTP to protokół synchroniczny. Klient wysyła żądanie i czeka na odpowiedź z usługi. Jest to niezależne od wykonywania kodu klienta, które może być synchroniczne (wątek jest zablokowany) lub asynchroniczne (wątek nie jest blokowany, a odpowiedź ostatecznie dotrze do wywołania zwrotnego). Ważnym punktem jest to, że protokół (HTTP/HTTPS) jest synchroniczny, a kod klienta może kontynuować swoje zadanie tylko wtedy, gdy odbiera odpowiedź serwera HTTP.
Protokół asynchroniczny. Inne protokoły, takie jak AMQP (protokół obsługiwany przez wiele systemów operacyjnych i środowisk w chmurze), używają komunikatów asynchronicznych. Kod klienta lub nadawca wiadomości zwykle nie czeka na odpowiedź. Po prostu wysyła komunikat jako podczas wysyłania komunikatu do kolejki RabbitMQ lub innego brokera komunikatów.
Druga oś określa, czy komunikacja ma jeden odbiornik lub wiele odbiorników:
Pojedynczy odbiornik. Każde żądanie musi być przetwarzane przez dokładnie jednego odbiornika lub usługę. Przykładem tej komunikacji jest wzorzec polecenia.
Wiele odbiorników. Każde żądanie może być obsługiwane przez od zera do wielu odbiorców. Ten typ komunikacji musi być asynchroniczny. Przykładem jest mechanizm publikowania/subskrybowania używany we wzorcach, takich jak architektura sterowana zdarzeniami. Jest to oparte na interfejsie szyny zdarzeń lub brokera wiadomości podczas propagacji aktualizacji danych między wieloma mikrousługami za pośrednictwem zdarzeń; jest on zwykle implementowany za pośrednictwem szyny usług lub podobnego artefaktu, takiego jak Usługa Azure Service Bus, przy użyciu tematów i subskrypcji.
Aplikacja oparta na mikrousługach często używa kombinacji tych stylów komunikacji. Najczęstszym typem jest komunikacja z jednym odbiornikiem za pomocą protokołu synchronicznego, takiego jak HTTP/HTTPS podczas korzystania ze standardowej usługi HTTP interfejsu API sieciowego. Mikrousługi zwykle używają protokołów obsługi komunikatów na potrzeby asynchronicznej komunikacji między mikrousługami.
Te osie są dobre do poznania, więc masz jasność co do możliwych mechanizmów komunikacji, ale nie są to ważne kwestie związane z tworzeniem mikrousług. Ani asynchroniczny charakter wykonywania wątku klienta, ani asynchroniczny charakter wybranego protokołu nie są ważnymi punktami podczas integrowania mikrousług. Ważne jest , aby można było asynchronicznie zintegrować mikrousługi przy zachowaniu niezależności mikrousług, jak wyjaśniono w poniższej sekcji.
Integracja mikrousługi asynchronicznej wymusza autonomię mikrousługi
Jak wspomniano, ważnym punktem tworzenia aplikacji opartej na mikrousługach jest sposób integrowania mikrousług. W idealnym przypadku należy spróbować zminimalizować komunikację między wewnętrznymi mikrousługami. Tym mniejsza jest komunikacja między mikrousługami, tym lepiej. Jednak w wielu przypadkach trzeba będzie w jakiś sposób zintegrować mikrousługi. Kiedy jest to konieczne, kluczową zasadą jest, aby komunikacja między mikrousługami była asynchroniczna. Nie oznacza to, że musisz użyć określonego protokołu (na przykład asynchronicznego przesyłania komunikatów w porównaniu z synchronicznym protokołem HTTP). Oznacza to tylko, że komunikacja między mikrousługami powinna być wykonywana tylko przez propagowanie danych w sposób asynchroniczny, ale nie należy zależeć od innych wewnętrznych mikrousług w ramach początkowego żądania i odpowiedzi HTTP usługi.
Jeśli to możliwe, nigdy nie zależy od synchronicznej komunikacji (żądania/odpowiedzi) między wieloma mikrousługami, nawet w przypadku zapytań. Celem każdej mikrousługi jest być autonomiczną i dostępną dla klienta, nawet jeśli inne usługi będące częścią aplikacji typu end-to-end nie działają lub są w złej kondycji. Jeśli uważasz, że musisz wykonać wywołanie z jednej mikrousługi do innych mikrousług (takich jak wykonywanie żądania HTTP dla zapytania o dane), aby móc dostarczyć odpowiedź na aplikację kliencką, masz architekturę, która nie będzie odporna, gdy niektóre mikrousługi kończą się niepowodzeniem.
Ponadto, posiadanie zależności HTTP między mikrousługami, na przykład podczas tworzenia długich cykli żądań/odpowiedzi za pomocą łańcuchów żądań HTTP, jak pokazano w pierwszej części rysunku 4–15, nie tylko uniemożliwia autonomiczne działanie mikrousług, ale także negatywnie wpływa na ich wydajność, gdy jedna z usług w tym łańcuchu nie działa prawidłowo.
Im więcej dodajesz synchroniczne zależności między mikrousługami, takimi jak żądania zapytań, tym gorzej jest ogólny czas odpowiedzi dla aplikacji klienckich.
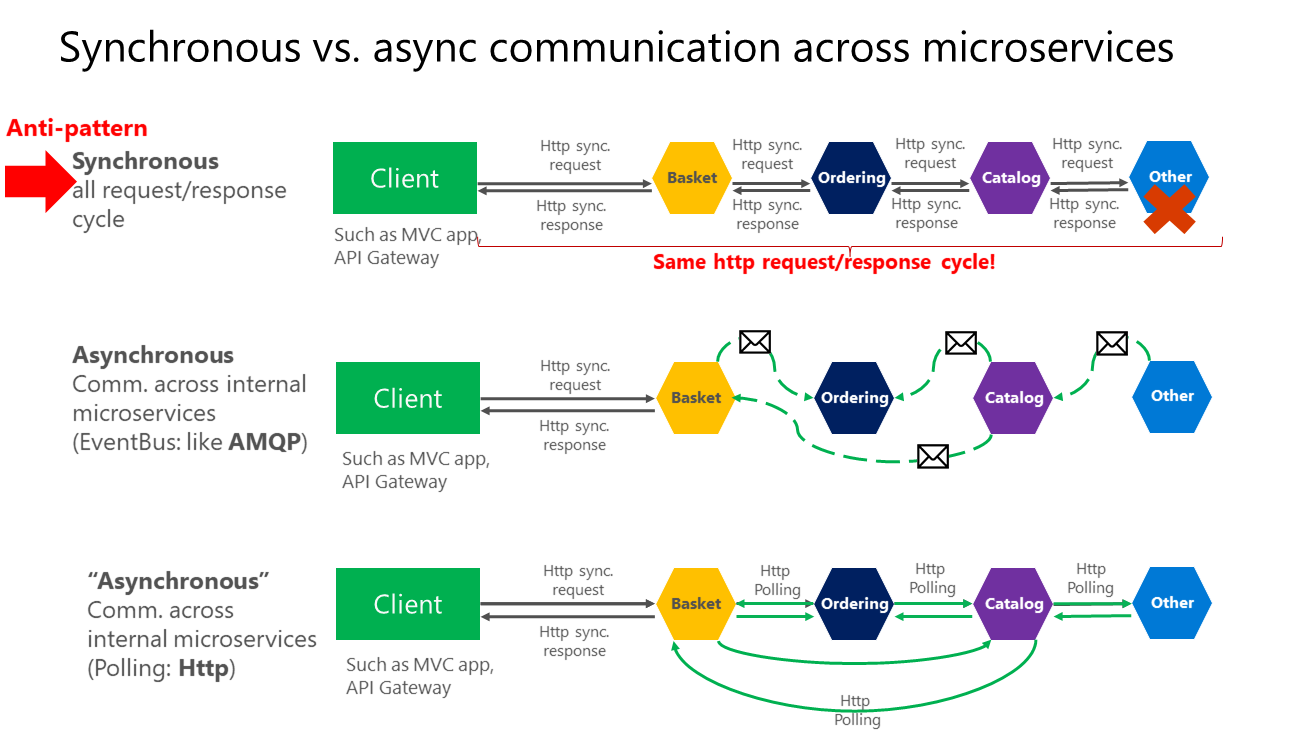
Rysunek 4–15. Antywzorce i wzorce w komunikacji między mikrousługami
Jak pokazano na powyższym diagramie, w synchronicznej komunikacji "łańcuch" żądań jest tworzony między mikrousługami podczas obsługi żądania klienta. Jest to antywzór. W przypadku asynchronicznej komunikacji mikrousługi używają komunikatów asynchronicznych lub sondowania http do komunikowania się z innymi mikrousługami, ale żądanie klienta jest obsługiwane od razu.
Jeśli mikrousługa musi wywołać dodatkową akcję w innej mikrousłudze, jeśli to możliwe, nie wykonuj tej akcji synchronicznie i jako część operacji żądania i odpowiedzi oryginalnej mikrousługi. Zamiast tego należy to zrobić asynchronicznie (przy użyciu asynchronicznych komunikatów lub zdarzeń integracji, kolejek itp.). Jednak jak najbardziej się da, nie należy wywoływać akcji w trybie synchronicznym jako części oryginalnego synchronicznego żądania i operacji odpowiedzi.
I wreszcie (i w tym miejscu pojawia się większość problemów podczas tworzenia mikrousług), jeśli początkowa mikrousługa potrzebuje danych, które są pierwotnie własnością innych mikrousług, nie polegaj na realizowaniu synchronicznych żądań dotyczących tych danych. Zamiast tego należy replikować lub propagować te dane (tylko potrzebne atrybuty) do bazy danych początkowej usługi przy użyciu spójności ostatecznej (zazwyczaj przy użyciu zdarzeń integracji, jak wyjaśniono w kolejnych sekcjach).
Jak wspomniano wcześniej w sekcji Identyfikowanie granic modelu domeny dla każdej mikrousługi , duplikowanie niektórych danych między kilkoma mikrousługami nie jest niepoprawnym projektem — wręcz przeciwnie, podczas wykonywania tego działania można przetłumaczyć dane na określony język lub terminy tej dodatkowej domeny lub ograniczonego kontekstu. Na przykład w aplikacji eShopOnContainers masz mikrousługę o nazwie identity-api , która jest odpowiedzialna za większość danych użytkownika z jednostką o nazwie User. Jeśli jednak musisz przechowywać dane o użytkowniku Ordering w ramach mikrousługi, zapisz je jako inną jednostkę o nazwie Buyer. Jednostka Buyer posiada tę samą tożsamość co oryginalna jednostka User, ale może mieć tylko kilka atrybutów wymaganych przez domenę Ordering, a nie pełny profil użytkownika.
Aby zapewnić spójność ostateczną, możesz użyć dowolnego protokołu do komunikowania i propagowania danych asynchronicznie między mikrousługami. Jak wspomniano, możesz użyć zdarzeń integracji przy użyciu magistrali zdarzeń lub brokera komunikatów, a nawet użyć protokołu HTTP, sondując inne usługi. To nie ma znaczenia. Ważną regułą jest nie tworzenie synchronicznych zależności między mikrousługami.
W poniższych sekcjach opisano wiele stylów komunikacji, które można rozważyć przy użyciu w aplikacji opartej na mikrousługach.
Style komunikacji
Istnieje wiele protokołów i opcji, których można użyć do komunikacji, w zależności od typu komunikacji, którego chcesz użyć. Jeśli używasz synchronicznego mechanizmu komunikacji żądań/odpowiedzi, protokoły, takie jak metody HTTP i REST, są najbardziej typowe, zwłaszcza w przypadku publikowania usług spoza hosta platformy Docker lub klastra mikrousług. Jeśli komunikujesz się wewnętrznie między usługami (w ramach hosta platformy Docker lub klastra mikrousług), możesz również użyć mechanizmów komunikacji formatu binarnego (takich jak WCF przy użyciu formatu TCP i formatu binarnego). Alternatywnie można użyć asynchronicznych mechanizmów komunikacji opartych na komunikatach, takich jak AMQP.
Istnieje również wiele formatów komunikatów, takich jak JSON lub XML, a nawet formaty binarne, które mogą być bardziej wydajne. Jeśli wybrany format binarny nie jest standardowy, prawdopodobnie nie jest dobrym pomysłem, aby publicznie opublikować usługi przy użyciu tego formatu. Możesz użyć niestandardowego formatu komunikacji wewnętrznej między mikrousługami. Można to zrobić podczas komunikacji między mikrousługami w ramach hosta platformy Docker lub klastra mikrousług (na przykład orkiestratorów platformy Docker) lub w przypadku zastrzeżonych aplikacji klienckich, które komunikują się z mikrousługami.
Komunikacja żądań/odpowiedzi za pomocą protokołu HTTP i REST
Gdy klient używa komunikacji żądania/odpowiedzi, wysyła żądanie do usługi, a następnie usługa przetwarza żądanie i wysyła odpowiedź. Komunikacja żądań/odpowiedzi jest szczególnie odpowiednia do wykonywania zapytań o dane dla interfejsu użytkownika w czasie rzeczywistym (interfejs użytkownika na żywo) z aplikacji klienckich. W związku z tym w architekturze mikrousług prawdopodobnie użyjesz tego mechanizmu komunikacyjnego dla większości zapytań, jak pokazano na rysunku 4–16.

Rysunek 4–16. Korzystanie z komunikacji żądania HTTP/odpowiedzi (synchronicznej lub asynchronicznej)
Gdy klient korzysta z komunikacji żądań/odpowiedzi, zakłada, że odpowiedź pojawi się w krótkim czasie, zazwyczaj mniej niż sekunda lub kilka sekund. W przypadku opóźnionych odpowiedzi należy zaimplementować asynchroniczną komunikację opartą na wzorcach obsługi komunikatów i technologiach obsługi komunikatów, co jest innym podejściem, które objaśniamy w następnej sekcji.
Popularnym stylem architektury komunikacji żądań/odpowiedzi jest REST. Takie podejście jest oparte na protokole HTTP, ściśle powiązanym z protokołem HTTP, obejmującym czasowniki HTTP , takie jak GET, POST i PUT. Rest to najczęściej używane podejście do komunikacji architektonicznej podczas tworzenia usług. Można zaimplementować usługi REST podczas tworzenia usług Web API w ASP.NET Core.
W przypadku używania usług REST HTTP jako języka definicji interfejsu jest dodatkowa wartość. Jeśli na przykład używasz metadanych Swagger do opisywania interfejsu API usługi, możesz użyć narzędzi, które generują klienty szkieletowe, mogące bezpośrednio wykrywać i korzystać z usług.
Dodatkowe zasoby
Martin Fowler. Model dojrzałości Richardson Opis modelu REST.
https://martinfowler.com/articles/richardsonMaturityModel.htmlSwagger Oficjalna strona.
https://swagger.io/
Push i komunikacja w czasie rzeczywistym na podstawie protokołu HTTP
Inną możliwością (zwykle w różnych celach niż REST) jest komunikacja w czasie rzeczywistym z platformami wyższego poziomu, takimi jak ASP.NET SignalR i protokoły, takie jak WebSocket.
Jak pokazano na rysunku 4–17, komunikacja HTTP w czasie rzeczywistym oznacza, że kod serwera przesyła treści do połączonych klientów, gdy dane są dostępne, zamiast czekać na żądanie nowych danych przez klienta.

Rysunek 4–17. Komunikacja asynchroniczna "jeden do wielu" w czasie rzeczywistym
SignalR to dobry sposób na realizację komunikacji w czasie rzeczywistym, umożliwiającego przesyłanie treści do klientów z serwera backendowego. Ponieważ komunikacja jest w czasie rzeczywistym, aplikacje klienckie pokazują zmiany niemal natychmiast. Jest to zwykle obsługiwane przez protokół, taki jak WebSockets, przy użyciu wielu połączeń protokołu WebSocket (po jednym na klienta). Typowym przykładem jest sytuacja, kiedy usługa przekazuje zmianę wyniku gry sportowej do wielu aplikacji internetowych klientów jednocześnie.
Współpracuj z nami na GitHub
Źródło tej zawartości można znaleźć w witrynie GitHub, gdzie można również tworzyć i przeglądać problemy oraz żądania ściągnięcia. Aby uzyskać więcej informacji, zapoznaj się z naszym przewodnikiem dla twórców.