Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
ML.NET Model Builder to intuicyjne graficzne rozszerzenie programu Visual Studio do tworzenia, trenowania i wdrażania niestandardowych modeli uczenia maszynowego. Używa zautomatyzowanego uczenia maszynowego (AutoML) do eksplorowania różnych algorytmów i ustawień uczenia maszynowego, aby ułatwić znalezienie tego, który najlepiej pasuje do danego scenariusza.
Do korzystania z narzędzia Model Builder nie potrzebujesz specjalistycznej wiedzy dotyczącej uczenia maszynowego. Wszystko, czego potrzebujesz, to niektóre dane i problem do rozwiązania. Narzędzie Model Builder generuje kod, aby dodać model do aplikacji platformy .NET.

Tworzenie projektu konstruktora modelu
Po pierwszym uruchomieniu narzędzia Model Builder zostanie wyświetlony monit o nadenie projektu nazwy, a następnie utworzenie mbconfig pliku konfiguracji wewnątrz projektu. Plik mbconfig śledzi wszystko, co robisz w narzędziu Model Builder, aby umożliwić ponowne otwarcie sesji.
Po trenowaniu trzy pliki są generowane w pliku *.mbconfig:
- Model.consumption.cs: ten plik zawiera
ModelInputschematy i orazModelOutputPredictfunkcję wygenerowaną do korzystania z modelu. - Model.training.cs: ten plik zawiera potok trenowania (przekształcenia danych, algorytm, hiperparametry algorytmu) wybrany przez konstruktora modeli do trenowania modelu. Tego potoku można użyć do ponownego trenowania modelu.
- Model.zip: jest to serializowany plik zip reprezentujący wytrenowany model ML.NET.
Podczas tworzenia mbconfig pliku zostanie wyświetlony monit o podanie nazwy. Ta nazwa jest stosowana do plików zużycia, trenowania i modelu. W tym przypadku używana nazwa to Model.
Scenariusz
Możesz przenieść wiele różnych scenariuszy do narzędzia Model Builder, aby wygenerować model uczenia maszynowego dla aplikacji.
Scenariusz to opis typu przewidywania, który chcesz utworzyć przy użyciu danych. Na przykład:
- Przewidywanie przyszłej wielkości sprzedaży produktów na podstawie historycznych danych sprzedaży.
- Klasyfikowanie tonacji jako pozytywnych lub negatywnych na podstawie recenzji klientów.
- Wykryj, czy transakcja bankowa jest fałszywa.
- Kierowanie problemów z opiniami klientów do właściwego zespołu w firmie.
Każdy scenariusz jest mapowy na inne zadanie uczenia maszynowego, w tym:
| Zadanie | Scenariusz |
|---|---|
| Klasyfikacja binarna | Klasyfikacja danych |
| Klasyfikacja wieloklasowa | Klasyfikacja danych |
| Klasyfikacja obrazów | Klasyfikacja obrazów |
| Klasyfikacja tekstu | Klasyfikacja tekstu |
| Regresja | Przewidywanie wartości |
| Zalecenie | Zalecenie |
| Prognozowanie | Prognozowanie |
Na przykład scenariusz klasyfikowania tonacji jako pozytywnych lub negatywnych będzie należeć do zadania klasyfikacji binarnej.
Aby uzyskać więcej informacji na temat różnych zadań uczenia maszynowego obsługiwanych przez ML.NET, zobacz Zadania uczenia maszynowego w ML.NET.
Który scenariusz uczenia maszynowego jest odpowiedni dla mnie?
W narzędziu Model Builder należy wybrać scenariusz. Typ scenariusza zależy od typu przewidywania, który próbujesz wykonać.
Tabelaryczny
Klasyfikacja danych
Klasyfikacja służy do kategoryzowania danych w kategoriach.
Przykładowe dane wejściowe
Przykładowe dane wyjściowe
| SepalLength | SepalWidth | Długość płatka | Szerokość płatka | Gatunki |
|---|---|---|---|---|
| 5,1 | 3.5 | 1.4 | 0,2 | setosa |
| Przewidywane gatunki |
|---|
| setosa |
Przewidywanie wartości
Przewidywanie wartości, które należy do zadania regresji, służy do przewidywania liczb.
Przykładowe dane wejściowe
Przykładowe dane wyjściowe
| vendor_id | rate_code | passenger_count | trip_time_in_secs | trip_distance | payment_type | fare_amount |
|---|---|---|---|---|---|---|
| CMT | 1 | 1 | 1271 | 3,8 | CRD | 17.5 |
| Przewidywana taryfa |
|---|
| 4.5 |
Zalecenie
Scenariusz rekomendacji przewiduje listę sugerowanych elementów dla określonego użytkownika, na podstawie tego, jak podobne są ich polubienia i niechęci do innych użytkowników".
Możesz użyć scenariusza rekomendacji, gdy masz zestaw użytkowników i zestaw "produktów", takich jak elementy do zakupu, filmów, książek lub programów telewizyjnych, wraz z zestawem "klasyfikacji" tych produktów użytkowników.
Przykładowe dane wejściowe
Przykładowe dane wyjściowe
| Identyfikator użytkownika | Identyfikator produktu | Rating |
|---|---|---|
| 1 | 2 | 4.2 |
| Przewidywana ocena |
|---|
| 4.5 |
Prognozowanie
Scenariusz prognozowania używa danych historycznych z szeregami czasowymi lub składnikami sezonowymi.
Scenariusz prognozowania umożliwia prognozowanie zapotrzebowania lub sprzedaży produktu.
Przykładowe dane wejściowe
Przykładowe dane wyjściowe
| Data | SaleQty |
|---|---|
| 1/1/1970 | 1000 |
| Prognoza 3-dniowa |
|---|
| [1000,1001,1002] |
Przetwarzanie obrazów
Klasyfikacja obrazów
Klasyfikacja obrazów służy do identyfikowania obrazów różnych kategorii. Na przykład różne rodzaje terenu lub zwierząt lub wad produkcyjnych.
Możesz użyć scenariusza klasyfikacji obrazów, jeśli masz zestaw obrazów i chcesz sklasyfikować obrazy w różnych kategoriach.
Przykładowe dane wejściowe
Przykładowe dane wyjściowe

| Prognozowana etykieta |
|---|
| Pies |
Wykrywanie obiektów
Wykrywanie obiektów służy do lokalizowania i kategoryzowania jednostek na obrazach. Na przykład lokalizowanie i identyfikowanie samochodów i osób na obrazie.
Wykrywanie obiektów można użyć, gdy obrazy zawierają wiele obiektów różnych typów.
Przykładowe dane wejściowe
Przykładowe dane wyjściowe

Przetwarzanie języka naturalnego
Klasyfikacja tekstu
Klasyfikacja tekstu kategoryzuje nieprzetworzone wprowadzanie tekstu.
Możesz użyć scenariusza klasyfikacji tekstu, jeśli masz zestaw dokumentów lub komentarzy i chcesz je sklasyfikować w różnych kategoriach.
Przykładowe dane wejściowe
Przykładowe dane wyjściowe
| Wykonaj przegląd |
|---|
| Naprawdę lubię ten stek! |
| Opinia |
|---|
| Pozytywne |
Środowisko
Model uczenia maszynowego można trenować lokalnie na maszynie lub w chmurze na platformie Azure, w zależności od scenariusza.
Podczas trenowania lokalnego pracujesz w ramach ograniczeń zasobów komputera (procesora CPU, pamięci i dysku). Podczas trenowania w chmurze możesz skalować zasoby w górę, aby spełnić wymagania scenariusza, szczególnie w przypadku dużych zestawów danych.
| Scenariusz | Procesor lokalny | Lokalny procesor GPU | Azure |
|---|---|---|---|
| Klasyfikacja danych | ✔️ | ❌ | ❌ |
| Przewidywanie wartości | ✔️ | ❌ | ❌ |
| Zalecenie | ✔️ | ❌ | ❌ |
| Prognozowanie | ✔️ | ❌ | ❌ |
| Klasyfikacja obrazów | ✔️ | ✔️ | ✔️ |
| Wykrywanie obiektów | ❌ | ❌ | ✔️ |
| Klasyfikacja tekstu | ✔️ | ✔️ | ❌ |
Data
Po wybraniu scenariusza narzędzie Model Builder prosi o podanie zestawu danych. Dane są używane do trenowania, oceniania i wybierania najlepszego modelu dla danego scenariusza.
Narzędzie Model Builder obsługuje zestawy danych w formatach .tsv, .csv, .txt i SQL Database. Jeśli masz plik .txt, kolumny powinny być oddzielone wartościami ,, ;lub \t.
Jeśli zestaw danych składa się z obrazów, obsługiwane typy plików to .jpg i .png.
Aby uzyskać więcej informacji, zobacz Ładowanie danych szkoleniowych do narzędzia Model Builder.
Wybieranie danych wyjściowych do przewidywania (etykieta)
Zestaw danych to tabela wierszy przykładów trenowania i kolumn atrybutów. Każdy wiersz ma:
- etykieta (atrybut, który chcesz przewidzieć)
- funkcje (atrybuty używane jako dane wejściowe do przewidywania etykiety)
W scenariuszu przewidywania cen domu funkcje mogą być następujące:
- Kwadratowy materiał z domu.
- Liczba sypialni i łazienek.
- Kod pocztowy.
Etykieta jest historyczną ceną domu dla tego wiersza materiału kwadratowego, sypialni i wartości łazienki i kodu pocztowego.
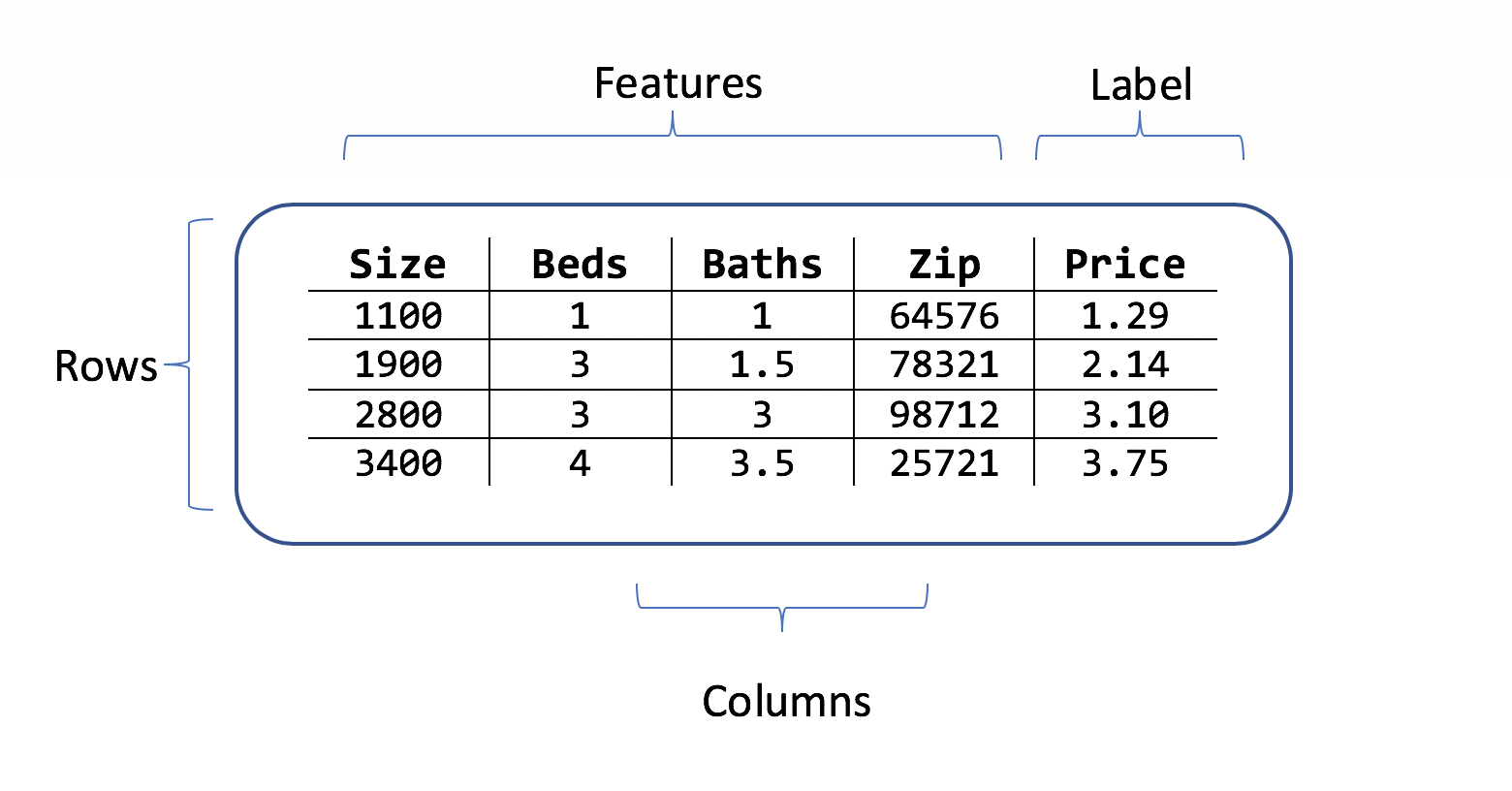
Przykładowe zestawy danych
Jeśli nie masz jeszcze własnych danych, wypróbuj jeden z następujących zestawów danych:
| Scenariusz | Przykład | Data | Etykieta | Funkcje |
|---|---|---|---|---|
| Klasyfikacja | Przewidywanie anomalii sprzedaży | dane sprzedaży produktów | Sprzedaż produktu | Month |
| Przewidywanie tonacji komentarzy w witrynie internetowej | dane komentarzy w witrynie sieci Web | Etykieta (1, gdy negatywna tonacja, 0, gdy dodatnia) | Komentarz, Rok | |
| Przewidywanie fałszywych transakcji kart kredytowych | dane karty kredytowej | Klasa (1, gdy fałszywe, 0 w przeciwnym razie) | Amount, V1-V28 (funkcje anonimowe) | |
| Przewidywanie typu problemu w repozytorium GitHub | Dane dotyczące problemów z usługą GitHub | Obszar | Tytuł, opis | |
| Przewidywanie wartości | Przewidywanie ceny taryf taksówek | dane taryfy taksówek | Taryfy | Czas podróży, odległość |
| Klasyfikacja obrazów | Przewidywanie kategorii kwiatu | obrazy kwiatów | Rodzaj kwiatu: daisy, mniszek, róże, słoneczniki, tulipany | Same dane obrazu |
| Zalecenie | Przewidywanie filmów, które ktoś polubi | oceny filmów | Użytkownicy, filmy | Oceny |
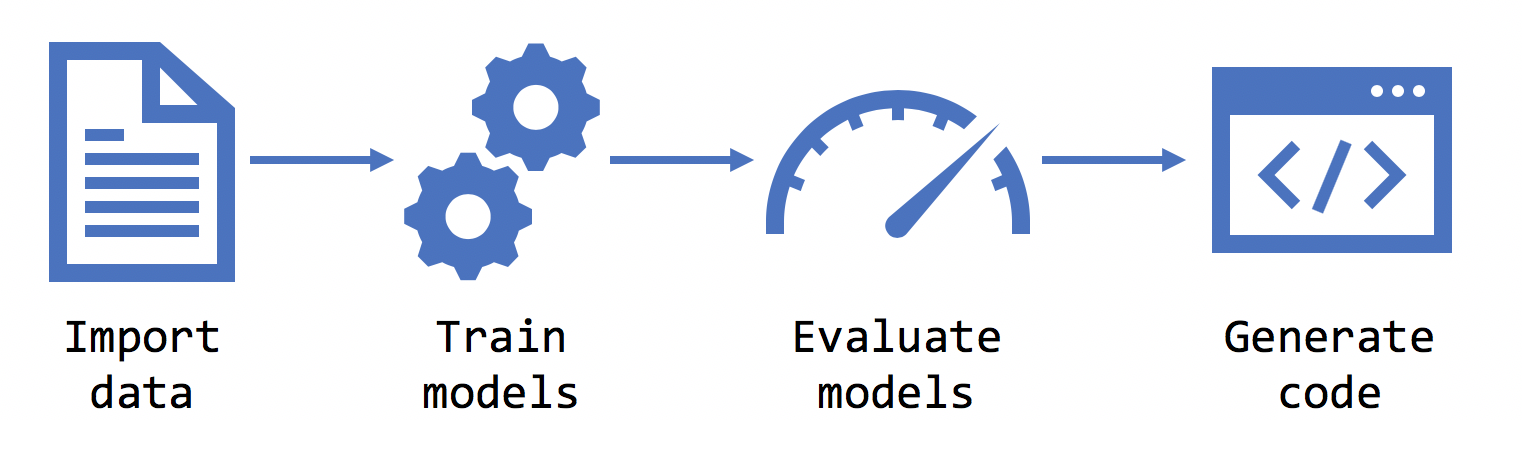
Szkolenie
Po wybraniu scenariusza, środowiska, danych i etykiety konstruktor modelu trenuje model.
Co to jest szkolenie?
Trenowanie to proces automatyczny, za pomocą którego narzędzie Model Builder uczy modelu, jak odpowiadać na pytania dotyczące danego scenariusza. Po wytrenowanym modelu można przewidywać dane wejściowe, których wcześniej nie widział. Jeśli na przykład przewidujesz ceny domów i na rynku pojawi się nowy dom, możesz przewidzieć jego cenę sprzedaży.
Ponieważ narzędzie Model Builder używa zautomatyzowanego uczenia maszynowego (AutoML), nie wymaga żadnych danych wejściowych ani dostrajania podczas trenowania.
Jak długo należy trenować?
Narzędzie Model Builder używa rozwiązania AutoML do eksplorowania wielu modeli w celu znalezienia najlepszego modelu.
Dłuższe okresy trenowania umożliwiają automl eksplorowanie większej liczby modeli z szerszym zakresem ustawień.
Poniższa tabela zawiera podsumowanie średniego czasu potrzebnego na uzyskanie dobrej wydajności dla zestawu przykładowych zestawów danych na komputerze lokalnym.
| Rozmiar zestawu danych | Średni czas trenowania |
|---|---|
| 0 – 10 MB | 10 s |
| 10– 100 MB | 10 minut |
| 100–500 MB | 30 min |
| 500– 1 GB | 60 min |
| 1 GB+ | 3+ godziny |
Te liczby są tylko przewodnikiem. Dokładna długość szkolenia zależy od:
- Liczba funkcji (kolumn) używanych jako dane wejściowe do modelu.
- Typ kolumn.
- Zadanie uczenia maszynowego.
- Wydajność procesora CPU, dysku i pamięci maszyny używanej do trenowania.
Zazwyczaj zaleca się użycie więcej niż 100 wierszy jako zestawów danych z mniejszą mniejszą ilością niż te, które mogą nie generować żadnych wyników.
Evaluate
Ocena to proces mierzenia, jak dobry jest model. Narzędzie Model Builder używa wytrenowanego modelu do przewidywania z nowymi danymi testowymi, a następnie mierzy, jak dobre są przewidywania.
Konstruktor modelu dzieli dane treningowe na zestaw treningowy i zestaw testowy. Dane szkoleniowe (80%) są używane do trenowania modelu, a dane testowe (20%) są wstrzymane w celu oceny modelu.
Jak mogę zrozumieć wydajność modelu?
Scenariusz jest mapowy na zadanie uczenia maszynowego. Każde zadanie uczenia maszynowego ma własny zestaw metryk oceny.
Przewidywanie wartości
Domyślna metryka problemów z przewidywaniem wartości to RSquared, wartość zakresów RSquared z zakresu od 0 do 1. 1 jest najlepszą możliwą wartością lub innymi słowy bliżej wartości RSquared do 1, tym lepiej działa model.
Inne metryki zgłaszane, takie jak utrata bezwzględna, utrata kwadratowa i utrata usługi RMS, to dodatkowe metryki, których można użyć do zrozumienia, jak działa model i porównać go z innymi modelami przewidywania wartości.
Klasyfikacja (2 kategorie)
Domyślna metryka problemów klasyfikacji to dokładność. Dokładność definiuje proporcję prawidłowych przewidywań, które model wykonuje w przypadku zestawu danych testowych. Im bliżej 100% lub 1,0, tym lepiej jest.
Inne metryki zgłaszane, takie jak AUC (Obszar pod krzywą), które mierzy rzeczywistą dodatnią stopę, a współczynnik wyników fałszywie dodatnich powinien być większy niż 0,50, aby modele byłyby akceptowalne.
Dodatkowe metryki, takie jak wynik F1, mogą służyć do kontrolowania równowagi między precyzją i kompletnością.
Klasyfikacja (3+ kategorie)
Domyślna metryka klasyfikacji wieloklasowej to Micro Accuracy. Im większa dokładność mikro do 100% lub 1,0, tym lepiej jest.
Kolejną ważną metryczką klasyfikacji wieloklasowej jest dokładność makr, podobnie jak w przypadku mikro-dokładności bliżej 1,0, tym lepiej jest. Dobrym sposobem myślenia o tych dwóch typach dokładności jest:
- Micro-accuracy: Jak często bilet przychodzący jest klasyfikowany do odpowiedniego zespołu?
- Dokładność makr: W przypadku przeciętnego zespołu, jak często bilet przychodzący jest poprawny dla swojego zespołu?
Więcej informacji na temat metryk oceny
Aby uzyskać więcej informacji, zobacz Metryki oceny modelu.
Poprawianie
Jeśli wynik wydajności modelu nie jest tak dobry, jak chcesz, możesz:
Trenowanie przez dłuższy czas. Dzięki większemu czasowi zautomatyzowane aparat uczenia maszynowego eksperymentuje z większą ilością algorytmów i ustawień.
Dodaj więcej danych. Czasami ilość danych nie wystarczy do wytrenowania wysokiej jakości modelu uczenia maszynowego. Dotyczy to szczególnie zestawów danych, które mają niewielką liczbę przykładów.
Zrównoważ dane. W przypadku zadań klasyfikacji upewnij się, że zestaw trenowania jest zrównoważony w różnych kategoriach. Jeśli na przykład masz cztery klasy dla 100 przykładów szkoleniowych, a dwie pierwsze klasy (tag1 i tag2) są używane dla 90 rekordów, ale pozostałe dwie (tag3 i tag4) są używane tylko na pozostałych 10 rekordach, brak zrównoważonych danych może spowodować, że model będzie miał trudności z prawidłowym przewidywaniem tag3 lub tag4.
Zużyj
Po fazie oceny narzędzie Model Builder generuje plik modelu i kod, którego można użyć do dodania modelu do aplikacji. ML.NET modele są zapisywane jako plik zip. Kod do załadowania i użycia modelu jest dodawany jako nowy projekt w rozwiązaniu. Konstruktor modelu dodaje również przykładową aplikację konsolową, którą można uruchomić, aby zobaczyć model w działaniu.
Ponadto narzędzie Model Builder umożliwia tworzenie projektów korzystających z modelu. Obecnie narzędzie Model Builder utworzy następujące projekty:
- Aplikacja konsolowa: tworzy aplikację konsolową platformy .NET w celu przewidywania na podstawie modelu.
- Internetowy interfejs API: tworzy internetowy interfejs API platformy ASP.NET Core, który umożliwia korzystanie z modelu przez Internet.
Co dalej?
Zainstaluj rozszerzenie programu Visual Studio w programie Model Builder.
Wypróbuj przewidywanie cen lub dowolny scenariusz regresji.
Współpracuj z nami w serwisie GitHub
Źródło tej zawartości można znaleźć w witrynie GitHub, gdzie można również tworzyć i przeglądać problemy i żądania ściągnięcia. Więcej informacji znajdziesz w naszym przewodniku dla współtwórców.