Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Dowiedz się, jak wytrenować niestandardowy model uczenia głębokiego przy użyciu uczenia transferowego, wstępnie wytrenowanego modelu TensorFlow oraz interfejsu API klasyfikacji obrazów ML.NET do klasyfikowania obrazów konkretnych powierzchni jako pękniętych lub niezakłęconych.
W tym poradniku nauczysz się, jak:
- Omówienie problemu
- Poznaj interfejs API klasyfikacji obrazów ML.NET
- Omówienie wstępnie wytrenowanego modelu
- Trenowanie niestandardowego modelu klasyfikacji obrazów TensorFlow przy użyciu uczenia transferowego
- Klasyfikowanie obrazów przy użyciu modelu niestandardowego
Wymagania wstępne
Omówienie problemu
Klasyfikacja obrazów to problem z przetwarzaniem obrazów. Klasyfikacja obrazów przyjmuje obraz jako dane wejściowe i kategoryzuje go w określonej klasie. Modele klasyfikacji obrazów są często trenowane przy użyciu uczenia głębokiego i sieci neuronowych. Aby uzyskać więcej informacji, zobacz Uczenie głębokie a uczenie maszynowe.
Oto niektóre scenariusze, w których klasyfikacja obrazów jest przydatna:
- Rozpoznawanie twarzy
- Wykrywanie emocji
- Diagnostyka medyczna
- Wykrywanie punktów orientacyjnych
Ten poradnik szkoli niestandardowy model klasyfikacji obrazów do wykonywania automatycznej inspekcji wizualnej płyt mostów w celu identyfikacji struktur uszkodzonych przez pęknięcia.
API klasyfikacji obrazów ML.NET
ML.NET zapewnia różne sposoby klasyfikacji obrazów. Ten samouczek dotyczy uczenia transferowego przy użyciu interfejsu API klasyfikacji obrazów. Interfejs API klasyfikacji obrazów korzysta z TensorFlow.NET, biblioteki niskiego poziomu, która udostępnia powiązania języka C# dla interfejsu API Języka C++ platformy TensorFlow.
Co to jest uczenie transferowe?
Uczenie transferowe stosuje wiedzę zdobytą na podstawie rozwiązywania jednego problemu do innego powiązanego problemu.
Trenowanie modelu uczenia głębokiego od podstaw wymaga ustawienia kilku parametrów, dużej ilości danych treningowych oznaczonych etykietami i ogromnej ilości zasobów obliczeniowych (setki godzin procesora GPU). Używanie wstępnie wytrenowanego modelu wraz z uczeniem transferowym umożliwia skrót do procesu trenowania.
Proces trenowania
API klasyfikacji obrazów uruchamia proces treningu przez wczytanie wstępnie wytrenowanego modelu TensorFlow. Proces trenowania składa się z dwóch kroków:
- Faza wąskiego gardła.
- Faza trenowania.
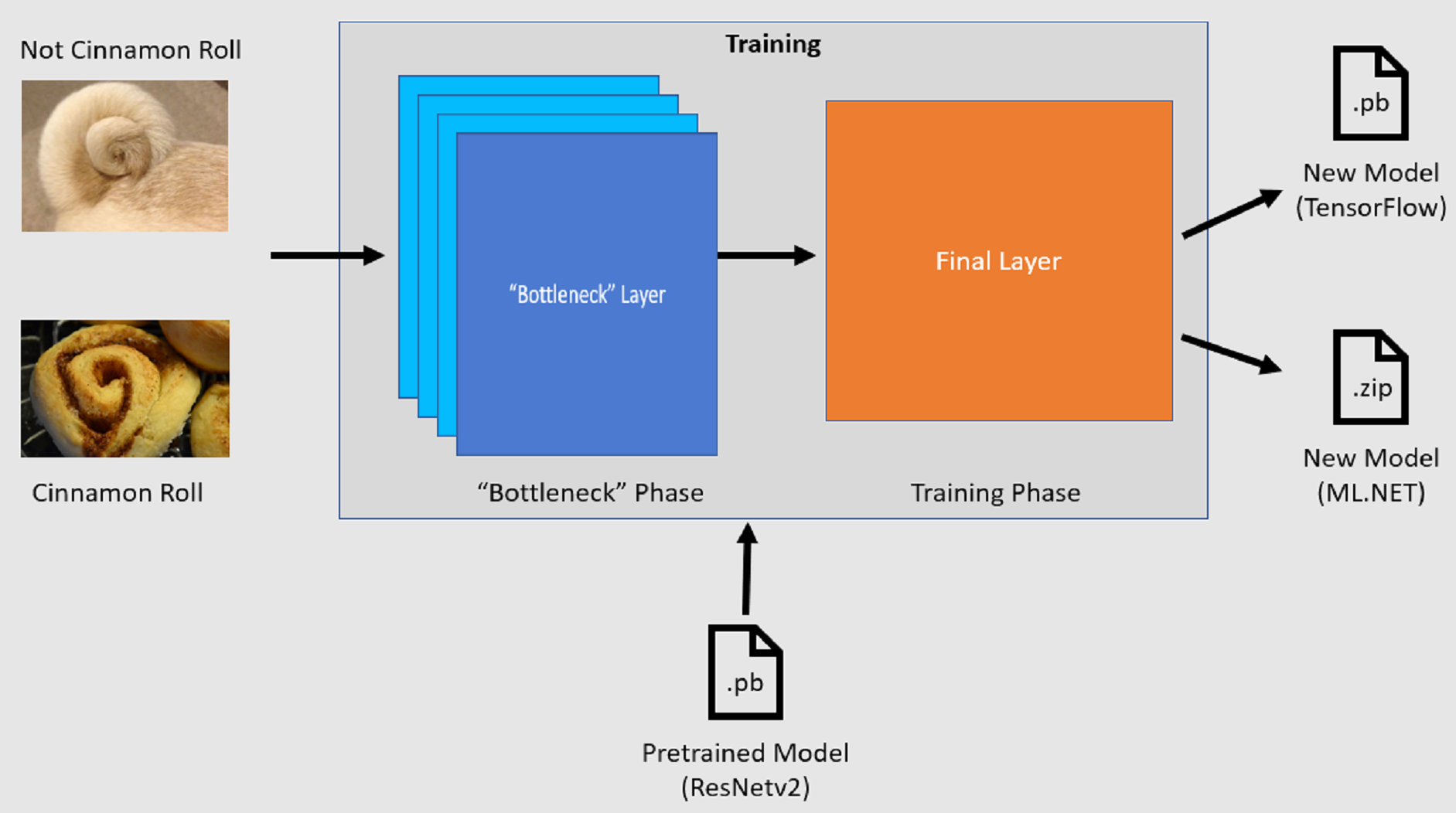
Faza wąskiego gardła
W fazie wąskiego gardła zestaw obrazów treningowych jest ładowany, a wartości pikseli są używane jako dane wejściowe lub funkcje dla zamrożonych warstw wstępnie wytrenowanego modelu. Warstwy zamrożone obejmują wszystkie warstwy w sieci neuronowej do przedostatniej warstwy, nieformalnie znanej jako warstwa wąskiego gardła. Te warstwy są określane jako zamrożone, ponieważ na tych warstwach nie będzie wykonywane trenowanie, a operacje są przekazywane. W tych warstwach zamrożonych są obliczane wzorce niższego poziomu, które pomagają modelowi rozróżniać różne klasy. Większa liczba warstw, tym bardziej intensywnie obciąża ten krok. Na szczęście, ponieważ jest to jednorazowe obliczenie, wyniki można buforować i używać w kolejnych uruchomieniach podczas eksperymentowania z różnymi parametrami.
Faza trenowania
Po obliczeniu wartości wyjściowych z etapu wąskiego gardła są one używane jako dane wejściowe do ponownego trenowania końcowej warstwy modelu. Ten proces jest iteracyjny i uruchamiany dla liczby razy określonych przez parametry modelu. Podczas każdego przebiegu są oceniane straty i dokładność. Następnie należy wprowadzić odpowiednie korekty w celu poprawy modelu w celu zminimalizowania utraty i maksymalizacji dokładności. Po zakończeniu trenowania dwa formaty modelu są danymi wyjściowymi. Jedną z nich jest .pb wersja modelu, a druga to .zip ML.NET serializowana wersja modelu. Podczas pracy w środowiskach obsługiwanych przez ML.NET zaleca się użycie .zip wersji modelu. Jednak w środowiskach, w których ML.NET nie jest obsługiwana, masz możliwość korzystania z .pb wersji.
Omówienie wstępnie wytrenowanego modelu
Wstępnie wytrenowany model używany w tym samouczku to wariant 101-warstwowy modelu Sieć Resztkowa (ResNet) w wersji v2. Oryginalny model jest trenowany do klasyfikowania obrazów w tysiącach kategorii. Model przyjmuje jako dane wejściowe obraz o rozmiarze 224 x 224 i generuje prawdopodobieństwa klas dla każdej z klas, na których był trenowany. Część tego modelu służy do trenowania nowego modelu przy użyciu obrazów niestandardowych w celu przewidywania między dwiema klasami.
Tworzenie aplikacji konsolowej
Teraz, gdy masz ogólną wiedzę na temat uczenia transferowego i interfejsu API klasyfikacji obrazów, nadszedł czas na skompilowanie aplikacji.
Utwórz aplikację konsolową języka C# o nazwie "DeepLearning_ImageClassification_Binary". Kliknij przycisk Next (Dalej).
Wybierz platformę .NET 8 jako platformę do użycia, a następnie wybierz pozycję Utwórz.
Zainstaluj pakiet NuGet Microsoft.ML :
Uwaga / Notatka
W tym przykładzie użyto najnowszej stabilnej wersji pakietów NuGet wymienionych, chyba że określono inaczej.
- W Eksploratorze rozwiązań kliknij prawym przyciskiem myszy projekt i wybierz polecenie Zarządzaj pakietami NuGet.
- Wybierz pozycję "nuget.org" jako źródło pakietu.
- Wybierz kartę Przeglądaj.
- Zaznacz pole wyboru Uwzględnij wersję wstępną .
- Wyszukaj Microsoft.ML.
- Wybierz przycisk Zainstaluj.
- Wybierz przycisk Akceptuję w oknie dialogowym Akceptacja licencji , jeśli zgadzasz się z postanowieniami licencyjnymi dla pakietów wymienionych.
- Powtórz te kroki dla pakietów NuGet Microsoft.ML.Vision, SciSharp.TensorFlow.Redist (wersja 2.3.1) i Microsoft.ML.ImageAnalytics .
Przygotowywanie i zrozumienie danych
Uwaga / Notatka
Zestawy danych do tego samouczka pochodzą od Maguire'a, Marca; Dorafshana, Sattara; i Thomasa, Roberta J., "SDNET2018: zbiór zdjęć pęknięć betonu do zastosowań w uczeniu maszynowym" (2018). Przeglądaj wszystkie zestawy danych. Papier 48. https://digitalcommons.usu.edu/all_datasets/48
SDNET2018 to zestaw danych obrazu zawierający adnotacje dla pękniętych i niełamanych konstrukcji (pomosty, ściany i chodniki).

Dane są zorganizowane w trzech podkatalogach:
- D zawiera obrazy pomostu
- P zawiera obrazy chodników
- W zawiera obrazy ściany
Każdy z tych podkatalogów zawiera dwa dodatkowe podkatalogi z prefiksem:
- C jest prefiksem używanym do pękniętych powierzchni
- U jest prefiksem używanym do powierzchni bez szczeliny
W tym samouczku są używane tylko obrazy mostowych pokładów.
- Pobierz zestaw danych i rozpakuj.
- Utwórz katalog o nazwie "Zasoby" w projekcie, aby zapisać pliki zestawu danych.
- Skopiuj podkatalogi CD i UD z ostatnio rozpakowanego katalogu do katalogu Assets .
Tworzenie klas wejściowych i wyjściowych
Otwórz plik Program.cs i zastąp istniejącą zawartość następującymi
usingdyrektywami:using Microsoft.ML; using Microsoft.ML.Vision; using static Microsoft.ML.DataOperationsCatalog;Utwórz klasę o nazwie
ImageData. Ta klasa służy do reprezentowania początkowo załadowanych danych.class ImageData { public string? ImagePath { get; set; } public string? Label { get; set; } }ImageDatazawiera następujące właściwości:-
ImagePathto w pełni kwalifikowana ścieżka, w której jest przechowywany obraz. -
Labelto kategoria, do którego należy obraz. Jest to wartość do przewidzenia.
-
Utwórz klasy dla danych wejściowych i wyjściowych.
ImageDataPoniżej klasy zdefiniuj schemat danych wejściowych w nowej klasie o nazwieModelInput.class ModelInput { public byte[]? Image { get; set; } public uint LabelAsKey { get; set; } public string? ImagePath { get; set; } public string? Label { get; set; } }ModelInputzawiera następujące właściwości:-
Imageto reprezentacjabyte[]obrazu. Model oczekuje, że dane obrazu będą tego typu przeznaczone do trenowania. -
LabelAsKeyto liczbowa reprezentacja elementuLabel. -
ImagePathto w pełni kwalifikowana ścieżka, w której jest przechowywany obraz. -
Labelto kategoria, do którego należy obraz. Jest to wartość do przewidzenia.
Tylko
ImageiLabelAsKeysą używane do trenowania modelu i tworzenia przewidywań. WłaściwościImagePathiLabelsą przechowywane dla wygody w celu uzyskania dostępu do oryginalnej nazwy pliku obrazu i kategorii.-
Następnie poniżej
ModelInputklasy zdefiniuj schemat danych wyjściowych w nowej klasie o nazwieModelOutput.class ModelOutput { public string? ImagePath { get; set; } public string? Label { get; set; } public string? PredictedLabel { get; set; } }ModelOutputzawiera następujące właściwości:-
ImagePathto w pełni kwalifikowana ścieżka, w której jest przechowywany obraz. -
Labelto oryginalna kategoria, do którego należy obraz. Jest to wartość do przewidzenia. -
PredictedLabeljest wartością przewidywaną przez model.
Podobnie jak
ModelInputw przypadku elementu ,PredictedLabelwymagane jest tylko przewidywanie, ponieważ zawiera on przewidywanie dokonane przez model. WłaściwościImagePathiLabelsą zachowywane dla wygody w celu uzyskania dostępu do oryginalnej nazwy pliku obrazu i kategorii.-
Definiowanie ścieżek i inicjowanie zmiennych
usingW ramach dyrektyw dodaj następujący kod do:Zdefiniuj lokalizację zasobów.
Zainicjuj
mlContextzmienną przy użyciu nowego wystąpienia metody MLContext.Klasa MLContext jest punktem wyjścia dla wszystkich operacji ML.NET, a inicjowanie metody mlContext tworzy nowe środowisko ML.NET, które może być współużytkowane przez obiekty przepływu pracy tworzenia modelu. Jest ona podobna, koncepcyjnie, do
DbContextw programie Entity Framework.
var projectDirectory = Path.GetFullPath(Path.Combine(AppContext.BaseDirectory, "../../../")); var assetsRelativePath = Path.Combine(projectDirectory, "Assets"); MLContext mlContext = new();
Ładowanie danych
Tworzenie metody narzędzia do ładowania danych
Obrazy są przechowywane w dwóch podkatalogach. Przed załadowaniem danych należy je sformatować na listę ImageData obiektów. W tym celu utwórz metodę LoadImagesFromDirectory :
static IEnumerable<ImageData> LoadImagesFromDirectory(string folder, bool useFolderNameAsLabel = true)
{
var files = Directory.GetFiles(folder, "*",
searchOption: SearchOption.AllDirectories);
foreach (var file in files)
{
if ((Path.GetExtension(file) != ".jpg") && (Path.GetExtension(file) != ".png"))
continue;
var label = Path.GetFileName(file);
if (useFolderNameAsLabel)
label = Directory.GetParent(file)?.Name;
else
{
for (int index = 0; index < label.Length; index++)
{
if (!char.IsLetter(label[index]))
{
label = label[..index];
break;
}
}
}
yield return new ImageData()
{
ImagePath = file,
Label = label
};
}
}
Metoda LoadImagesFromDirectory:
- Pobiera wszystkie ścieżki plików z podkatalogów.
- Wykonuje iterację po każdym z plików przy użyciu
foreachinstrukcji i sprawdza, czy rozszerzenia plików są obsługiwane. Interfejs API klasyfikacji obrazów obsługuje formaty JPEG i PNG. - Pobiera etykietę dla pliku.
useFolderNameAsLabelJeśli parametr jest ustawiony natruewartość , jako etykietę jest używany katalog nadrzędny, w którym jest zapisywany plik. W przeciwnym razie oczekuje, że etykieta będzie prefiksem nazwy pliku lub samej nazwy pliku. - Tworzy nowe wystąpienie klasy
ModelInput.
Przygotowywanie danych
Dodaj następujący kod po wierszu, w którym utworzysz nowe wystąpienie klasy MLContext.
IEnumerable<ImageData> images = LoadImagesFromDirectory(folder: assetsRelativePath, useFolderNameAsLabel: true);
IDataView imageData = mlContext.Data.LoadFromEnumerable(images);
IDataView shuffledData = mlContext.Data.ShuffleRows(imageData);
var preprocessingPipeline = mlContext.Transforms.Conversion.MapValueToKey(
inputColumnName: "Label",
outputColumnName: "LabelAsKey")
.Append(mlContext.Transforms.LoadRawImageBytes(
outputColumnName: "Image",
imageFolder: assetsRelativePath,
inputColumnName: "ImagePath"));
IDataView preProcessedData = preprocessingPipeline
.Fit(shuffledData)
.Transform(shuffledData);
TrainTestData trainSplit = mlContext.Data.TrainTestSplit(data: preProcessedData, testFraction: 0.3);
TrainTestData validationTestSplit = mlContext.Data.TrainTestSplit(trainSplit.TestSet);
IDataView trainSet = trainSplit.TrainSet;
IDataView validationSet = validationTestSplit.TrainSet;
IDataView testSet = validationTestSplit.TestSet;
Poprzedni kod:
Wywołuje metodę
LoadImagesFromDirectorynarzędzia w celu uzyskania listy obrazów używanych do trenowania po zainicjowaniu zmiennejmlContext.Ładuje obrazy do
IDataViewmetody przy użyciuLoadFromEnumerablemetody .Tasuje dane przy użyciu
ShuffleRowsmetody . Dane są ładowane w kolejności odczytywania z katalogów. Tasu jest wykonywana w celu zrównoważenia go.Wykonuje wstępne przetwarzanie danych przed rozpoczęciem trenowania. Dzieje się tak, ponieważ modele uczenia maszynowego oczekują, że dane wejściowe będą w formacie liczbowym. Kod przetwarzania wstępnego tworzy obiekt
EstimatorChainskładający się zMapValueToKeytransformacji iLoadRawImageBytes. PrzekształcenieMapValueToKeyprzyjmuje wartość kategorii wLabelkolumnie, konwertuje ją na wartość liczbowąKeyTypei przechowuje ją w nowej kolumnie o nazwieLabelAsKey. ElementLoadImagespobiera wartości z kolumnyImagePathwraz z parametremimageFolderw celu załadowania obrazów do treningu.FitUżywa metody , aby zastosować dane do następującejpreprocessingPipelineEstimatorChainTransformmetody, która zwracaIDataViewdane zawierające wstępnie przetworzone dane.Dzieli dane na zestawy trenowania, walidacji i testowania.
Aby wytrenować model, ważne jest, aby mieć zestaw danych trenowania, a także zestaw danych weryfikacji. Model jest trenowany na zestawie treningowym. Jak dobrze sprawia, że przewidywania dotyczące niezauważonych danych są mierzone przez wydajność zestawu weryfikacji. Na podstawie wyników tej wydajności model wprowadza korekty tego, czego nauczył się w celu poprawy. Zbiór walidacyjny może pochodzić z podziału oryginalnego zestawu danych lub z innego źródła, które zostało już odłożone do tego celu.
Przykładowy kod wykonuje dwa podziały. Najpierw wstępnie przetworzone dane są podzielone, a 70% jest używane do trenowania, podczas gdy pozostałe 30% jest używane do walidacji. Następnie zestaw weryfikacji 30% jest dodatkowo podzielony na zestawy weryfikacji i testów, w których 90% jest używany do walidacji, a 10% jest używany do testowania.
Jednym ze sposobów myślenia o celu tych partycji danych jest egzamin. Podczas nauki o egzaminie przejrzyj notatki, książki lub inne zasoby, aby zrozumieć pojęcia, które znajdują się na egzaminie. Właśnie do tego służy zestaw pociągowy. Następnie możesz wziąć egzamin pozorny, aby zweryfikować swoją wiedzę. W tym miejscu przydaje się zestaw weryfikacji. Chcesz sprawdzić, czy masz dobre zrozumienie pojęć przed przystąpieniem do rzeczywistego egzaminu. Na podstawie tych wyników zanotujesz to, co pomyliłeś lub nie zrozumiałeś dobrze i wprowadzisz zmiany, przygotowując się do właściwego egzaminu. Na koniec zdasz egzamin. Jest to zestaw testowy używany do testowania. Nigdy nie znasz pytań, które znajdują się na egzaminie, a teraz skorzystaj z wiedzy zdobytej na podstawie szkoleń i weryfikacji, aby zastosować swoją wiedzę do zadania.
Przypisuje partycji odpowiednie wartości dla danych trenowania, walidacji i testowania.
Definiowanie potoku trenowania
Trenowanie modelu składa się z dwóch kroków. Najpierw do trenowania modelu używany jest interfejs API klasyfikacji obrazów. Następnie zakodowane etykiety w PredictedLabel kolumnie są konwertowane z powrotem na oryginalną wartość kategorii przy użyciu MapKeyToValue przekształcenia.
var classifierOptions = new ImageClassificationTrainer.Options()
{
FeatureColumnName = "Image",
LabelColumnName = "LabelAsKey",
ValidationSet = validationSet,
Arch = ImageClassificationTrainer.Architecture.ResnetV2101,
MetricsCallback = (metrics) => Console.WriteLine(metrics),
TestOnTrainSet = false,
ReuseTrainSetBottleneckCachedValues = true,
ReuseValidationSetBottleneckCachedValues = true
};
var trainingPipeline = mlContext.MulticlassClassification.Trainers.ImageClassification(classifierOptions)
.Append(mlContext.Transforms.Conversion.MapKeyToValue("PredictedLabel"));
ITransformer trainedModel = trainingPipeline.Fit(trainSet);
Poprzedni kod:
Tworzy nową zmienną do przechowywania zestawu wymaganych i opcjonalnych parametrów dla elementu ImageClassificationTrainer. Parametr ImageClassificationTrainer przyjmuje kilka parametrów opcjonalnych:
-
FeatureColumnNameto kolumna, która jest używana jako dane wejściowe dla modelu. -
LabelColumnNameto kolumna dla wartości, która ma być przewidywana. -
ValidationSetIDataViewelement zawiera dane weryfikacji. -
Archokreśla, która z wstępnie wytrenowanych architektur modelu ma być używana. W tym samouczku jest używany wariant 101-warstwowy modelu ResNetv2. -
MetricsCallbacktworzy powiązanie funkcji w celu śledzenia postępu podczas trenowania. -
TestOnTrainSetinformuje model o mierzeniu wydajności względem zestawu treningowego, gdy nie ma zestawu walidacji. -
ReuseTrainSetBottleneckCachedValuesinformuje model, czy w kolejnych uruchomieniach mają być używane zbuforowane wartości z fazy ograniczenia przepustowości. Faza wąskiego gardła to jednorazowe obliczanie przekazywane, które jest intensywnie obciążające obliczenia po raz pierwszy. Jeśli dane szkoleniowe nie ulegają zmianie i chcesz eksperymentować przy użyciu innej liczby epok lub rozmiaru partii, użycie buforowanych wartości znacznie skraca czas wymagany do wytrenowania modelu. -
ReuseValidationSetBottleneckCachedValuesjest podobny doReuseTrainSetBottleneckCachedValues, jednak w tym przypadku jest przeznaczony dla zestawu danych do weryfikacji.
-
Definiuje potok trenowania
EstimatorChain, który składa się zarówno zmapLabelEstimator, jak i z ImageClassificationTrainer.FitUżywa metody do trenowania modelu.
Użyj modelu
Po wytrenowanym modelu nadszedł czas, aby użyć go do klasyfikowania obrazów.
Utwórz nową metodę narzędzia o nazwie OutputPrediction , aby wyświetlić informacje o przewidywaniach w konsoli programu .
static void OutputPrediction(ModelOutput prediction)
{
string? imageName = Path.GetFileName(prediction.ImagePath);
Console.WriteLine($"Image: {imageName} | Actual Value: {prediction.Label} | Predicted Value: {prediction.PredictedLabel}");
}
Klasyfikowanie pojedynczego obrazu
Utwórz metodę o nazwie
ClassifySingleImagew celu utworzenia i utworzenia pojedynczego przewidywania obrazu.static void ClassifySingleImage(MLContext mlContext, IDataView data, ITransformer trainedModel) { PredictionEngine<ModelInput, ModelOutput> predictionEngine = mlContext.Model.CreatePredictionEngine<ModelInput, ModelOutput>(trainedModel); ModelInput image = mlContext.Data.CreateEnumerable<ModelInput>(data, reuseRowObject: true).First(); ModelOutput prediction = predictionEngine.Predict(image); Console.WriteLine("Classifying single image"); OutputPrediction(prediction); }Metoda
ClassifySingleImage:- Tworzy wewnątrz
PredictionEngineClassifySingleImagemetody . JestPredictionEngineto wygodny interfejs API, który umożliwia przekazanie danych, a następnie przeprowadzenie przewidywania dla pojedynczego wystąpienia danych. - Aby uzyskać dostęp do pojedynczego wystąpienia
ModelInput, konwertujedataIDataViewnaIEnumerableza pomocą metodyCreateEnumerable, a następnie pobiera pierwszą obserwację. -
PredictUżywa metody do klasyfikowania obrazu. - Zwraca przewidywanie do konsoli za pomocą
OutputPredictionmetody .
- Tworzy wewnątrz
Najpierw wywołaj metodę
Fit, a następnie metodęClassifySingleImageprzy użyciu zestawu testowego obrazów.ClassifySingleImage(mlContext, testSet, trainedModel);
Klasyfikowanie wielu obrazów
Utwórz metodę o nazwie
ClassifyImagesw celu tworzenia i generowania wielu przewidywań obrazów.static void ClassifyImages(MLContext mlContext, IDataView data, ITransformer trainedModel) { IDataView predictionData = trainedModel.Transform(data); IEnumerable<ModelOutput> predictions = mlContext.Data.CreateEnumerable<ModelOutput>(predictionData, reuseRowObject: true).Take(10); Console.WriteLine("Classifying multiple images"); foreach (var prediction in predictions) { OutputPrediction(prediction); } }Metoda
ClassifyImages:- Tworzy element
IDataViewzawierający przewidywania przy użyciuTransformmetody . - Aby powtórzyć iteracje prognoz, konwertuje
predictionDataIDataViewnaIEnumerableprzy użyciu metodyCreateEnumerable, a następnie pobiera pierwsze 10 obserwacji. - Iteruje i generuje oryginalne i przewidywane etykiety dla prognoz.
- Tworzy element
Wywołaj
ClassifyImagespo wywołaniu metodyClassifySingleImage()przy użyciu zestawu testowego obrazów.ClassifyImages(mlContext, testSet, trainedModel);
Uruchamianie aplikacji
Uruchom aplikację konsolową. Dane wyjściowe powinny być podobne do następujących danych wyjściowych.
Uwaga / Notatka
Mogą pojawić się ostrzeżenia lub komunikaty dotyczące przetwarzania; te komunikaty zostały usunięte z poniższych wyników dla przejrzystości. W celu zwięzłości dane wyjściowe zostały skondensowane.
Faza wąskiego gardła
Żadna wartość nie jest drukowana dla nazwy obrazu, ponieważ obrazy są ładowane jako a byte[] zatem nie ma nazwy obrazu do wyświetlenia.
Phase: Bottleneck Computation, Dataset used: Train, Image Index: 279
Phase: Bottleneck Computation, Dataset used: Train, Image Index: 280
Phase: Bottleneck Computation, Dataset used: Validation, Image Index: 1
Phase: Bottleneck Computation, Dataset used: Validation, Image Index: 2
Faza trenowania
Phase: Training, Dataset used: Validation, Batch Processed Count: 6, Epoch: 21, Accuracy: 0.6797619
Phase: Training, Dataset used: Validation, Batch Processed Count: 6, Epoch: 22, Accuracy: 0.7642857
Phase: Training, Dataset used: Validation, Batch Processed Count: 6, Epoch: 23, Accuracy: 0.7916667
Klasyfikowanie danych wyjściowych obrazów
Classifying single image
Image: 7001-220.jpg | Actual Value: UD | Predicted Value: UD
Classifying multiple images
Image: 7001-220.jpg | Actual Value: UD | Predicted Value: UD
Image: 7001-163.jpg | Actual Value: UD | Predicted Value: UD
Image: 7001-210.jpg | Actual Value: UD | Predicted Value: UD
Po sprawdzeniu obrazu 7001-220.jpg można sprawdzić, czy nie jest pęknięty, zgodnie z przewidywaniami modelu.

Gratulacje! Udało Ci się utworzyć model uczenia głębokiego do klasyfikowania obrazów.
Ulepszanie modelu
Jeśli wyniki modelu nie są zadowalające, możesz spróbować poprawić jego wydajność, wykonując niektóre z następujących metod:
- Więcej danych: Tym więcej przykładów model uczy się na ich podstawie, tym lepiej działa. Pobierz pełny zestaw danych SDNET2018 i użyj go do trenowania.
- Rozszerzanie danych: popularną techniką dodawania różnych danych jest rozszerzenie danych przez utworzenie obrazu i zastosowanie różnych przekształceń (obracanie, przerzucanie, przesunięcie, przycinanie). Spowoduje to dodanie bardziej zróżnicowanych przykładów dla modelu, z których można się uczyć.
- Trenowanie przez dłuższy czas: tym dłużej trenujesz, tym bardziej dostrojony będzie model. Zwiększenie liczby epok może zwiększyć wydajność modelu.
- Poeksperymentuj z hiperparami: oprócz parametrów używanych w tym samouczku można dostroić inne parametry, aby potencjalnie poprawić wydajność. Zmiana szybkości uczenia, która określa wielkość aktualizacji w modelu po każdej epoki, może poprawić wydajność.
- Użyj innej architektury modelu: w zależności od wyglądu danych model, który może najlepiej poznać jego funkcje, może się różnić. Jeśli nie masz zadowolenia z wydajności modelu, spróbuj zmienić architekturę.
Dalsze kroki
W tym samouczku nauczyłeś się, jak tworzyć niestandardowy model uczenia głębokiego przy użyciu uczenia transferowego, wstępnie wytrenowanego modelu klasyfikacji obrazów TensorFlow oraz interfejsu API klasyfikacji obrazów ML.NET, aby klasyfikować obrazy powierzchni betonowych jako pęknięte lub niepęknięte.
Przejdź do następnego samouczka, aby dowiedzieć się więcej.
Zobacz także
Współpracuj z nami w serwisie GitHub
Źródło tej zawartości można znaleźć w witrynie GitHub, gdzie można również tworzyć i przeglądać problemy i żądania ściągnięcia. Więcej informacji znajdziesz w naszym przewodniku dla współtwórców.