Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Gdy dokument XML jest w pamięci, reprezentacja koncepcyjna jest drzewem. W przypadku programowania masz hierarchię obiektów, aby uzyskać dostęp do węzłów drzewa. W poniższym przykładzie pokazano, jak zawartość XML staje się węzłami.
Ponieważ kod XML jest odczytywany w modelu DOM (DOCUMENT Object Model), fragmenty są tłumaczone na węzły, a te węzły zachowują dodatkowe metadane dotyczące siebie, takie jak ich typ węzła i wartości. Typ węzła jest jego obiektem i określa, jakie akcje można wykonać, oraz jakie właściwości można ustawić lub pobrać.
Jeśli masz następujący prosty kod XML:
Dane wejściowe
<book>
<title>The Handmaid's Tale</title>
</book>
Dane wejściowe są reprezentowane w pamięci jako następujące drzewo węzłów z przypisaną właściwością typu węzła:
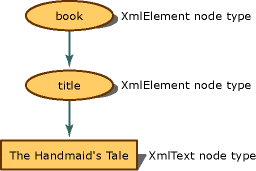
Reprezentacja drzewa węzłów książek i tytułów
Element book staje się obiektem XmlElement, następny element title również staje się obiektem XmlElement, podczas gdy zawartość elementu staje się obiektem XmlText. Podczas przeglądania metod i właściwości XmlElement, widać, że różnią się one od metod i właściwości dostępnych w obiekcie XmlText. Znajomość typu węzła znacznika XML jest niezbędna, ponieważ jego typ węzła określa akcje, które można wykonać.
Poniższy przykład odczytuje dane XML i zapisuje inny tekst w zależności od typu węzła. Używając następującego pliku danych XML jako danych wejściowych, items.xml:
Dane wejściowe
<?xml version="1.0"?>
<!-- This is a sample XML document -->
<!DOCTYPE Items [<!ENTITY number "123">]>
<Items>
<Item>Test with an entity: &number;</Item>
<Item>test with a child element <more/> stuff</Item>
<Item>test with a CDATA section <![CDATA[<456>]]> def</Item>
<Item>Test with a char entity: A</Item>
<!-- Fourteen chars in this element.-->
<Item>1234567890ABCD</Item>
</Items>
Poniższy przykład kodu odczytuje plik items.xml i wyświetla informacje dotyczące każdego typu węzła.
Imports System
Imports System.IO
Imports System.Xml
Public Class Sample
Private Const filename As String = "items.xml"
Public Shared Sub Main()
Dim reader As XmlTextReader = Nothing
Try
' Load the reader with the data file and
'ignore all white space nodes.
reader = New XmlTextReader(filename)
reader.WhitespaceHandling = WhitespaceHandling.None
' Parse the file and display each of the nodes.
While reader.Read()
Select Case reader.NodeType
Case XmlNodeType.Element
Console.Write("<{0}>", reader.Name)
Case XmlNodeType.Text
Console.Write(reader.Value)
Case XmlNodeType.CDATA
Console.Write("<![CDATA[{0}]]>", reader.Value)
Case XmlNodeType.ProcessingInstruction
Console.Write("<?{0} {1}?>", reader.Name, reader.Value)
Case XmlNodeType.Comment
Console.Write("<!--{0}-->", reader.Value)
Case XmlNodeType.XmlDeclaration
Console.Write("<?xml version='1.0'?>")
Case XmlNodeType.Document
Case XmlNodeType.DocumentType
Console.Write("<!DOCTYPE {0} [{1}]", reader.Name, reader.Value)
Case XmlNodeType.EntityReference
Console.Write(reader.Name)
Case XmlNodeType.EndElement
Console.Write("</{0}>", reader.Name)
End Select
End While
Finally
If Not (reader Is Nothing) Then
reader.Close()
End If
End Try
End Sub 'Main ' End class
End Class 'Sample
using System;
using System.IO;
using System.Xml;
public class Sample
{
private const String filename = "items.xml";
public static void Main()
{
XmlTextReader reader = null;
try
{
// Load the reader with the data file and ignore
// all white space nodes.
reader = new XmlTextReader(filename);
reader.WhitespaceHandling = WhitespaceHandling.None;
// Parse the file and display each of the nodes.
while (reader.Read())
{
switch (reader.NodeType)
{
case XmlNodeType.Element:
Console.Write("<{0}>", reader.Name);
break;
case XmlNodeType.Text:
Console.Write(reader.Value);
break;
case XmlNodeType.CDATA:
Console.Write("<![CDATA[{0}]]>", reader.Value);
break;
case XmlNodeType.ProcessingInstruction:
Console.Write("<?{0} {1}?>", reader.Name, reader.Value);
break;
case XmlNodeType.Comment:
Console.Write("<!--{0}-->", reader.Value);
break;
case XmlNodeType.XmlDeclaration:
Console.Write("<?xml version='1.0'?>");
break;
case XmlNodeType.Document:
break;
case XmlNodeType.DocumentType:
Console.Write("<!DOCTYPE {0} [{1}]", reader.Name, reader.Value);
break;
case XmlNodeType.EntityReference:
Console.Write(reader.Name);
break;
case XmlNodeType.EndElement:
Console.Write("</{0}>", reader.Name);
break;
}
}
}
finally
{
if (reader != null)
reader.Close();
}
}
} // End class
Dane wyjściowe z przykładu ujawniają mapowanie danych na typy węzłów.
Wynik
<?xml version='1.0'?><!--This is a sample XML document --><!DOCTYPE Items [<!ENTITY number "123">]<Items><Item>Test with an entity: 123</Item><Item>test with a child element <more> stuff</Item><Item>test with a CDATA section <![CDATA[<456>]]> def</Item><Item>Test with a char entity: A</Item><--Fourteen chars in this element.--><Item>1234567890ABCD</Item></Items>
Biorąc dane wejściowe po jednym wierszu naraz i używając danych wyjściowych wygenerowanych z kodu, możesz użyć poniższej tabeli, aby przeanalizować, który test węzła wygenerował wiersze danych wyjściowych, aby zrozumieć, jakie dane XML stały się typem węzła.
| Dane wejściowe | Wynik | Test typu węzła |
|---|---|---|
| <?xml version="1.0"?> | <?xml version='1.0'?> | XmlNodeType.XmlDeclaration |
| <-- Jest to przykładowy dokument XML —> | <--To jest przykładowy dokument XML--> | XmlNodeType.Comment |
| <! Elementy DOCTYPE [<! Numer JEDNOSTKI "123">]> | <! Elementy DOCTYPE [<! Numer JEDNOSTKI "123">] | XmlNodeType.DocumentType |
| <Elementy> | <Elementy> | XmlNodeType., element |
| <Przedmiot> | <Przedmiot> | XmlNodeType., element |
| Testowanie za pomocą jednostki: &number; | Testowanie za pomocą jednostki: 123 | XmlNodeType.Text |
| </Przedmiot> | </Przedmiot> | XmlNodeType.EndElement |
| <Przedmiot> | <Przedmiot> | XmNodeType., element |
| test z elementem podrzędnym | test z elementem podrzędnym | XmlNodeType.Text |
| <więcej> | <więcej> | XmlNodeType., element |
| zawartość | zawartość | XmlNodeType.Text |
| </Przedmiot> | </Przedmiot> | XmlNodeType.EndElement |
| <Przedmiot> | <Przedmiot> | XmlNodeType., element |
| testowanie za pomocą sekcji CDATA | testowanie za pomocą sekcji CDATA | XmlTest.Text |
| <! [CDATA[<456>]]> | <! [CDATA[<456>]]> | XmlTest.CDATA |
| Def | Def | XmlNodeType.Text |
| </Przedmiot> | </Przedmiot> | XmlNodeType.EndElement |
| <Przedmiot> | <Przedmiot> | XmlNodeType., element |
| Testowanie za pomocą jednostki char: A | Testowanie za pomocą jednostki char: A | XmlNodeType.Text |
| </Przedmiot> | </Przedmiot> | XmlNodeType.EndElement |
| <-- czternaście znaków w tym elemencie.--> | <--Czternaście znaków w tym elemecie.--> | XmlNodeType.Comment (komentarz) |
| <Przedmiot> | <Przedmiot> | XmlNodeType., element |
| 1234567890ABCD | 1234567890ABCD | XmlNodeType.Text |
| </Przedmiot> | </Przedmiot> | XmlNodeType.EndElement |
| </Pozycje> | </Pozycje> | XmlNodeType.EndElement |
Musisz wiedzieć, jaki typ węzła jest przypisany, ponieważ typ węzła kontroluje, jakie rodzaje akcji są prawidłowe i jakiego rodzaju właściwości można ustawić i pobrać.
Tworzenie węzła dla białych znaków jest kontrolowane, gdy dane są ładowane do modelu DOM przez flagę PreserveWhitespace . Aby uzyskać więcej informacji, zobacz Obsługa białych znaków oraz istotnych białych znaków podczas ładowania modelu DOM.
Aby dodać nowe węzły do modelu DOM, zobacz Wstawianie węzłów do dokumentu XML. Aby usunąć węzły z modelu DOM, zobacz Usuwanie węzłów, zawartości i wartości z dokumentu XML. Aby zmodyfikować zawartość węzłów w modelu DOM, zobacz Modyfikowanie węzłów, zawartości i wartości w dokumencie XML.
Zobacz także
Współpracuj z nami na GitHub
Źródło tej zawartości można znaleźć w witrynie GitHub, gdzie można również tworzyć i przeglądać problemy oraz żądania ściągnięcia. Aby uzyskać więcej informacji, zapoznaj się z naszym przewodnikiem dla twórców.