Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W tym artykule opisano sposób używania działania kopiowania w potoku danych do kopiowania danych z usługi Amazon RDS dla programu SQL Server.
Obsługiwana konfiguracja
W przypadku konfiguracji każdej karty w działaniu kopiowania przejdź odpowiednio do poniższych sekcji.
Ogólne
Zapoznaj się ze wskazówkami dotyczącymi ustawień ogólnych, aby skonfigurować kartę Ustawienia ogólne.
Źródło
Następujące właściwości są obsługiwane w przypadku usług Amazon RDS dla programu SQL Server na karcie Źródło działania kopiowania.
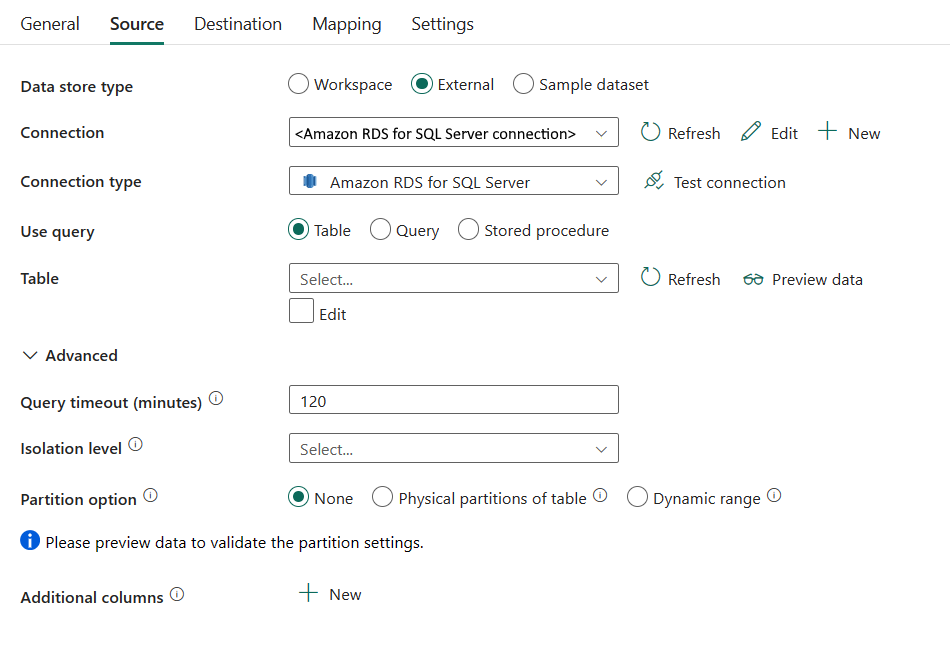
Wymagane są następujące właściwości:
Typ magazynu danych: wybierz pozycję Zewnętrzne.
Połączenie: wybierz połączenie usługi Amazon RDS dla programu SQL Server z listy połączeń. Jeśli połączenie nie istnieje, utwórz nową usługę Amazon RDS dla połączenia z programem SQL Server, wybierając pozycję Nowy.
Typ połączenia: wybierz pozycję Amazon RDS dla programu SQL Server.
Użyj zapytania: określ sposób odczytywania danych. Możesz wybrać tabelę, kwerendę lub procedurę składowaną. Poniższa lista zawiera opis konfiguracji każdego ustawienia:
Tabela: odczyt danych z określonej tabeli. Wybierz tabelę źródłową z listy rozwijanej lub wybierz pozycję Edytuj , aby wprowadzić ją ręcznie.
Zapytanie: określ niestandardowe zapytanie SQL do odczytu danych. Może to być na przykład
select * from MyTable. Możesz też wybrać ikonę ołówka, aby edytować w edytorze kodu.
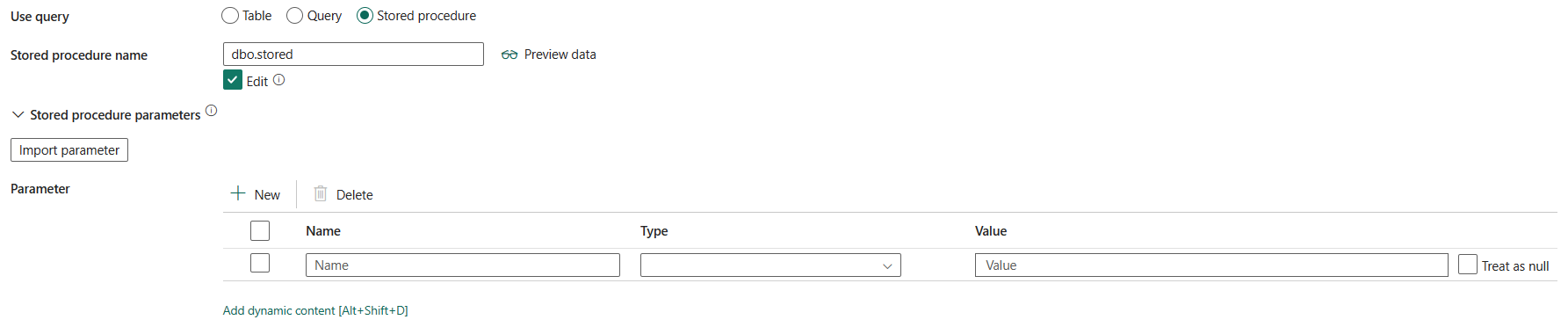
Procedura składowana: użyj procedury składowanej, która odczytuje dane z tabeli źródłowej. Ostatnia instrukcja SQL musi być instrukcją SELECT w procedurze składowanej.
Nazwa procedury składowanej: wybierz procedurę składowaną lub określ nazwę procedury składowanej ręcznie podczas wybierania pozycji Edytuj , aby odczytać dane z tabeli źródłowej.
Parametry procedury składowanej: określ wartości parametrów procedury składowanej. Dozwolone wartości to pary nazw lub wartości. Nazwy i wielkość liter parametrów muszą być zgodne z nazwami i wielkością parametrów procedury składowanej. Możesz wybrać pozycję Importuj parametry , aby uzyskać parametry procedury składowanej.
W obszarze Zaawansowane można określić następujące pola:
Limit czasu zapytania (minuty): określ limit czasu wykonywania polecenia zapytania, wartość domyślna to 120 minut. Jeśli parametr jest ustawiony dla tej właściwości, dozwolone wartości to przedział czasu, taki jak "02:00:00" (120 minut).
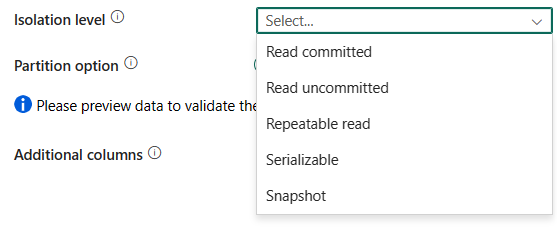
Poziom izolacji: określa zachowanie blokowania transakcji dla źródła SQL. Dozwolone wartości to: Odczyt zatwierdzony, Odczyt niezatwierdzony, Powtarzalny odczyt, Serializable, Migawka. Jeśli nie zostanie określony, zostanie użyty domyślny poziom izolacji bazy danych. Aby uzyskać więcej informacji, zapoznaj się z wyliczeniem IsolationLevel.
Opcja partycji: określ opcje partycjonowania danych używane do ładowania danych z usługi Amazon RDS dla programu SQL Server. Dozwolone wartości to: Brak (wartość domyślna), Partycje fizyczne tabeli i Zakres dynamiczny. Jeśli opcja partycji jest włączona (czyli nie brak), stopień równoległości równoczesnego ładowania danych z usługi Amazon RDS dla programu SQL Server jest kontrolowany przez stopień równoległości kopiowania na karcie ustawień działania kopiowania.
Brak: wybierz to ustawienie, aby nie używać partycji.
Fizyczne partycje tabeli: w przypadku korzystania z partycji fizycznej kolumna partycji i mechanizm są automatycznie określane na podstawie definicji tabeli fizycznej.
Zakres dynamiczny: w przypadku używania zapytania z włączonym równoległym parametrem partycji zakresu (
?DfDynamicRangePartitionCondition) jest wymagany. Przykładowe zapytanie:SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition.Nazwa kolumny partycji: określ nazwę kolumny źródłowej w liczbach całkowitych lub typ daty/daty/godziny (
int,smallint,smalldatetimebigintdatetimedate,datetime2lubdatetimeoffset) używany przez partycjonowanie zakresu na potrzeby kopiowania równoległego. Jeśli nie zostanie określony, indeks lub klucz podstawowy tabeli zostanie automatycznie wykryty i użyty jako kolumna partycji.Jeśli używasz zapytania do pobierania danych źródłowych, należy podłączyć
?DfDynamicRangePartitionConditionsię do klauzuli WHERE. Aby zapoznać się z przykładem, zobacz sekcję Kopiowanie równoległe z bazy danych SQL.Górna granica partycji: określ maksymalną wartość kolumny partycji dla podziału zakresu partycji. Ta wartość służy do decydowania o kroku partycji, a nie do filtrowania wierszy w tabeli. Wszystkie wiersze w tabeli lub wyniku zapytania zostaną podzielone na partycje i skopiowane. Jeśli nie zostanie określony, działanie kopiowania automatycznie wykrywa wartość. Aby zapoznać się z przykładem, zobacz sekcję Kopiowanie równoległe z bazy danych SQL.
Dolna granica partycji: określ minimalną wartość kolumny partycji dla podziału zakresu partycji. Ta wartość służy do decydowania o kroku partycji, a nie do filtrowania wierszy w tabeli. Wszystkie wiersze w tabeli lub wyniku zapytania zostaną podzielone na partycje i skopiowane. Jeśli nie zostanie określony, działanie kopiowania automatycznie wykrywa wartość. Aby zapoznać się z przykładem, zobacz sekcję Kopiowanie równoległe z bazy danych SQL.
Dodatkowe kolumny: Dodaj dodatkowe kolumny danych, aby przechowywać ścieżkę względną plików źródłowych lub wartość statyczną. Wyrażenie jest obsługiwane w przypadku tych ostatnich.
Należy uwzględnić następujące informacje:
- Jeśli zapytanie jest określone dla źródła, działanie kopiowania uruchamia to zapytanie względem źródła usługi Amazon RDS dla programu SQL Server w celu pobrania danych. Można również określić procedurę składowaną, określając nazwę procedury składowanej i parametry procedury składowanej, jeśli procedura składowana przyjmuje parametry .
- W przypadku używania procedury składowanej w źródle do pobierania danych należy pamiętać, że procedura składowana jest zaprojektowana jako zwracanie innego schematu po przekazaniu innej wartości parametru, może wystąpić błąd lub nieoczekiwany wynik podczas importowania schematu z interfejsu użytkownika lub kopiowania danych do bazy danych SQL z automatycznym tworzeniem tabeli.
Mapowanie
W obszarze Konfiguracja karty Mapowanie przejdź do tematu Konfigurowanie mapowań na karcie mapowania.
Ustawienia
W obszarze Konfiguracja karty Ustawienia przejdź do sekcji Konfigurowanie innych ustawień na karcie ustawienia.
Równoległa kopia z bazy danych SQL
Łącznik Amazon RDS for SQL Server w działaniu kopiowania zapewnia wbudowane partycjonowanie danych w celu równoległego kopiowania danych. Opcje partycjonowania danych można znaleźć na karcie Źródło działania kopiowania.
Po włączeniu kopii partycjonowanej działanie kopiowania uruchamia zapytania równoległe względem źródła usługi Amazon RDS dla programu SQL Server w celu załadowania danych według partycji. Stopień równoległy jest kontrolowany przez stopień równoległości kopiowania na karcie ustawień działania kopiowania. Jeśli na przykład ustawisz opcję Stopień równoległości kopiowania na cztery, usługa jednocześnie generuje i uruchamia cztery zapytania na podstawie określonej opcji partycji i ustawień, a każde zapytanie pobiera część danych z usługi Amazon RDS dla programu SQL Server.
Zaleca się włączenie kopiowania równoległego przy użyciu partycjonowania danych, szczególnie w przypadku ładowania dużej ilości danych z usług Amazon RDS dla programu SQL Server. Poniżej przedstawiono sugerowane konfiguracje dla różnych scenariuszy. Podczas kopiowania danych do magazynu danych opartego na plikach zaleca się zapisywanie w folderze jako wielu plików (tylko określ nazwę folderu), w tym przypadku wydajność jest lepsza niż zapisywanie w jednym pliku.
| Scenariusz | Sugerowane ustawienia |
|---|---|
| Pełne ładowanie z dużej tabeli z partycjami fizycznymi. | Opcja partycji: fizyczne partycje tabeli. Podczas wykonywania usługa automatycznie wykrywa partycje fizyczne i kopiuje dane według partycji. Aby sprawdzić, czy tabela ma partycję fizyczną, czy nie, możesz odwołać się do tego zapytania. |
| Pełne ładowanie z dużej tabeli, bez partycji fizycznych, podczas gdy z liczbą całkowitą lub kolumną datetime na potrzeby partycjonowania danych. | Opcje partycji: partycja zakresu dynamicznego. Kolumna partycji (opcjonalnie): określ kolumnę używaną do partycjonowania danych. Jeśli nie zostanie określona, zostanie użyta kolumna klucza podstawowego. Górna granica partycji i dolna granica partycji (opcjonalnie): określ, czy chcesz określić krok partycji. Nie dotyczy to filtrowania wierszy w tabeli. Wszystkie wiersze w tabeli zostaną podzielone na partycje i skopiowane. Jeśli nie zostanie określony, działanie kopiowania automatycznie wykrywa wartości i może zająć dużo czasu w zależności od wartości MIN i MAX. Zaleca się podanie górnej granicy i dolnej granicy. Jeśli na przykład kolumna partycji "ID" zawiera wartości z zakresu od 1 do 100, a dolna granica zostanie ustawiona na wartość 20, a górna granica to 80, z kopią równoległą jako 4, usługa pobiera dane według 4 partycji — identyfikatory w zakresie <=20, [21, 50], [51, 80] i >=81. |
| Załaduj dużą ilość danych przy użyciu zapytania niestandardowego, bez partycji fizycznych, natomiast z liczbą całkowitą lub kolumną date/datetime na potrzeby partycjonowania danych. | Opcje partycji: partycja zakresu dynamicznego. Zapytanie: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>.Kolumna partycji: określ kolumnę używaną do partycjonowania danych. Górna granica partycji i dolna granica partycji (opcjonalnie): określ, czy chcesz określić krok partycji. Nie jest to przeznaczone do filtrowania wierszy w tabeli, wszystkie wiersze w wyniku zapytania zostaną partycjonowane i skopiowane. Jeśli nie zostanie określony, działanie kopiowania automatycznie wykrywa wartość. Jeśli na przykład kolumna partycji "ID" zawiera wartości z zakresu od 1 do 100, a dolna granica zostanie ustawiona jako 20 i górna granica jako 80, z kopią równoległą jako 4, usługa pobiera dane według 4 partycji — identyfikatory w zakresie <=20, [21, 50], [51, 80] i >=81. Poniżej przedstawiono więcej przykładowych zapytań dla różnych scenariuszy: • Wykonaj zapytanie dotyczące całej tabeli: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition• Kwerenda z tabeli z zaznaczeniem kolumny i dodatkowymi filtrami klauzuli where: SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>• Kwerenda z podzapytaniami: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>• Zapytanie z partycją w podzapytaniu: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
Najlepsze rozwiązania dotyczące ładowania danych z opcją partycji:
- Wybierz charakterystyczną kolumnę jako kolumnę partycji (np. klucz podstawowy lub unikatowy klucz), aby uniknąć niesymetryczności danych.
- Jeśli tabela ma wbudowaną partycję, użyj opcji partycji Partycja Partycje fizyczne tabeli , aby uzyskać lepszą wydajność.
Przykładowe zapytanie do sprawdzania partycji fizycznej
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, pf.name AS PartitionFunctionName, c.name AS ColumnName, iif(pf.name is null, 'no', 'yes') AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.partition_schemes ps ON i.data_space_id = ps.data_space_id
LEFT JOIN sys.partition_functions pf ON pf.function_id = ps.function_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
Jeśli tabela ma partycję fizyczną, zostanie wyświetlona wartość "HasPartition" jako "tak", jak pokazano poniżej.

Podsumowanie tabeli
Zobacz poniższą tabelę, aby uzyskać podsumowanie i więcej informacji na temat działania kopiowania usługi Amazon RDS dla programu SQL Server.
Informacje źródłowe
| Nazwa/nazwisko | Opis | Wartość | Wymagania | Właściwość skryptu JSON |
|---|---|---|---|---|
| Typ magazynu danych | Typ magazynu danych. | Zewnętrzne | Tak | / |
| Połączenie | Połączenie ze źródłowym magazynem danych. | < połączenie > | Tak | połączenie |
| Connection type (Typ połączenia) | Typ połączenia. Wybierz pozycję Amazon RDS dla programu SQL Server. | Usługa Amazon RDS dla programu SQL Server | Tak | / |
| Korzystanie z zapytania | Niestandardowe zapytanie SQL służące do odczytywania danych. | •Stół •Zapytanie • Procedura składowana |
Tak | / |
| Tabela | Tabela danych źródłowych. | < nazwa tabeli docelowej> | Nie. | schemat table |
| Zapytanie | Niestandardowe zapytanie SQL służące do odczytywania danych. | < zapytanie > | Nie. | sqlReaderQuery |
| Nazwa procedury składowanej | Ta właściwość jest nazwą procedury składowanej, która odczytuje dane z tabeli źródłowej. Ostatnia instrukcja SQL musi być instrukcją SELECT w procedurze składowanej. | < nazwa procedury składowanej > | Nie. | sqlReaderStoredProcedureName |
| Parametr procedury składowanej | Te parametry są przeznaczone dla procedury składowanej. Dozwolone wartości to pary nazw lub wartości. Nazwy i wielkość liter parametrów muszą być zgodne z nazwami i wielkością parametrów procedury składowanej. | < pary nazw lub wartości > | Nie. | storedProcedureParameters |
| Limit czasu zapytania | Limit czasu wykonywania polecenia zapytania. | zakres czasu (wartość domyślna to 120 minut) |
Nie. | queryTimeout |
| Poziom izolacji | Określa zachowanie blokowania transakcji dla źródła SQL. | • Odczyt zatwierdzony • Odczytywanie niezatwierdzonych • Powtarzalny odczyt •Serializacji •Migawka |
Nie. | isolationLevel: • ReadCommitted • ReadUncommitted • Powtarzalny odczyt •Serializacji •Migawka |
| Opcja partycji | Opcje partycjonowania danych używane do ładowania danych z usługi Amazon RDS dla programu SQL Server. | • Brak (wartość domyślna) • Fizyczne partycje tabeli • Zakres dynamiczny |
Nie. | partitionOption: • Brak (wartość domyślna) • PhysicalPartitionsOfTable • DynamicRange |
| Nazwa kolumny partycji | Nazwa kolumny źródłowej w integerze lub typie daty/daty/godziny (int, smallint, bigintdatetimedatetime2datesmalldatetimelub datetimeoffset) używanym przez partycjonowanie zakresu na potrzeby kopiowania równoległego. Jeśli nie zostanie określony, indeks lub klucz podstawowy tabeli zostanie automatycznie wykryty i użyty jako kolumna partycji. Jeśli używasz zapytania do pobierania danych źródłowych, należy podłączyć ?DfDynamicRangePartitionCondition się do klauzuli WHERE. |
< nazwy kolumn partycji > | Nie. | partitionColumnName |
| Górna granica partycji | Maksymalna wartość kolumny partycji dla podziału zakresu partycji. Ta wartość służy do decydowania o kroku partycji, a nie do filtrowania wierszy w tabeli. Wszystkie wiersze w tabeli lub wyniku zapytania zostaną podzielone na partycje i skopiowane. Jeśli nie zostanie określony, działanie kopiowania automatycznie wykrywa wartość. | < górna granica partycji > | Nie. | partitionUpperBound |
| Dolna granica partycji | Minimalna wartość kolumny partycji dla podziału zakresu partycji. Ta wartość służy do decydowania o kroku partycji, a nie do filtrowania wierszy w tabeli. Wszystkie wiersze w tabeli lub wyniku zapytania zostaną podzielone na partycje i skopiowane. Jeśli nie zostanie określony, działanie kopiowania automatycznie wykrywa wartość. | < dolna granica partycji > | Nie. | partitionLowerBound |
| Dodatkowe kolumny | Dodaj dodatkowe kolumny danych, aby przechowywać ścieżkę względną plików źródłowych lub wartość statyczną. Wyrażenie jest obsługiwane w przypadku tych ostatnich. | • Nazwa •Wartość |
Nie. | additionalColumns: •nazwa •wartość |