Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W tym artykule omówiono matryce pomyłek, problemy z klasyfikacją i dokładność w modelach uczenia maszynowego. Celem jest zwiększenie zrozumienia dokładności w wynikach przewidywania uczenia maszynowego. Docelowi odbiorcy to m.in. inżynierowie, analitycy i menedżerowie, którzy chcą zdobywać wiedzę i umiejętności w dziedzinie nauki o danych.
Matryca pomyłek
Po wytrenowaniu nadzorowanego problemu uczenia maszynowego na zestawie danych historycznych jest on testowany przy użyciu danych wstrzymanych z procesu trenowania. W ten sposób można porównywać przewidywania z wytrenowanego modelu z rzeczywistymi wartościami. Matryca pomyłek stanowi sposób oceniania skuteczności problemu z klasyfikacją, a także jego błędów (to znaczy, kiedy „myli się”).
Na przykład mamy przewidzieć, czy zwierzę to pies czy kot, na podstawie pewnych fizycznych i behawioralnych atrybutów. Jeśli mamy zestaw danych testowych zawierający 30 psów i 20 kotów, to matryca pomyłek może wyglądać jak na poniższej ilustracji.
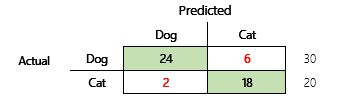
Liczby w zielonych komórkach reprezentują prawidłowe przewidywania. Jak widać, model poprawnie przewiduje wyższy procent kotów. Ogólna dokładność modelu jest łatwa do obliczenia. W tym przypadku jest to 42 ÷ 50 lub 0,84.
Klasyfikatory wieloklasowe w matrycy pomyłek
Większość dyskusji na temat matrycy pomyłek skupia się na klasyfikatorach binarnych, tak jak w poprzednim przykładzie. Tutaj jest szczególny przypadek, w którym można brać pod uwagę inne metryki, takie jak np. czułość i trafność.
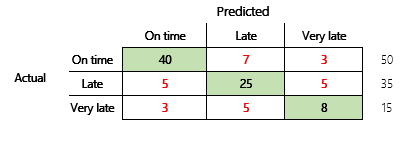
Następnie będziemy rozważać problem z klasyfikacją na przypadku scenariusza finansowego z trzema stanami Model przewiduje, czy faktura od odbiorcy będzie opłacona na czas, późno czy bardzo późno. Na przykład z 100 faktur testowych, 50 jest opłaconych na czas, 35 są spóźnione, a 15 jest opłaconych bardzo późno. W takim przypadku model może wygenerować matrycę pomyłek przypominającej poniższą ilustrację.
 ]
]
Matryca pomyłek zawiera znacznie więcej informacji niż metryka o prostej dokładności. Jest to jednak nadal stosunkowo łatwe do zrozumienia. Matryca pomyłek mówi, czy zestaw danych jest zrównoważony, czyli klasy wyjściowe mają podobne zliczenia. W przypadku scenariusza wieloklasowego użytkownik określa, jak daleko może mylić się przewidywanie, jeśli klasy wyjściowe są porządkowe, tak jak w poprzednim przykładzie dotyczącymi płatności od odbiorców.
Dokładność modelu
Różne metryki dokładności służą do określania ilościowego jakości modelu.
Ponieważ dokładność jest łatwa do zrozumienia, jest to dobry punkt wyjścia do wyjaśnienia modelu innym osobom, szczególnie użytkownikom modelu, którzy nie znają się na nauce o danych. Nie jest wymagane zrozumienie statystyk w celu zrozumienia dokładności modelu. Gdy jest dostępna matryca pomyłek, ułatwia uzyskanie szczegółowych informacji o działaniu modelu.
Jednak w celu dokładniejszego zrozumienia należy pamiętać o kilka wyzwaniach związanych z dokładnością. Użyteczność metryki zależy od kontekstu problemu. Pytanie, które często pojawia się w związku z wydajnością modelu, to: „Jak dobrze jest z modelem?” Jednak odpowiedź na to pytanie nie musi być jednoznaczna. Rozważmy następującą matrycę pomyłek (model 2).
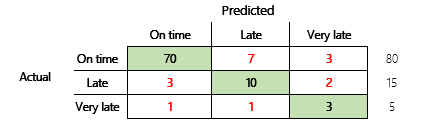
Szybkie obliczenie wskazuje, że dokładność tego modelu wynosi (70 + 10 + 3) ÷ 100 lub 0,83. Pozornie ten wynik jest lepszy niż wynik poprzedniego modelu wieloklasowego (model 1) o dokładności 0,73. Ale czy jest to lepsze?
Aby zacząć odpowiadać na to pytanie, należy wziąć pod uwagę dokładność naiwnego przypuszczenia. W przypadku problemu z klasyfikacją proste przypuszczenie zawsze będzie przewidywać najbardziej typową klasę. W modelu 1 będzie to przypuszczenie „na czas”, a jego dokładność wyniesie 0,50. Przypuszczenie w modelu 2 będzie także „na czas”, a jego dokładność wyniesie 0,80. Ponieważ model 1 poprawia naiwne przypuszczenie o 0,73 — 0,50 = 0,23, a model 2 poprawie naiwne przypuszczenie o 0,83 — 0,80 = 0,03, model 1 jest lepszym modelem, nawet jeśli ma niższą dokładność. Obliczenie ujawnia, że efektywna ocena jakości modelu wymaga większego kontekstu niż wartość dokładności.
Warto zwrócić uwagę na inny aspekt. Rozważmy scenariusz, w którym jest używany test medyczny w celu wykrycia choroby u pacjenta. Ten problem jest problemem z klasyfikacją binarną, w którym pozytywny wynik wskazuje, że pacjent ma tę chorobę. W tym scenariuszu należy wziąć pod uwagę wpływ następujących błędów:
- Fałszywie pozytywne, gdy test mówi, że pacjent ma chorobę, ale tak naprawdę pacjent jej nie ma.
- Fałszywe negatywy, w przypadku których test mówi, że pacjent nie ma choroby, ale pacjent naprawdę ją ma.
Oczywiście, oba typy błędów są niepożądane, ale który jest gorszy? Znowu, to zależy. W przypadku choroby zagrażającej życiu, która wymaga szybkiego leczenia, minimalizacja fałszywych wyników ujemnych (po których powinny nastąpić dodatkowe testy) ma pierwszeństwo. W innych, mniej krytycznych sytuacjach, twórcy modelu mogą natomiast minimalizować fałszywe dodatnie wyniki. W każdym razie racjonalny wniosek jest taki, że aby skutecznie ustalić jakość modelu, trzeba mieć więcej informacji niż zapewnia metryka dokładności.
Rekomendacje
Dokładność to ważne narzędzie komunikacji z ekspertami, którzy nie znają się na statystyce. Jednak, aby informacje były użyteczne, należy zapewnić dodatkowy kontekst wraz z wartością dokładności.
W scenariuszu przewidywania płatności można określić cel dla modelu uczenia maszynowego, który zawiera współczynniki w różnych zachowaniach płatności. Celem tego modelu powinno być poprawienie naiwnego przypuszczenia przez zmniejszenie liczby nieprawidłowych odpowiedzi o co najmniej 50 procent. Inaczej mówiąc, należy określić docelową dokładność, która dzieli różnicę między dokładnością naiwnego przypuszczenia a 100 procent.
Poniższa tabela podsumowuje tę zasadę dla matryc pomyłek w tym artykule.
| Model | Naiwne przypuszczenie | Cel | Dokładność modelu | Czy cel został osiągnięty? |
|---|---|---|---|---|
| Model 1 | 0.50 | 0.75 | 0.73 | Prawie. Ten model znacznie poprawia przypuszczenie. |
| Model 2 | 0.80 | 0.90 | 0.83 | Nr Wymagana jest poprawa. |
Dokładność klasyfikacji F1
Ostatnim rozważaniem w tym artykule jest bardziej zaawansowana miara skuteczności klasyfikacji uczenia maszynowego, określana jako dokładność F1.
Przed zdefiniowaniem dokładności F1 należy wprowadzić dwie dodatkowe metryki: precyzję i trafność. Precyzja wskazuje, ile z łącznej liczby przewidywań określonych jako dodatnie jest prawidłowo przypisanych. Ta metryka jest również określana jako dodatnia wartość predykcyjna. Trafność to łączna liczba rzeczywistych pozytywnych przypadków, które zostały prawidłowo przewidziane. Ta metryka jest również określana jako czułość.
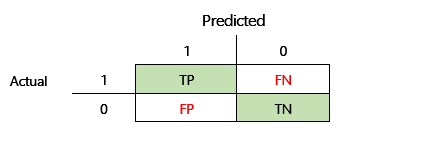
W matrycy pomyłek na powyższej ilustracji, te metryki są obliczane w następujący sposób:
- Precyzja = TP ÷ (TP + FP)
- Trafność = TP ÷ (TP + FN)
Miara F1 łączy precyzję i trafność. Wynik jest średnią harmoniczną dwóch wartości. Jest on obliczany w następujący sposób:
- F1 = 2 × (precyzja × trafność) ÷ (precyzja + trafność)
Przyjrzyjmy się konkretnemu przykładowi. Wcześniej w tym artykule mieliśmy przykład modelu, który przewiduje, czy zwierzę jest psem czy kotem. W tym miejscu ilustracja jest powtórzona.
Oto wyniki, jeśli jako odpowiedź pozytywną przyjmiemy „pies”.
- Precyzja = 24 ÷ (24 + 2) = 0,9231
- Trafność = 24 ÷ (24 + 6) = 0,8
- F1 = 2 × (0,9231 × 0,8) ÷ (0,9231 + 0,8) = 0,8572
Jak widać, wartość F1 jest pomiędzy wartościami precyzji i trafności.
Chociaż dokładność F1 nie jest łatwa w zrozumieniu, dodaje niuans do prostej liczby dokładności. Może również być przydatna w przypadku niezrównoważonych zestawów danych, jak w następnej dyskusji.
Sekcja Dokładność modelu w tym artykule porównuje następujące dwie matryce pomyłek. Nawet jeśli pierwszy model miał niższą dokładność, uznano, że jest bardziej przydatny, ponieważ wykazał się lepszą poprawą domyślnego przypuszczenia płatności na czas.
Zobaczmy, jak te dwa modele są porównywane w przypadku użycia wyniku F1. Wynik F1 mierzy precyzję i trafność poszczególnych stanów, a obliczenia w makrze F1 następnie uśredniają wynik F1 różnych stanów, aby określić ogólny wynik F1. Istnieją inne warianty F1, ale jest bardziej przydatne, aby wziąć pod uwagę wersję makro, ze względu na równe znaczenie przypisywane wszystkim trzem stanom.
Aby uprościć obliczenia, skonstruowano tablice przykładowe w celu dopasowania wartości rzeczywistych i przewidywanych. W tych tablicach użyto biblioteki metryk sklearn w Python w celu obliczenia wartości. Oto wynik.
| Model | Naiwne przypuszczenie | Dokładność | Makro F1 |
|---|---|---|---|
| Model 1 | 0.5 | 0.73 | 0.67 |
| Model 2 | 0.80 | 0.83 | 0.66 |
Więcej szczegółowych informacji o sposobach działania tego obliczenia zawiera niniejszy raport klasyfikacji sklearn.metrics dla modelu 1. Trzy stany, „Na czas”, „Z opóźnieniem” i „Z dużym opóźnieniem” są reprezentowane przez wiersze o numerach 1, 2 i 3. Średnia makro jest tylko średnią z kolumny „Wynik F1”.
| precyzja | trafność | wynik F1 | |
|---|---|---|---|
| 1 | 0.83 | 0.80 | 0.82 |
| 2 | 0.68 | 0.71 | 0.69 |
| 3 | 0.50 | 0.50 | 0.50 |
Jak pokazują te wyniki, dwa modele mają niemal identyczne wyniki dokładności makra F1. W tym i wielu innych przypadkach dokładność F1 stanowi lepszy wskaźnik zdolności modelu. Jeśli chodzi o dokładność, interpretacja wyników wymaga zrozumienia, co należy przede wszystkim rozważyć w modelu.