Omówienie zadań importowania i eksportowania danych
Obszar roboczy Zarządzanie danymi umożliwia tworzenie i zarządzanie danymi importu i eksportu zadań. Domyślne proces importowania i eksportowania danych tworzy tabelę przemieszczania dla każdej jednostki w docelowej bazie danych. Tabele przemieszczania umożliwiają sprawdzenie, czyszczenie lub konwersję danych przed ich przeniesieniem.
Uwaga
W tym artykule założono, że znasz koncepcję jednostek danych.
Proces importu/eksportu danych
Poniżej przedstawiono kroki importowania lub eksportowania danych.
Utwórz zadanie importu lub eksportu, w którym należy wykonać następujące zadania:
- Zdefiniuj kategorię projektu.
- Zdefiniuj jednostki do zaimportowania lub wyeksportowania.
- Ustaw format danych zadania.
- Określ kolejność jednostek tak, aby były przetwarzane w grupach logicznych oraz w kolejności, która ma sens.
- Określ, czy mają być używane tabele przemieszczania.
Sprawdź, czy dane źródłowe i dane docelowe są prawidłowo zmapowane.
Sprawdź zabezpieczenia zadania importu lub eksportu.
Uruchom zadanie importu lub eksportu.
Sprawdź, czy zadanie zostało wykonane zgodnie oczekiwaniami, przeglądając historię zadań.
Wyczyść tabele przemieszczania.
Pozostałe sekcje tego artykułu zawierają szczegółowe informacje o każdym kroku procesu.
Uwaga
Aby odświeżyć formularz importu/eksportu danych i zobaczyć aktualny postęp, użyj ikony odświeżania formularza. Nie zalecamy odświeżania na poziomie przeglądarki, ponieważ spowoduje to przerwanie wszystkich zadań importu/eksportu, które nie są wykonywane wsadowo.
Tworzenie zadania importu lub eksportu
Zadanie importu lub eksportu danych może zostać uruchomione raz lub wiele razy.
Definiowanie kategorii projektu
Zalecamy, aby poświęcić czas na wybranie odpowiedniej kategorii projektu dla zadania importu lub eksportu. Kategorie projektu ułatwiają zarządzanie powiązanymi zadaniami.
Zdefiniowanie jednostki do zaimportowania lub wyeksportowania
Do zadania importu lub eksportu można dodać określone jednostki lub wybrać szablon do zastosowania. Szablony umożliwiają wypełnienie zadania listą jednostek. Opcja Zastosuj szablon jest dostępna po nadaniu zadaniu nazwy i jego zapisaniu.
Ustawianie formatu danych zadania
Podczas wybieranie jednostki należy wybrać format eksportowanych lub importowanych danych. Formaty można określić, używając kafelka Ustawienia źródeł danych. Format danych źródłowych jest kombinacją elementów Typ, Format pliku, Separator wiersza i Separator kolumny. Istnieją jeszcze inne, ale te atrybuty są kluczowe do zrozumienia. Poniższa tabela zawiera listę prawidłowych kombinacji.
| Format pliku | Separator wiersza/kolumny | Styl XML |
|---|---|---|
| Plik programu Excel | Plik programu Excel | -ND- |
| Plik XML | -ND- | Element XML Atrybut XML |
| Ograniczone, stała szerokość | Przecinek, średnik, tabulator, pionowa kreska, dwukropek | -ND- |
Uwaga
Ważne jest, aby wybrać poprawną wartość pól Ogranicznik wiersza, Ogranicznik kolumn i Kwalifikator tekstu, jeśli w opcji Format pliku jest ustawiona wartość Ograniczone. Upewnij się, że dane nie zawierają znaku używanego jako ogranicznik lub kwalifikator, ponieważ może to spowodować błędy podczas importowania i eksportowania.
Uwaga
W przypadku formatów plików opartych na XML-u pamiętaj, by używać tylko dozwolonych znaków. Więcej informacji na temat ważnych znaków znajdziesz w dozwolone znaki w XML 1.0. XML 1.0 nie dopuszcza żadnych znaków sterujących z wyjątkiem tabulatorów, powrotów karetki i podawania wierszy. Przykładami niedozwolonych znaków są nawiasy kwadratowe, nawiasy klamrowe i ukośniki.
Aby zaimportować lub wyeksportować dane, użyj Unicode zamiast określonej strony kodowej. Pomaga to zapewnić najbardziej spójne wyniki i wyeliminować zadania zarządzania danymi, ponieważ zawierają znaki Unicode. Zdefiniowane w systemie formaty danych źródłowych, które używają standardu Unicode, mają w nazwie źródła standard Unicode. Format Unicode jest stosowany przez wybranie strony kodowej ANSI kodowania Unicode jako Strony kodowej na karcie Ustawienia regionalne. Wybierz jedną z następujących stron kodów dla Unicode:
| Strona kodowa | Nazwa wyświetlana |
|---|---|
| 1200 | Unicode |
| 12000 | Unicode (UTF-32) |
| 12001 | Unicode (UTF-32 Big-Endian) |
| 1201 | Unicode (Big-Endian) |
| 65 000 | Unicode (UTF-7) |
| 65001 | Unicode (UTF-8) |
Aby uzyskać więcej informacji dotyczących stron kodów, zobacz Identyfikatory stron kodów.
Określanie kolejności jednostek
Kolejność jednostek można określić w szablonie danych albo w zadaniach importu lub eksportu. Po uruchomieniu zadania, które zawiera więcej niż jedną jednostkę należy się upewnić, że kolejność jednostek danych jest prawidłowa. Kolejność jednostek określa się głównie po to, aby obsłużyły zależności funkcjonalne między jednostkami. Jeżeli jednostki nie mają żadnych zależności funkcjonalnych, można zaplanować ich import lub eksport równoległy.
Jednostki wykonywania, poziomy i kolejności
Jednostka wykonywania, poziom w jednostce wykonywania i kolejność jednostek ułatwiają kontrolowanie jakości eksportu lub importu danych.
- W każdej jednostce wykonawczej encje są przetwarzane równolegle.
- W każdej jednostce wykonywania jednostek są przetwarzane równolegle, jeśli mają ten sam poziom.
- Na każdym poziomie jednostki są przetwarzane zgodnie z ich kolejnym numerem na tym poziomie.
- Po przetworzeniu jednego poziomu przetwarzany jest następny.
Zmiana kolejności
Zmiana kolejności jednostek może być konieczna w następujących sytuacjach:
- Jeżeli dla wszystkich zmian używane jest tylko jedno zadanie danych, można użyć opcji zmiany kolejności w celu optymalizacji czasu wykonania pełnego zadania. W takich przypadkach można użyć jednostki wykonywania do reprezentacji modułu, poziomu do reprezentacji obszaru funkcji w module, a kolejności do reprezentacji jednostki. Używając tej metody można pracować równolegle między modułami, ale także pracować kolejno w module. Aby zapewnić powodzenie operacji równoległych, należy uwzględnić wszystkie zależności.
- W przypadku używania wielu zadań danych (na przykład jednego zadania dla każdego modułu) można użyć harmonogramu w celu określenia poziomu i kolejności jednostek i optymalnego wykonania.
- Jeżeli nie ma żadnych zależności, można określić kolejność jednostek w różnych jednostkach wykonywania w celu maksymalnej optymalizacji.
Menu Zmiana kolejności jest dostępne po wybraniu wielu jednostek. Kolejność można zmienić na podstawie opcji jednostki wykonywania, poziomu lub kolejności. Można ustawić przyrost w celu zmiany kolejności wybranych jednostek. Numer jednostki, poziomu i/lub kolejności wybrany dla każdej jednostki zostanie zaktualizowany o określony przyrost.
Sortowanie
Można użyć opcji Sortuj według, aby wyświetlić listę jednostek w odpowiedniej kolejności.
Obcięcie
W projektach importowania można wybrać opcję obcinania rekordów w jednostek przed rozpoczęciem importu. Obcinanie jest przydatne, jeśli rekordy muszą zostać zaimportowane do czystego zestawu tabel. To ustawienie jest domyślnie wyłączone.
Sprawdzanie, czy dane źródłowe i dane docelowe są prawidłowo zmapowane
Mapowanie to funkcja dotycząca zadań importu i eksportu.
- W kontekście zadania importu mapowanie opisuje, które kolumny w pliku źródłowych będą kolumnami w tabeli przemieszczania. Dlatego system może określić, które dane z kolumny w pliku źródłowym muszą zostać skopiowane do kolumny w tabeli przemieszczania.
- W kontekście zadania eksportu mapowanie opisuje, które kolumny w tabeli przemieszczanie (czyli w źródle) będą kolumnami w pliku docelowym.
Jeżeli nazwy kolumn w tabeli przemieszczania oraz w pliku są zgodne, system automatycznie określa mapowanie na podstawie nazw. Jeżeli jednak nazwy różnią się, kolumny nie są mapowane automatycznie. W tych przypadkach należy uzupełnić mapowanie, wybierając opcję Wyświetl mapę dla jednostki w zadaniu danych.
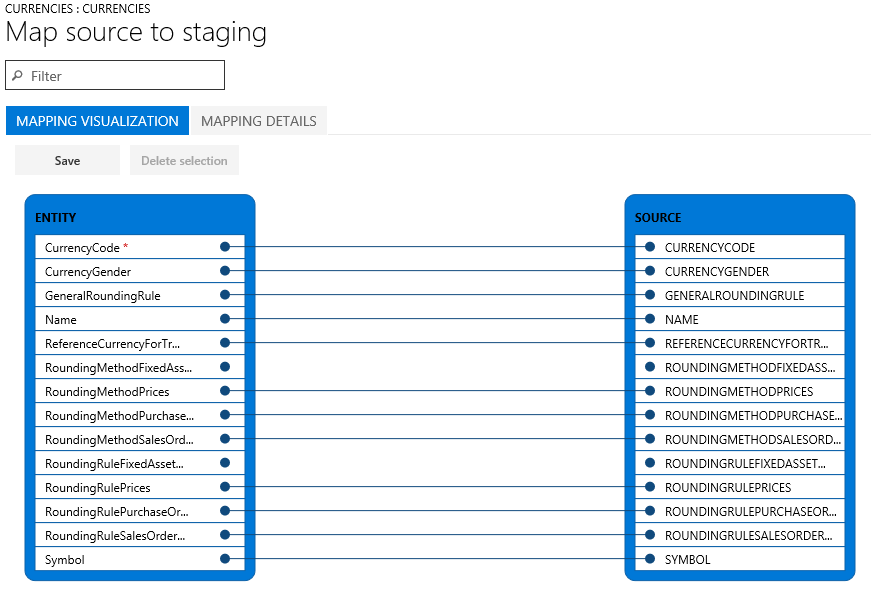
Dostępne są dwa widoki mapowania: Wizualizacja mapowania, czyli widok domyślny i Szczegóły mapowania. Czerwona gwiazdka (*) określa pola wymagane pola w jednostce. Te pola muszą zostać zmapowane przed rozpoczęciem pracy z jednostką. Podczas pracy z jednostką można anulować mapowanie innych pól. Aby anulować mapowanie pola, wybierz pole w kolumnie Jednostka lub kolumnie Źródło, a następnie wybierz opcję Usuń wybór. Wybierz opcję Zapisz, aby zapisać zmiany, a następnie zamknij stronę, aby wrócić do projektu. Ten sam proces umożliwia edycję mapowania pól od źródła do przemieszczania po ukończeniu importu.
Mapowanie można wygenerować na stronie, wybierając opcję Generuj mapowanie źródła. Wygenerowane mapowanie zachowuje się jak mapowanie automatyczne. Dlatego należy ręczne zmapować wszystkie niezmapowane pola.
Sprawdzanie zabezpieczeń zadania importu lub eksportu
Dostęp do obszaru roboczego Zarządzanie danymi można ograniczyć tak, aby użytkownicy inni niż administratorzy mieli dostęp tylko do określonych zadań danych. Dostęp do zadania danych oznacza pełny dostęp do historii wykonania tego zdania i dostęp do tabeli przemieszczania. W związku z tym należy się upewnić, że kontrola dostępu odpowiednie obowiązują podczas tworzenia zadania danych.
Zabezpieczanie zadania według ról i użytkowników
Skorzystaj z menu Odpowiednie role, aby ograniczyć zadanie do jeden lub kilku ról zabezpieczeń. Dostęp do tego zadania będą mieli tylko użytkownicy o tych rolach.
Zadanie można także ograniczyć do określonych użytkowników. Zabezpieczenie zadania według użytkowników zamiast według ról ułatwia sprawdzenie, czy wielu użytkowników jest przypisanych do roli.
Zabezpieczanie zadania według firm
Zadania danych mają charakter globalny. Dlatego, jeżeli zadanie danych zostało utworzone i użyte w firmie, będzie widoczne w innych firmach w systemie. To domyślne zachowanie może być preferowane w niektórych scenariuszach aplikacji. Przykładowo organizacja, która importuje faktury za pomocą jednostek danych może korzystać z centralnego zespołu przetwarzania faktur odpowiedzialnego za zarządzanie błędami w fakturach we wszystkich oddziałach organizacji. W tym scenariuszy przydatny dla centralnego zespołu przetwarzania faktur jest dostęp do zadań importu faktur ze wszystkich firm. Dlatego zachowanie domyślne spełnia wymagania z punktu widzenia firmy.
Jednak w organizacji może być preferowane posiadanie zespołu przetwarzania faktur w każdej firmie. W takim przypadku zespół w firmie powinien mieć dostęp tylko do zadania importu faktur we własnej firmie. W celu spełnienia tego wymagania można skonfigurować kontrolę dostępu do zadań danych na podstawie firmy, używając menu Odpowiednie firmy w zadaniu danych. Po ukończeniu konfiguracji użytkownicy widzą tylko te zadania, które są dostępne w firmie, w której są aktualnie zalogowani. Aby zobaczyć zadania z innej firmy, użytkownicy muszą przełączyć się na tę firmę.
Zadanie można jednocześnie zabezpieczyć według ról, użytkowników i firm.
Uruchamianie zadania importu lub eksportu
Zadanie można uruchomić jeden raz, klikając przycisk Importuj lub Eksportuj po zdefiniowaniu zadania. Aby skonfigurować zadanie cykliczne, wybierz opcję Utwórz cykliczne zadanie danych.
Uwaga
Zadania importu i eksportu mogą być włączane za pomocą przycisku importuj lub Eksportuj. Spowoduje to zaplanowanie uruchomienia zadania wsadowego tylko raz. Zadanie może nie zostać wykonane natychmiast, jeśli usługa wsadowa jest ograniczana z powodu ładunku w usłudze przetwarzania wsadowego. Zadania można również uruchamiać synchronicznie, wybierając Importuj teraz lub Eksportuj teraz. Powoduje to natychmiastowe włączenie zadania i jest przydatne, jeśli z powodu ograniczeń nie można uruchomić zadania wsadowego. Zadania mogą być również zaplanowane do wykonania w późniejszym czasie. Można to zrobić, wybierając opcję Uruchom w partii. Zasoby przetwarzania wsadowego podlegają ograniczeniom, więc zadanie wsadowe może nie rozpocząć się natychmiast. Użycie przetwarzania wsadowego jest zalecaną opcją, ponieważ umożliwia także tworzenie dużych ilości danych, które wymagają zaimportowania lub wyeksportowania. Zadania wsadowe można zaplanować pod kątem uruchomienia w grupie określonej partii, co daje większą kontrolę z perspektywy równoważenia obciążenia.
Sprawdzanie, czy zadanie zostało uruchomione zgodnie z oczekiwaniami
Dostępna jest historia zadań umożliwiająca rozwiązywanie problemów i badanie zadań importu i eksportu. Historyczne uruchomienia zadań są zorganizowane według zakresów czasu.
Dla każdego uruchomionego zadania dostępne są następujące informacje:
- Szczegóły wykonania
- Dziennik wykonywania
Szczegóły wykonania pokazują stan każdej jednostki danych przetworzonych przez zadanie. Dlatego można szybko znaleźć następujące informacje:
- Jednostki przetworzone.
- Ile rekordów zostało pomyślnie przetworzonych, a przetworzenie ilu nie powiodło się dla każdej jednostki.
- Rekordy przemieszczania dla każdej jednostki.
Dane przemieszczania można pobrać w pliku dla zadań eksportu lub pobrać je jako pakiet dla zadań importu i eksportu.
W oknie szczegółów wykonania można także otworzyć dziennik wykonania.
Import równoległy
Aby przyspieszyć Importowanie danych, można włączyć równoległe przetwarzanie importu pliku, jeśli jednostka obsługuje import równoległy. Aby skonfigurować import równoległy dla jednostki, należy zastosować następujące kroki:
Wybierz kolejno opcje Administrowanie systemem > Obszary robocze > Zarządzanie danymi.
W sekcji Import/eksport wybierz kafelek Parametry struktury, aby otworzyć stronę Parametry importu/eksportu danych.
Na karcie Ustawienia jednostki wybierz opcję Konfiguruj parametry wykonania jednostki, aby otworzyć stronę Parametry wykonywania importu jednostki.
Aby skonfigurować import równoległy dla jednostki, należy skonfigurować następujące pola:
- W polu Jednostka wybierz jednostkę. Jeśli pole jednostki jest puste, pusta wartość jest używana jako ustawienie domyślne dla wszystkich kolejnych importów, jeśli jednostka obsługuje import równoległy.
- W polu Licznik rekordów progów importu wprowadź wartość licznika rekordów progu dla importu. Określa to licznik rekordów, które mają być przetworzone przez wątek. Jeśli plik ma 10 000 rekordów, liczba rekordów 2500 i liczba zadań 4 będą oznaczały, że każdy wątek przetworzy 2500 rekordów.
- W polu Licznik importu zadań wprowadź liczbę zadań importu. Nie może ona przekraczać maksymalnej liczby wątków wsadowych przydzielonych do przetwarzania wsadowego w Administrowanie systemem >Konfigurowanie serwera.
Uwaga
Dodanie zbyt wielu równoległych zadań powoduje, że infrastruktura bazowa wykorzystuje pojemność zasobów w 100% i wpływa na wydajność środowiska i inne operacje. Zaleca się zrozumienie pojemności zasobów środowiska i zużycia w oparciu o skonfigurowane zadania importu równoległego i ograniczenie liczby zadań.
Czyszczenie historii zadań
Domyślnie wpisy historii stanowisk pracy i powiązane dane tabeli przemieszczania starsze niż 90 dni są automatycznie usuwane. Funkcji czyszczenia historii zadań w zarządzaniu danymi można użyć do skonfigurowania okresowego czyszczenia historii wykonania z krótszym okresem przechowywania niż domyślny. Ta funkcja zastępuje poprzednią funkcję oczyszczania tabeli przemieszczania, która jest obecnie przestarzała. Poniższe tabele zostaną oczyszczone przez proces oczyszczania.
Wszystkie tabele przemieszczania
DMFSTAGINGVALIDATIONLOG
DMFSTAGINGEXECUTIONERRORS
DMFSTAGINGLOGDETAIL
DMFSTAGINGLOG
DMFDEFINITIONGROUPEXECUTIONHISTORY
DMFEXECUTION
DMFDEFINITIONGROUPEXECUTION
Dostęp do funkcji Czyszczenie historii wykonywania można uzyskać z Zarządzanie danymi > Czyszczenie historii zadań.
Parametry planowania
Podczas planowania procesu oczyszczania, należy określić następujące parametry, aby zdefiniować kryteria oczyszczania.
Liczba dni do zachowania historii — to ustawienie służy do kontrolowania ilości historii wykonywania, która ma zostać zachowana. Historia jest to określana liczbą dni. Gdy zadanie oczyszczania jest zaplanowane jako cykliczne zadanie wsadowe, to ustawienie będzie działać jak stale przesuwające się okno, tym samym zawsze pozostawiając historię dla określonej liczby dni w stanie nienaruszonym i usuwając resztę. Wartość domyślna to siedem dni.
Liczba godzin do wykonania zadania — w zależności od ilości historii do oczyszczenia całkowity czas wykonania zadania oczyszczania może wynosić od kilku minut do kilku godzin. Ten parametr musi być określony jako liczba godzin wykonywania zadania. Gdy zadanie oczyszczania zostanie wykonane przez określoną liczbę godzin, zadanie zostanie zakończone i wznowi oczyszczanie przy następnym uruchomieniu na podstawie harmonogramu cyklu.
Maksymalny czas wykonywania można określić przez ustawienie maksymalnego limitu liczby godzin działania zadania przy użyciu tego ustawienia. Logika oczyszczania analizuje po jednym identyfikatorze wykonywania zadania w sekwencji chronologicznej, w której jako pierwszy oczyszczane są najstarsza powiązana historia uruchamiania. Zbieranie nowych identyfikatorów wykonywania podczas oczyszczania zatrzyma się, gdy pozostały czas wykonywania jest w zakresie ostatnich 10% określonego czasu trwania. W niektórych przypadkach zadanie oczyszczania będzie mogło trwać dłużej niż określony maksymalny czas trwania. Będzie to w dużej mierze zależeć od liczby rekordów, które mają zostać usunięte dla bieżącego identyfikatora wykonania, który został uruchomiony przed osiągnięciem progu 10%. Oczyszczanie, który zostało uruchomione, musi zostać dokończone, aby zapewnić integralność danych, co oznacza, że oczyszczanie będzie kontynuowane pomimo przekroczenia określonego limitu czasu. Po zakończeniu, nowe identyfikatory wykonywania nie są pobierane i zadanie oczyszczania jest kończone. Pozostała historia wykonania, która nie została wyczyszczona ze względu na brak wystarczającej ilości czasu wykonania, zostanie pobrana przy następnym zaplanowanym zadaniu oczyszczania. Wartość domyślna i minimalna dla tego ustawienia jest ustawiona na 2 godziny.
Partia cykliczna — zadanie oczyszczania można uruchomić jako jednorazowe, ręczne wykonanie lub może być również zaplanowane do cyklicznego wykonywania w partii. Partia może być zaplanowana przy użyciu ustawienia Uruchom w tle, co jest standardową konfiguracją partii.
Uwaga
Jeśli funkcja czyszczenia historii zadań nie jest używana, historia wykonania starsza niż 90 dni jest nadal automatycznie usuwana. Oprócz automatycznego usuwania można uruchomić czyszczenie historii zadań. Upewnij się, że zadanie czyszczenia jest zaplanowane i cyklicznie powtarzane. Jak to wyjaśniono powyżej, w każdym wykonaniu zadania oczyszczania jest oczyszczanych tyle identyfikatorów wykonania, ile to możliwe w podanym maksymalnym limicie godzin.
Czyszczenie i archiwizacja historii zadań
Funkcja oczyszczania i archiwizacji historii zadań zastępuje poprzednie wersje funkcji oczyszczania. Ta sekcja wyjaśnia te nowe możliwości.
Jedną z głównych zmian funkcji oczyszczania jest użycie w systemie zadania wsadowego do oczyszczenia historii. Użycie systemowego zadania wsadowego umożliwia aplikacjom finansowym i operacyjnym automatyczne planowanie i uruchamianie zadania przetwarzania wsadowego zaraz po gotowości systemu. Nie jest już konieczne ręczne planowanie zadania wsadowego. W tym domyślnym trybie wykonywania zadanie wsadowe będzie wykonywane co godzinę, zaczynając o północy, i zachowa historię wykonania z ostatnich 7 dni. Oczyszczana historia jest archiwizowana do przyszłego pobierania. Począwszy od wersji 10.0.20, ta funkcja jest zawsze w użyciu.
Druga zmianą w procesie oczyszczania jest archiwizacja oczyszczonej historii wykonania. Zadanie oczyszczania spowoduje zarchiwizowanie usuniętych rekordów w Blob Storage, którego usługa DIXF używa do regularnych integracji. Zarchiwizowany plik będzie w formacie pakietu DIXF i będzie dostępny przez 7 dni w obiekcie blob, w trakcie których można go będzie pobrać. Domyślną trwałość 7 dni zarchiwizowanego pliku można zmienić na maksymalnie 90 dni w parametrach.
Zmienianie domyślnych ustawień
Ta funkcja jest obecnie w wersji zapoznawczej i musi być jawnie włączona przez włączenie lotu DMFEnableExecutionHistoryCleanupSystemJob. Funkcja oczyszczania przemieszczania musi również być włączona w zarządzaniu funkcjami.
Aby zmienić domyślne ustawienie trwałości zarchiwizowanego pliku, przejdź do obszaru roboczego zarządzania danymi i wybierz opcję Czyszczenie historii zadań. Należy skonfigurować Dni przechowywania pakietu w obiekcie blob jako wartość z przedziału od 7 do 90 (włącznie). Ma to wpływ na archiwa utworzone po wykonaniu tej zmiany.
Pobieranie zarchiwizowanego pakietu
Ta funkcja jest obecnie w wersji zapoznawczej i musi być jawnie włączona przez włączenie lotu DMFEnableExecutionHistoryCleanupSystemJob. Funkcja oczyszczania przemieszczania musi również być włączona w zarządzaniu funkcjami.
Aby pobrać zarchiwizowaną historię wykonania, przejdź do obszaru roboczego zarządzania danymi i wybierz opcję Czyszczenie historii zadań. Wybierz Historia kopii zapasowej pakietu, aby otworzyć formularz Historia. W tym formularzu jest wyświetlana lista wszystkich zarchiwizowanych pakietów. Archiwum można wybrać i pobrać, wybierając Pobierz pakiet. Pobrany pakiet jest w formacie pakietu DIXF i zawiera następujące pliki:
- Plik tabeli przemieszczania jednostki
- DMFDEFINITIONGROUPEXECUTION
- DMFDEFINITIONGROUPEXECUTIONHISTORY
- DMFEXECUTION
- DMFSTAGINGEXECUTIONERRORS
- DMFSTAGINGLOG
- DMFSTAGINGLOGDETAILS
- DMFSTAGINGVALIDATIONLOG
Sortowanie złożonych danych encji przy użyciu xslt
Ta funkcjonalność pozwala wyeksportować złożoną encję i zastosować plik xslt do sortowania danych w pliku xml.
Aby posortować złożone dane encji za pomocą xslt, wykonaj następujące kroki.
- Utwórz plik xslt, aby posortować dane w formacie XML. Na przykład, jeśli masz plik XSLT dla encji dostepnej domyślnie Purchase orders composite V3, możesz posortować dane w formacie atrybutów XML w kolejności według INVOICEVENDORACCOUNTNUMBER dla PURCHPURCHASEORDERHEADERV2ENTITY i w kolejności według LINENUMBER dla PURCHPURCHASEORDERLINEV2ENTITY.
<xsl:stylesheet version='1.0' xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="/*">
<xsl:copy>
<xsl:apply-templates select="@*" />
<xsl:apply-templates>
<xsl:sort select="@INVOICEVENDORACCOUNTNUMBER" data-type="text" order="ascending" />
</xsl:apply-templates>
</xsl:copy>
</xsl:template>
<xsl:template match="PURCHPURCHASEORDERHEADERV2ENTITY">
<xsl:copy>
<xsl:apply-templates select="@*"/>
<xsl:apply-templates select="*">
<xsl:sort select="@LINENUMBER" data-type="number" order="descending"/>
</xsl:apply-templates>
</xsl:copy>
</xsl:template>
<xsl:template match="@*|node()">
<xsl:copy>
<xsl:apply-templates select="@*|node()"/>
</xsl:copy>
</xsl:template>
</xsl:stylesheet>
- Otwórz obszar roboczy Zarządzanie danymi.
- Z listy projektów eksportu danych wybierz projekt ze źródłem danych XML i wybierz Wyświetl mapę.
- Wybierz Wyświetl mapę dla dowolnej encji.
- Wybierz kartę Przekształcenia
- Wybierz Nowa i prześlij plik xslt utworzony w kroku 1.