Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Usługa Lakehouse obsługuje tworzenie schematów niestandardowych. Schematy umożliwiają grupowanie tabel w celu lepszego odnajdywania danych, kontroli dostępu i nie tylko.
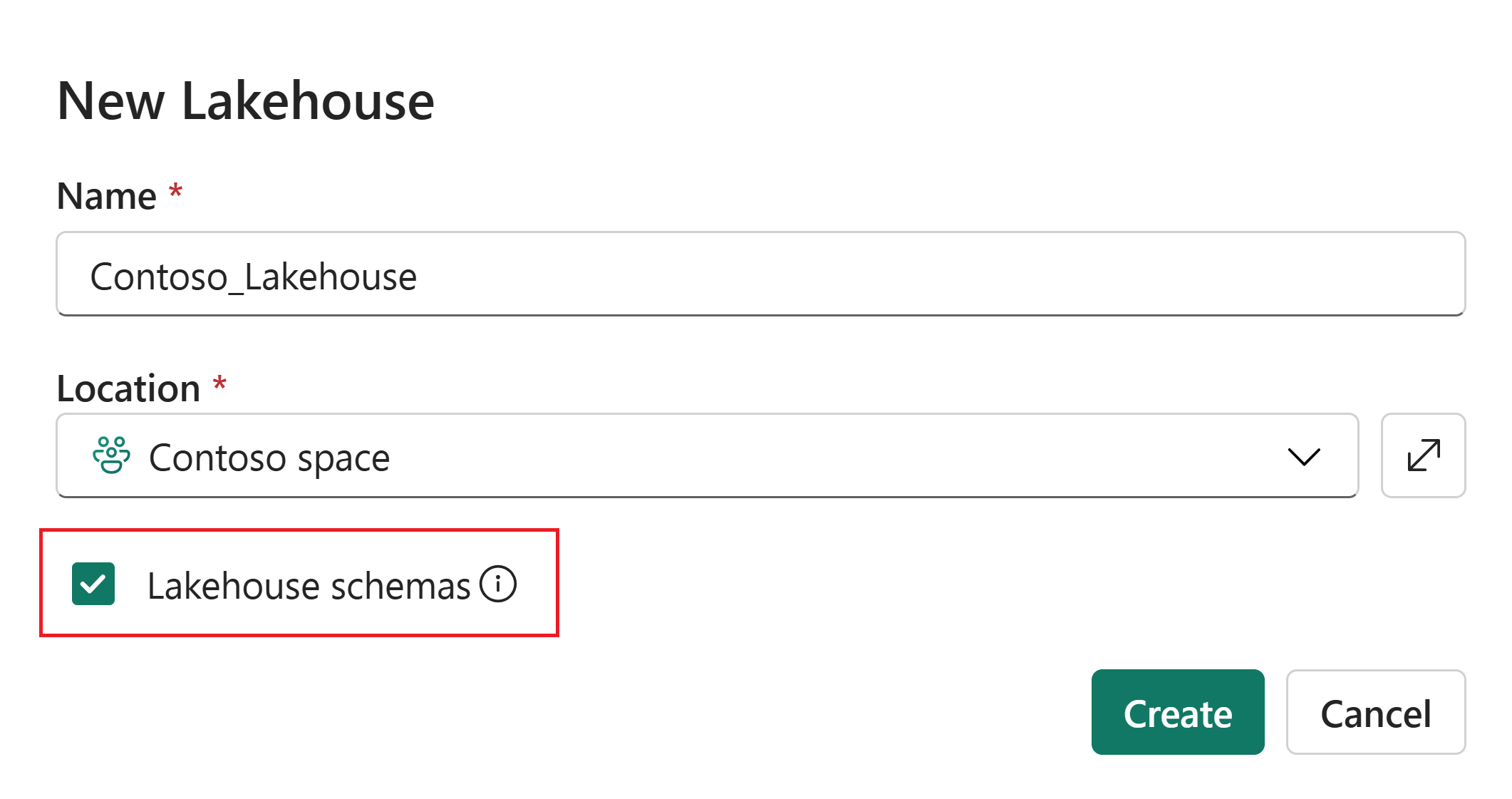
Tworzenie schematu lakehouse
Podczas tworzenia Lakehouse, aby włączyć obsługę jego schematów, zaznacz pole wyboru obok Schematy Lakehouse (Publiczna Wersja Zapoznawcza).
Ważne
Nazwy obszarów roboczych mogą zawierać tylko znaki alfanumeryczne ze względu na ograniczenia wersji zapoznawczej. Jeśli znaki specjalne są używane w nazwach obszarów roboczych, niektóre funkcje usługi Lakehouse nie będą działać.
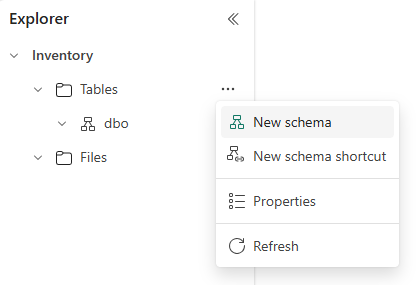
Po utworzeniu magazynu typu lakehouse można znaleźć domyślny schemat o nazwie dbo w sekcji Tabele. Ten schemat jest zawsze dostępny i nie można go zmienić ani usunąć. Aby utworzyć nowy schemat, umieść kursor nad tabelami, wybierz pozycję ..., a następnie wybierz pozycję Nowy schemat. Wprowadź nazwę schematu i wybierz pozycję Utwórz. Schemat zostanie wyświetlony w obszarze Tabele w kolejności alfabetycznej.
Przechowywanie tabel w ramach schematów lakehouse
Do przechowywania tabeli w schemacie potrzebna jest nazwa schematu. W przeciwnym razie przechodzi do domyślnego schematu dbo .
df.write.mode("Overwrite").saveAsTable("contoso.sales")
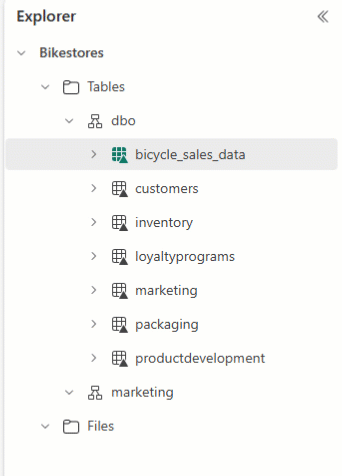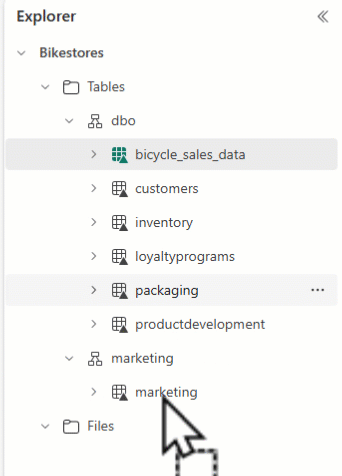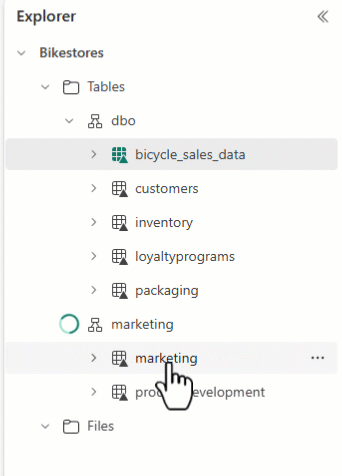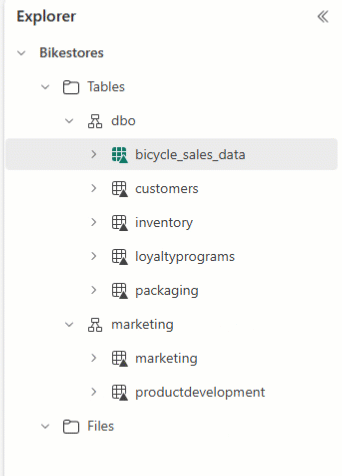
Eksplorator usługi Lakehouse umożliwia rozmieszczenie tabel i przeciąganie i upuszczanie nazw tabel do różnych schematów.
Uwaga
Jeśli zmodyfikujesz tabelę, musisz również zaktualizować powiązane elementy, takie jak kod notesu lub przepływy danych, aby upewnić się, że są one dopasowane do poprawnego schematu.
Przenieś wiele tabel ze skrótem schematu
Aby odwołać się do wielu tabel różnicowych z innej usługi Fabric Lakehouse lub magazynu zewnętrznego, użyj skrótu schematu, który wyświetla wszystkie tabele w wybranym schemacie lub folderze. Wszelkie zmiany w tabelach w lokalizacji źródłowej również są wyświetlane w schemacie. Aby utworzyć skrót schematu, umieść kursor nad tabelami, wybierz pozycję ..., a następnie wybierz pozycję Nowy skrót schematu. Następnie wybierz schemat w innym magazynie typu lakehouse lub folder z tabelami delty w magazynie zewnętrznym, takimi jak Azure Data Lake Storage (ADLS) Gen2. Spowoduje to utworzenie nowego schematu z przywołynymi tabelami.
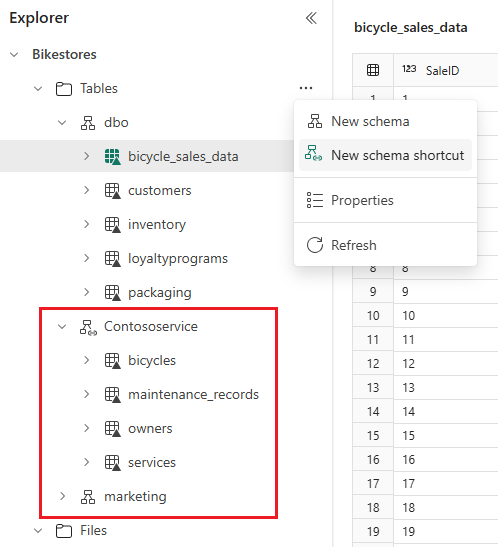
Uzyskiwanie dostępu do schematów usługi Lakehouse na potrzeby raportowania usługi Power BI
Aby utworzyć model semantyczny, wystarczy wybrać tabele, których chcesz użyć. Tabele mogą znajdować się w różnych schematach. Jeśli tabele z różnych schematów mają taką samą nazwę, numery są wyświetlane obok nazw tabel w widoku modelu.
Schematy usługi Lakehouse w notesie
Po zapoznaniu się ze schematem z włączoną usługą Lakehouse w eksploratorze obiektów notesu tabele znajdują się w schematach. Tabelę można przeciągać i upuszczać do komórki kodu i pobierać fragment kodu odwołujący się do schematu, w którym znajduje się tabela. Użyj tego namespace, aby odwołać się do tabel w kodzie: "workspace.lakehouse.schema.table". Jeśli pominiesz którykolwiek z elementów, wykonawca używa ustawienia domyślnego. Jeśli na przykład podasz nazwę tabeli, używa domyślnego schematu (dbo) z domyślnego lakehouse w notesie.
Ważne
Jeśli chcesz używać schematów w swoim kodzie, upewnij się, że domyślny lakehouse dla notesu ma włączoną obsługę schematów.
Zapytania Spark SQL między obszarami roboczymi
Użyj przestrzeni nazw "workspace.lakehouse.schema.table", aby odwołać się do tabel w kodzie. W ten sposób można łączyć tabele z różnych obszarów roboczych, jeśli użytkownik, który uruchamia kod, ma uprawnienia dostępu do tabel.
SELECT *
FROM operations.hr.hrm.employees as employees
INNER JOIN global.corporate.company.departments as departments
ON employees.deptno = departments.deptno;
Ważne
Upewnij się, że tabele są przyłączane tylko z magazynów lakehouse, które mają włączone schematy. Łączenie tabel z magazynów danych lakehouse, które nie mają aktywowanych schematów, nie będzie działać.
Ograniczenia publicznej wersji zapoznawczej
Poniżej wymieniono nieobsługiwane funkcje/funkcjonalności dla bieżącej wersji zapoznawczej. Zostaną one rozwiązane w nadchodzących wersjach przed ogólną dostępnością.
| Nieobsługiwane cechy/funkcjonalność | Uwagi |
|---|---|
| Wspólny dom nad jeziorem | Używanie środowiska roboczego w przestrzeni nazw dla wspólnych magazynów typu lakehouse nie będzie działać, np. workspace.sharedlakehouse.schema.table. Aby użytkownik mógł używać obszaru roboczego w przestrzeni namaspace, musi mieć rolę w obszarze roboczym. |
| Schemat tabeli innej niż delta, schemat tabeli zarządzanej | Pobieranie schematu dla tabel zarządzanych, które nie mają formatu Delta (na przykład CSV), nie jest obsługiwane. Rozwijanie tych tabel w eksploratorze lakehouse nie pokazuje żadnych informacji o schemacie w interfejsie użytkownika. |
| Zewnętrzne tabele Spark | Zewnętrzne operacje tabel platformy Spark (na przykład odnajdywanie, pobieranie schematu itp.) nie są obsługiwane. Te tabele są niezidentyfikowane w środowisku użytkownika. |
| Publiczny interfejs API | Publiczne interfejsy API (wykazy tabel, ładowanie tabeli, udostępnianie własności rozszerzonej domyślnego schematu itp.) nie są obsługiwane w przypadku Lakehouse z włączonymi schematami. Istniejące publiczne interfejsy API wywoływane w schemacie z włączonym Lakehouse powodują wystąpienie błędu. |
| Aktualizowanie właściwości tabeli | Nieobsługiwane. |
| Nazwa obszaru roboczego zawierająca znaki specjalne | Przestrzeń robocza ze znakami specjalnymi (na przykład spacją, ukośnikami) nie jest obsługiwana. Zostanie wyświetlony błąd użytkownika. |
| Widoki Spark | Nieobsługiwane. |
| Funkcje specyficzne dla programu Hive | Nieobsługiwane. |
| Spark.catalog API | Nieobsługiwane. Zamiast tego użyj usługi Spark SQL. |
USE <schemaName> |
Nie działa między obszarami roboczymi, ale jest obsługiwany w tym samym obszarze roboczym. |
| Migracja | Migracja istniejących Lakehouse, które nie są oparte na schemacie, do Lakehouse opartych na schemacie nie jest obsługiwana. |
| Przepływ danych Gen2 | Nieobsługiwane. |