Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Dotyczy:✅ Inżynieria danych sieci szkieletowej i nauka o danych
Profile zasobów w Inżynierii Danych Fabric pomagają uzyskać zoptymalizowane konfiguracje obliczeniowe Spark bez ręcznego dostrajania. Obciążenie można opisać, wybierając podstawowy przypadek użycia, ilość danych i kilka innych danych wejściowych wysokiego poziomu. Następnie "Fabric" generuje zalecaną konfigurację — w tym rozmiary węzłów, ustawienia automatycznego skalowania i wersję środowiska uruchomieniowego — na podstawie sprawdzonych najlepszych praktyk oraz wewnętrznych danych dotyczących wydajności.
Dlaczego warto używać profilów zasobów
Profile zasobów zapewniają:
- Zoptymalizowane od początku: Pierwsza sesja platformy Spark jest uruchamiana na obliczeniach dostosowanych do obciążenia — nie jest wymagana iteracyjna analiza porównawcza.
- Spójność: wszystkie zadania platformy Spark w obszarze roboczym mają taką samą konfigurację dostrajaną do wydajności.
- Lepsza wydajność cenowa: zasoby o odpowiednich rozmiarach zmniejszają straty i zwiększają przepływność.
- Mniejsze obciążenie operacyjne: mniejsza liczba cykli dostrajania i mniejsza liczba eskalacji pomocy technicznej.
Wymagania wstępne
Aby skonfigurować profile zasobów, musisz mieć rolę administratora dla obszaru roboczego.
Konfigurowanie profilu zasobu
Aby skonfigurować profil zasobu dla obszaru roboczego:
Przejdź do obszaru roboczego i wybierz pozycję Ustawienia obszaru roboczego.
Rozwiń Inżynieria danych/Nauka w lewym panelu, a następnie wybierz Ustawienia Spark.
Aby uzyskać zalecaną konfigurację obliczeniową w celu zoptymalizowania użycia zasobów, w obszarze Optymalizowanie przypadku użycia wybierz pozycję Rozpocznij.
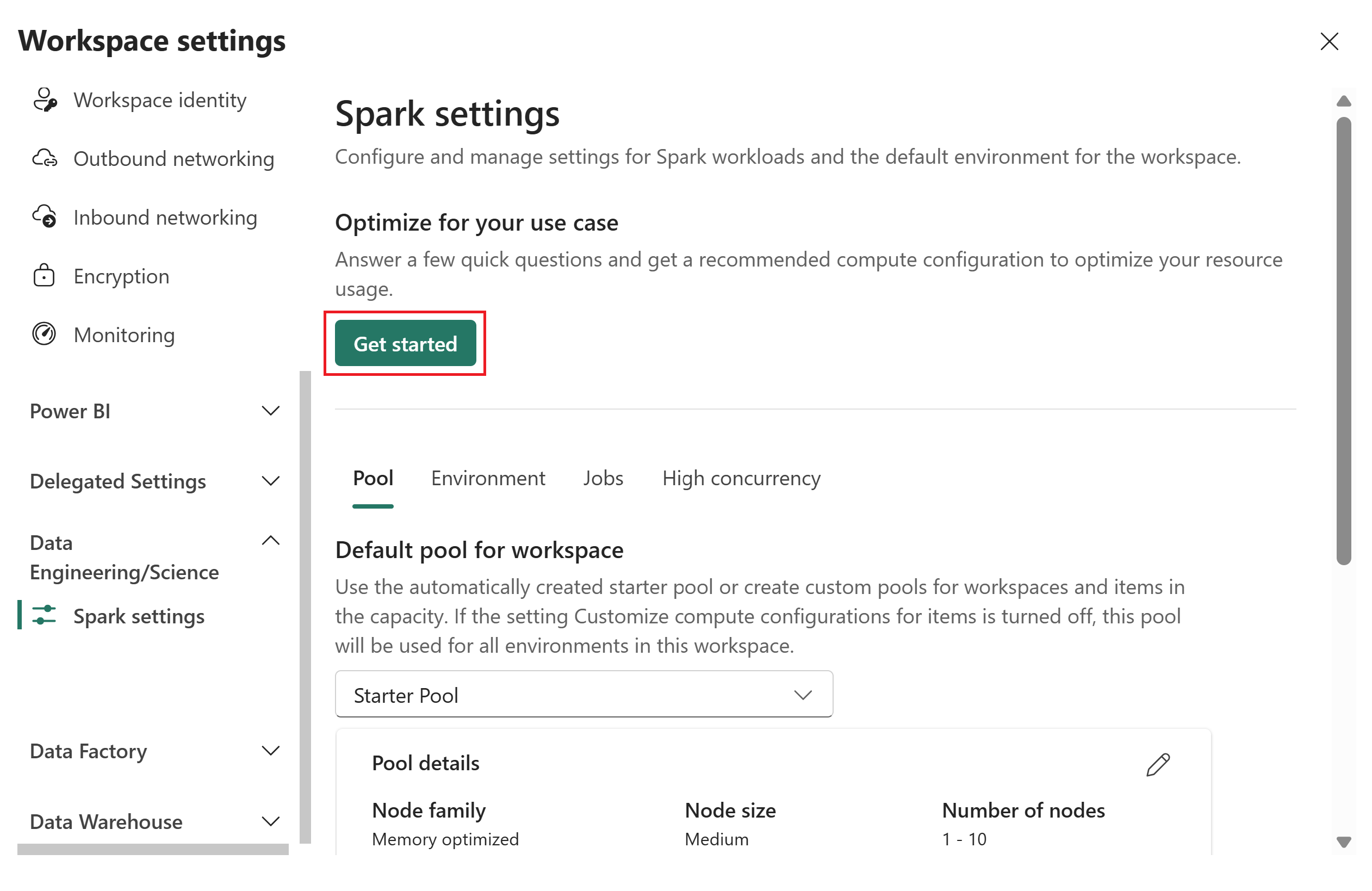
Na stronie Optymalizacja pod kątem przypadku użycia podaj następujące dane wejściowe:
- Przypadek użycia podstawowego: wybierz warstwę medalionu lub opartą na zadaniu, a następnie wybierz określoną opcję z listy rozwijanej. Opcje warstwy medalonu to Brązowa, Srebrna lub Złota. Opcje oparte na zadaniach są zoptymalizowane pod kątem odczytu lub zoptymalizowane pod kątem zapisu. Aby uzyskać wskazówki dotyczące wybierania przypadku użycia, zobacz Dokumentację podstawowego przypadku użycia.
- Typowy wolumin danych: wybierz wolumin z listy rozwijanej: do 1 GB, 10 GB, 100 GB, 1 TB lub ponad 1 TB.
- Maksymalna liczba jednostek pojemności (CU): użyj suwaka, aby ustawić maksymalny limit CU dla puli Spark.
Wybierz pozycję Pobierz zalecenie.
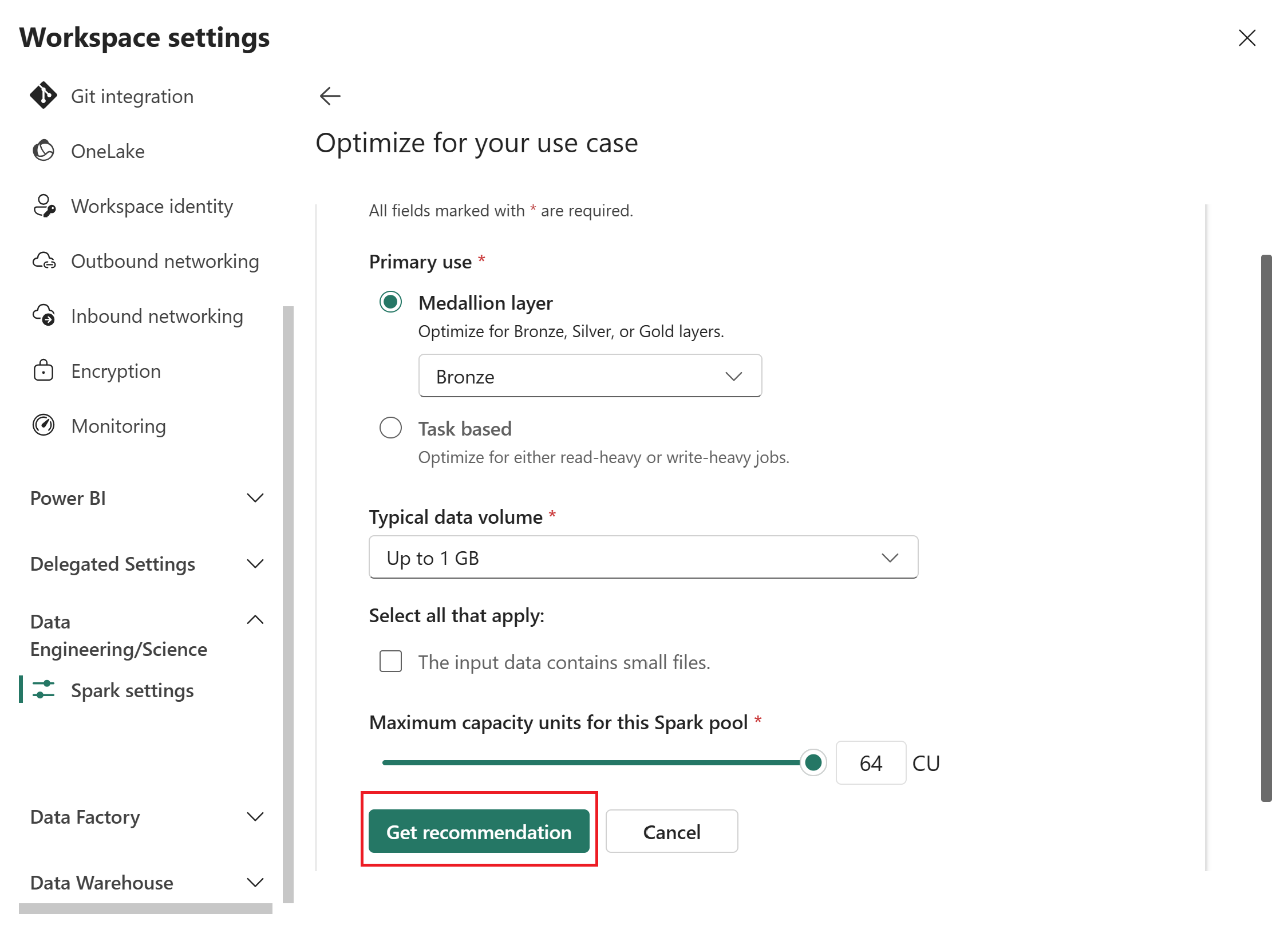
Struktura generuje zoptymalizowaną konfigurację na podstawie parametrów wejściowych.
Zapoznaj się z zaleceniem. Zalecenie zawiera wartości dla dwóch kategorii:
- Pula Spark: typ puli Spark, rodzina węzłów, rozmiar węzła, autoskalowanie i dynamiczna alokacja wykonawcy.
- Środowisko: wersja środowiska uruchomieniowego, rdzenie sterowników platformy Spark i pamięć, rdzenie wykonawcze platformy Spark, pamięć i wystąpienia.
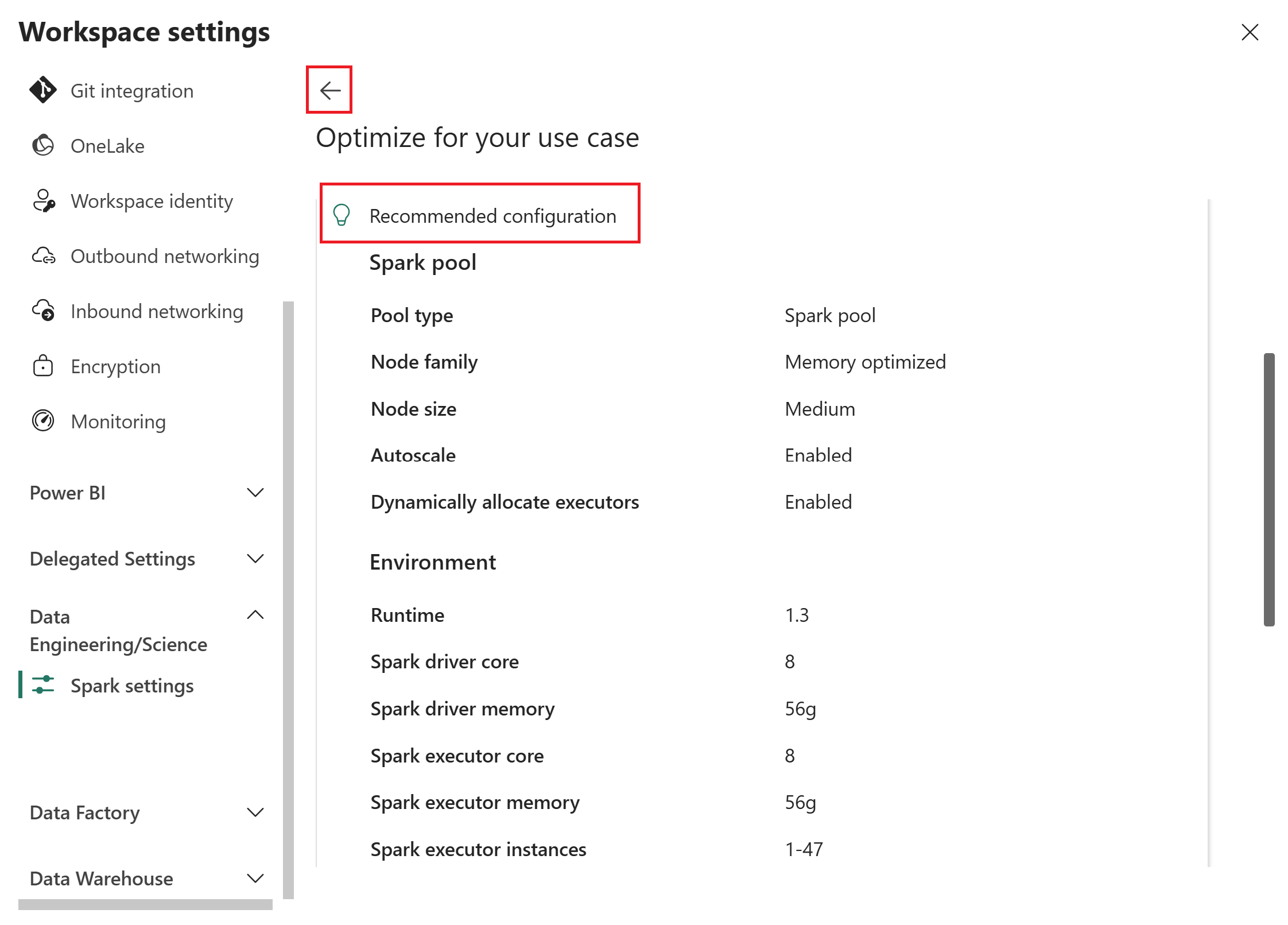
Jeśli chcesz dostosować dane wejściowe, wybierz strzałkę wstecz, aby powrócić do poprzedniej strony, zaktualizuj wybrane opcje, a następnie ponownie wybierz pozycję Pobierz zalecenie .
Wprowadź nazwę puli Spark i środowisko dla konfiguracji, a następnie wybierz Zastosuj, aby ją zapisać w obszarze roboczym.
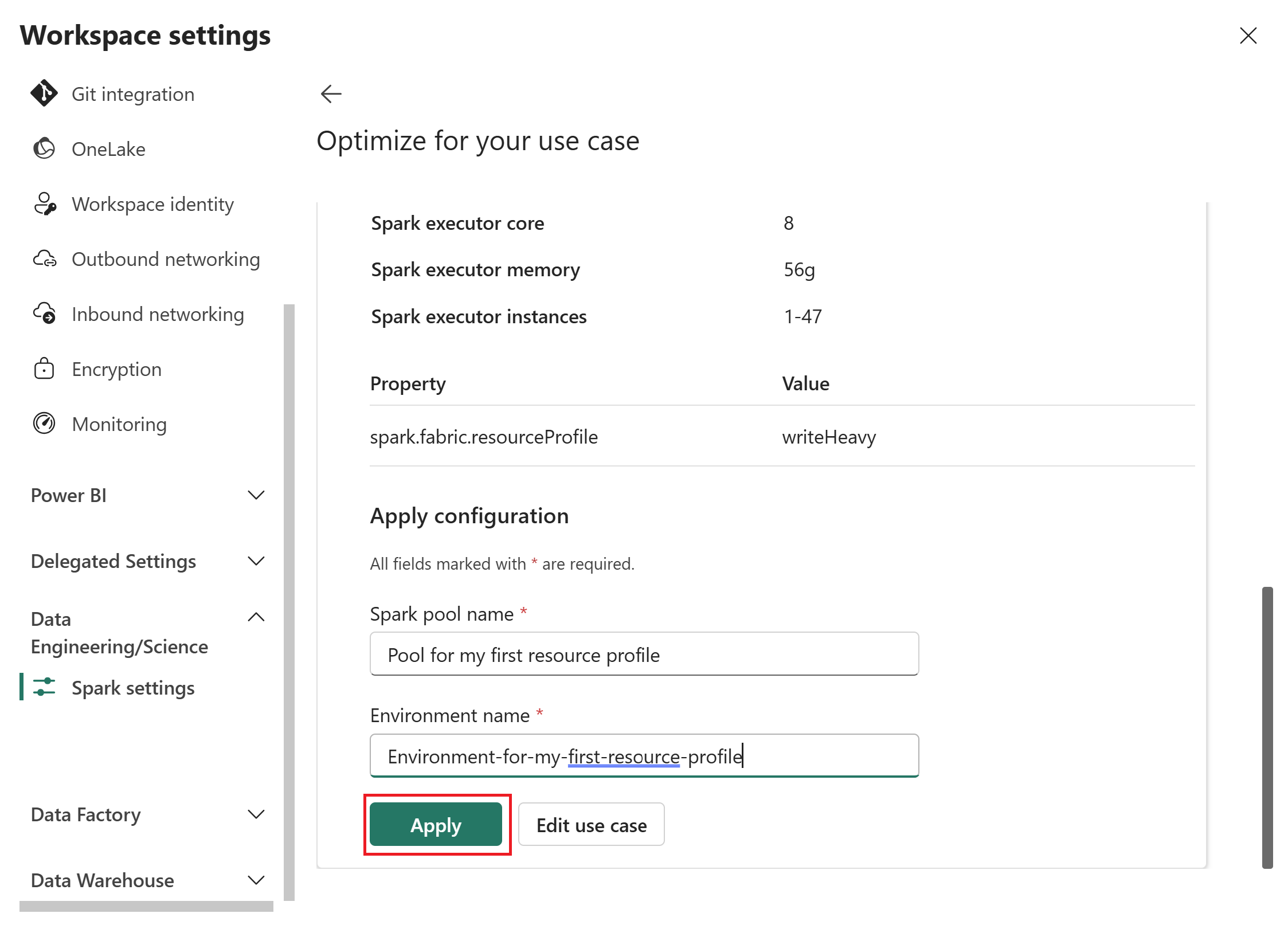




Po zastosowaniu profilu zasobów, Fabric tworzy niestandardową pulę Spark z zalecanymi ustawieniami.
Uwaga / Notatka
Jeśli obszar roboczy nie ma jeszcze puli niestandardowej, nowa pula zostanie automatycznie ustawiona jako domyślna pula dla obszaru roboczego. Jeśli obszar roboczy ma już pulę domyślną, musisz ręcznie przełączyć się do nowej puli w ustawieniach obszaru roboczego platformy Spark. Aktywne sesje nie mają wpływu, dopóki nie zostaną uruchomione ponownie.
Odniesienie do podstawowego przypadku użycia
Skorzystaj z poniższych wskazówek, aby wybrać odpowiednie dane wejściowe podstawowego przypadku użycia podczas konfigurowania profilu zasobu:
Warstwa medalionu
Wybierz warstwę Medallion , jeśli potok danych jest zgodny ze wzorcem architektury medalionu, w którym dane przechodzą przez etapy Brązowe (nieprzetworzone), Silver (oczyszczone) i Gold (wyselekcjonowane). Każda opcja dostraja obliczenia dotyczące cech odczytu/zapisu typowych dla tego etapu.
| Przypadek użycia | Kiedy stosować |
|---|---|
| Brąz | Pozyskiwanie danych pierwotnych, wysoka przepływność zapisu, różne formaty |
| Srebro | Czyszczenie i wzbogacanie, zrównoważony odczyt/zapis z umiarkowanymi złączeniami |
| Złoto | Agregacja i raportowanie zoptymalizowane pod kątem odczytu na potrzeby analizy i usługi Power BI |
Na podstawie zadania
Wybierz opcję Na podstawie zadania jeśli obciążenie nie jest zgodne ze schematem medalionu lub jeśli jest zdominowane przez pojedynczy schemat dostępu. Na przykład użyj tej opcji dla autonomicznych zadań ETL, notesów analizy interakcyjnej lub potoków przesyłania strumieniowego.
| Przypadek użycia | Kiedy stosować |
|---|---|
| Odczyt zoptymalizowany | Częste odczyty i zapytania, interaktywne notesy |
| Zoptymalizowane pod kątem zapisu | Przyjmowanie dużych ilości danych, potoki przetwarzania ETL, przesyłanie strumieniowe |
Automatyczne aktualizowanie profilów zasobów
Profile zasobów obsługują funkcję automatycznej aktualizacji, która utrzymuje konfigurację obliczeniową platformy Spark dostosowaną do najnowszych optymalizacji z Fabric. Po włączeniu automatycznych aktualizacji Fabric stosuje właściwości Spark specyficzne dla danego obciążenia na podstawie typu profilu zasobów, bez konieczności ręcznego dostrajania.
Konfiguracje automatycznej aktualizacji
Fabric udostępnia trzy profile automatycznej aktualizacji, z których każdy jest dostrojony do określonego wzorca obciążenia:
Duże obciążenie odczytu dla obciążeń platformy Spark
Ustaw przez spark.fabric.resourceProfile.readHeavyForSparkAutoUpdate:
{
"spark.databricks.delta.optimizeWrite.enabled": "true",
"spark.databricks.delta.optimizeWrite.partitioned.enabled": "true",
"spark.databricks.delta.optimizeWrite.binSize": "128"
}
Użyj tego profilu, gdy obciążenie składa się głównie z operacji odczytu w Spark i wymaga umiarkowanej optymalizacji zapisu.
Duże obciążenie odczytu dla obciążeń Power BI
Ustaw przez spark.fabric.resourceProfile.readHeavyForPBIAutoUpdate:
{
"spark.sql.parquet.vorder.default": "true",
"spark.databricks.delta.optimizeWrite.enabled": "true",
"spark.databricks.delta.optimizeWrite.binSize": "1g"
}
Użyj tego profilu, gdy dane są używane głównie przez Power BI. V-Order jest włączone, aby zapewnić optymalną wydajność usługi DirectLake, a większy rozmiar zasobnika powoduje tworzenie mniejszej liczby większych plików, odpowiednich do odczytów analitycznych.
Obciążenia z dużym obciążeniem zapisu
Ustaw przez spark.fabric.resourceProfile.writeHeavyAutoUpdate:
{
"spark.sql.parquet.vorder.default": "false",
"spark.databricks.delta.optimizeWrite.binSize": "128",
"spark.databricks.delta.optimizeWrite.partitioned.enabled": "true"
}
Użyj tego profilu, gdy obciążenie jest zapisochłonne (na przykład przy pozyskiwaniu dużych wolumenów danych lub w procesach ETL). V-Order jest wyłączone, aby zmniejszyć narzut operacji zapisu, a optymalizacja zapisu z partycjonowaniem jest włączona, aby zapewnić wydajny układ plików.
Jak działa automatyczna aktualizacja
Po zastosowaniu profilu zasobu z automatyczną aktualizacją:
- Fabric wybiera odpowiednią konfigurację automatycznej aktualizacji na podstawie podstawowego przypadku użycia i typu obciążenia.
- Właściwości platformy Spark są automatycznie stosowane do nowych sesji w obszarze roboczym.
- Aktywne sesje nie będą miały wpływu, dopóki nie zostaną uruchomione ponownie.
Uwaga / Notatka
Konfiguracje automatycznej aktualizacji optymalizują sposób zapisu w Delta Lake i układ plików w ramach pierwotnych parametrów profilu wejściowego. Nie zmieniają one rozmiaru puli, konfiguracji węzła ani ustawień automatycznego skalowania.
Dokumentacja konfiguracji
| Setting | Zastosowane właściwości | Kiedy stosować |
|---|---|---|
spark.fabric.resourceProfile.readHeavyForSparkAutoUpdate |
Włączona optymalizacja zapisu, zapis partycjonowany, rozmiar binu 128 MB | Analityka Spark z przewagą operacji odczytu |
spark.fabric.resourceProfile.readHeavyForPBIAutoUpdate |
Włączono V-Order, optymalizacja zapisu, rozmiar binu 1 GB | Power BI/DirectLake z przewagą operacji odczytu |
spark.fabric.resourceProfile.writeHeavyAutoUpdate |
Wyłączono V-Order, optymalizacja zapisu, rozmiar binu 128 MB, z partycjonowaniem | Intensywne ładowanie danych i ETL |