Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Użyj dedykowanych pul Spark, aby dostosować komputację do swoich obciążeń w usłudze Fabric. Możesz wybrać rozmiar węzła, skonfigurować zachowanie autoskalowania i włączyć dynamiczną alokację funkcji wykonawczej.
Pule niestandardowe ułatwiają równoważenie wydajności i kosztów, umożliwiając ustawianie limitów skalowania, które odpowiadają zapotrzebowaniu na obciążenia.
Uwaga / Notatka
Niestandardowe pule platformy Spark mogą osiągnąć około 5-sekundowe rozpoczęcie sesji, gdy są skonfigurowane jako niestandardowa pula na żywo w środowisku, które używa trybu pełnego do publikowania biblioteki. Bez konfiguracji puli na żywo uruchamianie niestandardowych pul platformy Spark trwa około trzech minut.
Jeśli już używasz pul początkowych, pule niestandardowe są opcją uzupełniającą, gdy potrzebujesz większej kontroli nad określaniem rozmiaru i zachowaniem skalowania dla określonych obciążeń. Użyj pul startowych do szybkiego uruchamiania i ustawień domyślnych, a następnie przejdź do pul niestandardowych, gdy potrzebujesz dostrajania zasobów obliczeniowych specyficznych dla obciążenia. Aby dowiedzieć się więcej na temat pul startowych, zobacz Konfigurowanie pul startowych w usłudze Fabric.
Wymagania wstępne
Aby utworzyć niestandardową pulę dla Sparka:
- Potrzebna jest rola administratora w obszarze roboczym.
- Administrator zasobów musi włączyć niestandardowe pule obszarów roboczych w ustawieniach Spark Compute dla zasobów.
Aby uzyskać więcej informacji, zobacz Konfigurowanie i zarządzanie ustawieniami inżynierii danych i nauki o danych dla pojemności Fabric.
Utwórz niestandardowe pule Spark
Aby utworzyć lub zarządzać pulą Spark skojarzoną z obszarem roboczym:
Przejdź do obszaru roboczego i wybierz pozycję Ustawienia obszaru roboczego.
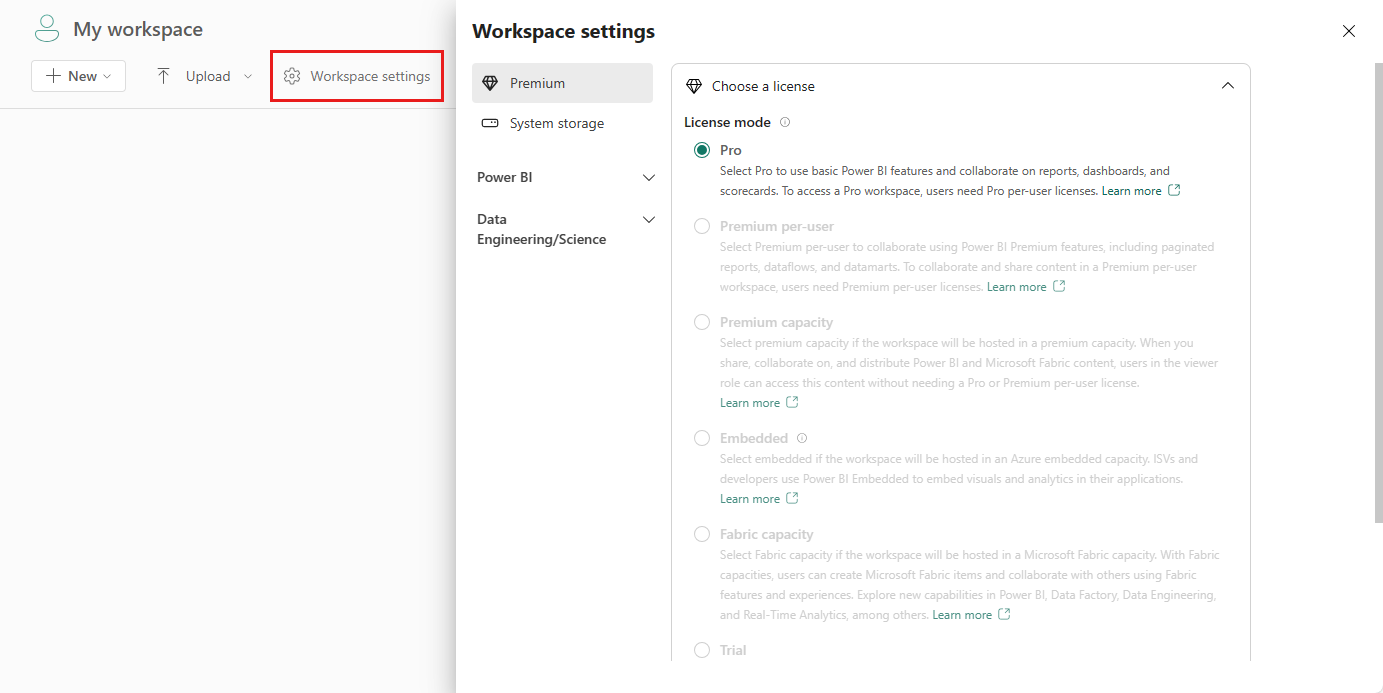
Wybierz opcję Data Engineering/Science, aby rozwinąć menu, a następnie wybierz ustawienia Spark.

Wybierz pozycję Nowa pula z listy rozwijanej Domyślna pula dla obszaru roboczego , aby utworzyć nową niestandardową pulę platformy Spark. Możesz utworzyć wiele pul niestandardowych i wybrać dowolną z nich jako domyślną pulę obszaru roboczego.
Na stronie Tworzenie nowej puli wprowadź nazwę puli. Wybierz rodzinę węzłów (np. zoptymalizowaną pod kątem pamięci) i rozmiar węzła na podstawie wymagań dotyczących obciążenia. Aby uzyskać więcej informacji na temat rozmiarów węzłów, zobacz sekcję Opcje rozmiaru węzła poniżej.
Wskazówka
Rozmiar węzła jest określany przez jednostki pojemności (CU), które reprezentują pojemność obliczeniową przypisaną do każdego węzła.
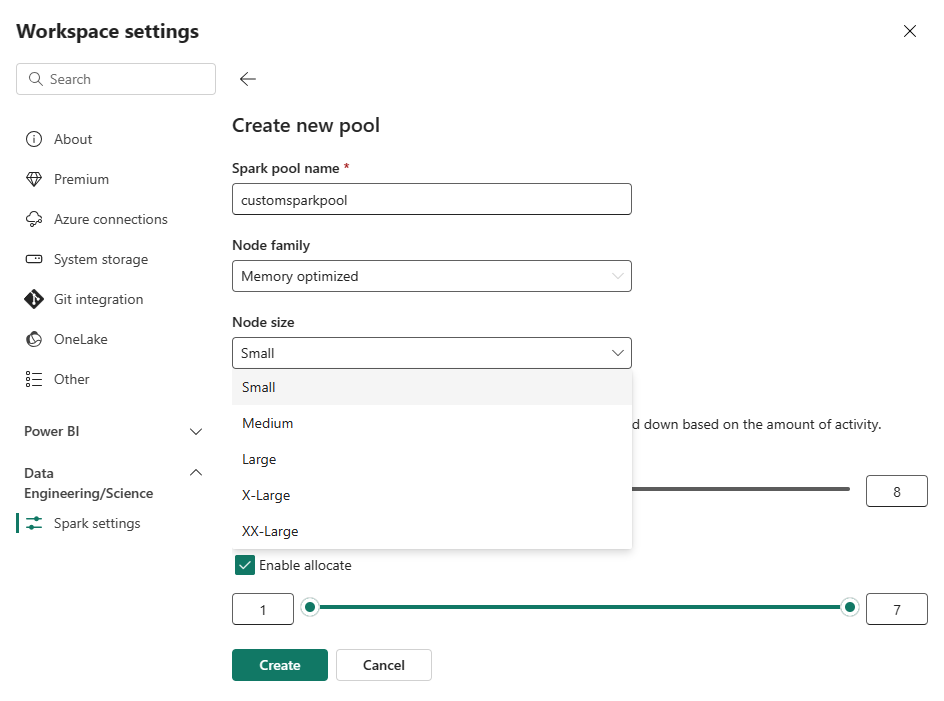
W widoku edycji skonfiguruj funkcję autoskalowania i dynamiczne przydzielanie funkcji wykonawczych.
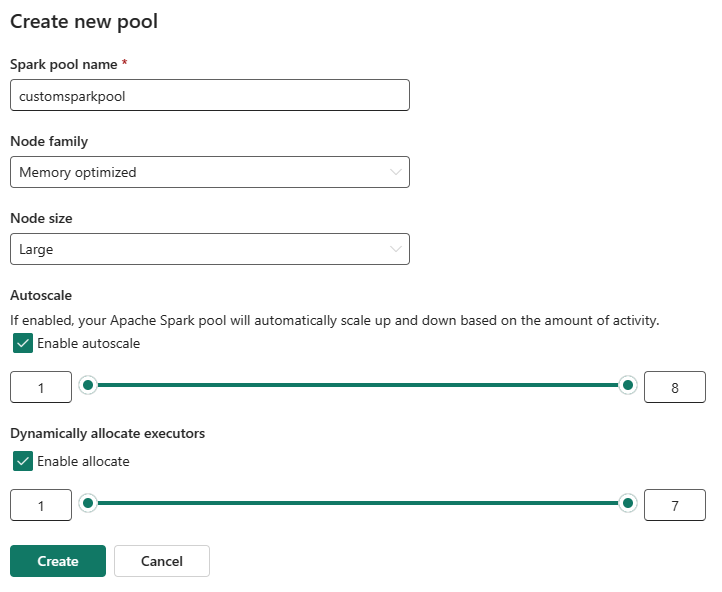
Użyj suwaków, aby zwiększyć lub zmniejszyć każde ustawienie w zależności od potrzeb związanych z obciążeniem.
Jeśli automatyczne skalowanie jest włączone, pula jest skalowana między skonfigurowanymi wartościami minimalnymi i maksymalnymi węzłów na podstawie działania.
Jeśli funkcja Dynamiczne przydzielanie wykonawców jest włączona, Szkielet dostosowuje alokację wykonawców na podstawie zapotrzebowania na obciążenie w skonfigurowanych granicach.
Wybierz Utwórz.




Wskazówka
Po utworzeniu niestandardowej puli Spark czas wdrażania biblioteki zależy od trybu publikowania w dołączonym środowisku. Tryb szybki publikuje w ciągu około 5 sekund i instaluje biblioteki na początku sesji. Pełny tryb trwa od 3 do 6 minut, obejmując publikację i wdrożenie bibliotek, jako części uruchamiania sesji, co zajmuje od 1 do 3 minut. Aby uzyskać najszybsze działanie, skonfiguruj pulę jako niestandardową pulę na żywo z trybem pełnym, co pozwala na rozpoczęcie sesji w około 5 sekund.
Pule niestandardowe mają domyślny czas autopauzy trwający 2 minuty po braku aktywności. Po osiągnięciu autopauzy sesji, sesja wygaśnie, a klaster zostanie dealokowany. Rozliczenia mają zastosowanie tylko wtedy, gdy zasoby obliczeniowe są aktywnie używane. Niestandardowe pule platformy Spark w Microsoft Fabric obecnie obsługują maksymalny limit węzłów wynoszący 200, dlatego upewnij się, że minimalne i maksymalne wartości autoskalowania pozostają w tym limicie.
Opcje rozmiaru węzła
Podczas konfigurowania niestandardowej puli Spark wybierasz spośród następujących rozmiarów węzłów:
| Rozmiar węzła | vCores | Pamięć (GB) | Opis |
|---|---|---|---|
| Mały | 4 | 32 | Do lekkich prac związanych z tworzeniem i testowaniem. |
| Średni | 8 | 64 | W przypadku ogólnych obciążeń i typowych operacji. |
| Duży | 16 | 128 | W przypadku zadań intensywnie korzystających z pamięci lub dużych zadań przetwarzania danych. |
| X-Large | 32 | 256 | W przypadku najbardziej wymagających obciążeń platformy Spark, które potrzebują znaczących zasobów. |
| XX-Duży | 64 | 512 | W przypadku największych obciążeń platformy Spark, które wymagają najwyższych zasobów obliczeniowych i pamięci na węzeł. |
Powiązana zawartość
- Dowiedz się więcej na temat publicznej dokumentacji platformy Apache Spark .
- Rozpocznij pracę z ustawieniami administrowania obszarem roboczym Spark w Microsoft Fabric.
- Zarządzanie bibliotekami w środowiskach Fabric