Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Napiwek
Ta zawartość jest fragmentem książki eBook, architektury mikrousług platformy .NET dla konteneryzowanych aplikacji platformy .NET dostępnych na platformie .NET Docs lub jako bezpłatnego pliku PDF, który można odczytać w trybie offline.

W większości przypadków kontener można traktować jako wystąpienie procesu. Proces nie utrzymuje stanu trwałego. Chociaż kontener może zapisywać w magazynie lokalnym, zakładając, że wystąpienie będzie w nieskończoność, będzie wyglądać tak, jakby zakładało, że pojedyncza lokalizacja w pamięci będzie trwała. Należy założyć, że obrazy kontenerów, takie jak procesy, mają wiele wystąpień lub zostaną ostatecznie zabite. Jeśli są zarządzane za pomocą orkiestratora kontenerów, należy założyć, że mogą one zostać przeniesione z jednego węzła lub maszyny wirtualnej do innej.
Do zarządzania danymi w aplikacjach platformy Docker służą następujące rozwiązania:
Z hosta platformy Docker jako woluminy platformy Docker:
Woluminy są przechowywane w obszarze systemu plików hosta zarządzanego przez platformę Docker.
Instalacje powiązane mogą być mapowane na dowolny folder w systemie plików hosta, więc dostęp nie może być kontrolowany z procesu platformy Docker i może stanowić zagrożenie bezpieczeństwa, ponieważ kontener może uzyskać dostęp do poufnych folderów systemu operacyjnego.
Instalacji tmpfs są jak foldery wirtualne, które istnieją tylko w pamięci hosta i nigdy nie są zapisywane w systemie plików.
Z magazynu zdalnego:
Usługa Azure Storage, która zapewnia magazyn geograficznie dystrybucyjny, zapewniając dobre długoterminowe rozwiązanie trwałości dla kontenerów.
Zdalne relacyjne bazy danych, takie jak bazy danych Azure SQL Database lub NoSQL, takie jak Azure Cosmos DB, lub usługi pamięci podręcznej, takie jak Redis.
Z kontenera platformy Docker:
- Nakładanie systemu plików. Ta funkcja platformy Docker implementuje zadanie kopiowania na zapis, które przechowuje zaktualizowane informacje w głównym systemie plików kontenera. Te informacje są "na górze" oryginalnego obrazu, na którym opiera się kontener. Jeśli kontener zostanie usunięty z systemu, te zmiany zostaną utracone. W związku z tym chociaż istnieje możliwość zapisania stanu kontenera w magazynie lokalnym, zaprojektowanie systemu wokół niego spowoduje konflikt z założeniem projektu kontenera, który domyślnie jest bezstanowy.
Jednak użycie woluminów platformy Docker jest teraz preferowanym sposobem obsługi danych lokalnych na platformie Docker. Jeśli potrzebujesz więcej informacji na temat magazynu w kontenerach, sprawdź sterowniki magazynu platformy Docker i Informacje o sterownikach magazynu.
Poniżej przedstawiono bardziej szczegółowe informacje na temat tych opcji:
Woluminy to katalogi mapowane z systemu operacyjnego hosta na katalogi w kontenerach. Gdy kod w kontenerze ma dostęp do katalogu, dostęp ten jest rzeczywiście do katalogu w systemie operacyjnym hosta. Ten katalog nie jest powiązany z okresem istnienia samego kontenera, a katalog jest zarządzany przez platformę Docker i odizolowany od podstawowych funkcji maszyny hosta. W związku z tym woluminy danych są przeznaczone do utrwalania danych niezależnie od okresu eksploatacji kontenera. Jeśli usuniesz kontener lub obraz z hosta platformy Docker, dane utrwalone w woluminie danych nie zostaną usunięte.
Woluminy mogą być nazwane lub anonimowe (wartość domyślna). Nazwane woluminy są ewolucją kontenerów woluminów danych i ułatwiają udostępnianie danych między kontenerami. Woluminy obsługują również sterowniki woluminów, które umożliwiają przechowywanie danych na hostach zdalnych, między innymi.
Instalacje powiązane są dostępne od dawna i umożliwiają mapowanie dowolnego folderu na punkt instalacji w kontenerze. Instalacje powiązane mają więcej ograniczeń niż woluminy i niektóre ważne problemy z zabezpieczeniami, dlatego woluminy są zalecaną opcją.
Instalacja tmpfs to zasadniczo foldery wirtualne, które żyją tylko w pamięci hosta i nigdy nie są zapisywane w systemie plików. Są one szybkie i bezpieczne, ale używają pamięci i są przeznaczone tylko dla danych tymczasowych, nietrwalnych.
Jak pokazano na rysunku 4–5, zwykłe woluminy platformy Docker mogą być przechowywane poza samymi kontenerami, ale w granicach fizycznych serwera hosta lub maszyny wirtualnej. Jednak kontenery platformy Docker nie mogą uzyskać dostępu do woluminu z jednego serwera hosta lub maszyny wirtualnej do innej. Innymi słowy, w przypadku tych woluminów nie można zarządzać danymi współużytkowymi między kontenerami uruchomionymi na różnych hostach platformy Docker, chociaż można to osiągnąć za pomocą sterownika woluminu obsługującego hosty zdalne.
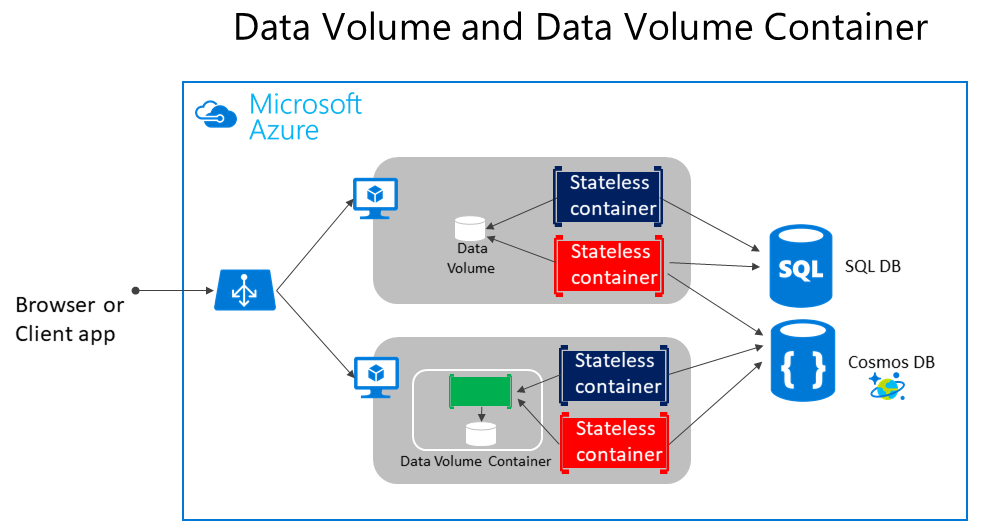
Rysunek 4–5. Woluminy i zewnętrzne źródła danych dla aplikacji opartych na kontenerach
Woluminy mogą być współużytkowane między kontenerami, ale tylko na tym samym hoście, chyba że używasz sterownika zdalnego obsługującego hosty zdalne. Ponadto, gdy kontenery platformy Docker są zarządzane przez koordynatora, kontenery mogą "przenosić się" między hostami w zależności od optymalizacji wykonywanych przez klaster. W związku z tym nie zaleca się używania woluminów danych dla danych biznesowych. Są one jednak dobrym mechanizmem pracy z plikami śledzenia, plikami czasowymi lub podobnymi, które nie będą miały wpływu na spójność danych biznesowych.
Zdalne źródła danych i narzędzia pamięci podręcznej, takie jak Azure SQL Database, Azure Cosmos DB lub zdalna pamięć podręczna , taka jak Redis, mogą być używane w konteneryzowanych aplikacjach w taki sam sposób, jak podczas tworzenia bez kontenerów. Jest to sprawdzony sposób przechowywania danych aplikacji biznesowych.
Azure Storage. Dane biznesowe zwykle muszą być umieszczane w zewnętrznych zasobach lub bazach danych, takich jak Usługa Azure Storage. Usługa Azure Storage, w konkretnym przypadku, udostępnia następujące usługi w chmurze:
Magazyn obiektów blob przechowuje dane obiektów bez struktury. Obiekt blob może być dowolnym typem danych tekstowych lub binarnych, takich jak pliki dokumentów lub multimediów (obrazy, audio i pliki wideo). Magazyn obiektów Blob jest także nazywany magazynem obiektów.
Magazyn plików oferuje magazyn udostępniony dla starszych aplikacji korzystających ze standardowego protokołu SMB. Maszyny wirtualne platformy Azure i usługi w chmurze mogą udostępniać dane plików między składnikami aplikacji za pośrednictwem zainstalowanych udziałów. Aplikacje lokalne mogą uzyskiwać dostęp do danych plików w udziale za pośrednictwem interfejsu API REST usługi plików.
Table Storage — przechowuje zestawy danych ze strukturą. Usługa Table Storage to magazyn danych typu key-attribute NoSQL, który umożliwia szybki rozwój i szybki dostęp do dużych ilości danych.
Relacyjne bazy danych i bazy danych NoSQL. Istnieje wiele opcji dla zewnętrznych baz danych, z relacyjnych baz danych, takich jak SQL Server, PostgreSQL, Oracle lub NoSQL, takich jak Azure Cosmos DB, MongoDB itp. Te bazy danych nie zostaną wyjaśnione w ramach tego przewodnika, ponieważ znajdują się one w zupełnie innym temacie.
Współpracuj z nami na GitHub
Źródło tej treści można znaleźć na GitHubie, gdzie można także tworzyć i przeglądać problemy oraz pull requesty. Więcej informacji znajdziesz w naszym przewodniku dla współautorów.