Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W tym samouczku utworzysz lakehouse, załadujesz przykładowe dane do tabeli Delta, zastosujesz transformację tam, gdzie jest to wymagane, a następnie utworzysz raporty.
Wskazówka
Ten samouczek jest częścią serii. Po ukończeniu tego samouczka kontynuuj pozyskiwanie danych do usługi Lakehouse , aby utworzyć kompletną usługę Enterprise Lakehouse przy użyciu potoków usługi Data Factory, notesów platformy Spark i zaawansowanych technik raportowania.
Poniżej znajduje się lista kontrolna kroków, które wykonasz w procesie nauki:
Jeśli nie masz usługi Microsoft Fabric, utwórz konto w celu uzyskania pojemności bezpłatnej wersji próbnej.
Wymagania wstępne
- Przed utworzeniem lakehouse, należy utworzyć obszar roboczy Fabric.
- Przed przetwarzaniem pliku CSV, trzeba skonfigurować usługę OneDrive. Jeśli nie masz skonfigurowanej usługi OneDrive, utwórz konto bezpłatnej wersji próbnej platformy Microsoft 365: Bezpłatna wersja próbna — wypróbuj platformę Microsoft 365 przez miesiąc. Aby uzyskać instrukcje dotyczące konfiguracji, zobacz Konfigurowanie usługi OneDrive.
Dlaczego potrzebuję usługi OneDrive na potrzeby tego samouczka?
Na potrzeby tego samouczka potrzebujesz usługi OneDrive, ponieważ proces pozyskiwania danych opiera się na usłudze OneDrive jako podstawowym mechanizmie przechowywania dla przekazywania plików. Po przesłaniu pliku CSV do Fabric jest on tymczasowo przechowywany na koncie OneDrive przed wprowadzeniem do Lakehouse. Ta integracja zapewnia bezpieczny i bezproblemowy transfer plików w ekosystemie platformy Microsoft 365.
Etap pobierania nie działa, jeśli nie skonfigurowano usługi OneDrive, ponieważ Fabric nie ma dostępu do przesłanego pliku. Jeśli masz już dane dostępne w usłudze Lakehouse lub innej obsługiwanej lokalizacji, usługa OneDrive nie jest wymagana.
Uwaga
Jeśli masz już dane w usłudze Lakehouse, możesz użyć tych danych zamiast przykładowego pliku CSV. Aby sprawdzić, czy dane są już skojarzone z usługą Lakehouse, użyj Eksploratora usługi Lakehouse lub punktu końcowego analizy SQL, aby przeglądać tabele, pliki i foldery. Aby uzyskać więcej informacji na temat sprawdzania, zobacz Omówienie usługi Lakehouse i Tabele usługi Query Lakehouse z punktem końcowym analizy SQL.
Tworzenie lakehouse'u
W tej sekcji utworzysz magazyn lakehouse w usłudze Fabric.
W Fabricwybierz Obszary robocze z paska nawigacyjnego.
Aby otworzyć obszar roboczy, wprowadź jego nazwę w polu wyszukiwania znajdującym się u góry i wybierz go z wyników wyszukiwania.
W obszarze roboczym wybierz pozycję Nowy element, wprowadź ciąg Lakehouse w polu wyszukiwania, a następnie wybierz pozycję Lakehouse.
W oknie dialogowym Nowy lakehouse wprowadź wwilakehouse w polu Nazwa.
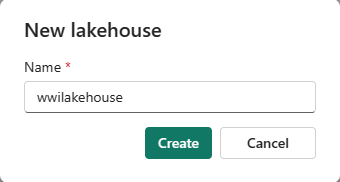
Wybierz Utwórz, aby utworzyć i otworzyć nowy lakehouse.

Pozyskiwanie przykładowych danych
W tej sekcji załadujesz przykładowe dane klientów do lakehouse.
Uwaga
Jeśli nie masz skonfigurowanej usługi OneDrive, utwórz konto bezpłatnej wersji próbnej platformy Microsoft 365: Bezpłatna wersja próbna — wypróbuj platformę Microsoft 365 przez miesiąc.
Pobierz plik dimension_customer.csv z repozytorium przykładów usługi Fabric.
Wybierz Lakehouse i przejdź do karty Strona główna.
Wybierz Pobierz dane>, aby utworzyć nowy przepływ danych. Ten przepływ danych służy do pozyskiwania przykładowych danych do lakehouse'u. Alternatywnie w obszarze Pobieranie danych w usłudze Lakehouse możesz wybrać kafelek Nowy przepływ danych Gen2 .
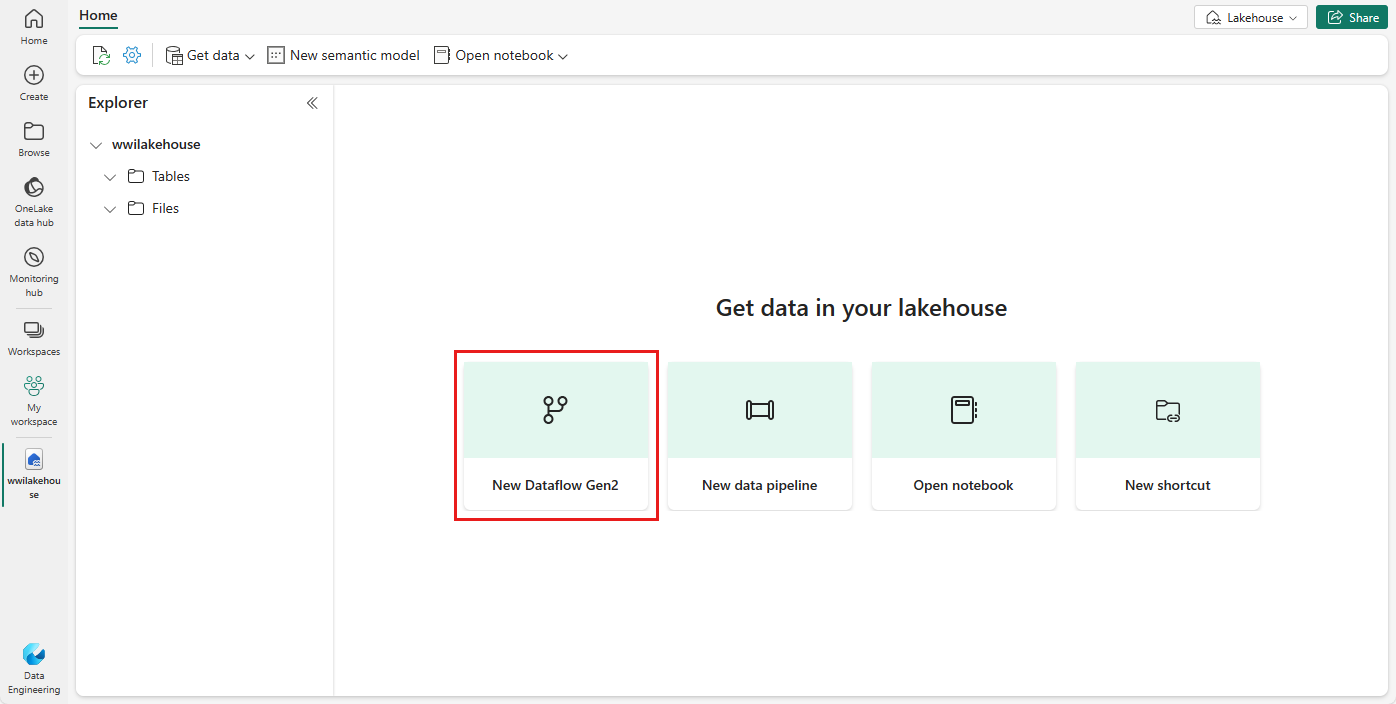
W okienku Nowy przepływ danych Gen2 wprowadź Dane Wymiaru Klienta w polu Nazwa i wybierz Utwórz.
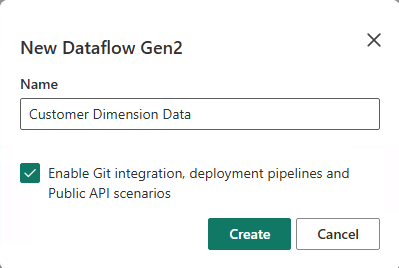
Na karcie Startowa przepływu danych wybierz kafelek Importuj z pliku tekstowego/CSV.
Na ekranie Łączenie ze źródłem danych wybierz przycisk radiowy Przekaż plik .
Przeglądaj lub upuść plik dimension_customer.csv, który pobrałeś w kroku 1. Po przekazaniu pliku wybierz Dalej.
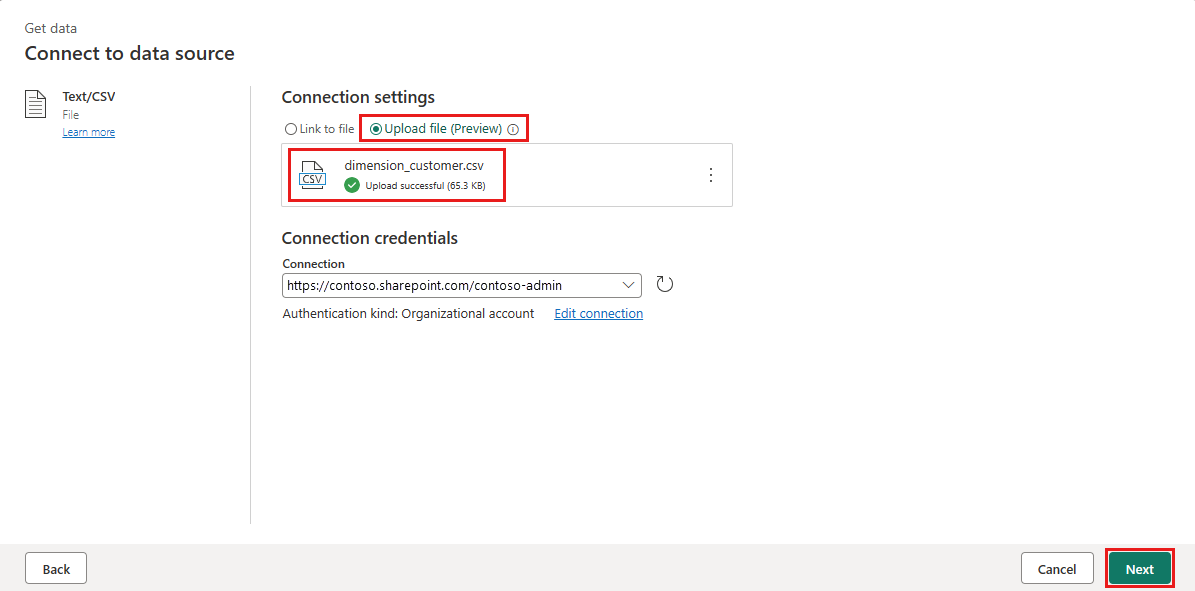
Na stronie Podgląd danych pliku można wyświetlić podgląd danych. Następnie wybierz pozycję Utwórz , aby kontynuować i wrócić do kanwy przepływu danych.



Przekształcanie i ładowanie danych do magazynu lakehouse
W tej sekcji dokonasz transformacji danych zgodnie z wymaganiami biznesowymi i załadujesz je do lakehouse.
W okienku Ustawienia zapytania upewnij się, że pole Nazwa ma ustawioną wartość dimension_customer. Ta nazwa jest używana jako nazwa tabeli w lakehouse, więc musi być pisana małymi literami i nie może zawierać spacji.
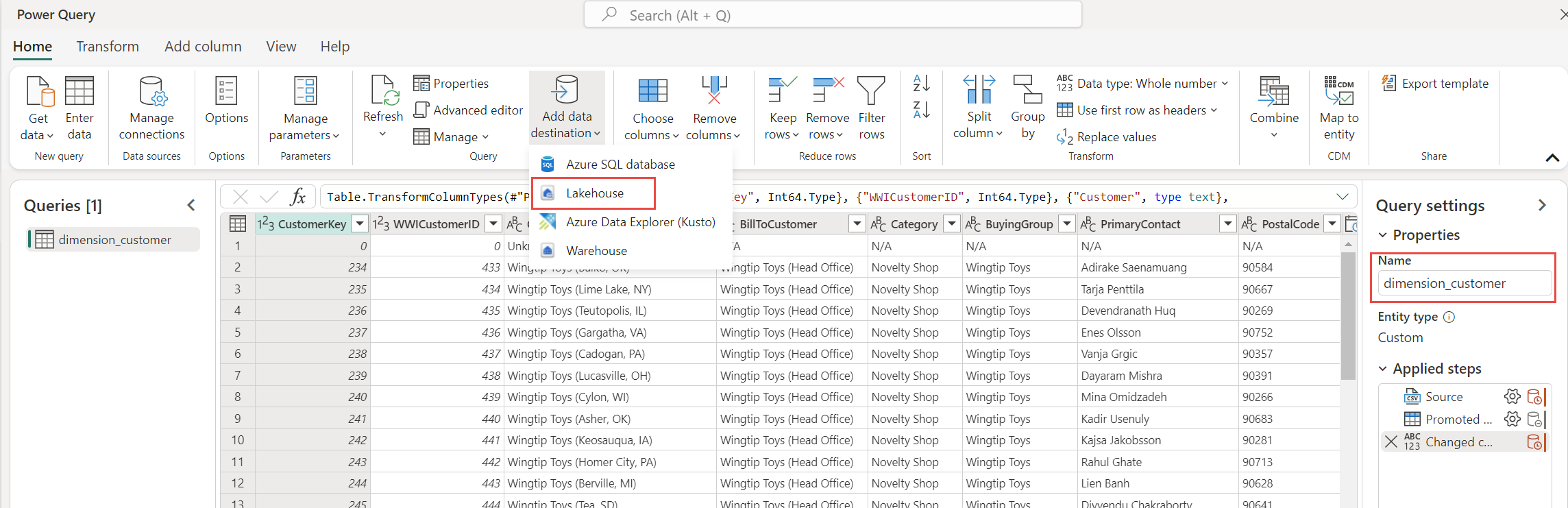
Ponieważ utworzyłeś przepływ danych z lakehouse, miejsce docelowe danych jest automatycznie ustawiane na lakehouse. Możesz to sprawdzić, sprawdzając miejsce docelowe danych w okienku ustawień zapytania.
Wskazówka
Jeśli tworzysz przepływ danych z obszaru roboczego zamiast z magazynu typu lakehouse, musisz ręcznie dodać miejsce docelowe danych. Aby uzyskać więcej informacji, zobacz Domyślna lokalizacja docelowa przepływu danych Gen2 i lokalizacje docelowe danych oraz ustawienia zarządzane.
Na kanwie przepływu danych można łatwo przekształcić dane na podstawie wymagań biznesowych. Dla uproszczenia nie wprowadzamy żadnych zmian w tym samouczku. Aby kontynuować, wybierz pozycję Zapisz i uruchom na pasku narzędzi.
Poczekaj na zakończenie działania przepływu danych. Gdy jest w toku, zobaczysz obrotowy wskaźnik stanu.
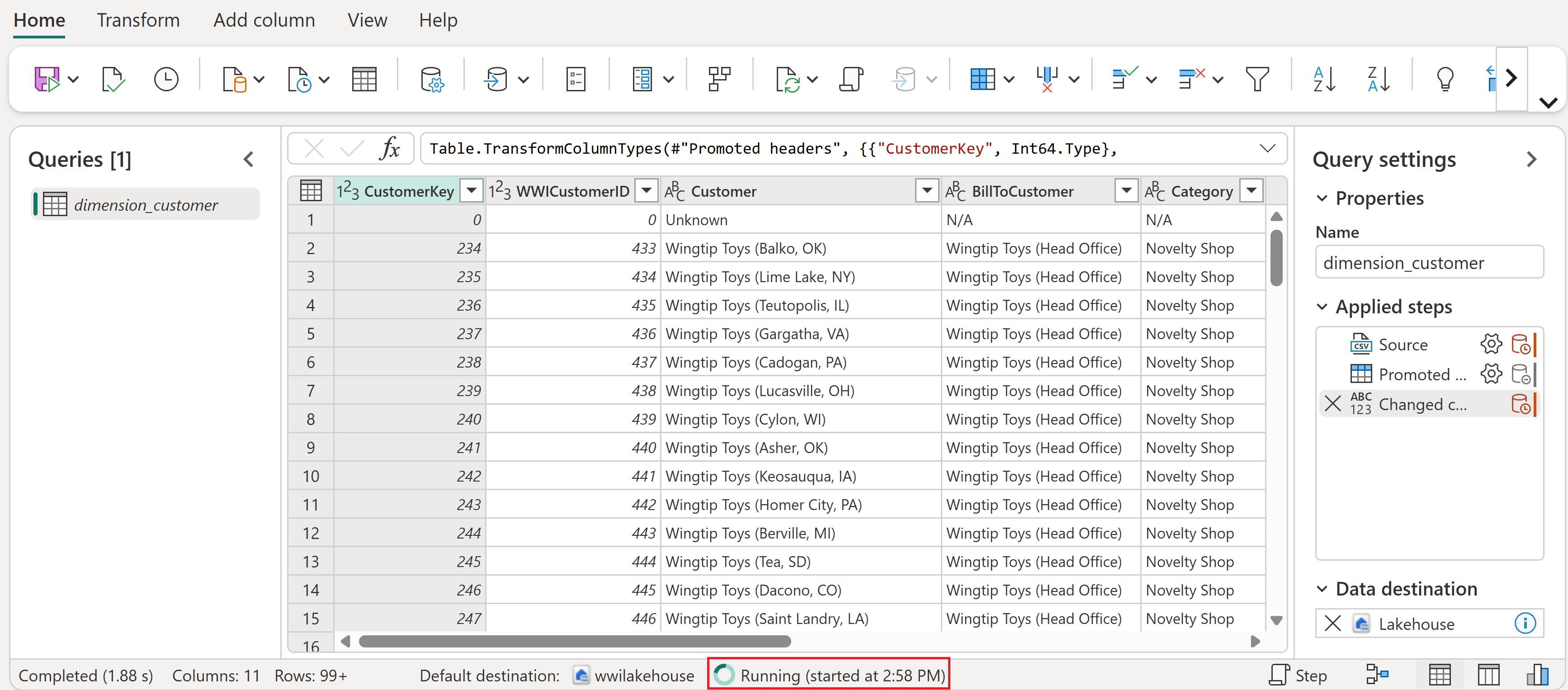
Po pomyślnym zakończeniu przebiegu przepływu danych wybierz swój Lakehouse na pasku menu u góry, aby go otworzyć.
W eksploratorze Lakehouse znajdź schemat dbo pod Tabele, wybierz menu ... (wielokropka), a następnie wybierz Odśwież. Spowoduje to uruchomienie przepływu danych i załadowanie danych z pliku źródłowego do tabeli lakehouse.
Po zakończeniu odświeżania rozwiń schemat dbo, aby wyświetlić tabelę Delta dimension_customer. Wybierz tabelę, aby wyświetlić podgląd danych.
Punkt końcowy analizy SQL usługi Lakehouse umożliwia wykonywanie zapytań dotyczących danych za pomocą instrukcji SQL. Wybierz punkt końcowy analiz SQL z menu rozwijanego w prawym górnym rogu ekranu.
Wybierz tabelę dimension_customer , aby wyświetlić podgląd danych. Aby napisać instrukcje SQL, wybierz pozycję Nowe zapytanie SQL z menu lub wybierz kafelek Nowe zapytanie SQL .
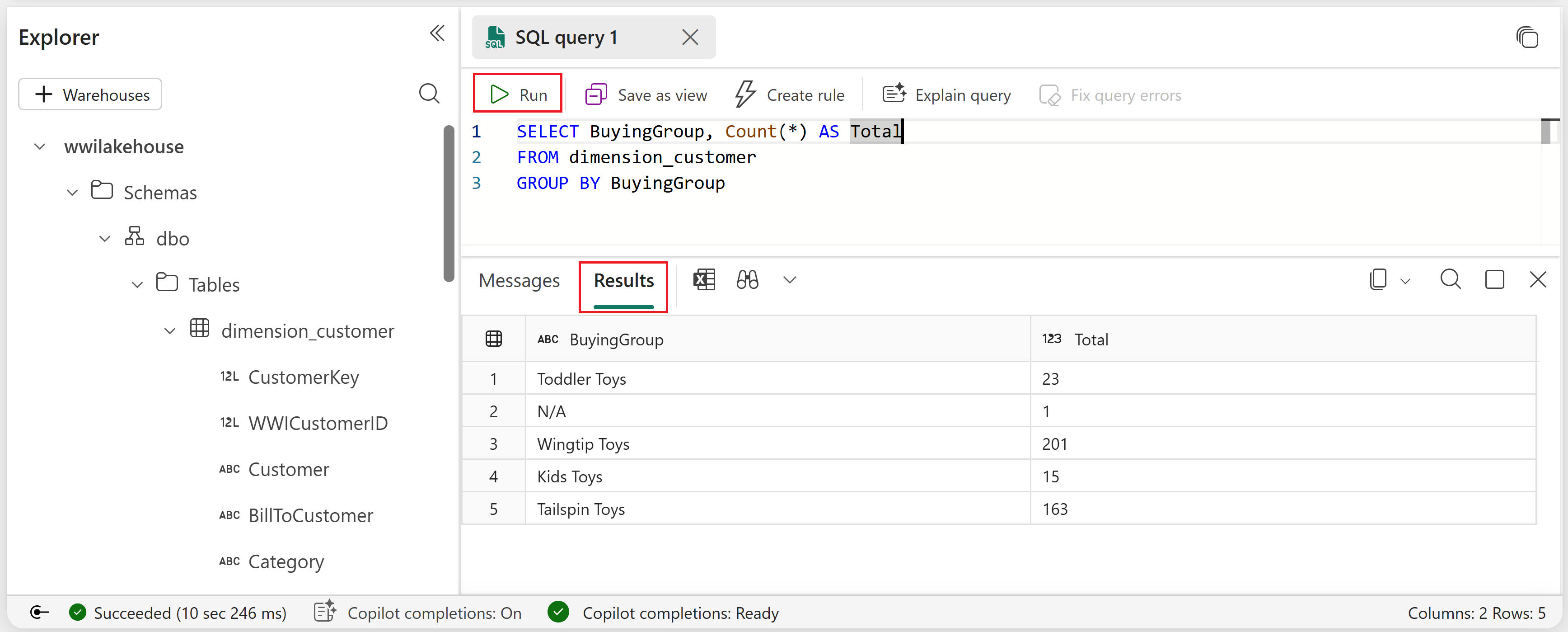
Wprowadź następujące przykładowe zapytanie, które agreguje liczbę wierszy na podstawie kolumny BuyingGroup tabeli dimension_customer .
SELECT BuyingGroup, Count(*) AS Total FROM dimension_customer GROUP BY BuyingGroupUwaga
Pliki zapytań SQL są zapisywane automatycznie w celu uzyskania przyszłego odwołania i można zmienić nazwę lub usunąć te pliki w zależności od potrzeb.
Aby uruchomić skrypt, wybierz ikonę Uruchom w górnej części pliku skryptu.







Dodawanie tabel do modelu semantycznego
W tej sekcji dodasz tabele do modelu semantycznego, aby można było ich użyć do tworzenia raportów.
Otwórz swoją usługę Lakehouse i przejdź do widoku punktu końcowego analizy SQL.
Wybierz pozycję Nowy model semantyczny.
W okienku Nowy semantyczny model wprowadź nazwę modelu semantycznego , przypisz obszar roboczy i wybierz tabele, które chcesz dodać. W takim przypadku wybierz tabelę dimension_customer.
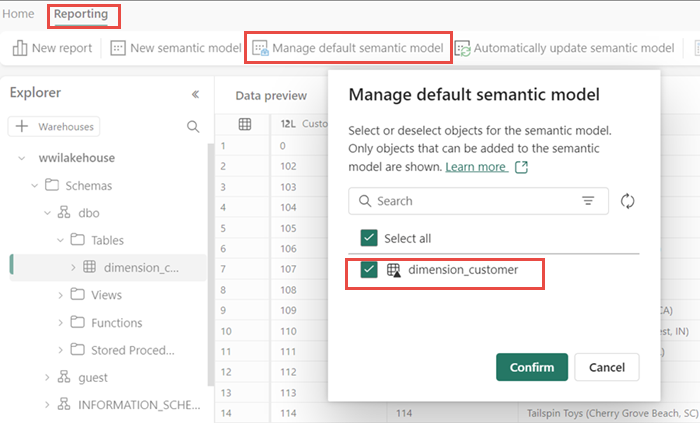
Wybierz pozycję Potwierdź , aby utworzyć model semantyczny.
Ostrzeżenie
Jeśli zostanie wyświetlony komunikat o błędzie "Nie można dodać lub usunąć tabel" z powodu przekroczenia limitów wydajności obliczeniowej sieci szkieletowej organizacji, zaczekaj kilka minut i spróbuj ponownie. Aby uzyskać więcej informacji, zobacz dokumentację pojemności sieci szkieletowej.
Model semantyczny jest tworzony w trybie przechowywania usługi Direct Lake, co oznacza, że odczytuje dane bezpośrednio z tabel delta w usłudze OneLake w celu zapewnienia szybkiej wydajności zapytań bez konieczności importowania danych. Po utworzeniu można edytować semantyczny model, aby dodać relacje, miary i nie tylko.
Wskazówka
Aby dowiedzieć się więcej na temat usługi Direct Lake i jej korzyści, zobacz Omówienie usługi Direct Lake.

Tworzenie raportu
W tej sekcji utworzysz raport z utworzonego modelu semantycznego.
W obszarze roboczym znajdź utworzony model semantyczny, wybierz menu ... (wielokropek), a następnie wybierz pozycję Automatycznie utwórz raport.
Tabela jest wymiarem i nie ma w niej żadnych miar. Usługa Power BI tworzy miarę dla liczby wierszy, agreguje ją w różnych kolumnach i tworzy różne wykresy, jak pokazano na poniższym zrzucie ekranu.
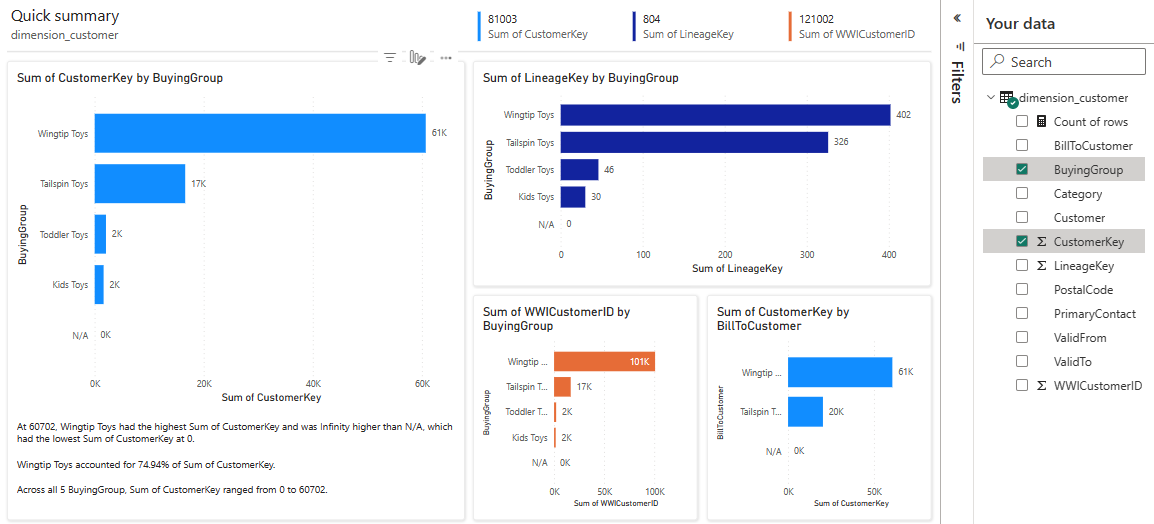
Ten raport można zapisać w przyszłości, wybierając pozycję Zapisz na górnej wstążce. Aby spełnić wymagania, możesz wprowadzić więcej zmian w tym raporcie, włączając lub wykluczając inne tabele lub kolumny.

