Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Wskazówka
Ta treść jest fragmentem eBooka "Architektura mikrousług .NET dla konteneryzowanych aplikacji .NET", dostępnego na .NET Docs lub jako bezpłatny plik PDF do pobrania i czytania w trybie offline.

Pierwszym krokiem korzystania z magistrali zdarzeń jest zapisanie mikrousług na wydarzenia, które chcą otrzymywać. Ta funkcja powinna być wykonywana w mikrousługach odbiorcy.
Poniższy prosty kod pokazuje, co każda mikrousługa odbiorcy musi zaimplementować podczas uruchamiania usługi (czyli w Startup klasie), aby subskrybować zdarzenia, których potrzebuje. W takim przypadku mikrousługa basket-api musi zasubskrybować komunikaty ProductPriceChangedIntegrationEvent i OrderStartedIntegrationEvent.
Na przykład podczas subskrybowania zdarzenia ProductPriceChangedIntegrationEvent, mikrousługa koszyka zostaje poinformowana o wszelkich zmianach w cenie produktu i ostrzega użytkownika o zmianie, jeśli produkt znajduje się w koszyku użytkownika.
var eventBus = app.ApplicationServices.GetRequiredService<IEventBus>();
eventBus.Subscribe<ProductPriceChangedIntegrationEvent,
ProductPriceChangedIntegrationEventHandler>();
eventBus.Subscribe<OrderStartedIntegrationEvent,
OrderStartedIntegrationEventHandler>();
Po uruchomieniu tego kodu mikrousługa subskrybująca będzie nasłuchiwać za pośrednictwem kanałów RabbitMQ. Po nadejściu dowolnego komunikatu typu ProductPriceChangedIntegrationEvent kod wywołuje program obsługi zdarzeń przekazywany do niego i przetwarza zdarzenie.
Publikowanie zdarzeń za pomocą busa zdarzeń
Na koniec nadawca komunikatu (mikrousługa pochodzenia) publikuje zdarzenia integracji z kodem podobnym do poniższego przykładu. (Takie podejście jest uproszczonym przykładem, który nie uwzględnia atomiczności). Można zaimplementować podobny kod za każdym razem, gdy zdarzenie musi być propagowane w wielu mikrousługach, zwykle zaraz po zatwierdzeniu danych lub transakcji z mikrousługi źródłowej.
Najpierw obiekt implementacji magistrali zdarzeń (oparty na RabbitMQ lub oparty na magistrali usług) zostanie wstrzyknięty do konstruktora kontrolera, jak w poniższym kodzie:
[Route("api/v1/[controller]")]
public class CatalogController : ControllerBase
{
private readonly CatalogContext _context;
private readonly IOptionsSnapshot<Settings> _settings;
private readonly IEventBus _eventBus;
public CatalogController(CatalogContext context,
IOptionsSnapshot<Settings> settings,
IEventBus eventBus)
{
_context = context;
_settings = settings;
_eventBus = eventBus;
}
// ...
}
Następnie użyjesz go z metod kontrolera, takich jak w metodzie UpdateProduct:
[Route("items")]
[HttpPost]
public async Task<IActionResult> UpdateProduct([FromBody]CatalogItem product)
{
var item = await _context.CatalogItems.SingleOrDefaultAsync(
i => i.Id == product.Id);
// ...
if (item.Price != product.Price)
{
var oldPrice = item.Price;
item.Price = product.Price;
_context.CatalogItems.Update(item);
var @event = new ProductPriceChangedIntegrationEvent(item.Id,
item.Price,
oldPrice);
// Commit changes in original transaction
await _context.SaveChangesAsync();
// Publish integration event to the event bus
// (RabbitMQ or a service bus underneath)
_eventBus.Publish(@event);
// ...
}
// ...
}
W takim przypadku, ponieważ mikrousługa pochodzenia jest prostą mikrousługą CRUD, kod jest umieszczany bezpośrednio w kontrolerze internetowego interfejsu API.
W bardziej zaawansowanych mikrousługach, takich jak korzystanie z podejść CQRS, można ją zaimplementować w klasie CommandHandler, w ramach metody Handle().
Projektowanie atomowości i odporności podczas publikowania w magistrali zdarzeń
Podczas publikowania zdarzeń integracji za pośrednictwem rozproszonego systemu przesyłania wiadomości, takiego jak magistrala zdarzeń, występuje problem atomowego aktualizowania oryginalnej bazy danych i publikowania zdarzenia (czyli albo obie operacje są zakończone, albo żadna z nich). Na przykład w uproszczonym przykładzie przedstawionym wcześniej kod zatwierdza dane do bazy danych po zmianie ceny produktu, a następnie publikuje komunikat ProductPriceChangedIntegrationEvent. Początkowo wydaje się konieczne, aby te dwie operacje były wykonywane atomowo. Jeśli jednak używasz transakcji rozproszonej z udziałem bazy danych i brokera komunikatów, tak jak w starszych systemach, takich jak Microsoft Message Queuing (MSMQ), to podejście nie jest zalecane z powodów opisanych przez twierdzenie CAP.
Zasadniczo mikrousługi służą do tworzenia skalowalnych i wysoce dostępnych systemów. Upraszczając nieco, twierdzenie CAP mówi, że nie można utworzyć (rozproszonej) bazy danych (lub mikrousługi, która jest właścicielem modelu), która jest stale dostępna, silnie spójna i odporna na dowolną partycję. Należy wybrać dwie z tych trzech właściwości.
W architekturach opartych na mikrousługach należy wybrać dostępność i tolerancję, a silną spójność traktować jako mniej priorytetową. W związku z tym w większości nowoczesnych aplikacji opartych na mikrousługach zwykle nie chcesz używać transakcji rozproszonych w komunikatach, tak jak podczas implementowania transakcji rozproszonych opartych na koordynatorze transakcji rozproszonych systemu Windows (DTC) za pomocą msMQ.
Wróćmy do początkowego problemu i jego przykładu. Jeśli usługa ulegnie awarii po zaktualizowaniu bazy danych (w tym przypadku bezpośrednio po wierszu kodu z _context.SaveChangesAsync()), ale przed opublikowaniem zdarzenia integracji, ogólny system może stać się niespójny. Takie podejście może mieć krytyczne znaczenie dla działania firmy, w zależności od określonej operacji biznesowej, z którą masz do czynienia.
Jak wspomniano wcześniej w sekcji architektury, możesz mieć kilka podejść do radzenia sobie z tym problemem:
Stosowanie pełnego wzorca Event Sourcing.
Korzystanie z wyszukiwania dzienników transakcji.
Korzystanie z wzorca skrzynki nadawczej. Jest to tabela transakcyjna do przechowywania zdarzeń integracji (rozszerzanie transakcji lokalnych).
W tym scenariuszu użycie pełnego wzorca Event Sourcing (ES) jest jednym z najlepszych rozwiązań, jeśli nie najlepszym. Jednak w wielu scenariuszach aplikacji może nie być możliwe zaimplementowanie pełnego systemu ES. ES oznacza przechowywanie tylko zdarzeń domeny w transakcyjnej bazie danych zamiast przechowywania bieżących danych stanu. Przechowywanie tylko zdarzeń domeny może mieć duże korzyści, takie jak posiadanie dostępnej historii systemu i możliwość określenia stanu systemu w dowolnym momencie w przeszłości. Jednak zaimplementowanie pełnego systemu ES wymaga ponownej architektury większości systemu i wprowadzenia wielu innych złożoności i wymagań. Na przykład chcesz użyć bazy danych specjalnie utworzonej do określania źródła zdarzeń, takiego jak Magazyn zdarzeń lub bazy danych zorientowanej na dokumenty, takiej jak Azure Cosmos DB, MongoDB, Cassandra, CouchDB lub RavenDB. ES jest doskonałym rozwiązaniem tego problemu, ale nie najprostszym rozwiązaniem, chyba że znasz już określanie źródła zdarzeń.
Opcja korzystania z funkcji eksploracji dzienników transakcji początkowo wygląda przezroczysta. Jednak aby użyć tego podejścia, mikrousługę należy połączyć z dziennikem transakcji RDBMS, takim jak dziennik transakcji programu SQL Server. Takie podejście prawdopodobnie nie jest pożądane. Kolejną wadą jest to, że aktualizacje niskiego poziomu zarejestrowane w dzienniku transakcji mogą nie być na tym samym poziomie co zdarzenia integracji wysokiego poziomu. Jeśli tak, proces odwrotnej inżynierii tych operacji dziennika transakcji może być trudny.
Zrównoważone podejście to kombinacja transakcyjnej tabeli bazy danych i uproszczonego wzorca ES. Możesz użyć stanu takiego jak "gotowy do opublikowania zdarzenia", który został ustawiony w oryginalnym zdarzeniu podczas zatwierdzania go w tabeli zdarzeń integracji. Następnie spróbujesz opublikować zdarzenie w magistrali zdarzeń. Jeśli akcja publikowania zdarzenia powiedzie się, uruchom kolejną transakcję w usłudze pochodzenia i przenieś stan z "gotowego do opublikowania zdarzenia" na "zdarzenie zostało już opublikowane".
Jeśli akcja publikowania zdarzenia w magistrali zdarzeń nie powiedzie się, dane nadal nie będą niespójne w mikrousłudze pochodzenia — nadal są one oznaczone jako "gotowe do opublikowania zdarzenia" i w odniesieniu do pozostałych usług, ostatecznie będą spójne. Zawsze możesz mieć zadania w tle sprawdzające stan transakcji lub zdarzeń integracji. Jeśli zadanie znajdzie zdarzenie w stanie "gotowym do publikacji", może próbować opublikować na nowo to zdarzenie w magistrali zdarzeń.
Zwróć uwagę, że w przypadku tego podejścia utrwalasz tylko zdarzenia integracyjne dla każdej mikrousługi pochodzenia i tylko te zdarzenia, które chcesz przekazywać innym mikrousługom lub systemom zewnętrznym. Z kolei w pełnym systemie ES przechowujesz również wszystkie zdarzenia domeny.
W związku z tym takie zrównoważone podejście jest uproszczonym systemem ES. Potrzebna jest lista zdarzeń związanych z integracją wraz z ich aktualnym stanem ("gotowe do opublikowania" versus "opublikowane"). Konieczne jest jednak zaimplementowanie tylko tych stanów dla zdarzeń integracyjnych. W tym podejściu nie trzeba przechowywać wszystkich danych domeny jako zdarzeń w transakcyjnej bazie danych, tak jak w pełnym systemie ES.
Jeśli używasz już relacyjnej bazy danych, możesz użyć tabeli transakcyjnej do przechowywania zdarzeń integracji. Aby osiągnąć atomowość w aplikacji, używasz dwuetapowego procesu opartego na transakcjach lokalnych. Zasadniczo masz tabelę IntegrationEvent w tej samej bazie danych, w której masz jednostki domeny. Ta tabela działa jako mechanizm zabezpieczający zapewniający atomowość, umożliwiając dołączenie utrwalonych zdarzeń integracyjnych wewnątrz tych samych transakcji co zatwierdzanie danych domeny.
Krok po kroku proces wygląda następująco:
Aplikacja rozpoczyna transakcję lokalnej bazy danych.
Następnie aktualizuje stan jednostek domeny i wstawia zdarzenie do tabeli zdarzeń integracji.
Na koniec zatwierdza transakcję, więc uzyskasz żądaną atomowość, a następnie
W jakiś sposób publikujesz zdarzenie (dalej).
Podczas implementowania kroków publikowania zdarzeń dostępne są następujące opcje:
Opublikuj zdarzenie integracji bezpośrednio po zatwierdzeniu transakcji i użyj innej transakcji lokalnej, aby oznaczyć zdarzenia w tabeli jako opublikowane. Następnie użyj tabeli jako artefaktu, aby śledzić zdarzenia integracji w przypadku problemów w zdalnych mikrousług i wykonywać akcje wyrównywujące na podstawie przechowywanych zdarzeń integracji.
Użyj tabeli jako rodzaju kolejki. Oddzielny wątek aplikacji lub proces wysyła zapytanie do tabeli zdarzeń integracji, publikuje zdarzenia w magistrali zdarzeń, a następnie używa transakcji lokalnej do oznaczania zdarzeń jako opublikowanych.
Rysunek 6–22 przedstawia architekturę dla pierwszego z tych podejść.
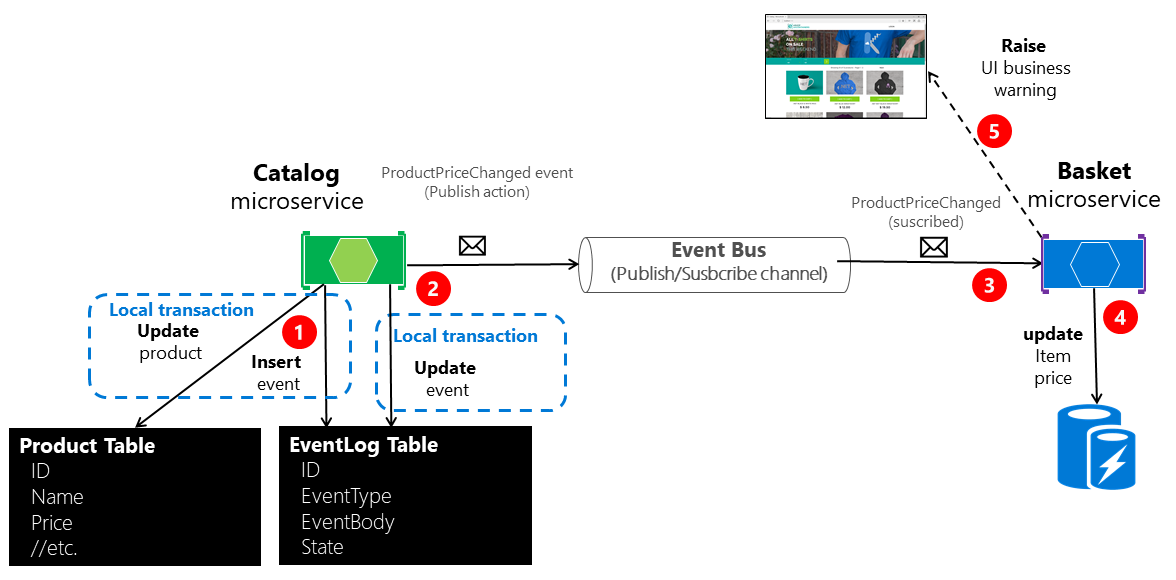
Rysunek 6–22. Niepodzielność podczas publikowania zdarzeń w magistrali zdarzeń
Na rysunku 6–22 brakuje dodatkowej mikrousługi pracowniczej, która jest odpowiedzialna za sprawdzanie i potwierdzanie powodzenia opublikowanych zdarzeń integracyjnych. W przypadku awarii dodatkowa mikrousługa kontrolera może odczytywać zdarzenia z tabeli i ponownie je publikować, czyli powtarza to krok 2.
Informacje o drugim podejściu: używasz tabeli EventLog jako kolejki i zawsze używasz mikrousługi worker do publikowania komunikatów. W takim przypadku proces jest podobny do przedstawionego na rysunku 6–23. Spowoduje to wyświetlenie dodatkowej mikrousługi, a tabela jest pojedynczym źródłem podczas publikowania zdarzeń.
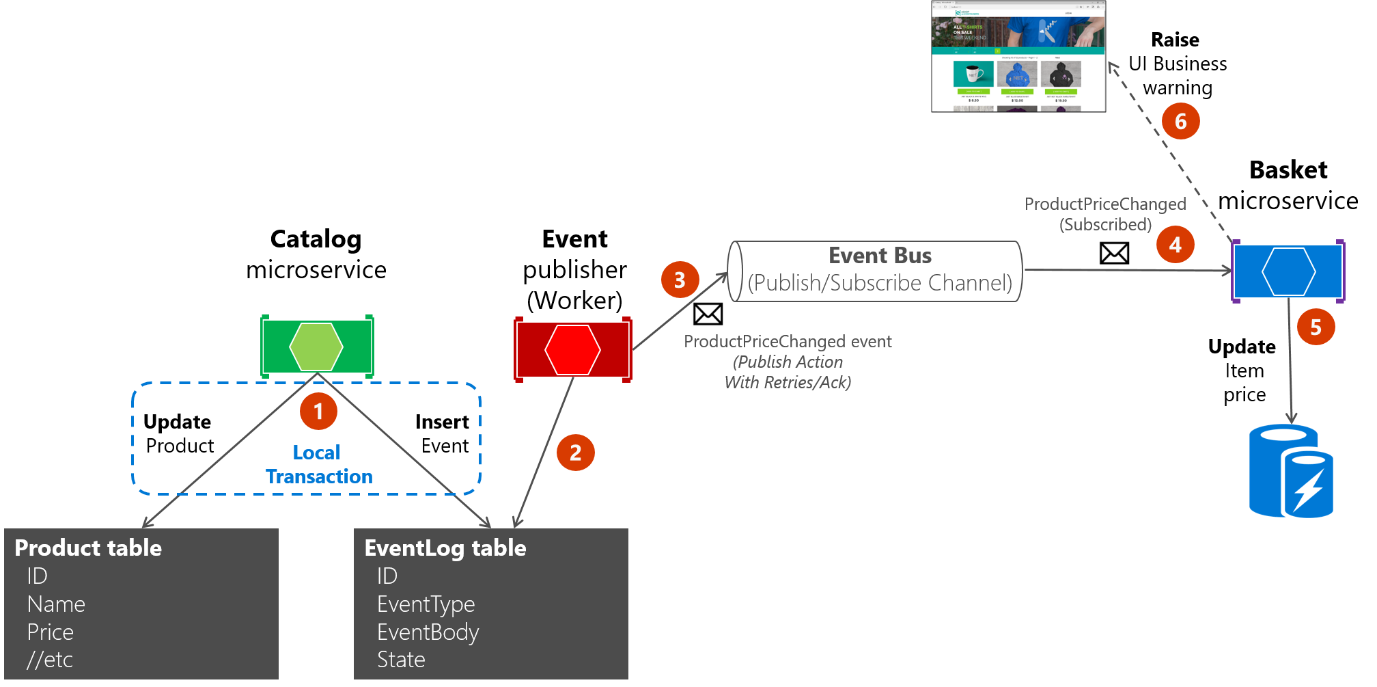
Rysunek 6–23. Niepodzielność podczas publikowania zdarzeń w magistrali zdarzeń za pomocą mikrousługi pracującej
Dla uproszczenia przykład eShopOnContainers używa pierwszego podejścia (bez dodatkowych procesów lub mikrousług kontrolnych) oraz magistrali zdarzeń. Jednak przykład eShopOnContainers nie obsługuje wszystkich możliwych przypadków awarii. W rzeczywistej aplikacji wdrożonej w chmurze należy uwzględnić fakt, że problemy pojawią się w końcu, i musisz zaimplementować tę logikę sprawdzania i ponownego wysłania. Użycie tabeli jako kolejki może być bardziej skuteczne niż pierwsze podejście, jeśli ta tabela jest jednym źródłem zdarzeń podczas publikowania ich (z procesem roboczym) za pośrednictwem magistrali zdarzeń.
Implementowanie atomowości podczas publikowania zdarzeń integracyjnych poprzez magistralę zdarzeń
Poniższy kod pokazuje, jak utworzyć jedną transakcję obejmującą wiele obiektów DbContext — jeden kontekst związany z aktualizowanym oryginalnymi danymi, a drugi kontekst związany z tabelą IntegrationEventLog.
Transakcja w poniższym przykładowym kodzie nie będzie odporna, jeśli połączenia z bazą danych mają jakikolwiek problem w momencie uruchomienia kodu. Może się to zdarzyć w systemach opartych na chmurze, takich jak usługa Azure SQL DB, która może przenosić bazy danych między serwerami. Aby zaimplementować odporne transakcje w wielu kontekstach, zobacz sekcję Implementowanie odpornych połączeń SQL platformy Entity Framework Core w dalszej części tego przewodnika.
W poniższym przykładzie pokazano cały proces w jednym fragcie kodu. Jednak implementacja eShopOnContainers jest refaktoryzowana i dzieli tę logikę na wiele klas, aby ułatwić konserwację.
// Update Product from the Catalog microservice
//
public async Task<IActionResult> UpdateProduct([FromBody]CatalogItem productToUpdate)
{
var catalogItem =
await _catalogContext.CatalogItems.SingleOrDefaultAsync(i => i.Id ==
productToUpdate.Id);
if (catalogItem == null) return NotFound();
bool raiseProductPriceChangedEvent = false;
IntegrationEvent priceChangedEvent = null;
if (catalogItem.Price != productToUpdate.Price)
raiseProductPriceChangedEvent = true;
if (raiseProductPriceChangedEvent) // Create event if price has changed
{
var oldPrice = catalogItem.Price;
priceChangedEvent = new ProductPriceChangedIntegrationEvent(catalogItem.Id,
productToUpdate.Price,
oldPrice);
}
// Update current product
catalogItem = productToUpdate;
// Just save the updated product if the Product's Price hasn't changed.
if (!raiseProductPriceChangedEvent)
{
await _catalogContext.SaveChangesAsync();
}
else // Publish to event bus only if product price changed
{
// Achieving atomicity between original DB and the IntegrationEventLog
// with a local transaction
using (var transaction = _catalogContext.Database.BeginTransaction())
{
_catalogContext.CatalogItems.Update(catalogItem);
await _catalogContext.SaveChangesAsync();
await _integrationEventLogService.SaveEventAsync(priceChangedEvent);
transaction.Commit();
}
// Publish the integration event through the event bus
_eventBus.Publish(priceChangedEvent);
_integrationEventLogService.MarkEventAsPublishedAsync(
priceChangedEvent);
}
return Ok();
}
Po utworzeniu zdarzenia integracyjnego ProductPriceChangedIntegrationEvent transakcja przechowująca oryginalną operację domeny (aktualizację elementu wykazu) obejmuje również zapisanie zdarzenia w tabeli EventLog. Dzięki temu jest to jedna transakcja i zawsze będzie można sprawdzić, czy komunikaty o zdarzeniach zostały wysłane.
Tabela dziennika zdarzeń jest aktualizowana atomowo wraz z oryginalną operacją bazy danych w ramach lokalnej transakcji przeciwko tej samej bazie danych. Jeśli którakolwiek z operacji zakończy się niepowodzeniem, zgłaszany jest wyjątek, a transakcja cofa wszystkie ukończone operacje, zachowując spójność między operacjami domeny a komunikatami zdarzeń zapisanymi w tabeli.
Odbieranie komunikatów z subskrypcji: programy obsługi zdarzeń w mikrousługach odbiorcy
Oprócz logiki subskrypcji zdarzeń należy zaimplementować kod wewnętrzny dla procedur obsługi zdarzeń integracji (takich jak metoda wywołania zwrotnego). Procedura obsługi zdarzeń określa miejsce odbierania i przetwarzania komunikatów o zdarzeniach określonego typu.
Program obsługi zdarzeń najpierw odbiera wystąpienie zdarzenia z magistrali zdarzeń. Następnie lokalizuje składnik do przetworzenia związanego z tym zdarzeniem integracji, propagując i utrwalając zdarzenie jako zmianę stanu w odbiorczej mikrousłudze. Jeśli na przykład zdarzenie zmiany ceny produktu pochodzi z mikrousługi katalogu, jest obsługiwane w mikrousłudze koszyka i zmienia stan w tej mikrousłudze koszyka odbiorcy, jak pokazano w poniższym kodzie.
namespace Microsoft.eShopOnContainers.Services.Basket.API.IntegrationEvents.EventHandling
{
public class ProductPriceChangedIntegrationEventHandler :
IIntegrationEventHandler<ProductPriceChangedIntegrationEvent>
{
private readonly IBasketRepository _repository;
public ProductPriceChangedIntegrationEventHandler(
IBasketRepository repository)
{
_repository = repository;
}
public async Task Handle(ProductPriceChangedIntegrationEvent @event)
{
var userIds = await _repository.GetUsers();
foreach (var id in userIds)
{
var basket = await _repository.GetBasket(id);
await UpdatePriceInBasketItems(@event.ProductId, @event.NewPrice, basket);
}
}
private async Task UpdatePriceInBasketItems(int productId, decimal newPrice,
CustomerBasket basket)
{
var itemsToUpdate = basket?.Items?.Where(x => int.Parse(x.ProductId) ==
productId).ToList();
if (itemsToUpdate != null)
{
foreach (var item in itemsToUpdate)
{
if(item.UnitPrice != newPrice)
{
var originalPrice = item.UnitPrice;
item.UnitPrice = newPrice;
item.OldUnitPrice = originalPrice;
}
}
await _repository.UpdateBasket(basket);
}
}
}
}
Program obsługi zdarzeń musi sprawdzić, czy produkt istnieje w dowolnym z wystąpień koszyka. Aktualizuje również cenę elementu dla każdego powiązanego elementu wiersza koszyka. Na koniec tworzy alert, który ma być wyświetlany użytkownikowi na temat zmiany ceny, jak pokazano na rysunku 6–24.
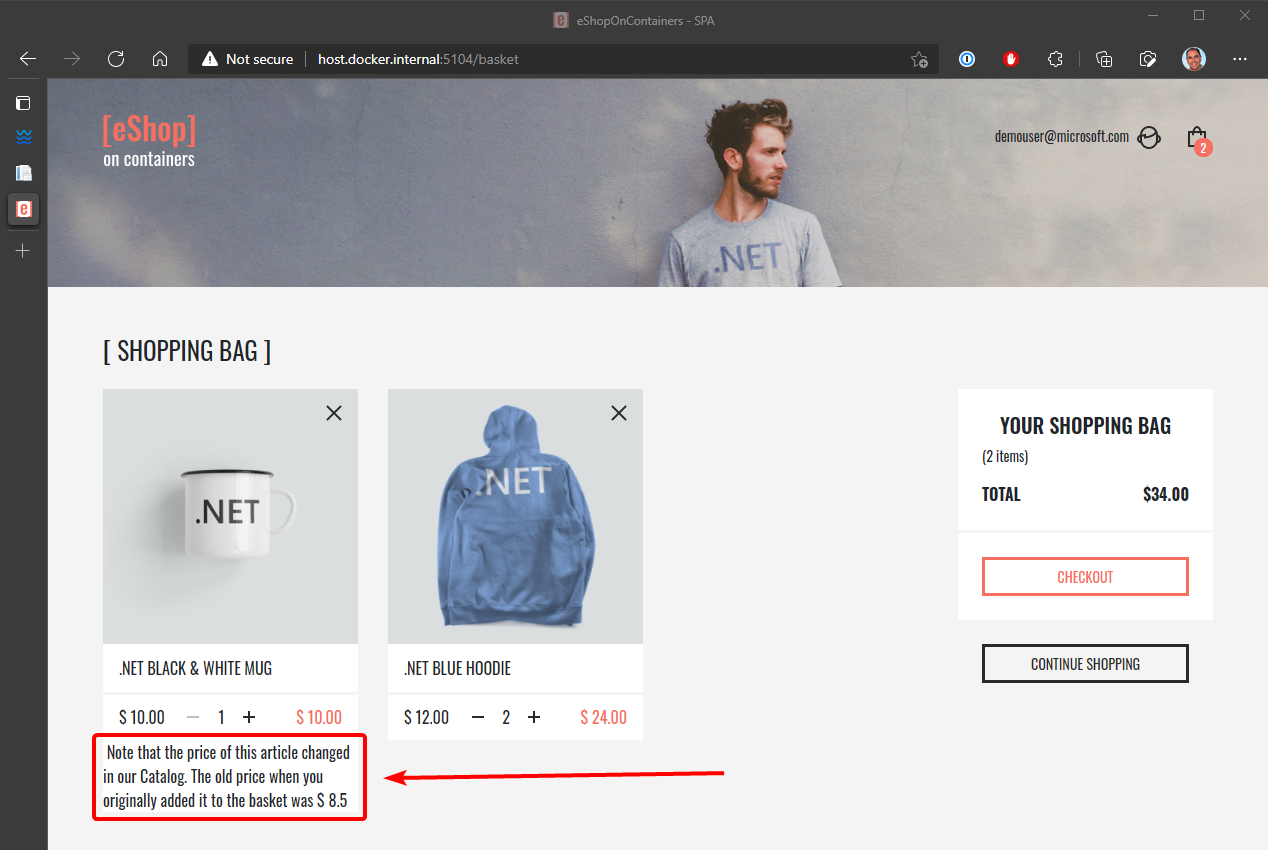
Rysunek 6–24. Wyświetlanie zmiany ceny elementu w koszyku zgodnie ze zdarzeniami integracji
Idempotency in update message events (Idempotentność w zdarzeniach komunikatów aktualizacji)
Ważnym aspektem zdarzeń związanych z komunikatami aktualizacji jest to, że każda awaria w komunikacji powinna prowadzić do ponownego wysłania komunikatu. W przeciwnym razie zadanie w tle może spróbować opublikować wydarzenie, które zostało już opublikowane, tworząc warunek wyścigu. Upewnij się, że aktualizacje są idempotentne lub zapewniają wystarczającą ilość informacji, aby upewnić się, że można wykryć duplikat, odrzucić je i wysłać z powrotem tylko jedną odpowiedź.
Jak wspomniano wcześniej, idempotencyjność oznacza, że można wykonać operację wiele razy bez zmiany wyniku. W środowisku przesyłania wiadomości, jak przy komunikowaniu zdarzeń, zdarzenie jest idempotentne, jeśli może być dostarczane wiele razy bez zmiany wyniku dla mikrousługi odbierającej. Może to być konieczne ze względu na charakter samego zdarzenia lub ze względu na sposób, w jaki system obsługuje zdarzenie. Idempotentność komunikatów jest ważna w każdej aplikacji korzystającej z komunikatów, a nie tylko w aplikacjach implementujących wzorzec magistrali zdarzeń.
Przykładem operacji idempotentnej jest instrukcja SQL, która wstawia dane do tabeli tylko wtedy, gdy te dane nie są jeszcze w tabeli. Nie ma znaczenia, ile razy uruchamiasz instrukcję SQL; wynik będzie taki sam — tabela będzie zawierać te dane. Idempotencja taka jak ta może być również konieczna w przypadku obsługi komunikatów, jeśli komunikaty mogą być potencjalnie wysyłane, a więc przetwarzane więcej niż raz. Jeśli na przykład logika ponawiania powoduje, że nadawca wysyła dokładnie ten sam komunikat więcej niż raz, musisz upewnić się, że jest on idempotentny.
Istnieje możliwość zaprojektowania komunikatów idempotentnych. Możesz na przykład utworzyć zdarzenie z komunikatem "ustaw cenę produktu na 25 USD" zamiast "dodaj $5 do ceny produktu". Pierwszy komunikat można bezpiecznie przetworzyć dowolną liczbę razy, a wynik będzie taki sam. To nieprawda dla drugiego komunikatu. Ale nawet w pierwszym przypadku możesz nie chcieć przetworzyć pierwszego zdarzenia, ponieważ system mógł również wysłać nowsze zdarzenie zmiany ceny i mogłoby to spowodować nadpisanie nowej ceny.
Innym przykładem może być zdarzenie ukończenia zamówienia, które jest propagowane do wielu subskrybentów. Aplikacja musi upewnić się, że informacje o zamówieniu są aktualizowane w innych systemach tylko raz, nawet jeśli istnieją zduplikowane zdarzenia komunikatów dla tego samego zdarzenia zakończenia zamówienia.
Wygodne jest posiadanie jakiejś tożsamości na zdarzenie, dzięki czemu można utworzyć logikę, która wymusza przetwarzanie każdego zdarzenia tylko raz na odbiorcę.
Niektóre procesy przetwarzania komunikatów są z natury idempotentne. Na przykład jeśli system generuje miniatury obrazów, może nie mieć znaczenia, ile razy komunikat o wygenerowanej miniaturze jest przetwarzany; wynikiem jest to, że miniatury są generowane i są takie same za każdym razem. Z drugiej strony, operacje takie jak wywoływanie bramy płatności do naliczania opłaty za kartę kredytową mogą wcale nie być idempotentne. W takich przypadkach należy upewnić się, że przetwarzanie komunikatu wiele razy ma oczekiwany efekt.
Dodatkowe zasoby
-
Honorowanie idempotentności wiadomości
https://learn.microsoft.com/previous-versions/msp-n-p/jj591565(v=pandp.10)#honoring-message-idempotency
Deduplikacja komunikatów dotyczących zdarzeń integracji
Możesz upewnić się, że komunikaty zdarzeń są wysyłane i przetwarzane tylko raz dla każdego subskrybenta na różnych poziomach. Jednym ze sposobów jest użycie funkcji deduplikacji oferowanej przez używaną infrastrukturę obsługi komunikatów. Innym jest zaimplementowanie niestandardowej logiki w docelowej mikrousłudze. Sprawdzanie poprawności zarówno na poziomie transportu, jak i na poziomie aplikacji jest najlepszym rozwiązaniem.
Usuwanie duplikatów zdarzeń wiadomości na poziomie EventHandler
Jednym ze sposobów upewnienia się, że zdarzenie jest przetwarzane tylko raz przez dowolny odbiornik, jest zaimplementowanie określonej logiki podczas przetwarzania zdarzeń komunikatów w programach obsługi zdarzeń. Na przykład jest to metoda używana w aplikacji eShopOnContainers, jak widać w kodzie źródłowym klasy UserCheckoutAcceptedIntegrationEventHandler po odebraniu UserCheckoutAcceptedIntegrationEvent zdarzenia integracji. (W tym przypadku CreateOrderCommand jest opakowany w IdentifiedCommand, używając eventMsg.RequestId jako identyfikatora, przed wysłaniem go do programu obsługi poleceń).
Deduplikacja komunikatów podczas korzystania z systemu RabbitMQ
Gdy występują sporadyczne awarie sieci, komunikaty mogą być zduplikowane, a odbiornik komunikatów musi być gotowy do obsługi tych zduplikowanych komunikatów. Jeśli to możliwe, odbiorcy powinni obsługiwać komunikaty w sposób idempotentny, co jest lepsze niż jawne obsługiwanie ich z deduplikacją.
Zgodnie z dokumentacją RabbitMQ, "Jeśli komunikat jest dostarczany do konsumenta, a następnie przekazany z powrotem do kolejki (ponieważ nie został potwierdzony przed usunięciem połączenia konsumenta, na przykład), RabbitMQ ustawi ponownie flagę redelivered przy ponownym dostarczeniu (czy do tego samego konsumenta, czy innego).
Jeśli ustawiono znacznik "redelivered", odbiorca musi to uwzględnić, ponieważ komunikat mógł już zostać przetworzony. Ale to nie jest gwarantowane; komunikat mógł nigdy nie dotrzeć do odbiornika po opuszczeniu brokera komunikatów, być może z powodu problemów z siecią. Z drugiej strony, jeśli flaga "redelivered" nie jest ustawiona, gwarantowana jest, że wiadomość nie została wysłana więcej niż raz. W związku z tym odbiorca musi deduplikować komunikaty lub przetwarzać komunikaty w sposób idempotentny tylko wtedy, gdy flaga "redelivered" jest ustawiona w komunikacie.
Dodatkowe zasoby
Forkowanie eShopOnContainers przy użyciu NServiceBus (Particular Software)
https://go.particular.net/eShopOnContainersObsługa komunikatów sterowanych zdarzeniami
https://patterns.arcitura.com/soa-patterns/design_patterns/event_driven_messagingJimmy Bogard. Refaktoryzacja w kierunku odporności: ocenianie sprzężenia
https://jimmybogard.com/refactoring-towards-resilience-evaluating-coupling/kanałPublish-Subscribe
https://www.enterpriseintegrationpatterns.com/patterns/messaging/PublishSubscribeChannel.htmlKomunikacja między powiązanymi kontekstami
https://learn.microsoft.com/previous-versions/msp-n-p/jj591572(v=pandp.10)Spójność docelowa
https://en.wikipedia.org/wiki/Eventual_consistencyPhilip Brown. Strategie integrowania ograniczonych kontekstów
https://www.culttt.com/2014/11/26/strategies-integrating-bounded-contexts/Chris Richardson. Opracowywanie transakcyjnych mikrousług przy użyciu agregacji, określania źródła zdarzeń i CQRS — część 2
https://www.infoq.com/articles/microservices-aggregates-events-cqrs-part-2-richardsonChris Richardson. Wzorzec określania źródła zdarzeń
https://microservices.io/patterns/data/event-sourcing.htmlWprowadzenie do Event Sourcing
https://learn.microsoft.com/previous-versions/msp-n-p/jj591559(v=pandp.10)Baza danych Event Store. Oficjalna witryna.
https://geteventstore.com/Patrick Nommensen. zarządzanie danymi Event-Driven dla mikrousług
https://dzone.com/articles/event-driven-data-management-for-microservices-1Twierdzenie CAP
https://en.wikipedia.org/wiki/CAP_theoremCo to jest twierdzenie CAP?
https://www.quora.com/What-Is-CAP-Theorem-1Podstawy spójności danych
https://learn.microsoft.com/previous-versions/msp-n-p/dn589800(v=pandp.10)Rick Saling. Twierdzenie CAP: Dlaczego "Wszystko jest różne" z chmurą i Internetem
https://learn.microsoft.com/archive/blogs/rickatmicrosoft/the-cap-theorem-why-everything-is-different-with-the-cloud-and-internet/Eric Brewer. WPR dwanaście lat później: jak zmieniły się "reguły"
https://www.infoq.com/articles/cap-twelve-years-later-how-the-rules-have-changedCAP, PACELC i mikrousługi
https://ardalis.com/cap-pacelc-and-microservices/Azure Service Bus. Komunikacja brokerska: wykrywanie duplikatów
https://github.com/microsoftarchive/msdn-code-gallery-microsoft/tree/master/Windows%20Azure%20Product%20Team/Brokered%20Messaging%20Duplicate%20DetectionPrzewodnik po niezawodności (dokumentacja RabbitMQ)
https://www.rabbitmq.com/reliability.html#consumer
Współpracuj z nami na GitHub
Źródło tej zawartości można znaleźć w witrynie GitHub, gdzie można również tworzyć i przeglądać problemy oraz żądania ściągnięcia. Aby uzyskać więcej informacji, zapoznaj się z naszym przewodnikiem dla twórców.