Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Ten artykuł zawiera omówienie typów, które ułatwiają odczytywanie danych z wielu buforów. Są one używane głównie do obsługi PipeReader obiektów.
IBufferWriter<T>
System.Buffers.IBufferWriter<T> jest kontraktem na zapis synchroniczny buforowany. Na najniższym poziomie interfejs:
- Jest podstawowy i nie jest trudny do użycia.
- Zezwala na dostęp do elementu Memory<T> lub Span<T>. Element
Memory<T>lubSpan<T>można zapisać i określić, ile elementówTzostało zapisanych.
void WriteHello(IBufferWriter<byte> writer)
{
// Request at least 5 bytes.
Span<byte> span = writer.GetSpan(5);
ReadOnlySpan<char> helloSpan = "Hello".AsSpan();
int written = Encoding.ASCII.GetBytes(helloSpan, span);
// Tell the writer how many bytes were written.
writer.Advance(written);
}
Poprzednia metoda:
- Żąda buforu o rozmiarze co najmniej 5 bajtów z
IBufferWriter<byte>, używającGetSpan(5). - Zapisuje bajty dla ciągu ASCII "Hello" do zwróconego
Span<byte>elementu. - Wywołuje IBufferWriter<T>, aby wskazać, ile bajtów zapisano w buforze.
To metoda zapisu używa buforu Memory<T>/Span<T> dostarczonego przez IBufferWriter<T>. Alternatywnie można użyć metody rozszerzenia, aby skopiować istniejący bufor do Write.
Write wykonuje pracę polegającą na wywoływaniu GetSpan/Advance zgodnie z potrzebami, więc nie trzeba wywoływać Advance po napisaniu:
void WriteHello(IBufferWriter<byte> writer)
{
byte[] helloBytes = Encoding.ASCII.GetBytes("Hello");
// Write helloBytes to the writer. There's no need to call Advance here
// since Write calls Advance.
writer.Write(helloBytes);
}
ArrayBufferWriter<T> jest implementacją IBufferWriter<T>, której pamięć pomocnicza jest pojedynczą, ciągłą tablicą.
IBufferWriter — typowe problemy
-
GetSpaniGetMemoryzwraca bufor z co najmniej żądaną ilością pamięci. Nie zakładaj dokładnych rozmiarów buforu. - Nie ma gwarancji, że kolejne wywołania będą zwracać ten sam bufor lub bufor o takim samym rozmiarze.
- Po wywołaniu
Advancepolecenia należy zażądać nowego buforu, aby kontynuować zapisywanie większej ilości danych. Nie można zapisać wcześniej uzyskanego buforu po wywołaniuAdvance.
ReadOnlySequence<T>
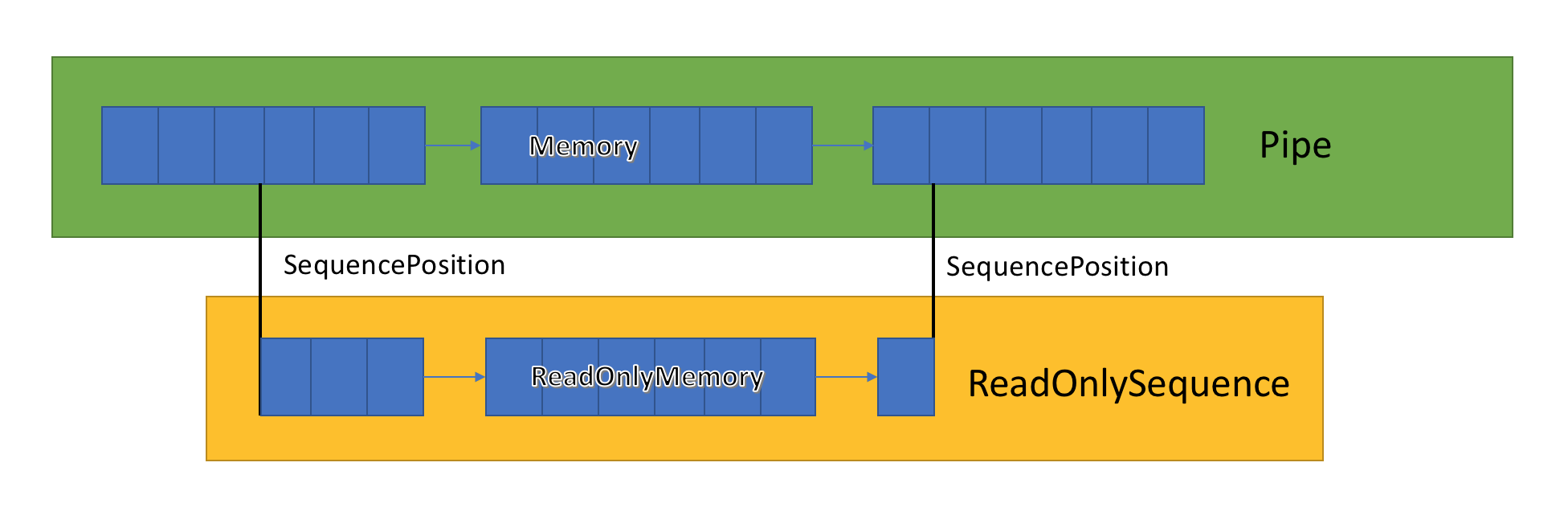
ReadOnlySequence<T> jest strukturą, która może reprezentować ciągłą lub nieciągłą sekwencję T. Można go skonstruować z:
- Polecenie
T[] - Polecenie
ReadOnlyMemory<T> - Para połączonego węzła ReadOnlySequenceSegment<T> listy i indeksu reprezentującego pozycję początkową i końcową sekwencji.
Trzecia reprezentacja jest najbardziej interesująca, ponieważ ma wpływ na wydajność różnych operacji na obiekcie ReadOnlySequence<T>:
| Reprezentacja | Operacja | Złożoność |
|---|---|---|
T[]/ReadOnlyMemory<T> |
Length |
O(1) |
T[]/ReadOnlyMemory<T> |
GetPosition(long) |
O(1) |
T[]/ReadOnlyMemory<T> |
Slice(int, int) |
O(1) |
T[]/ReadOnlyMemory<T> |
Slice(SequencePosition, SequencePosition) |
O(1) |
ReadOnlySequenceSegment<T> |
Length |
O(1) |
ReadOnlySequenceSegment<T> |
GetPosition(long) |
O(number of segments) |
ReadOnlySequenceSegment<T> |
Slice(int, int) |
O(number of segments) |
ReadOnlySequenceSegment<T> |
Slice(SequencePosition, SequencePosition) |
O(1) |
Ze względu na tę mieszaną reprezentację ReadOnlySequence<T> indeksy są uwidaczniane jako SequencePosition zamiast liczby całkowitej. A SequencePosition:
- Jest nieprzejrzystą wartością, która reprezentuje indeks w
ReadOnlySequence<T>, z którego pochodzi. - Składa się z dwóch części, liczby całkowitej i obiektu. Te dwie wartości są powiązane z implementacją programu
ReadOnlySequence<T>.
Uzyskiwanie dostępu do danych
Element ReadOnlySequence<T> uwidacznia dane jako wyliczenie elementu ReadOnlyMemory<T>. Wyliczanie każdego z segmentów można wykonać przy użyciu podstawowego foreach:
long FindIndexOf(in ReadOnlySequence<byte> buffer, byte data)
{
long position = 0;
foreach (ReadOnlyMemory<byte> segment in buffer)
{
ReadOnlySpan<byte> span = segment.Span;
var index = span.IndexOf(data);
if (index != -1)
{
return position + index;
}
position += span.Length;
}
return -1;
}
Poprzednia metoda wyszukuje poszczególne segmenty dla określonego bajtu. Jeśli musisz śledzić poszczególne segmenty SequencePosition, ReadOnlySequence<T>.TryGet jest bardziej odpowiednie. Następny przykład zmienia poprzedni kod, aby zwrócić wartość SequencePosition zamiast liczby całkowitej. Zwracanie elementu SequencePosition ma korzyść z umożliwienia obiektowi wywołującego uniknięcia drugiego skanowania w celu pobrania danych w określonym indeksie.
SequencePosition? FindIndexOf(in ReadOnlySequence<byte> buffer, byte data)
{
SequencePosition position = buffer.Start;
SequencePosition result = position;
while (buffer.TryGet(ref position, out ReadOnlyMemory<byte> segment))
{
ReadOnlySpan<byte> span = segment.Span;
var index = span.IndexOf(data);
if (index != -1)
{
return buffer.GetPosition(index, result);
}
result = position;
}
return null;
}
Kombinacja SequencePosition i TryGet działa jak enumerator. Pole pozycji jest modyfikowane na początku każdej iteracji, aby określać początek każdego segmentu w ReadOnlySequence<T>.
Poprzednia metoda istnieje jako metoda rozszerzenia w metodzie ReadOnlySequence<T>.
PositionOf można użyć do uproszczenia poprzedniego kodu:
SequencePosition? FindIndexOf(in ReadOnlySequence<byte> buffer, byte data) => buffer.PositionOf(data);
Przetwórz ReadOnlySequence<T>
Przetwarzanie obiektu ReadOnlySequence<T> może być trudne, ponieważ dane mogą być podzielone między wiele segmentów w ramach sekwencji. Aby uzyskać najlepszą wydajność, podziel kod na dwie ścieżki:
- Szybka ścieżka, która dotyczy przypadku pojedynczego segmentu.
- Powolna ścieżka, która zajmuje się podziałem danych między segmenty.
Istnieje kilka podejść, które mogą służyć do przetwarzania danych w sekwencjach wielosegmentowych:
- Użyj
SequenceReader<T>. - Analizuj segmenty danych jeden po drugim, śledząc
SequencePositionoraz indeks w ramach analizowanego segmentu. Pozwala to uniknąć niepotrzebnych alokacji, ale może być nieefektywne, zwłaszcza w przypadku małych buforów. - Skopiuj element
ReadOnlySequence<T>do ciągłej tablicy i traktuj ją jak pojedynczy bufor:- Jeśli rozmiar obiektu
ReadOnlySequence<T>jest mały, może być uzasadnione skopiowanie danych do buforu przydzielonego na stosie przy użyciu operatora stackalloc. - Skopiuj element
ReadOnlySequence<T>do tablicy w puli przy użyciu polecenia ArrayPool<T>.Shared. - Użyj
ReadOnlySequence<T>.ToArray(). Nie jest to zalecane w gorących ścieżkach, ponieważ przydziela noweT[]na stercie.
- Jeśli rozmiar obiektu
W poniższych przykładach przedstawiono niektóre typowe przypadki przetwarzania ReadOnlySequence<byte>:
Przetwarzanie danych binarnych
Poniższy przykład analizuje 4-bajtową długość liczby całkowitej w formacie big-endian od początku ReadOnlySequence<byte>.
bool TryParseHeaderLength(ref ReadOnlySequence<byte> buffer, out int length)
{
// If there's not enough space, the length can't be obtained.
if (buffer.Length < 4)
{
length = 0;
return false;
}
// Grab the first 4 bytes of the buffer.
var lengthSlice = buffer.Slice(buffer.Start, 4);
if (lengthSlice.IsSingleSegment)
{
// Fast path since it's a single segment.
length = BinaryPrimitives.ReadInt32BigEndian(lengthSlice.First.Span);
}
else
{
// There are 4 bytes split across multiple segments. Since it's so small, it
// can be copied to a stack allocated buffer. This avoids a heap allocation.
Span<byte> stackBuffer = stackalloc byte[4];
lengthSlice.CopyTo(stackBuffer);
length = BinaryPrimitives.ReadInt32BigEndian(stackBuffer);
}
// Move the buffer 4 bytes ahead.
buffer = buffer.Slice(lengthSlice.End);
return true;
}
Przetwarzanie danych tekstowych
Poniższy przykład:
- Znajduje pierwszy nowy wiersz (
\r\n) wReadOnlySequence<byte>obiekcie i zwraca go za pośrednictwem parametru "line". - Przycina ten wiersz, z wyłączeniem
\r\nz buforu wejściowego.
static bool TryParseLine(ref ReadOnlySequence<byte> buffer, out ReadOnlySequence<byte> line)
{
SequencePosition position = buffer.Start;
SequencePosition previous = position;
var index = -1;
line = default;
while (buffer.TryGet(ref position, out ReadOnlyMemory<byte> segment))
{
ReadOnlySpan<byte> span = segment.Span;
// Look for \r in the current segment.
index = span.IndexOf((byte)'\r');
if (index != -1)
{
// Check next segment for \n.
if (index + 1 >= span.Length)
{
var next = position;
if (!buffer.TryGet(ref next, out ReadOnlyMemory<byte> nextSegment))
{
// You're at the end of the sequence.
return false;
}
else if (nextSegment.Span[0] == (byte)'\n')
{
// A match was found.
break;
}
}
// Check the current segment of \n.
else if (span[index + 1] == (byte)'\n')
{
// It was found.
break;
}
}
previous = position;
}
if (index != -1)
{
// Get the position just before the \r\n.
var delimeter = buffer.GetPosition(index, previous);
// Slice the line (excluding \r\n).
line = buffer.Slice(buffer.Start, delimeter);
// Slice the buffer to get the remaining data after the line.
buffer = buffer.Slice(buffer.GetPosition(2, delimeter));
return true;
}
return false;
}
Niezapełnione segmenty
Dopuszczalne jest przechowywanie pustych segmentów wewnątrz elementu ReadOnlySequence<T>. Puste segmenty mogą wystąpić podczas jawnego wyliczania segmentów:
static void EmptySegments()
{
// This logic creates a ReadOnlySequence<byte> with 4 segments,
// two of which are empty.
var first = new BufferSegment(new byte[0]);
var last = first.Append(new byte[] { 97 })
.Append(new byte[0]).Append(new byte[] { 98 });
// Construct the ReadOnlySequence<byte> from the linked list segments.
var data = new ReadOnlySequence<byte>(first, 0, last, 1);
// Slice using numbers.
var sequence1 = data.Slice(0, 2);
// Slice using SequencePosition pointing at the empty segment.
var sequence2 = data.Slice(data.Start, 2);
Console.WriteLine($"sequence1.Length={sequence1.Length}"); // sequence1.Length=2
Console.WriteLine($"sequence2.Length={sequence2.Length}"); // sequence2.Length=2
// sequence1.FirstSpan.Length=1
Console.WriteLine($"sequence1.FirstSpan.Length={sequence1.FirstSpan.Length}");
// Slicing using SequencePosition will Slice the ReadOnlySequence<byte> directly
// on the empty segment!
// sequence2.FirstSpan.Length=0
Console.WriteLine($"sequence2.FirstSpan.Length={sequence2.FirstSpan.Length}");
// The following code prints 0, 1, 0, 1.
SequencePosition position = data.Start;
while (data.TryGet(ref position, out ReadOnlyMemory<byte> memory))
{
Console.WriteLine(memory.Length);
}
}
class BufferSegment : ReadOnlySequenceSegment<byte>
{
public BufferSegment(Memory<byte> memory)
{
Memory = memory;
}
public BufferSegment Append(Memory<byte> memory)
{
var segment = new BufferSegment(memory)
{
RunningIndex = RunningIndex + Memory.Length
};
Next = segment;
return segment;
}
}
Powyższy kod tworzy element ReadOnlySequence<byte> z pustymi segmentami i pokazuje, jak te puste segmenty wpływają na różne interfejsy API:
-
ReadOnlySequence<T>.SliceSequencePositionelement wskazujący na pusty segment zachowuje ten segment. -
ReadOnlySequence<T>.Sliceużywając typu int pomija puste segmenty. - Wyliczanie
ReadOnlySequence<T>powoduje wyliczenie pustych segmentów.
Potencjalne problemy z funkcją ReadOnlySequence<T> i SequencePosition
Istnieje kilka nietypowych wyników podczas radzenia sobie z ReadOnlySequence<T>/SequencePosition w porównaniu do normalnego ReadOnlySpan<T>/ReadOnlyMemory<T>/T[]/int:
-
SequencePositionjest znacznikiem położenia dla określonegoReadOnlySequence<T>, a nie położenia bezwzględnego. Ponieważ jest on względny względem określonegoReadOnlySequence<T>elementu, nie ma znaczenia, jeśli jest używany pozaReadOnlySequence<T>miejscem, gdzie powstał. - Nie można wykonać operacji arytmetycznych na
SequencePositionbezReadOnlySequence<T>. Oznacza to, że wykonywanie podstawowych czynności, takich jakposition++jest napisaneposition = ReadOnlySequence<T>.GetPosition(1, position). -
GetPosition(long)nie obsługuje indeksów ujemnych. Oznacza to, że nie można uzyskać przedostatniego znaku bez przechodzenia przez wszystkie segmenty. - Nie można porównać dwóch
SequencePosition, co utrudnia:- Sprawdź, czy jedna pozycja jest większa niż lub mniejsza niż inna pozycja.
- Napisz kilka algorytmów analizowania.
-
ReadOnlySequence<T>ma większy rozmiar niż odwołanie do obiektu i należy przekazywać przez lub ref, tam, gdzie to możliwe. PrzekazywanieReadOnlySequence<T>przezinlubrefzmniejsza liczbę kopii struktury. - Puste części
- Są prawidłowe w obrębie obiektu
ReadOnlySequence<T>. - Może pojawić się podczas iteracji przy użyciu metody
ReadOnlySequence<T>.TryGet. - Może pojawić się fragmentowanie sekwencji przy użyciu
ReadOnlySequence<T>.Slice()metody z obiektamiSequencePosition.
- Są prawidłowe w obrębie obiektu
SequenceReader<T>
- Jest nowym typem wprowadzonym na platformie .NET Core 3.0 w celu uproszczenia przetwarzania elementu
ReadOnlySequence<T>. - Łączy różnice między pojedynczym segmentem
ReadOnlySequence<T>a wieloma segmentamiReadOnlySequence<T>. - Udostępnia narzędzia pomocnicze do odczytywania danych binarnych i tekstowych (
byteichar), które mogą, ale nie muszą być podzielone między segmenty.
Istnieją wbudowane metody przetwarzania zarówno danych binarnych, jak i rozdzielonych. W poniższej sekcji pokazano, jak te same metody wyglądają w przypadku elementu SequenceReader<T>:
Uzyskiwanie dostępu do danych
SequenceReader<T> ma metody do wyliczania danych wewnątrz ReadOnlySequence<T> bezpośrednio. Poniższy kod jest przykładem przetwarzania obiektu ReadOnlySequence<byte>byte w danym momencie:
while (reader.TryRead(out byte b))
{
Process(b);
}
Element CurrentSpan uwidacznia bieżący segment Span, który jest podobny do tego, co zostało wykonane w metodzie ręcznie.
Użyj pozycji
Poniższy kod to przykładowa implementacja FindIndexOf korzystająca z SequenceReader<T>:
SequencePosition? FindIndexOf(in ReadOnlySequence<byte> buffer, byte data)
{
var reader = new SequenceReader<byte>(buffer);
while (!reader.End)
{
// Search for the byte in the current span.
var index = reader.CurrentSpan.IndexOf(data);
if (index != -1)
{
// It was found, so advance to the position.
reader.Advance(index);
return reader.Position;
}
// Skip the current segment since there's nothing in it.
reader.Advance(reader.CurrentSpan.Length);
}
return null;
}
Przetwarzanie danych binarnych
Poniższy przykład analizuje 4-bajtową długość liczby całkowitej w formacie big-endian od początku ReadOnlySequence<byte>.
bool TryParseHeaderLength(ref ReadOnlySequence<byte> buffer, out int length)
{
var reader = new SequenceReader<byte>(buffer);
return reader.TryReadBigEndian(out length);
}
Przetwarzanie danych tekstowych
static ReadOnlySpan<byte> NewLine => new byte[] { (byte)'\r', (byte)'\n' };
static bool TryParseLine(ref ReadOnlySequence<byte> buffer,
out ReadOnlySequence<byte> line)
{
var reader = new SequenceReader<byte>(buffer);
if (reader.TryReadTo(out line, NewLine))
{
buffer = buffer.Slice(reader.Position);
return true;
}
line = default;
return false;
}
Typowe problemy z SequenceReader<T>
- Ponieważ
SequenceReader<T>jest modyfikowalną strukturą, zawsze powinno być przekazywane przez odwołanie. -
SequenceReader<T>jest strukturą ref , więc można jej używać tylko w metodach synchronicznych i nie można ich przechowywać w polach. Aby uzyskać więcej informacji, zobacz Unikanie alokacji. -
SequenceReader<T>jest zoptymalizowany do użycia jako czytnik do jednorazowego odczytu.Rewindjest przeznaczony dla małych kopii zapasowych, których nie można obsłużyć przy użyciu innych interfejsów API:Read,PeekiIsNext.
Współpracuj z nami w serwisie GitHub
Źródło tej zawartości można znaleźć w witrynie GitHub, gdzie można również tworzyć i przeglądać problemy i żądania ściągnięcia. Więcej informacji znajdziesz w naszym przewodniku dla współtwórców.