Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Z tego samouczka dowiesz się, jak utworzyć definicję zadania platformy Spark w usłudze Microsoft Fabric.
Wymagania wstępne
Przed rozpoczęciem potrzebne są następujące elementy:
- Konto dzierżawy sieci szkieletowej z aktywną subskrypcją. Utwórz konto bezpłatnie.
Napiwek
Aby uruchomić element definicji zadania platformy Spark, musisz mieć plik definicji głównej i domyślny kontekst lakehouse. Jeśli nie masz jeziora, możesz go utworzyć, wykonując kroki opisane w temacie Tworzenie jeziora.
Tworzenie definicji zadania platformy Spark
Proces tworzenia definicji zadań platformy Spark jest szybki i prosty; Istnieje kilka sposobów rozpoczęcia pracy.
Opcje tworzenia definicji zadania platformy Spark
Istnieją dwa sposoby rozpoczęcia procesu tworzenia:
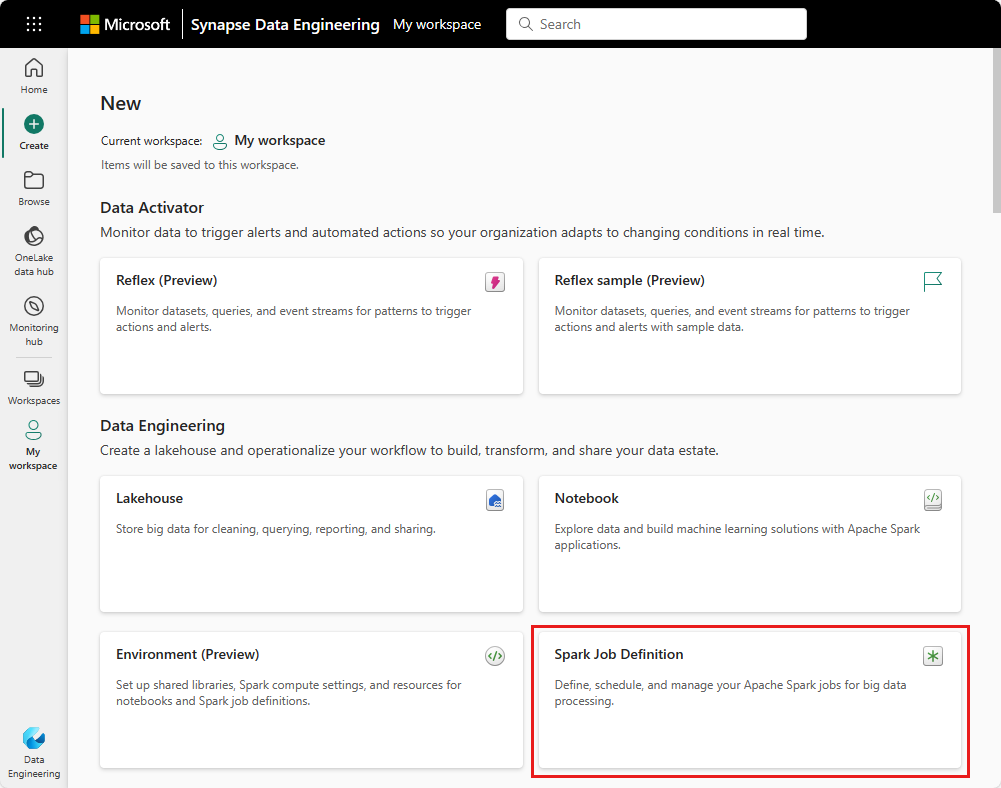
Widok obszaru roboczego: możesz łatwo utworzyć definicję zadania platformy Spark za pomocą obszaru roboczego usługi Fabric, wybierając pozycję Nowy element>definicji zadania platformy Spark.
Strona główna Fabric: Innym punktem wejścia do utworzenia definicji zadania Spark jest kafelek Analiza danych z użyciem SQL ... na stronie głównej Fabric. Tę samą opcję można znaleźć, wybierając kafelek Ogólne.

Podczas tworzenia zadania platformy Spark musisz podać nazwę zadania platformy Spark. Nazwa musi być unikatowa w bieżącym obszarze roboczym. Nowa definicja zadania platformy Spark jest tworzona w bieżącym obszarze roboczym.
Tworzenie definicji zadania platformy Spark dla platformy PySpark (Python)
Aby utworzyć definicję zadania platformy Spark dla programu PySpark:
Pobierz przykładowy plik Parquet yellow_tripdata_2022-01.parquet i przekaż go do sekcji plików lakehouse.
Utwórz nową definicję zadania platformy Spark.
Wybierz pozycję PySpark (Python) z listy rozwijanej Język .
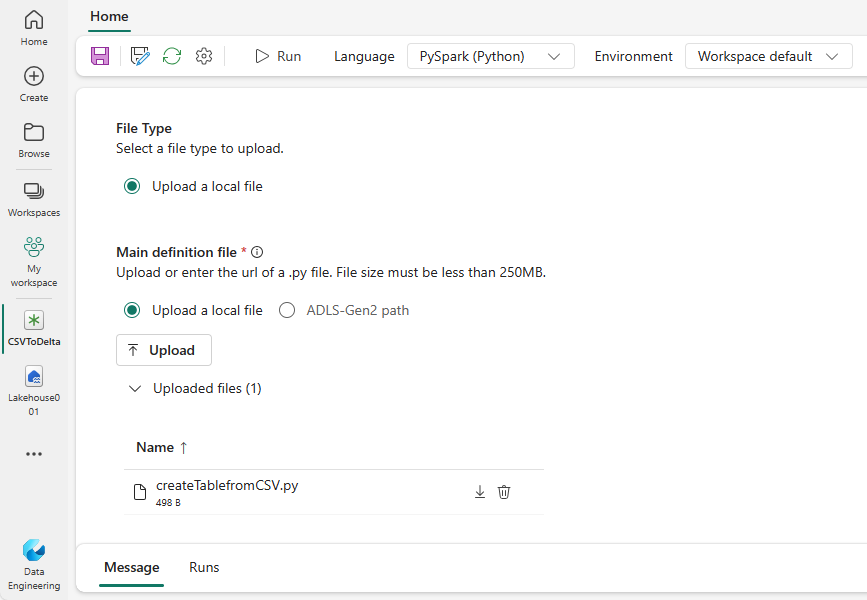
Pobierz przykład createTablefromParquet.py i przekaż go jako główny plik definicji. Główny plik definicji (zadanie. Main) to plik, który zawiera logikę aplikacji i jest obowiązkowy do uruchamiania zadania platformy Spark. Dla każdej definicji zadania platformy Spark można przekazać tylko jeden plik definicji głównej.
Możesz przekazać główny plik definicji z pulpitu lokalnego lub przekazać go z istniejącej usługi Azure Data Lake Storage (ADLS) Gen2, podając pełną ścieżkę ABFSS pliku. Na przykład
abfss://your-storage-account-name.dfs.core.windows.net/your-file-path.Przekaż pliki referencyjne jako pliki .py . Pliki referencyjne to moduły języka Python importowane przez główny plik definicji. Podobnie jak plik definicji głównej, można przekazać z pulpitu lub z istniejącej usługi ADLS Gen2. Obsługiwane są wiele plików referencyjnych.
Napiwek
Jeśli używasz ścieżki usługi ADLS Gen2, aby upewnić się, że plik jest dostępny, musisz nadać konto użytkownika uruchamiające zadanie odpowiednie uprawnienie do konta magazynu. Sugerujemy dwa różne sposoby, aby to zrobić:
- Przypisz konto użytkownika rolę Współautor dla konta magazynu.
- Udziel uprawnień odczyt i wykonanie do konta użytkownika dla pliku za pośrednictwem listy kontroli dostępu (ACL) usługi ADLS Gen2.
W przypadku ręcznego uruchomienia konto bieżącego użytkownika logowania jest używane do uruchamiania zadania.
W razie potrzeby podaj argumenty wiersza polecenia dla zadania. Użyj spacji jako separatora, aby oddzielić argumenty.
Dodaj odwołanie do usługi Lakehouse do zadania. Musisz mieć co najmniej jedno odwołanie do usługi Lakehouse dodane do zadania. Ten lakehouse jest domyślnym kontekstem lakehouse dla zadania.
Obsługiwane są odwołania do wielu magazynów lakehouse. Znajdź inną niż domyślną nazwę lakehouse i pełny adres URL usługi OneLake na stronie Ustawienia platformy Spark.
Tworzenie definicji zadania platformy Spark dla języka Scala/Java
Aby utworzyć definicję zadania platformy Spark dla języka Scala/Java:
Utwórz nową definicję zadania platformy Spark.
Wybierz pozycję Spark(Scala/Java) z listy rozwijanej Język .
Przekaż główny plik definicji jako plik .jar . Głównym plikiem definicji jest plik, który zawiera logikę aplikacji tego zadania i jest obowiązkowy do uruchamiania zadania platformy Spark. Dla każdej definicji zadania platformy Spark można przekazać tylko jeden plik definicji głównej. Podaj nazwę klasy Main.
Przekaż pliki referencyjne jako pliki .jar . Pliki referencyjne to pliki, do których się odwołuje/importowane przez główny plik definicji.
W razie potrzeby podaj argumenty wiersza polecenia dla zadania.
Dodaj odwołanie do usługi Lakehouse do zadania. Musisz mieć co najmniej jedno odwołanie do usługi Lakehouse dodane do zadania. Ten lakehouse jest domyślnym kontekstem lakehouse dla zadania.
Tworzenie definicji zadania platformy Spark dla języka R
Aby utworzyć definicję zadania platformy Spark dla platformy SparkR(R):
Utwórz nową definicję zadania platformy Spark.
Wybierz pozycję SparkR(R) z listy rozwijanej Język .
Przekaż główny plik definicji jako . Plik języka R . Głównym plikiem definicji jest plik, który zawiera logikę aplikacji tego zadania i jest obowiązkowy do uruchamiania zadania platformy Spark. Dla każdej definicji zadania platformy Spark można przekazać tylko jeden plik definicji głównej.
Przekaż pliki referencyjne jako . Pliki języka R . Pliki referencyjne to pliki, do których się odwołuje/importowane przez główny plik definicji.
W razie potrzeby podaj argumenty wiersza polecenia dla zadania.
Dodaj odwołanie do usługi Lakehouse do zadania. Musisz mieć co najmniej jedno odwołanie do usługi Lakehouse dodane do zadania. Ten lakehouse jest domyślnym kontekstem lakehouse dla zadania.
Uwaga
Definicja zadania platformy Spark zostanie utworzona w bieżącym obszarze roboczym.
Opcje dostosowywania definicji zadań platformy Spark
Istnieje kilka opcji dostosowywania wykonywania definicji zadań platformy Spark.
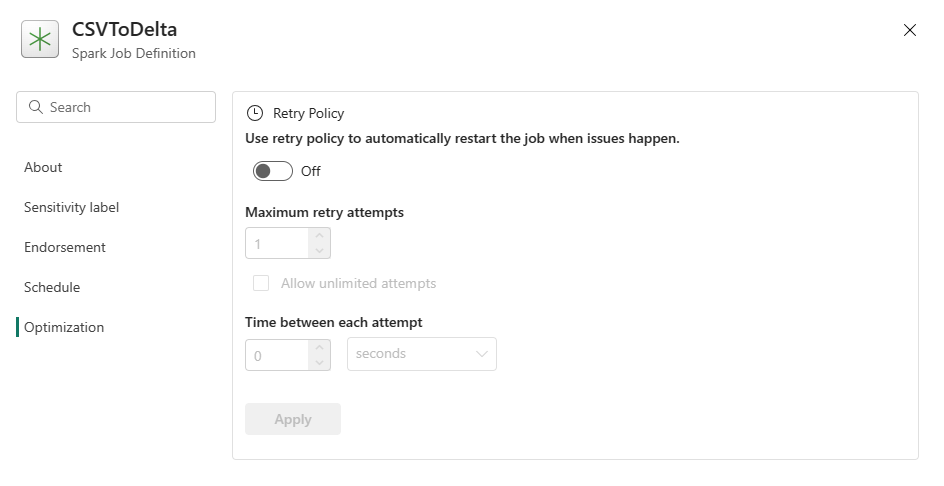
- Spark Compute: na karcie Spark Compute można zobaczyć wersję środowiska uruchomieniowego, która jest wersją platformy Spark, która będzie używana do uruchamiania zadania. Możesz również wyświetlić ustawienia konfiguracji platformy Spark, które będą używane do uruchamiania zadania. Ustawienia konfiguracji platformy Spark można dostosować, klikając przycisk Dodaj .
Optymalizacja: na karcie Optymalizacja można włączyć i skonfigurować zasady ponawiania dla zadania. Po włączeniu zadanie zostanie ponowione, jeśli zakończy się niepowodzeniem. Można również ustawić maksymalną liczbę ponownych prób i interwał między ponowną próbą. Dla każdej próby ponawiania zadanie jest uruchamiane ponownie. Upewnij się, że zadanie jest idempotentne.