Najlepsze rozwiązania w zakresie ujednolicania danych
Podczas konfigurowania reguł w celu ujednolicenia danych w profilu klienta należy wziąć pod uwagę następujące sprawdzone metody:
Zrównoważenie czasu na ujednolicenie a pełne dopasowanie. Próba uchwycenia każdego możliwego dopasowania prowadzi do tego, że wiele zasad i unifikacja zajmuje dużo czasu.
Dodawaj reguły stopniowo i śledź wyniki. Usuń reguły, które nie poprawiają wyniku dopasowania.
Deduplikacja każdej tabeli , tak aby każdy klient był reprezentowany w jednym wierszu.
Normalizacja służy do standaryzacji różnic w sposobie wprowadzania danych, takich jak ulica vs. St vs. St. vs. ulica.
Używaj strategicznego dopasowania rozmytego, aby poprawiać literówki i błędy , takie jak bob@contoso.com i bob@contoso.cm. Dopasowania rozmyte trwają dłużej niż dopasowania dokładne. Zawsze sprawdzaj, czy dodatkowy czas spędzony na dopasowywaniu rozmytym jest wart dodatkowego współczynnika dopasowania.
Zawęź zakres dopasowań za pomocą dopasowania ścisłego. Upewnij się, że każda reguła z warunkami rozmytymi ma co najmniej jeden warunek dokładnego dopasowania.
Nie dopasowuj kolumn, które zawierają często powtarzające się dane. Upewnij się, że kolumny z dopasowaniem rozmytym nie mają często powtarzających się wartości, takich jak domyślna wartość formularza "Imię".
Wydajność unifikacji
Uruchomienie każdej reguły wymaga czasu. Wzorce, takie jak porównywanie każdej tabeli z każdą inną tabelą lub próba przechwycenia każdego możliwego dopasowania rekordu, mogą prowadzić do długiego czasu przetwarzania unifikacji. Zwraca również niewiele, jeśli w ogóle, dopasowań w planie, który porównuje każdą tabelę z tabelą podstawową.
Najlepszym podejściem jest rozpoczęcie od podstawowego zestawu reguł, o których wiesz, że są potrzebne, takich jak porównywanie każdej tabeli z tabelą podstawową. Tabela podstawowa powinna być tabelą z najbardziej kompletnymi i dokładnymi danymi. Ta tabela powinna być uporządkowana na górze w kroku ujednolicania reguł dopasowywania.
Stopniowo dodawaj kilka reguł i zobacz, jak długo trwa wprowadzanie zmian i czy Twoje wyniki ulegną poprawie. Przejdź do pozycji Ustawienia>Stan>systemu i wybierz pozycję Dopasuj , aby zobaczyć, jak długo trwała deduplikacja i dopasowywanie dla każdego przebiegu ujednolicania.
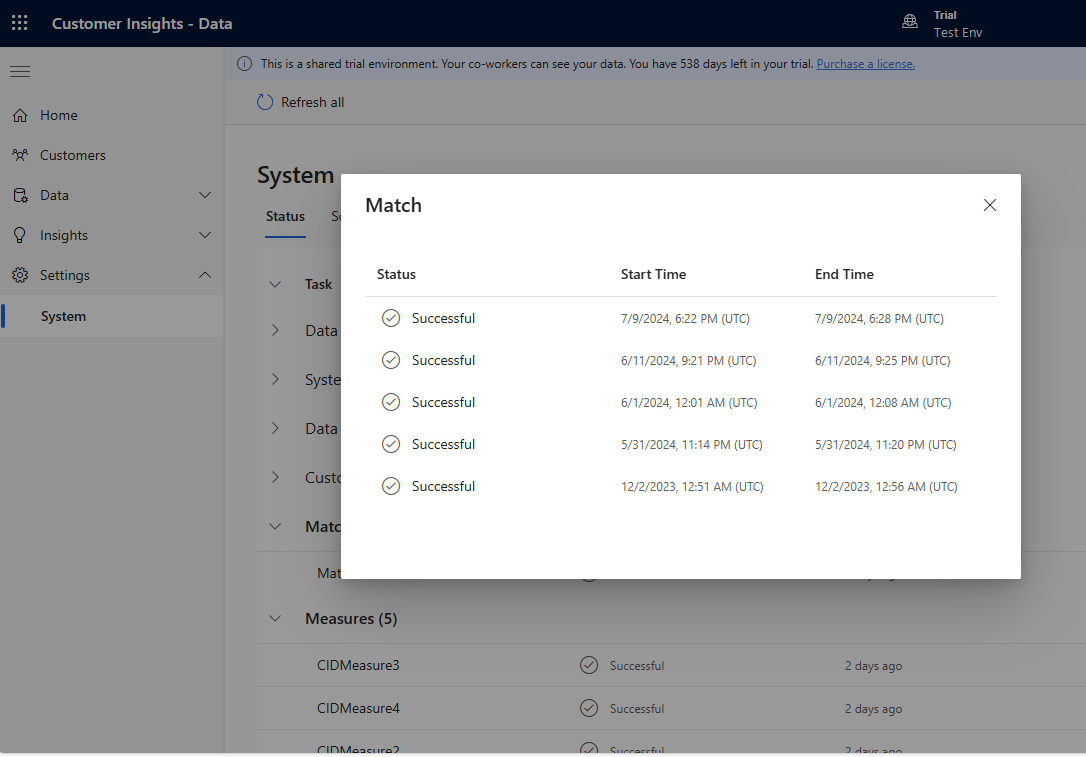
Wyświetl statystyki reguł na stronach Reguły deduplikacji i Reguły dopasowywania, aby sprawdzić, czy liczba unikatowych rekordów uległa zmianie. Jeśli nowa reguła pasuje do niektórych rekordów, a liczba unikatowych rekordów nie ulega zmianie, oznacza to, że poprzednia reguła identyfikuje te dopasowania.
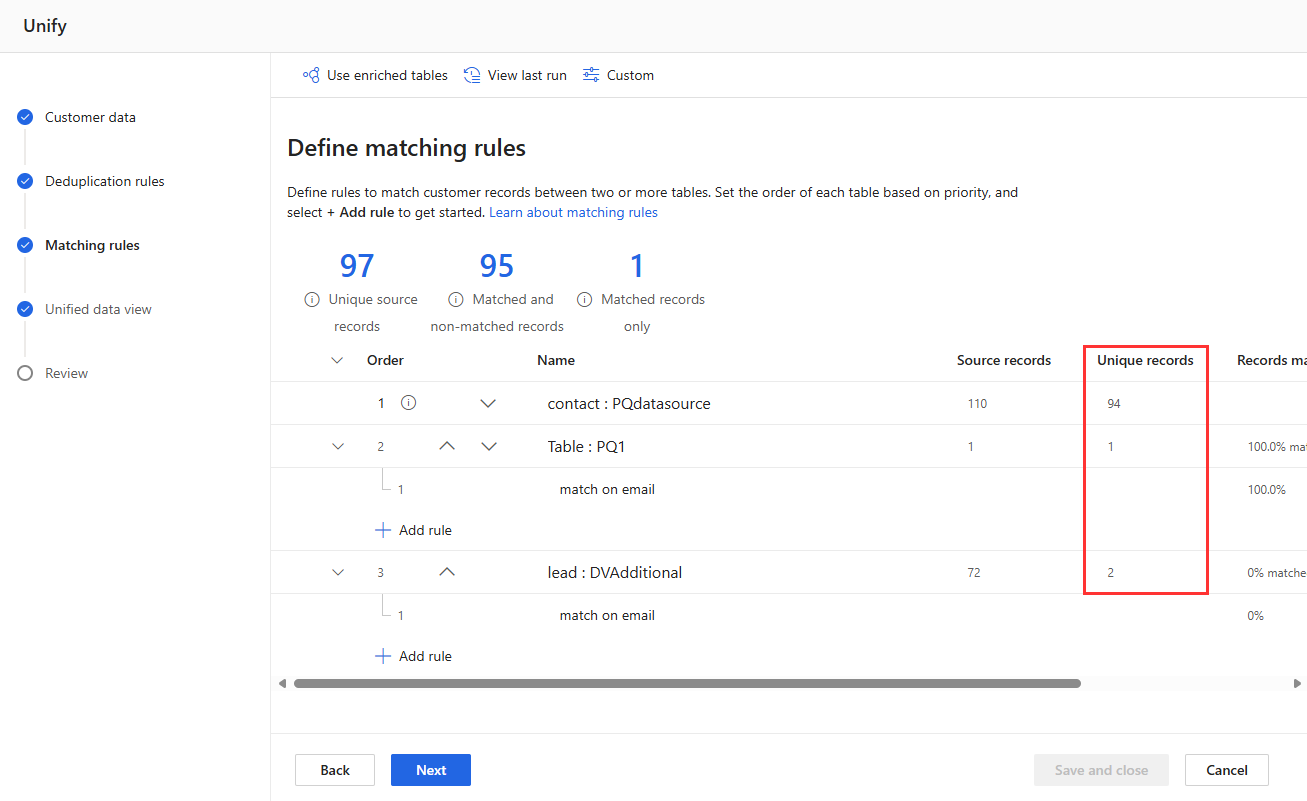
Deduplikacji
Reguły deduplikacji służą do usuwania zduplikowanych rekordów klientów w tabeli, tak aby pojedynczy wiersz w każdej tabeli reprezentował każdego klienta. Dobrym regułą jest zidentyfikowanie unikatowego klienta.
W tym prostym przykładzie rekordy 1, 2 i 3 mają ten sam adres e-mail lub numer telefonu i reprezentują tę samą osobę.
| ID | Nazwa/nazwisko | Phone | |
|---|---|---|---|
| 1 | Osoba 1 | (425) 555-1111 | AAA@A.com |
| 2 | Osoba 1 | (425) 555-1111 | BBB@B.com |
| 3 | Osoba 1 | (425) 555-2222 | BBB@B.com |
| 100 | Osoba 2 | (206) 555-9999 | Person2@contoso.com |
Nie chcemy, aby takie same imię i nazwisko odpowiadało różnym osobom.
Utwórz regułę 1 przy użyciu nazwy i telefonu, która pasuje do rekordów 1 i 2.
Utwórz regułę 2 przy użyciu nazwy i adresu e-mail, która pasuje do rekordów 2 i 3.
Połączenie reguły 1 i reguły 2 powoduje utworzenie jednej grupy dopasowania, ponieważ rekord 2 jest im udostępniania.
Ty decydujesz o liczbie reguł i warunków, które jednoznacznie identyfikują Twoich klientów. Dokładne reguły zależą od dostępnych danych, jakości danych i tego, jak wyczerpujący ma być proces deduplikacji.
Zwycięzca i inne rekordy
Po uruchomieniu reguł i zidentyfikowaniu zduplikowanych rekordów proces deduplikacji wybiera "wiersz zwycięzcy". Wiersze, które nie są zwycięzcami, są nazywane "wierszami alternatywnymi". Wiersze alternatywne są używane w kroku ujednolicania reguł uzgadniania w celu dopasowania rekordów z innych tabel do wiersza zwycięzcy. Wiersze są dopasowane do danych w alternatywnych wierszach oprócz wiersza zwycięzcy.
Po dodaniu reguły do tabeli można skonfigurować, który wiersz ma zostać wybrany jako zwycięski, korzystając z preferencji scalania. Preferencje scalania są ustawione na tabelę. Bez względu na to, jakie zasady scalania są wybrane, jeśli w wierszu zwycięzcy występuje remis, pierwszy wiersz w kolejności danych jest używany jako rozstrzygający.
Normalizacja
Użyj normalizacji, aby ustandaryzować dane w celu lepszego dopasowania. Normalizacja działa dobrze w przypadku dużych zestawów danych.
Znormalizowane dane są wykorzystywane wyłącznie do celów porównawczych, aby skuteczniej dopasować zapisy klientów. Nie spowoduje to zmiany danych w końcowym ujednoliconym profilu klienta.
| Normalizacja | Przykłady |
|---|---|
| Cyfry | Konwertuje wiele symboli Unicode reprezentujących liczby na liczby proste. Przykłady: ❽ i VIII. są znormalizowane do liczby 8. Uwaga: symbole muszą być zakodowane w formacie punktowym Unicode. |
| Symbole | Usuwa symbole i znaki specjalne. Przykłady: !?"#$%&'( )+,.-/:;<=>@^~{}`[ ] |
| Tekst na małe litery | Konwertuje wielkie litery na małe litery. Przykład: "THIS Is aN EXamplE" jest konwertowane na "this is an example" |
| Typ — telefon | Konwertuje telefony w różnych formatach na cyfry i uwzględnia różnice w sposobie prezentowania kodów krajów i rozszerzeń. Przykład: +01 425.555.1212 = 1 (425) 555-1212 |
| Typ — nazwa | Konwertuje ponad 500 odmian nazw zwyczajowych i tytułów. Przykłady: „debby” -> „Deborah”, „prof” i „profesor” -> „Prof.” |
| Typ — adres | Konwertuje wspólne części adresów Przykłady: „ulica” -> „st” i „północny-zachód” -> „pn.-zach.” |
| Typ — organizacja | Usuwa około 50 "szumiących słów" nazw firm, takich jak "co", "corp", "corporation" i "ltd". |
| Unicode na ASCII | Unicode na ASCII: konwertowanie znaków Unicode na ich odpowiednika literowego ASCII Przykład: znaki „à”, „á”, „â”, „À”, „Á”, „”, „Ô, „Ę”, „Ⓐ” i „A” są konwertowane na „a”. |
| Znak odstępu | Usuwa wszystkie białe znaki |
| Mapowanie aliasu | Umożliwia przesłanie niestandardowej listy par ciągów, których można następnie użyć do wskazania ciągów, które zawsze należy uważać za dopasowanie dokładne. Użyj mapowania aliasów, jeśli masz konkretne przykłady danych, które Twoim zdaniem powinny pasować, a które nie są dopasowane przy użyciu jednego z pozostałych wzorców normalizacji. Przykład: Scott and Scooter lub MSFT i Microsoft. |
| Obejście niestandardowe | Umożliwia przesłanie niestandardowej listy ciągów, których można następnie użyć do wskazania ciągów, których nigdy nie należy uważać za dopasowanie. Obejście niestandardowe jest przydatne, gdy masz dane z typowymi wartościami, które należy zignorować, takie jak fikcyjny numer telefonu lub fikcyjny adres e-mail. Przykład: Nigdy nie dopasowuj telefonu 555-1212 lub test@contoso.com |
Dokładne dopasowanie
Użyj precyzji, aby określić, jak blisko siebie powinny znajdować się dwa ciągi, aby można je było uznać za zgodne. Domyślne ustawienie dokładności wymaga dokładnego dopasowania. Każda inna wartość umożliwia dopasowanie rozmyte dla tego warunku.
Precyzję można ustawić na niską (30% dopasowania), średnią (60% dopasowania) i wysoką (80% dopasowania). Możesz też dostosować i ustawić dokładność w krokach co 1%.
Dokładne warunki dopasowania
Dokładne warunki dopasowania są uruchamiane jako pierwsze, aby uzyskać mniejszy zestaw wartości dla dopasowań rozmytych. Aby warunki dokładnego dopasowania były skuteczne, powinny charakteryzować się rozsądnym stopniem niepowtarzalności. Jeśli na przykład wszyscy klienci mieszkają w tym samym kraju/regionie, dokładne dopasowanie w tym kraju nie pomoże zawęzić zakresu.
Kolumny, takie jak pola imienia i nazwiska, adresu e-mail, telefonu lub adresu, mają dobrą unikatowość i są świetnymi kolumnami do użycia jako dokładne dopasowanie.
Upewnij się, że kolumna używana dla warunku dopasowania ścisłego nie zawiera żadnych często powtarzających się wartości, takich jak wartość domyślna "Imię" przechwycona przez formularz. Szczegółowe informacje o klientach mogą profilować kolumny danych, aby zapewnić wgląd w najczęściej powtarzające się wartości. Profilowanie danych można włączyć w połączeniach usługi Azure Data Lake (przy użyciu formatu Common Data Model lub formatu różnicowego) i usłudze Synapse. Profil danych jest uruchamiany, gdy źródło danych jest odświeżane po raz kolejny. Aby uzyskać więcej informacji, przejdź do tematu Profilowanie danych.
Dopasowanie rozmyte
Użyj dopasowania rozmytego, aby dopasować ciągi, które są zbliżone, ale nie są dokładne z powodu literówek lub innych drobnych odmian. Strategicznie używaj dopasowania rozmytego, ponieważ jest ono wolniejsze niż dopasowania dokładne. Upewnij się, że w każdej regule, która zawiera warunki rozmyte, występuje co najmniej jeden warunek dopasowania.
Dopasowanie rozmyte nie jest przeznaczone do przechwytywania odmian imion, takich jak Suzzie i Suzanne. Te odmiany są lepiej uchwycone za pomocą wzorca normalizacji Typ: Nazwa lub niestandardowego dopasowania aliasu, w którym klienci mogą wprowadzić listę odmian nazw, które chcą rozważyć jako dopasowania.
Do reguły można dodać warunki, takie jak dopasowanie wartości Imię i Numer telefonu. Warunki w danej regule są warunkami "AND". Każdy warunek musi być spełniony, aby wiersze były zgodne. Odrębnymi regułami są warunki "OR". Jeśli reguła 1 nie pasuje do wierszy, wiersze są porównywane z regułą 2.
Uwaga
Tylko kolumny typu danych typu ciąg mogą używać dopasowania rozmytego. W przypadku kolumn z innymi typami danych, takimi jak liczba całkowita, podwójna precyzja lub data/godzina, pole precyzji jest tylko do odczytu i ustawione na dokładne dopasowanie.
Rozmyte obliczenia dopasowujące
Dopasowania rozmyte są określane przez obliczenie wyniku odległości edycji między dwoma ciągami. Jeśli wynik osiąga lub przekracza próg precyzji, ciągi są uznawane za zgodne.
Odległość edycji to liczba edycji wymagana do przekształcenia jednego ciągu w inny poprzez dodanie, usunięcie lub zmianę znaku.
Na przykład ciągi "Jacqueline" i "Jaclyne" mają odległość edycji równą pięć, gdy usuniemy znaki q, u, e, i i e i wstawimy znak y.
Aby obliczyć wynik odległości edycji, użyj tego wzoru: (Podstawowa długość ciągu – Edytuj odległość) / Podstawowa długość ciągu.
| Ciąg podstawowy | Ciąg do porównania | Ocena |
|---|---|---|
| Jacqueline | Jaclyne | (10-4)/10=,6 |
| fred@contoso.com | fred@contso.cm | (14-2) / 14 = 0,857 |
| franklin | frank | (8-3) / 8 = 0,625 |