Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Wskazówka
Ta treść jest fragmentem eBooka "Architektura mikrousług .NET dla konteneryzowanych aplikacji .NET", dostępnego na .NET Docs lub jako bezpłatny plik PDF do pobrania i czytania w trybie offline.

Jak wspomniano wcześniej, należy obsługiwać błędy, których rozwiązanie może wymagać zmiennej ilości czasu, co może się zdarzyć, gdy próbujesz nawiązać połączenie z zdalną usługą lub zasobem. Obsługa tego typu błędów może poprawić stabilność i odporność aplikacji.
W środowisku rozproszonym wywołania zasobów zdalnych i usług mogą zakończyć się niepowodzeniem z powodu przejściowych błędów, takich jak wolne połączenia sieciowe i przekroczenia limitu czasu, lub jeśli zasoby odpowiadają wolno lub są tymczasowo niedostępne. Te błędy zwykle naprawiają się po krótkim czasie, a niezawodna aplikacja w chmurze powinna być przygotowana do ich obsługi przy użyciu strategii takiej jak "Wzorzec ponawiania prób".
Mogą jednak wystąpić sytuacje, w których błędy są spowodowane nieprzewidzianymi zdarzeniami, których naprawa może zająć znacznie więcej czasu. Takie błędy mogą mieć różny stopień ważności — od częściowej utraty łączności do całkowitej awarii usługi. W takich sytuacjach może to być bezcelowe, aby aplikacja stale ponawiała próbę wykonania operacji, która prawdopodobnie nie powiedzie się.
Zamiast tego aplikacja powinna zostać zakodowana w celu zaakceptowania, że operacja nie powiodła się i odpowiednio obsłużyła błąd.
Użycie ponownych prób http nieostrożnie może spowodować utworzenie ataku typu "odmowa usługi" (DoS) w ramach własnego oprogramowania. Ponieważ mikrousługa kończy się niepowodzeniem lub działa wolno, wielu klientów może wielokrotnie ponawiać próby żądań, które zakończyły się niepowodzeniem. Stwarza to niebezpieczne ryzyko wykładniczo rosnącego ruchu ukierunkowanego na awarię usługi.
W związku z tym potrzebujesz jakiejś bariery obronnej, aby nadmierne żądania zatrzymały się, gdy nie warto próbować. Ta bariera obrony jest właśnie wyłącznik.
Wzorzec przełącznika ma inny cel niż wzorzec ponawiania. Wzorzec ponawiania umożliwia aplikacji ponawianie próby wykonania operacji w oczekiwaniu, że operacja zakończy się pomyślnie. Wzorzec wyłącznika uniemożliwia aplikacji wykonywanie operacji, która prawdopodobnie zakończy się niepowodzeniem. Aplikacja może połączyć te dwa wzorce. Jednak logika ponawiania powinna być wrażliwa na każdy wyjątek zwrócony przez wyłącznik obwodu i powinna porzucić próby ponawiania, jeśli wyłącznik wskazuje, że błąd nie jest przejściowy.
Implementowanie wzorca wyłącznika za pomocą elementów IHttpClientFactory i Polly
Podobnie jak podczas implementowania ponownych prób, zalecane podejście dla wyłączników polega na wykorzystaniu sprawdzonych bibliotek platformy .NET, takich jak Polly i natywnej integracji z usługą IHttpClientFactory.
Dodanie polityki wyłącznika awaryjnego do przepływu oprogramowania pośredniczącego jest równie proste jak dodanie pojedynczego fragmentu kodu przyrostowego do tego, co już masz podczas korzystania z IHttpClientFactory.
Jedyny dodatek do kodu używanego do ponawiania wywołań HTTP polega na dodaniu zasady Circuit Breaker do listy zasad do wykorzystania, jak pokazano w poniższym kodzie inkrementalnym.
// Program.cs
var retryPolicy = GetRetryPolicy();
var circuitBreakerPolicy = GetCircuitBreakerPolicy();
builder.Services.AddHttpClient<IBasketService, BasketService>()
.SetHandlerLifetime(TimeSpan.FromMinutes(5)) // Sample: default lifetime is 2 minutes
.AddHttpMessageHandler<HttpClientAuthorizationDelegatingHandler>()
.AddPolicyHandler(retryPolicy)
.AddPolicyHandler(circuitBreakerPolicy);
Metoda AddPolicyHandler() to ta, która dodaje zasady do obiektów HttpClient, których będziesz używać. W tym przypadku dodaje się zasady Polly dla wyłącznika.
Aby zapewnić bardziej modułowe podejście, polityka wyłącznika jest definiowana w oddzielnej metodzie o nazwie GetCircuitBreakerPolicy(), jak pokazano w poniższym kodzie.
// also in Program.cs
static IAsyncPolicy<HttpResponseMessage> GetCircuitBreakerPolicy()
{
return HttpPolicyExtensions
.HandleTransientHttpError()
.CircuitBreakerAsync(5, TimeSpan.FromSeconds(30));
}
W powyższym przykładzie kodu zasada wyłącznika jest skonfigurowana tak, aby przerywała (otwierała) obwód w przypadku pięciu kolejnych błędów podczas ponawiania żądań HTTP. W takim przypadku obwód zostanie przerwany na 30 sekund: w tym okresie wywołania zostaną natychmiast odrzucone przez mechanizm wyłącznika, zamiast faktycznie być realizowane. Zasady automatycznie interpretują odpowiednie wyjątki i kody stanu HTTP jako błędy.
Wyłączniki powinny być również używane do przekierowywania żądań do infrastruktury rezerwowej, jeśli wystąpiły problemy w konkretnym zasobie wdrożonym w innym środowisku niż aplikacja kliencka lub usługa wykonująca wywołanie HTTP. W ten sposób, jeśli w centrum danych wystąpi awaria, która ma wpływ tylko na mikrousługi zaplecza, ale nie aplikacje klienckie, aplikacje klienckie mogą przekierowywać do usług rezerwowych. Polly planuje nowe zasady automatyzowania tego scenariusza zasad trybu failover .
Wszystkie te funkcje dotyczą przypadków, w których zarządzasz przełączaniem awaryjnym w kodzie .NET, w przeciwieństwie do automatycznego zarządzania przez platformę Azure, zapewniając przy tym przezroczystość lokalizacji.
Z punktu widzenia użytkowania klienta HttpClient nie ma potrzeby dodawania niczego nowego, ponieważ kod jest taki sam, jak przy użyciu HttpClient i IHttpClientFactory, jak pokazano w poprzednich sekcjach.
Testowanie ponownego wysyłania żądań HTTP i wyłączników obwodów w eShopOnContainers
Za każdym razem, gdy uruchamiasz rozwiązanie eShopOnContainers na hoście platformy Docker, należy uruchomić wiele kontenerów. Niektóre kontenery są wolniejsze do uruchamiania i inicjowania, na przykład kontenera programu SQL Server. Jest to szczególnie istotne przy pierwszym wdrożeniu aplikacji eShopOnContainers na platformie Docker, ponieważ wymaga skonfigurowania obrazów i bazy danych. Fakt, że niektóre kontenery zaczynają działać wolniej niż inne, mogą spowodować, że pozostałe usługi początkowo zgłaszają wyjątki HTTP, nawet jeśli ustawisz zależności między kontenerami na poziomie docker-compose, jak wyjaśniono w poprzednich sekcjach. Te zależności docker-compose między kontenerami są po prostu na poziomie procesu. Proces punktu wejścia kontenera może zostać uruchomiony, ale program SQL Server może nie być gotowy do obsługi zapytań. Wynikiem może być kaskada błędów, a aplikacja może uzyskać wyjątek podczas próby użycia tego konkretnego kontenera.
Ten typ błędu może być również wyświetlany podczas uruchamiania, gdy aplikacja jest wdrażana w chmurze. W takim przypadku koordynatorzy mogą przenosić kontenery z jednego węzła lub maszyny wirtualnej do innego (czyli uruchamianie nowych wystąpień) podczas równoważenia liczby kontenerów w węzłach klastra.
Sposób, w jaki 'eShopOnContainers' rozwiązuje te problemy podczas uruchamiania wszystkich kontenerów, polega na użyciu wzorca retry omówionego wcześniej.
Testowanie wyłącznika w eShopOnContainers
Istnieje kilka sposobów na przerwanie lub otworzenie obwodu i przetestowanie go za pomocą eShopOnContainers.
Jedną z opcji jest obniżenie dozwolonej liczby ponownych prób do 1 w zasadach wyłącznika i ponowne wdrożenie całego rozwiązania na platformie Docker. Przy pojedynczym ponowieniu istnieje wysokie prawdopodobieństwo, że żądanie HTTP zakończy się niepowodzeniem podczas wdrażania, wyłącznik zostanie otwarty i pojawi się błąd.
Inną opcją jest użycie niestandardowego oprogramowania pośredniczącego zaimplementowanego w mikrousłudze Koszyk . Po włączeniu tego oprogramowania pośredniczącego przechwytuje wszystkie żądania HTTP i zwraca kod stanu 500. Oprogramowanie pośredniczące można włączyć, wysyłając żądanie GET do odrzucanego URI, w następujący sposób:
GET http://localhost:5103/failing
To żądanie zwraca bieżący stan oprogramowania pośredniczącego. Jeśli oprogramowanie pośredniczące jest włączone, żądanie zwraca kod stanu 500. Jeśli oprogramowanie pośredniczące jest wyłączone, nie ma odpowiedzi.GET http://localhost:5103/failing?enable
To żądanie aktywuje middleware.GET http://localhost:5103/failing?disable
To żądanie wyłącza oprogramowanie pośredniczące.
Na przykład po uruchomieniu aplikacji możesz włączyć oprogramowanie pośredniczące, wysyłając żądanie przy użyciu następującego identyfikatora URI w dowolnej przeglądarce. Pamiętaj, że mikrousługa porządkowania używa portu 5103.
http://localhost:5103/failing?enable
Następnie możesz sprawdzić stan przy użyciu identyfikatora URI http://localhost:5103/failing, jak pokazano na rysunku 8-5.
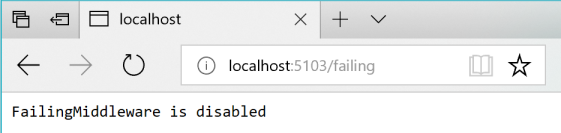
Rysunek 8–5. Sprawdzanie stanu "Niepowodzenie" ASP.NET oprogramowania pośredniczącego — w tym przypadku wyłączone.
W tym momencie mikrousługa Koszyk odpowiada kodem stanu 500 za każdym razem, gdy wywołasz ją.
Po uruchomieniu oprogramowania pośredniczącego możesz spróbować wykonać zamówienie z aplikacji internetowej MVC. Ponieważ żądania kończą się niepowodzeniem, obwód zostanie otwarty.
W poniższym przykładzie widać, że aplikacja internetowa MVC ma blok catch w logice składania zamówienia. Jeśli kod przechwytuje wyjątek otwartego obwodu, zostaje wyświetlony przyjazny komunikat, który mówi użytkownikowi, aby poczekał.
public class CartController : Controller
{
//…
public async Task<IActionResult> Index()
{
try
{
var user = _appUserParser.Parse(HttpContext.User);
//Http requests using the Typed Client (Service Agent)
var vm = await _basketSvc.GetBasket(user);
return View(vm);
}
catch (BrokenCircuitException)
{
// Catches error when Basket.api is in circuit-opened mode
HandleBrokenCircuitException();
}
return View();
}
private void HandleBrokenCircuitException()
{
TempData["BasketInoperativeMsg"] = "Basket Service is inoperative, please try later on. (Business message due to Circuit-Breaker)";
}
}
Oto podsumowanie. Polityka ponawiania próbuje kilkakrotnie wykonać żądanie HTTP i otrzymuje błędy HTTP. Gdy liczba ponownych prób osiągnie maksymalną liczbę ustawioną dla zasad wyłącznika (w tym przypadku 5), aplikacja zgłasza wyjątek BrokenCircuitException. Wynikiem jest przyjazny komunikat, jak pokazano na rysunku 8–6.
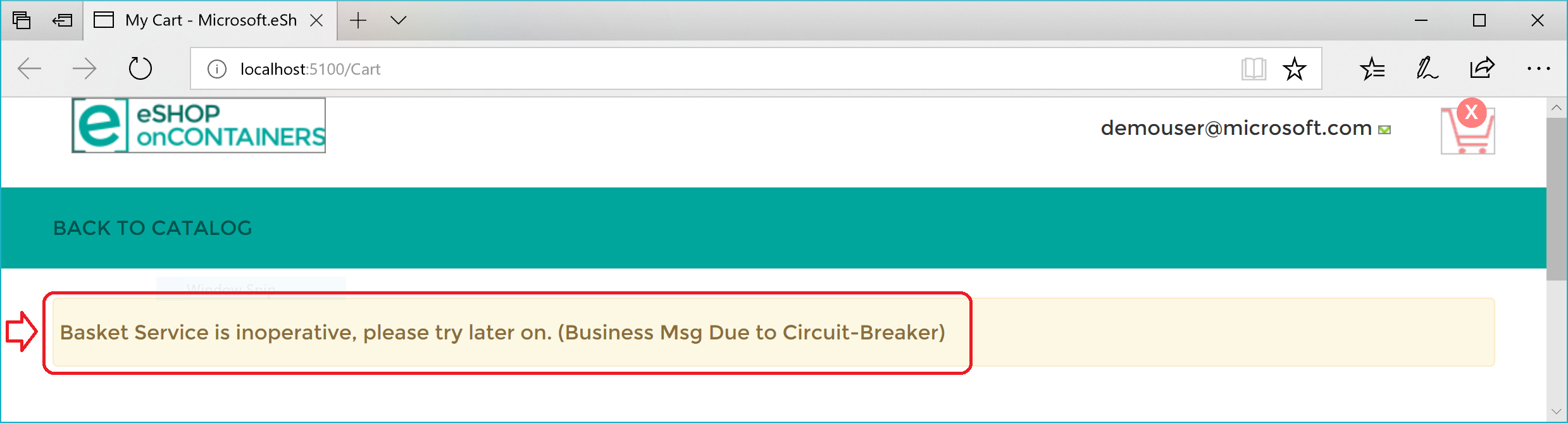
Rysunek 8–6. Wyłącznik zwraca błąd w interfejsie użytkownika
Możesz zaimplementować inną logikę dla tego, kiedy należy otworzyć/przerwać obwód. Możesz też wypróbować żądanie HTTP względem innej mikrousługi zaplecza, jeśli istnieje rezerwowe centrum danych lub nadmiarowy system zaplecza.
Na koniec możliwe jest wykorzystanie CircuitBreakerPolicy do użycia Isolate (które wymusza otwarcie obwodu i utrzymuje go otwartym) oraz Reset (które ponownie go zamyka). Mogą one być użyte do stworzenia pomocniczego punktu końcowego HTTP, który bezpośrednio wywołuje funkcje Izolowanie i Resetowanie w polityce. Taki punkt końcowy HTTP, odpowiednio zabezpieczony, może być również używany w środowisku produkcyjnym do tymczasowego izolowania systemu podrzędnego, na przykład gdy chcesz go zaktualizować. Możesz też ręcznie odciąć zasilanie obwodu, aby chronić system podrzędny, który podejrzewasz, że jest uszkodzony.
Dodatkowe zasoby
- wzorzec wyłącznika
https://learn.microsoft.com/azure/architecture/patterns/circuit-breaker
Współpracuj z nami na GitHub
Źródło tej zawartości można znaleźć w witrynie GitHub, gdzie można również tworzyć i przeglądać problemy oraz żądania ściągnięcia. Aby uzyskać więcej informacji, zapoznaj się z naszym przewodnikiem dla twórców.