Obsługa wyjątków i błędów
Wyjątki są używane do lokalnego komunikowania błędów w usłudze lub implementacji klienta. Z drugiej strony błędy są używane do komunikowania błędów poza granicami usługi, takich jak z serwera do klienta lub na odwrót. Oprócz usterek kanały transportu często używają mechanizmów specyficznych dla transportu do komunikowania błędów na poziomie transportu. Na przykład transport HTTP używa kodów stanu, takich jak 404, aby komunikować się z nieistnienym adresem URL punktu końcowego (nie ma punktu końcowego do wysłania błędu). Ten dokument składa się z trzech sekcji, które zawierają wskazówki dla autorów kanałów niestandardowych. Pierwsza sekcja zawiera wskazówki dotyczące tego, kiedy i jak definiować i zgłaszać wyjątki. Druga sekcja zawiera wskazówki dotyczące generowania i używania błędów. W trzeciej sekcji wyjaśniono, jak dostarczyć informacje o śledzeniu, aby ułatwić użytkownikowi kanału niestandardowego rozwiązywanie problemów z uruchomionymi aplikacjami.
Wyjątki
Podczas zgłaszania wyjątku należy pamiętać o dwóch kwestiach: najpierw musi być typu, który umożliwia użytkownikom pisanie poprawnego kodu, który może odpowiednio reagować na wyjątek. Po drugie, musi dostarczyć użytkownikowi wystarczające informacje, aby zrozumieć, co poszło nie tak, wpływ na awarię i jak go naprawić. Poniższe sekcje zawierają wskazówki dotyczące typów wyjątków i komunikatów dla kanałów programu Windows Communication Foundation (WCF). Istnieją również ogólne wskazówki dotyczące wyjątków na platformie .NET w dokumencie Wytyczne dotyczące projektowania wyjątków.
Typy wyjątków
Wszystkie wyjątki zgłaszane przez kanały muszą być System.TimeoutExceptiontypu , System.ServiceModel.CommunicationExceptionlub typu pochodzącego z CommunicationExceptionklasy . (Wyjątki, takie jak ObjectDisposedException mogą być również zgłaszane, ale tylko w celu wskazania, że kod wywołujący nieprawidłowo używa kanału. Jeśli kanał jest używany poprawnie, musi zgłaszać tylko podane wyjątki). Program WCF udostępnia siedem typów wyjątków, które pochodzą z CommunicationException i są przeznaczone do użycia przez kanały. Istnieją inne CommunicationExceptionwyjątki pochodne, które mają być używane przez inne części systemu. Te typy wyjątków to:
| Typ wyjątku | Znaczenie | Zawartość wyjątku wewnętrznego | Strategia odzyskiwania |
|---|---|---|---|
| AddressAlreadyInUseException | Adres punktu końcowego określony do nasłuchiwania jest już używany. | Jeśli jest obecny, zawiera więcej szczegółów na temat błędu transportu, który spowodował ten wyjątek. Na przykład PipeException, HttpListenerExceptionlub SocketException. | Spróbuj użyć innego adresu. |
| AddressAccessDeniedException | Proces nie może uzyskać dostępu do adresu punktu końcowego określonego na potrzeby nasłuchiwania. | Jeśli jest obecny, zawiera więcej szczegółów na temat błędu transportu, który spowodował ten wyjątek. Na przykład , PipeExceptionlub HttpListenerException. | Spróbuj użyć różnych poświadczeń. |
| CommunicationObjectFaultedException | Używany ICommunicationObject jest w stanie Błąd (aby uzyskać więcej informacji, zobacz Opis zmian stanu). Należy pamiętać, że gdy obiekt z wieloma oczekującymi wywołaniami przechodzi do stanu Błędy, tylko jedno wywołanie zgłasza wyjątek związany z awarią, a pozostałe wywołania zgłaszają wyjątek CommunicationObjectFaultedException. Ten wyjątek jest zwykle zgłaszany, ponieważ aplikacja pomija jakiś wyjątek i próbuje użyć już uszkodzonego obiektu, prawdopodobnie w wątku innym niż ten, który przechwycił oryginalny wyjątek. | Jeśli element obecny zawiera szczegółowe informacje na temat wyjątku wewnętrznego. | Utwórz nowy obiekt. Należy pamiętać, że w zależności od przyczyn wystąpienia błędu ICommunicationObject w pierwszej kolejności może istnieć inna praca wymagana do odzyskania. |
| CommunicationObjectAbortedException | Używany ICommunicationObject element został przerwany (aby uzyskać więcej informacji, zobacz Opis zmian stanu). Podobnie jak CommunicationObjectFaultedExceptionw przypadku , ten wyjątek wskazuje, że aplikacja wywołała Abort obiekt, prawdopodobnie z innego wątku, a obiekt nie jest już używany z tego powodu. | Jeśli element obecny zawiera szczegółowe informacje na temat wyjątku wewnętrznego. | Utwórz nowy obiekt. Należy pamiętać, że w zależności od tego, co spowodowało ICommunicationObject przerwanie w pierwszej kolejności, może istnieć inna praca wymagana do odzyskania. |
| EndpointNotFoundException | Docelowy zdalny punkt końcowy nie nasłuchuje. Może to spowodować, że dowolny element adresu punktu końcowego jest niepoprawny, nieodwracalny lub punkt końcowy jest wyłączony. Przykłady obejmują błąd DNS, menedżer kolejek niedostępny i usługa nie jest uruchomiona. | Wyjątek wewnętrzny zawiera szczegóły, zazwyczaj z transportu bazowego. | Spróbuj użyć innego adresu. Alternatywnie nadawca może poczekać chwilę i spróbować ponownie, jeśli usługa nie działa |
| ProtocolException | Protokoły komunikacyjne, zgodnie z opisem zasad punktu końcowego, są niezgodne między punktami końcowymi. Na przykład niedopasowanie typu zawartości do ramek lub przekroczono maksymalny rozmiar komunikatu. | Jeśli jest obecny, zawiera więcej informacji na temat określonego błędu protokołu. Na przykład jest wyjątkiem wewnętrznym, QuotaExceededException gdy przyczyna błędu przekracza wartość MaxReceivedMessageSize. | Odzyskiwanie: upewnij się, że ustawienia nadawcy i odebranych protokołów są zgodne. Jednym ze sposobów jest ponowne zaimportowanie metadanych (zasad) punktu końcowego usługi i ponowne utworzenie kanału przy użyciu wygenerowanego powiązania. |
| ServerTooBusyException | Zdalny punkt końcowy nasłuchuje, ale nie jest przygotowany do przetwarzania komunikatów. | Jeśli jest obecny, wewnętrzny wyjątek zawiera szczegóły błędu protokołu SOAP lub błędu na poziomie transportu. | Odzyskiwanie: Poczekaj i ponów próbę wykonania operacji później. |
| TimeoutException | Operacja nie powiodła się w okresie przekroczenia limitu czasu. | Może podać szczegółowe informacje o przekroczeniu limitu czasu. | Poczekaj i ponów próbę wykonania operacji później. |
Zdefiniuj nowy typ wyjątku tylko wtedy, gdy ten typ odpowiada określonej strategii odzyskiwania innej niż wszystkie istniejące typy wyjątków. Jeśli zdefiniujesz nowy typ wyjątku, musi pochodzić z lub jednej z CommunicationException jego klas pochodnych.
Komunikaty o wyjątkach
Komunikaty o wyjątkach są przeznaczone dla użytkownika, a nie programu, dlatego powinny dostarczyć wystarczające informacje, aby ułatwić użytkownikowi zrozumienie i rozwiązanie problemu. Trzy podstawowe części dobrego komunikatu o wyjątku to:
co miało miejsce. Podaj jasny opis problemu przy użyciu terminów odnoszących się do środowiska użytkownika. Na przykład nieprawidłowy komunikat o wyjątku to "Nieprawidłowa sekcja konfiguracji". Spowoduje to, że użytkownik zastanawia się, która sekcja konfiguracji jest niepoprawna i dlaczego jest niepoprawna. Ulepszony komunikat to "Invalid configuration section customBinding" (Nieprawidłowa sekcja <konfiguracji customBinding>). Jeszcze lepszym komunikatem będzie "Nie można dodać transportu o nazwie myTransport do powiązania o nazwie myBinding, ponieważ powiązanie ma już transport o nazwie myTransport". Jest to bardzo konkretny komunikat używający terminów i nazw, które użytkownik może łatwo zidentyfikować w pliku konfiguracji aplikacji. Jednak nadal brakuje kilku kluczowych składników.
Znaczenie błędu. Chyba że komunikat wyraźnie wskazuje, co oznacza błąd, użytkownik może się zastanawiać, czy jest to błąd krytyczny, czy też można go zignorować. Ogólnie rzecz biorąc, komunikaty powinny prowadzić do znaczenia lub znaczenia błędu. Aby ulepszyć poprzedni przykład, komunikat może mieć wartość "ServiceHost failed to Open due to a configuration error: Cannot add the transport named myTransport to the binding named myBinding because the binding already has a transport named myTransport".
Jak użytkownik powinien rozwiązać ten problem. Najważniejszą częścią komunikatu jest pomoc użytkownikowi w rozwiązaniu problemu. Komunikat powinien zawierać wskazówki lub wskazówki dotyczące tego, co należy sprawdzić lub rozwiązać, aby rozwiązać problem. Na przykład "ServiceHost nie można otworzyć z powodu błędu konfiguracji: Nie można dodać transportu o nazwie myTransport do powiązania o nazwie myBinding, ponieważ powiązanie ma już transport o nazwie myTransport. Upewnij się, że w powiązaniu znajduje się tylko jeden transport".
Komunikacja błędów
Protokół SOAP 1.1 i SOAP 1.2 definiują określoną strukturę błędów. Istnieją pewne różnice między dwoma specyfikacjami, ale ogólnie typy Message i MessageFault są używane do tworzenia i korzystania z błędów.
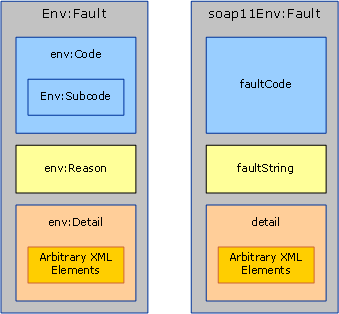
Błąd PROTOKOŁU SOAP 1.2 (po lewej) i błąd SOAP 1.1 (po prawej). W usłudze SOAP 1.1 tylko element Fault jest kwalifikowany.
Protokół SOAP definiuje komunikat o błędzie jako komunikat zawierający tylko element błędu (element, którego nazwa to <env:Fault>) jako element podrzędny <env:Body>. Zawartość elementu błędu różni się nieco między soap 1.1 i SOAP 1.2, jak pokazano na rysunku 1. System.ServiceModel.Channels.MessageFault Jednak klasa normalizuje te różnice w jednym modelu obiektów:
public abstract class MessageFault
{
protected MessageFault();
public virtual string Actor { get; }
public virtual string Node { get; }
public static string DefaultAction { get; }
public abstract FaultCode Code { get; }
public abstract bool HasDetail { get; }
public abstract FaultReason Reason { get; }
public T GetDetail<T>();
public T GetDetail<T>( XmlObjectSerializer serializer);
public System.Xml.XmlDictionaryReader GetReaderAtDetailContents();
// other methods omitted
}
Właściwość Code odpowiada env:Code (lub faultCode w soap 1.1) i identyfikuje typ błędu. Protokół SOAP 1.2 definiuje pięć dozwolonych wartości faultCode (na przykład Nadawca i Odbiornik) i definiuje element, który może zawierać dowolną Subcode wartość podkodowania. (Zobacz Specyfikacja protokołu SOAP 1.2 dla listy dozwolonych kodów błędów i ich znaczenia). Protokół SOAP 1.1 ma nieco inny mechanizm: definiuje cztery faultCode wartości (na przykład Klient i serwer), które można rozszerzyć, definiując zupełnie nowe lub używając notacji kropkowej, aby utworzyć bardziej szczegółowe faultCodes, na przykład Client.Authentication.
W przypadku używania funkcji MessageFault do programowania błędów FaultCode.Name i FaultCode.Namespace są mapowane na nazwę i przestrzeń nazw protokołu SOAP 1.2 env:Code lub SOAP 1.1 faultCode. Kod błędu FaultCode.SubCode jest mapowany na env:Subcode wartość dla protokołu SOAP 1.2 i ma wartość null dla protokołu SOAP 1.1.
Należy utworzyć nowe podkody błędów (lub nowe kody błędów, jeśli używasz protokołu SOAP 1.1), jeśli interesujące jest programowe odróżnienie błędu. Jest to analogiczne do tworzenia nowego typu wyjątku. Należy unikać używania notacji kropkowej z kodami błędów protokołu SOAP 1.1. (Profil podstawowy WS-I zniechęca również do korzystania z notacji kropkowej kodu błędu).
public class FaultCode
{
public FaultCode(string name);
public FaultCode(string name, FaultCode subCode);
public FaultCode(string name, string ns);
public FaultCode(string name, string ns, FaultCode subCode);
public bool IsPredefinedFault { get; }
public bool IsReceiverFault { get; }
public bool IsSenderFault { get; }
public string Name { get; }
public string Namespace { get; }
public FaultCode SubCode { get; }
// methods omitted
}
Właściwość Reason odpowiada env:Reason (lub faultString w soap 1.1) czytelny dla człowieka opis warunku błędu analogiczny do komunikatu wyjątku. Klasa FaultReason (i SOAP env:Reason/faultString) ma wbudowaną obsługę obsługi wielu tłumaczeń w interesie globalizacji.
public class FaultReason
{
public FaultReason(FaultReasonText translation);
public FaultReason(IEnumerable<FaultReasonText> translations);
public FaultReason(string text);
public SynchronizedReadOnlyCollection<FaultReasonText> Translations
{
get;
}
}
Zawartość szczegółów błędu jest uwidoczniona w usłudze MessageFault przy użyciu różnych metod, w tym GetDetail<T> i GetReaderAtDetailContents(). Szczegóły błędu to nieprzezroczystym elementem do przenoszenia dodatkowych szczegółów dotyczących błędu. Jest to przydatne, jeśli istnieje dowolny ustrukturyzowany szczegół, który ma być przenoszony z błędem.
Generowanie błędów
W tej sekcji opisano proces generowania błędu w odpowiedzi na błąd wykryty w kanale lub we właściwości komunikatu utworzonej przez kanał. Typowym przykładem jest wysłanie z powrotem błędu w odpowiedzi na komunikat żądania, który zawiera nieprawidłowe dane.
Podczas generowania błędu kanał niestandardowy nie powinien wysyłać błędu bezpośrednio, dlatego powinien zgłosić wyjątek i pozwolić powyższej warstwie zdecydować, czy przekonwertować ten wyjątek na błąd i jak go wysłać. Aby pomóc w tej konwersji, kanał powinien zapewnić implementację FaultConverter , która może przekonwertować wyjątek zgłoszony przez kanał niestandardowy na odpowiedni błąd. FaultConverter parametr jest zdefiniowany jako:
public class FaultConverter
{
public static FaultConverter GetDefaultFaultConverter(
MessageVersion version);
protected abstract bool OnTryCreateFaultMessage(
Exception exception,
out Message message);
public bool TryCreateFaultMessage(
Exception exception,
out Message message);
}
Każdy kanał, który generuje niestandardowe błędy, musi implementować FaultConverter i zwracać go z wywołania do GetProperty<FaultConverter>. Implementacja niestandardowa OnTryCreateFaultMessage musi przekonwertować wyjątek na błąd lub delegować go do kanału FaultConverterwewnętrznego . Jeśli kanał jest transportem, musi przekonwertować wyjątek lub delegować do kodera FaultConverter lub wartość domyślna FaultConverter podana w programie WCF . Wartość domyślna FaultConverter konwertuje błędy odpowiadające komunikatom o błędach określonym przez adresowanie WS i protokół SOAP. Oto przykładowa OnTryCreateFaultMessage implementacja.
public override bool OnTryCreateFaultMessage(Exception exception,
out Message message)
{
if (exception is ...)
{
message = ...;
return true;
}
#if IMPLEMENTING_TRANSPORT_CHANNEL
FaultConverter encoderConverter =
this.encoder.GetProperty<FaultConverter>();
if ((encoderConverter != null) &&
(encoderConverter.TryCreateFaultMessage(
exception, out message)))
{
return true;
}
FaultConverter defaultConverter =
FaultConverter.GetDefaultFaultConverter(
this.channel.messageVersion);
return defaultConverter.TryCreateFaultMessage(
exception,
out message);
#else
FaultConverter inner =
this.innerChannel.GetProperty<FaultConverter>();
if (inner != null)
{
return inner.TryCreateFaultMessage(exception, out message);
}
else
{
message = null;
return false;
}
#endif
}
Implikacją tego wzorca jest to, że wyjątki zgłaszane między warstwami w przypadku warunków błędów wymagających błędów muszą zawierać wystarczające informacje dla odpowiedniego generatora błędów, aby utworzyć poprawną usterkę. Jako niestandardowy autor kanału można zdefiniować typy wyjątków, które odpowiadają różnym warunkom błędów, jeśli takie wyjątki jeszcze nie istnieją. Należy pamiętać, że wyjątki przechodzące przez warstwy kanału powinny komunikować się ze stanem błędu, a nie nieprzezroczyste dane błędów.
Kategorie błędów
Zazwyczaj istnieją trzy kategorie błędów:
Błędy, które są wszechobecne w całym stosie. Te błędy można napotkać w dowolnej warstwie w stosie kanału, na przykład InvalidCardinalityAddressingException.
Błędy, które można napotkać w dowolnym miejscu powyżej określonej warstwy w stosie, na przykład niektóre błędy dotyczące przepływanej transakcji lub ról zabezpieczeń.
Błędy skierowane do pojedynczej warstwy w stosie, na przykład błędy, takie jak błędy numeru sekwencji WS-RM.
Kategoria 1. Błędy są zazwyczaj błędami WS-Addressing i SOAP. Klasa bazowa FaultConverter dostarczana przez usługę WCF konwertuje błędy odpowiadające komunikatom o błędach określonym przez usługę WS-Addressing i SOAP, dzięki czemu nie trzeba samodzielnie obsługiwać konwersji tych wyjątków.
Kategoria 2. Błędy występują, gdy warstwa dodaje właściwość do komunikatu, który nie korzysta całkowicie z informacji o komunikatach odnoszących się do tej warstwy. Błędy mogą zostać wykryte później, gdy wyższa warstwa prosi właściwość komunikatu o dalsze przetwarzanie informacji o wiadomościach. Takie kanały powinny implementować określone wcześniej, GetProperty aby umożliwić wyższej warstwie wysyłanie z powrotem poprawnego błędu. Przykładem jest TransactionMessageProperty. Ta właściwość jest dodawana do komunikatu bez pełnego sprawdzania poprawności wszystkich danych w nagłówku (może to obejmować skontaktowanie się z koordynatorem transakcji rozproszonej (DTC).
Kategoria 3. Błędy są generowane i wysyłane tylko przez jedną warstwę w procesorze. W związku z tym wszystkie wyjątki są zawarte w warstwie. Aby zwiększyć spójność kanałów i ułatwić konserwację, kanał niestandardowy powinien używać określonego wcześniej wzorca do generowania komunikatów o błędach nawet w przypadku błędów wewnętrznych.
Interpretowanie odebranych błędów
Ta sekcja zawiera wskazówki dotyczące generowania odpowiedniego wyjątku podczas odbierania komunikatu o błędzie. Drzewo decyzyjne do przetwarzania komunikatu w każdej warstwie w stosie jest następujące:
Jeśli warstwa uzna komunikat za nieprawidłowy, warstwa powinna wykonać przetwarzanie "nieprawidłowego komunikatu". Takie przetwarzanie jest specyficzne dla warstwy, ale może obejmować usunięcie komunikatu, śledzenia lub zgłoszenie wyjątku, który zostanie przekonwertowany na błąd. Przykłady obejmują odbieranie komunikatu zabezpieczeń, który nie jest prawidłowo zabezpieczony, lub komunikat odbierający komunikat z nieprawidłowym numerem sekwencji.
W przeciwnym razie, jeśli komunikat jest komunikatem o błędzie, który dotyczy konkretnie warstwy, a komunikat nie ma znaczenia poza interakcją warstwy, warstwa powinna obsłużyć warunek błędu. Przykładem tego jest błąd odmowy sekwencji RM, który jest bez znaczenia dla warstw nad kanałem RM i oznacza to błąd kanału RM i zgłaszanie z oczekujących operacji.
W przeciwnym razie komunikat powinien zostać zwrócony z żądania() lub receive(). Dotyczy to przypadków, w których warstwa rozpoznaje błąd, ale błąd wskazuje tylko, że żądanie nie powiodło się i nie oznacza błędu kanału i zgłaszało oczekujące operacje. Aby poprawić użyteczność w takim przypadku, warstwa powinna zaimplementować
GetProperty<FaultConverter>i zwrócić klasę pochodnąFaultConverter, która może przekonwertować błąd na wyjątek przez zastąpienieOnTryCreateExceptionelementu .
Następujący model obiektów obsługuje konwertowanie komunikatów na wyjątki:
public class FaultConverter
{
public static FaultConverter GetDefaultFaultConverter(
MessageVersion version);
protected abstract bool OnTryCreateException(
Message message,
MessageFault fault,
out Exception exception);
public bool TryCreateException(
Message message,
MessageFault fault,
out Exception exception);
}
Warstwa kanału może implementować GetProperty<FaultConverter> w celu obsługi konwertowania komunikatów o błędach na wyjątki. W tym celu przesłoń OnTryCreateException i sprawdź komunikat o błędzie. Jeśli zostanie rozpoznana, wykonaj konwersję, w przeciwnym razie poproś kanał wewnętrzny o jego przekonwertowanie. Kanały transportu powinny delegować do pobrania FaultConverter.GetDefaultFaultConverter domyślnego błędu SOAP/WS-Addressing FaultConverter.
Typowa implementacja wygląda następująco:
public override bool OnTryCreateException(
Message message,
MessageFault fault,
out Exception exception)
{
if (message.Action == "...")
{
exception = ...;
return true;
}
// OR
if ((fault.Code.Name == "...") && (fault.Code.Namespace == "..."))
{
exception = ...;
return true;
}
if (fault.IsMustUnderstand)
{
if (fault.WasHeaderNotUnderstood(
message.Headers, "...", "..."))
{
exception = new ProtocolException(...);
return true;
}
}
#if IMPLEMENTING_TRANSPORT_CHANNEL
FaultConverter encoderConverter =
this.encoder.GetProperty<FaultConverter>();
if ((encoderConverter != null) &&
(encoderConverter.TryCreateException(
message, fault, out exception)))
{
return true;
}
FaultConverter defaultConverter =
FaultConverter.GetDefaultFaultConverter(
this.channel.messageVersion);
return defaultConverter.TryCreateException(
message, fault, out exception);
#else
FaultConverter inner =
this.innerChannel.GetProperty<FaultConverter>();
if (inner != null)
{
return inner.TryCreateException(message, fault, out exception);
}
else
{
exception = null;
return false;
}
#endif
}
W przypadku określonych warunków błędów, które mają różne scenariusze odzyskiwania, rozważ zdefiniowanie klasy pochodnej klasy ProtocolException.
MustUnderstand Processing
Protokół SOAP definiuje ogólną usterkę sygnalizającą, że wymagany nagłówek nie był zrozumiały dla odbiornika. Ten błąd jest znany jako mustUnderstand błąd. W programie WCF kanały niestandardowe nigdy nie generują mustUnderstand błędów. Zamiast tego dyspozytor WCF, który znajduje się w górnej części stosu komunikacyjnego programu WCF, sprawdza, czy wszystkie nagłówki oznaczone jako MustUnderstand=true były zrozumiałe dla bazowego stosu. Jeśli jakiekolwiek z nich nie zostało zrozumiane, w tym momencie zostanie wygenerowana usterka mustUnderstand . (Użytkownik może wyłączyć to mustUnderstand przetwarzanie i mieć aplikację odbierać wszystkie nagłówki komunikatów. W takim przypadku aplikacja jest odpowiedzialna za wykonywanie mustUnderstand przetwarzania). Wygenerowany błąd zawiera nagłówek NotUnderstood zawierający nazwy wszystkich nagłówków z wartością MustUnderstand=true, które nie zostały zrozumiane.
Jeśli kanał protokołu wysyła niestandardowy nagłówek z wartością MustUnderstand=true i otrzymuje mustUnderstand błąd, musi ustalić, czy ten błąd jest spowodowany wysłanym nagłówkiem. W klasie znajdują się dwa elementy członkowskie MessageFault , które są przydatne w tym celu:
public class MessageFault
{
...
public bool IsMustUnderstandFault { get; }
public static bool WasHeaderNotUnderstood(MessageHeaders headers,
string name, string ns) { }
...
}
IsMustUnderstandFault zwraca true wartość , jeśli błąd jest błędem mustUnderstand . WasHeaderNotUnderstood Zwraca true wartość , jeśli nagłówek o określonej nazwie i przestrzeni nazw jest uwzględniony w błędzie jako nagłówek NotUnderstood. W przeciwnym razie zwraca wartość false.
Jeśli kanał emituje nagłówek oznaczony jako MustUnderstand = true, ta warstwa powinna również zaimplementować wzorzec interfejsu API generowania wyjątków i powinna konwertować mustUnderstand błędy spowodowane przez ten nagłówek na bardziej przydatny wyjątek, jak opisano wcześniej.
Śledzenie
Program .NET Framework udostępnia mechanizm śledzenia wykonywania programu jako sposób na pomoc w diagnozowaniu aplikacji produkcyjnych lub sporadycznych problemach, gdy nie można po prostu dołączyć debugera i przejść przez kod. Podstawowe składniki tego mechanizmu znajdują się w System.Diagnostics przestrzeni nazw i składają się z następujących elementów:
System.Diagnostics.TraceSource, który jest źródłem informacji śledzenia, które mają być zapisywane, System.Diagnostics.TraceListener, czyli abstrakcyjną klasą bazową dla konkretnych odbiorników, które odbierają informacje, które mają być śledzone z obiektu TraceSource i wyprowadza je do miejsca docelowego specyficznego dla odbiornika. Na przykład XmlWriterTraceListener dane śledzenia są zwracane do pliku XML. Na koniec element System.Diagnostics.TraceSwitch, który umożliwia użytkownikowi aplikacji kontrolowanie szczegółowości śledzenia i jest zwykle określony w konfiguracji.
Oprócz podstawowych składników można użyć narzędzia podglądu śledzenia usługi (SvcTraceViewer.exe) do wyświetlania i wyszukiwania śladów WCF. Narzędzie zostało zaprojektowane specjalnie pod kątem plików śledzenia generowanych przez usługę WCF i zapisywanych przy użyciu polecenia XmlWriterTraceListener. Na poniższej ilustracji przedstawiono różne składniki związane z śledzeniem.
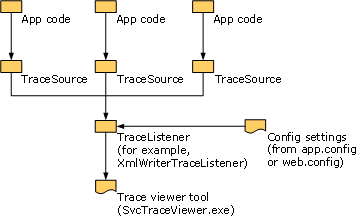
Śledzenie z niestandardowego kanału
Kanały niestandardowe powinny zapisywać komunikaty śledzenia, aby pomóc w diagnozowaniu problemów, gdy nie można dołączyć debugera do uruchomionej aplikacji. Obejmuje to dwa zadania wysokiego poziomu: utworzenie wystąpienia obiektu TraceSource i wywołanie jego metod w celu zapisania śladów.
Podczas tworzenia wystąpienia obiektu TraceSourceokreślony ciąg staje się nazwą tego źródła. Ta nazwa służy do konfigurowania (włącz/wyłącz/ustaw poziom śledzenia) źródła śledzenia. Pojawia się również w danych wyjściowych śledzenia. Kanały niestandardowe powinny używać unikatowej nazwy źródłowej, aby ułatwić czytelnikom danych wyjściowych śledzenia zrozumienie, skąd pochodzą informacje o śledzeniu. Typowym rozwiązaniem jest użycie nazwy zestawu, który zapisuje informacje jako nazwę źródła śledzenia. Na przykład WCF używa elementu System.ServiceModel jako źródła śledzenia informacji zapisanych z zestawu System.ServiceModel.
Po utworzeniu źródła śledzenia należy wywołać jego TraceDatametody , TraceEventlub TraceInformation w celu zapisania wpisów śledzenia do odbiorników śledzenia. Dla każdego zapisu wpisu śledzenia należy sklasyfikować typ zdarzenia jako jeden z typów zdarzeń zdefiniowanych w pliku TraceEventType. Ta klasyfikacja i ustawienie poziomu śledzenia w konfiguracji określają, czy wpis śledzenia jest wyjściowy do odbiornika. Na przykład ustawienie poziomu śledzenia w konfiguracji w celu zezwalania WarningWarning na zapisywanie wpisów i śledzenia, ErrorCritical ale blokuje informacje i pełne wpisy. Oto przykład tworzenia wystąpienia źródła śledzenia i zapisywania wpisu na poziomie informacji:
using System.Diagnostics;
//...
TraceSource udpSource = new TraceSource("Microsoft.Samples.Udp");
//...
udpsource.TraceInformation("UdpInputChannel received a message");
Ważne
Zdecydowanie zaleca się określenie nazwy źródła śledzenia, która jest unikatowa dla niestandardowego kanału, aby ułatwić śledzenie czytników danych wyjściowych, z których pochodzą dane wyjściowe.
Integrowanie z przeglądarką śledzenia
Ślady generowane przez kanał mogą być danymi wyjściowymi w formacie czytelnym przez narzędzie podglądu śledzenia usługi (SvcTraceViewer.exe) przy użyciu System.Diagnostics.XmlWriterTraceListener jako odbiornika śledzenia. Nie jest to coś, co musisz zrobić jako deweloper kanału. Zamiast tego jest to użytkownik aplikacji (lub osoba, która rozwiązuje problemy z aplikacją), który musi skonfigurować ten odbiornik śledzenia w pliku konfiguracji aplikacji. Na przykład następująca konfiguracja generuje informacje o śledzeniu zarówno z pliku , jak System.ServiceModel i Microsoft.Samples.Udp do pliku o nazwie TraceEventsFile.e2e:
<configuration>
<system.diagnostics>
<sources>
<!-- configure System.ServiceModel trace source -->
<source name="System.ServiceModel" switchValue="Verbose"
propagateActivity="true">
<listeners>
<add name="e2e" />
</listeners>
</source>
<!-- configure Microsoft.Samples.Udp trace source -->
<source name="Microsoft.Samples.Udp" switchValue="Verbose" >
<listeners>
<add name="e2e" />
</listeners>
</source>
</sources>
<!--
Define a shared trace listener that outputs to TraceFile.e2e
The listener name is e2e
-->
<sharedListeners>
<add name="e2e" type="System.Diagnostics.XmlWriterTraceListener"
initializeData=".\TraceFile.e2e"/>
</sharedListeners>
<trace autoflush="true" />
</system.diagnostics>
</configuration>
Śledzenie danych strukturalnych
System.Diagnostics.TraceSource ma metodę TraceData , która przyjmuje co najmniej jeden obiekt, który ma zostać uwzględniony we wpisie śledzenia. Ogólnie rzecz biorąc, Object.ToString metoda jest wywoływana dla każdego obiektu, a wynikowy ciąg jest zapisywany jako część wpisu śledzenia. W przypadku użycia System.Diagnostics.XmlWriterTraceListener funkcji do śledzenia danych wyjściowych można przekazać obiekt System.Xml.XPath.IXPathNavigable jako obiekt danych do TraceDataobiektu . Wynikowy wpis śledzenia zawiera kod XML dostarczony przez System.Xml.XPath.XPathNavigatorelement . Oto przykładowy wpis z danymi aplikacji XML:
<E2ETraceEvent xmlns="http://schemas.microsoft.com/2004/06/E2ETraceEvent">
<System xmlns="...">
<EventID>12</EventID>
<Type>3</Type>
<SubType Name="Information">0</SubType>
<Level>8</Level>
<TimeCreated SystemTime="2006-01-13T22:58:03.0654832Z" />
<Source Name="Microsoft.ServiceModel.Samples.Udp" />
<Correlation ActivityID="{00000000-0000-0000-0000-000000000000}" />
<Execution ProcessName="UdpTestConsole"
ProcessID="3348" ThreadID="4" />
<Channel />
<Computer>COMPUTER-LT01</Computer>
</System>
<!-- XML application data -->
<ApplicationData>
<TraceData>
<DataItem>
<TraceRecord
Severity="Information"
xmlns="…">
<TraceIdentifier>some trace id</TraceIdentifier>
<Description>EndReceive called</Description>
<AppDomain>UdpTestConsole.exe</AppDomain>
<Source>UdpInputChannel</Source>
</TraceRecord>
</DataItem>
</TraceData>
</ApplicationData>
</E2ETraceEvent>
Przeglądarka śledzenia WCF rozumie schemat TraceRecord pokazanego wcześniej elementu i wyodrębnia dane z jego elementów podrzędnych i wyświetla je w formacie tabelarycznym. Kanał powinien używać tego schematu podczas śledzenia danych aplikacji ustrukturyzowanych, aby ułatwić Svctraceviewer.exe użytkownikom odczytywanie danych.