Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W tym artykule wyjaśniono, jak działa integracja z Gitem i potoki wdrożeniowe dla funkcji przetwarzania danych użytkownika w Microsoft Fabric. Dzięki integracji z usługą Git możesz synchronizować obszar roboczy usługi Fabric z gałęzią repozytorium, umożliwiając kontrolowanie wersji funkcji danych użytkownika, współpracę przy użyciu gałęzi i żądań ściągnięcia oraz pracę z kodem w preferowanym narzędziu Git, takim jak Usługa Azure DevOps.
Dowiedz się więcej na temat procesu integrowania usługi Git z obszarem roboczym usługi Microsoft Fabric w temacie Podstawowe pojęcia dotyczące integracji z usługą Git.
Konfigurowanie połączenia
Z poziomu ustawień obszaru roboczego można łatwo skonfigurować połączenie z repozytorium w celu zatwierdzania i synchronizowania zmian. Aby skonfigurować połączenie, zobacz Wprowadzenie do integracji z usługą Git. Po nawiązaniu połączenia elementy, w tym funkcje danych użytkownika, są wyświetlane w okienku Kontrola źródła .

Po pomyślnym zatwierdzeniu elementów funkcji danych użytkownika w repozytorium Git zobaczysz foldery funkcji danych użytkownika w repozytorium. Teraz możesz wykonywać operacje dotyczące przyszłych działań, takie jak stworzenie pull requesta.
Reprezentacja funkcji danych użytkownika w usłudze Git
Na poniższej ilustracji przedstawiono przykład struktury plików każdego elementu funkcji danych użytkownika w repozytorium.

Struktura folderów zawiera następujące elementy:
.platform:
.platformplik zawiera następujące atrybuty: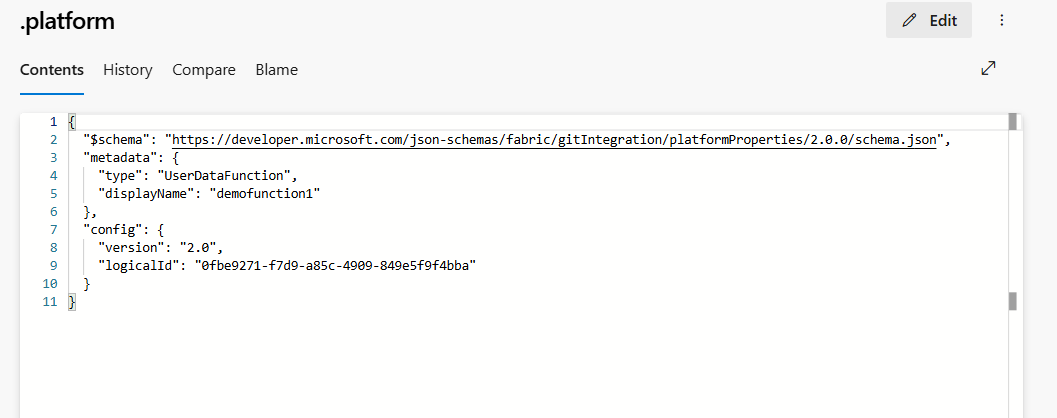
- version: numer wersji plików systemowych. Ta liczba służy do włączania zgodności z poprzednimi wersjami. Numer wersji elementu może być inny.
- logicalId: automatycznie wygenerowany identyfikator między obszarami roboczymi reprezentujący element i jego reprezentację kontroli źródła.
-
type:
UserDataFunctionjest typem do zdefiniowania elementu funkcji danych użytkownika. - displayName: reprezentuje nazwę elementu. Gdy nazwa elementu funkcji danych użytkownika zostanie zmieniona, ta nazwa displayName zostanie zaktualizowana.
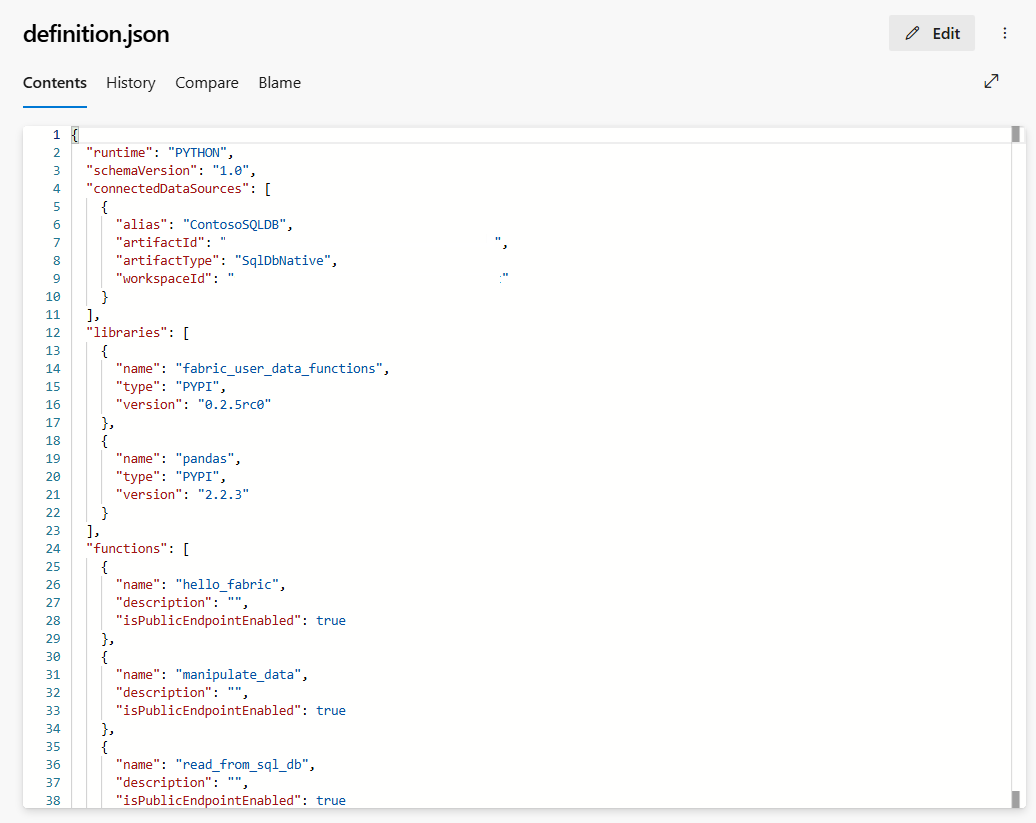
definitions.json: ten plik udostępnia wszystkie definicje elementów funkcji danych użytkownika, takie jak połączenia, biblioteki itp., jako reprezentacja właściwości elementu funkcji danych użytkownika.
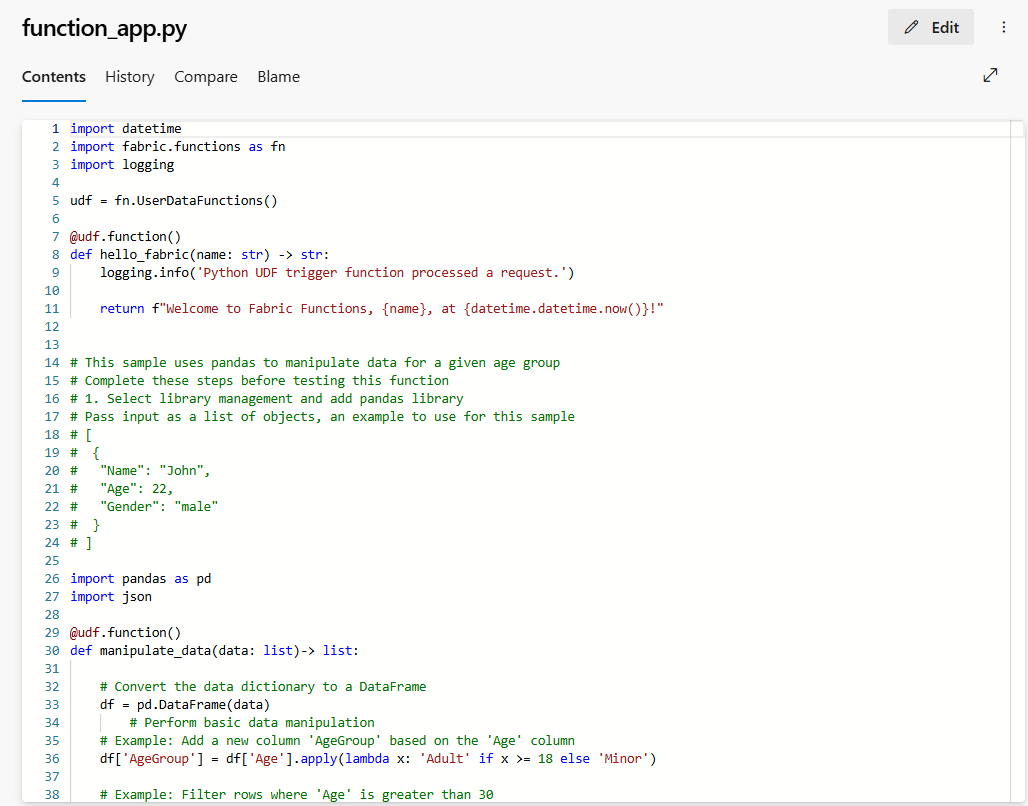
function-app.py: ten plik jest twoim kodem funkcji. Wszelkie zmiany kodu wprowadzone w elemencie funkcji danych użytkownika są synchronizowane z repozytorium przy użyciu tego pliku. Aby zarządzać cyklem tworzenia kodu, można wykonywać różne operacje git.
resources: folder zawiera plik functions.json ze wszystkimi metadanymi, takimi jak połączenia, biblioteki i funkcje w tym elemencie. NIE AKTUALIZUJ TEGO PLIKU ręcznie.
functions.jsonumożliwia platformie Fabric tworzenie lub odtwarzanie funkcji danych użytkownika w obszarze roboczym.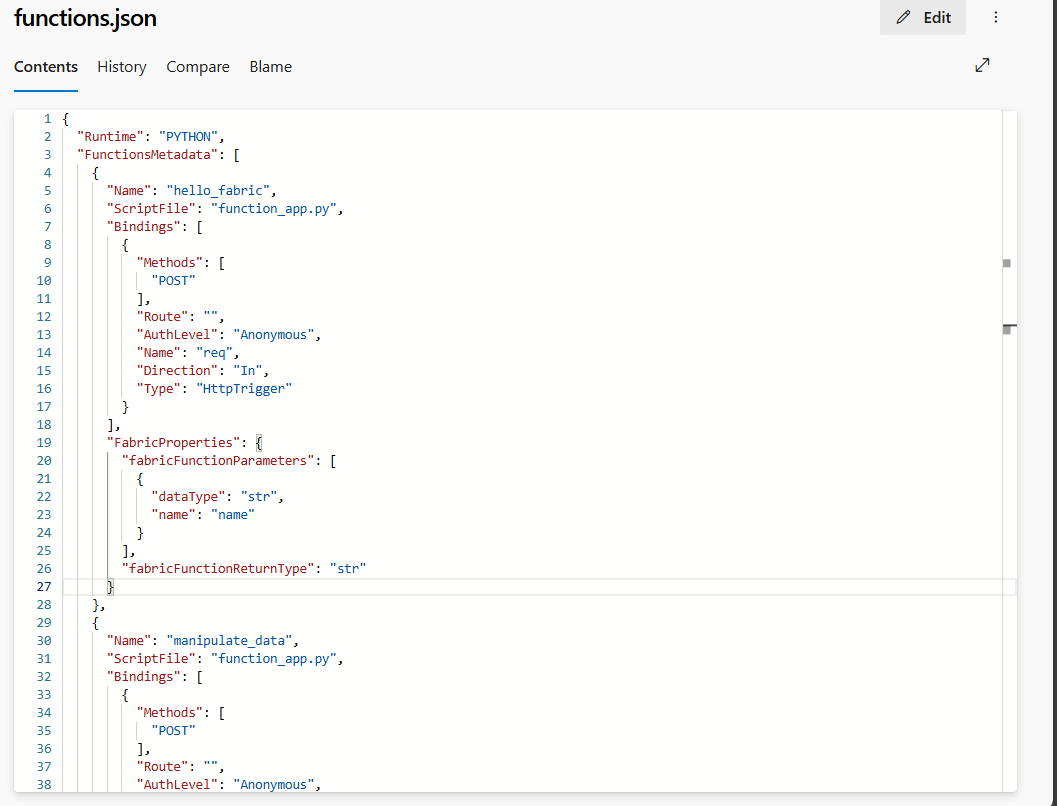




Aby uzyskać więcej informacji na temat integracji z usługą Git, w tym szczegółowe informacje o strukturze folderów i plikach systemowych, zobacz Format kodu źródłowego integracji git.
Funkcje danych użytkownika w potokach wdrażania
Potoki wdrażania umożliwiają wdrażanie funkcji danych użytkownika w różnych środowiskach, takich jak programowanie, testowanie i produkcja. Potoki wdrażania pomagają usprawnić proces programowania, zapewnić jakość i spójność oraz zmniejszyć błędy ręczne przy użyciu lekkich operacji z małą ilością kodu.
Uwaga
Wszystkie połączenia i biblioteki są dodawane do nowych elementów funkcji danych użytkownika utworzonych w innych środowiskach.
Aby wdrożyć funkcje danych użytkownika przy użyciu pipeline'u wdrażania:
Utwórz nową linię przetwarzania lub otwórz istniejącą linię przetwarzania. Aby uzyskać więcej informacji, zobacz Rozpocznij pracę z potokami wdrażania.
Przypisz obszary robocze do różnych etapów zgodnie z celami wdrożenia.
Wybierz, wyświetl i porównaj elementy, w tym elementy funkcji danych użytkownika między różnymi etapami.
Wybierz pozycję Wdróż , aby wdrożyć element funkcji danych użytkownika w środowisku testowym. Możesz dodać notatkę, aby podać szczegółowe informacje o zmianach dla tego wdrożenia. Podobnie można wdrażać zmiany na etapy rozwojowy, testowy i produkcyjny.
Monitoruj stan wdrożenia z historii wdrożenia.