Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W tym artykule opisano sposób używania działania kopiowania w potoku danych do kopiowania danych z i do bazy danych SQL.
Obsługiwana konfiguracja
For the configuration of each tab under copy activity, go to the following sections respectively.
General
Refer to the General settings guidance to configure the General settings tab.
Źródło
The following properties are supported for SQL database under the Source tab of a copy activity.

The following properties are required:
Connection: Select an existing SQL database referring to the step in this article.
Use query: You can choose Table, Query, or Stored procedure. Poniższa lista zawiera opis konfiguracji każdego ustawienia:
Table: określ nazwę bazy danych SQL, aby odczytywać dane. Wybierz istniejącą tabelę z listy rozwijanej lub wybierz pozycję Wprowadź ręcznie, aby wprowadzić nazwę schematu i tabeli.
Zapytanie: określ niestandardowe zapytanie SQL do odczytu danych. Przykładem jest
select * from MyTable. Możesz też wybrać ikonę ołówka, aby edytować w edytorze kodu.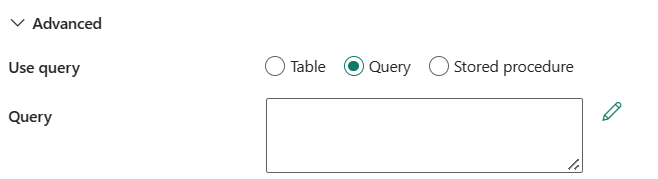
Stored procedure: Select the stored procedure from the drop-down list.

W obszarze Advancedmożna określić następujące pola:
limit czasu zapytania (w minutach): określ limit czasu wykonywania polecenia zapytania, wartość domyślna to 120 minut. Jeśli parametr jest ustawiony dla tej właściwości, dozwolone wartości są przedziałem czasu, takim jak "02:00:00" (120 minut).
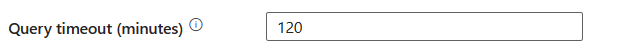
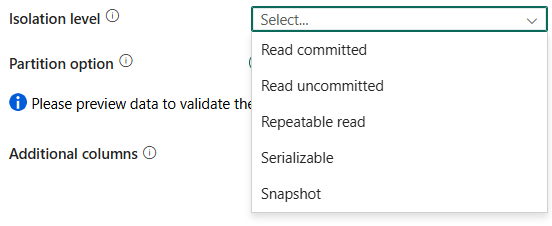
poziom izolacji: określa zachowanie blokowania transakcji dla źródła SQL. The allowed values are: Read committed, Read uncommitted, Repeatable read, Serializable, or Snapshot. Aby uzyskać więcej informacji, zobacz IsolationLevel Enum.
Opcja partycjonowania: Wybierz opcje partycjonowania danych używane do ładowania danych z bazy danych SQL. Allowed values are: None (default), Physical partitions of table, and Dynamic range. When a partition option is enabled (that is, not None), the degree of parallelism to concurrently load data from an SQL database is controlled by Degree of copy parallelism in copy activity settings tab.
Brak: wybierz to ustawienie, aby nie używać partycji.
Partycje fizyczne tabeli: W przypadku korzystania z partycji fizycznej, kolumna partycji i mechanizm są automatycznie ustalane na podstawie definicji tabeli fizycznej.
Dynamic range: When using query with parallel enabled, the range partition parameter(
?DfDynamicRangePartitionCondition) is needed. Przykładowe zapytanie:SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition.Partition column name: Specify the name of the source column in integer or date/datetime type (
int,smallint,bigint,date,smalldatetime,datetime,datetime2, ordatetimeoffset) that's used by range partitioning for parallel copy. Jeśli nie zostanie określony, indeks lub klucz podstawowy tabeli zostanie automatycznie wykryty i użyty jako kolumna partycji.Jeśli używasz zapytania do pobierania danych źródłowych, podłącz
?DfDynamicRangePartitionConditionw klauzuli WHERE. For an example, see the Parallel copy from SQL database section.Górna granica partycji: określ maksymalną wartość kolumny partycji dla podziału zakresu partycji. Ta wartość służy do decydowania o kroku partycji, a nie do filtrowania wierszy w tabeli. All rows in the table or query result will be partitioned and copied. Jeśli nie zostanie określona, operacja kopiowania automatycznie wykryje wartość. For an example, see the Parallel copy from SQL database section.
Partition lower bound: Specify the minimum value of the partition column for partition range splitting. Ta wartość służy do decydowania o kroku partycji, a nie do filtrowania wierszy w tabeli. All rows in the table or query result will be partitioned and copied. Jeśli nie zostanie określona, operacja kopiowania automatycznie wykryje wartość. For an example, see the Parallel copy from SQL database section.
dodatkowe kolumny: dodaj więcej kolumn danych, aby przechowywać ścieżkę względną plików źródłowych lub wartość statyczną. Expression is supported for the latter. For more information, go to Add additional columns during copy.


Destination
The following properties are supported for SQL database under the Destination tab of a copy activity.

The following properties are required:
Connection: Select an existing SQL database referring to the step in this article.
Table option: Select from Use existing or Auto create table.
W przypadku wybrania opcji Użyj istniejącej:
- Table: określ nazwę bazy danych SQL do zapisywania danych. Wybierz istniejącą tabelę z listy rozwijanej lub wybierz pozycję Wprowadź ręcznie, aby wprowadzić nazwę schematu i tabeli.
W przypadku wybrania opcji Automatyczne tworzenie tabeli:
- Table: It automatically creates the table (if nonexistent) in source schema, which is not supported when stored procedure is used as write behavior.
W obszarze Advancedmożna określić następujące pola:
zachowanie zapisu: definiuje zachowanie zapisu, gdy źródłem są pliki z magazynu danych opartego na plikach. You can choose Insert, Upsert or Stored procedure.

Wstaw: wybierz tę opcję, jeśli dane źródłowe zawierają wstawki.
Upsert: Choose this option if your source data has both inserts and updates.
Użyj bazy danych TempDB: Określ, czy używać globalnej tabeli tymczasowej, czy tabeli fizycznej jako tabeli pośredniej dla operacji upsert. Domyślnie usługa używa globalnej tabeli tymczasowej jako tabeli pośredniej, a to pole wyboru jest zaznaczone.
Jeśli zapisujesz duże ilości danych w bazie danych SQL, usuń zaznaczenie tego pola i określ nazwę schematu, w którym usługa Data Factory utworzy tabelę przejściową w celu załadowania danych nadrzędnych i automatycznego czyszczenia po zakończeniu. Upewnij się, że użytkownik ma uprawnienie do tworzenia tabeli w bazie danych i zmień uprawnienia w schemacie. If not specified, a global temp table is used as staging.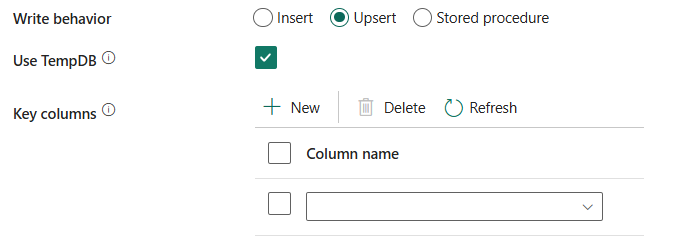
Select user DB schema: When the Use TempDB isn't selected, specify a schema name under which Data Factory will create a staging table to load upstream data and automatically clean them up upon completion. Upewnij się, że masz uprawnienie do tworzenia tabeli w bazie danych i zmień uprawnienia w schemacie.
Notatka
Musisz mieć uprawnienia do tworzenia i usuwania tabel. Domyślnie tabela tymczasowa będzie współdzielić ten sam schemat co tabela docelowa.
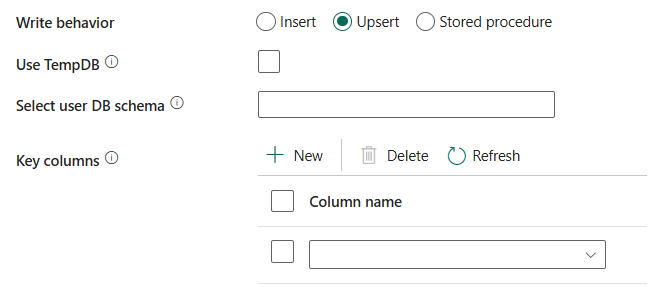
Kolumny klucza: wybierz kolumnę używaną do określenia, czy wiersz ze źródła pasuje do wiersza z miejsca docelowego.
Nazwa procedury składowanej: Wybierz procedurę składowaną z listy rozwijanej.
Bulk insert table lock: Choose Yes or No. Use this setting to improve copy performance during a bulk insert operation on a table with no index from multiple clients. Aby uzyskać więcej informacji, przejdź do BULK INSERT (Transact-SQL)
skrypt przed kopiowaniem: określ skrypt, który ma zostać wykonany przed zapisaniem danych w tabeli docelowej w każdym uruchomieniu. Za pomocą tej właściwości można wyczyścić wstępnie załadowane dane.
Write batch timeout: Specify the wait time for the batch insert operation to finish before it times out. The allowed value is timespan. Wartość domyślna to "00:30:00" (30 minut).
Zapisuj rozmiar partii: określ liczbę wierszy do wstawienia do tabeli SQL na partię. Dozwolona wartość to liczba całkowita (liczba wierszy). Domyślnie usługa dynamicznie określa odpowiedni rozmiar partii na podstawie rozmiaru wiersza.
Max concurrent connections: Specify the upper limit of concurrent connections established to the data store during the activity run. Określ wartość tylko wtedy, gdy chcesz ograniczyć połączenia współbieżne.


Mapowanie
For the Mapping tab configuration, if you don't apply SQL database with auto create table as your destination, go to Mapping.
If you apply SQL database with auto create table as your destination, except the configuration in Mapping, you can edit the type for your destination columns. Po wybraniu Importuj schematymożna określić typ kolumny w miejscu docelowym.
For example, the type for ID column in source is int, and you can change it to float type when mapping to the destination column.

Ustawienia
For Settings tab configuration, go to Configure your other settings under settings tab.
Równoległa kopia z bazy danych SQL
Łącznik bazy danych SQL w działaniu kopiowania zapewnia wbudowane partycjonowanie danych w celu równoległego kopiowania danych. You can find data partitioning options on the Source tab of the copy activity.
Po włączeniu kopii partycjonowanej działanie kopiowania uruchamia zapytania równoległe względem źródła bazy danych SQL w celu załadowania danych według partycji. Stopień równoległy jest kontrolowany przez Stopień równoległości kopiowania na karcie ustawień działania kopiowania. Jeśli na przykład ustawisz stopień równoległości kopiowania na cztery, usługa jednocześnie generuje i uruchamia cztery zapytania na podstawie określonej opcji partycji i ustawień, a każde zapytanie pobiera część danych z bazy danych SQL.
Zaleca się włączenie kopiowania równoległego przy użyciu partycjonowania danych, szczególnie w przypadku ładowania dużej ilości danych z bazy danych SQL. Poniżej przedstawiono sugerowane konfiguracje dla różnych scenariuszy. Podczas kopiowania danych do magazynu danych opartego na plikach zaleca się zapisywanie w folderze jako wielu plików (tylko określ nazwę folderu), w tym przypadku wydajność jest lepsza niż zapisywanie w jednym pliku.
| Scenariusz | Sugerowane ustawienia |
|---|---|
| Full load from large table, with physical partitions. |
Opcja partycjonowania: Fizyczne partycje tabeli. Podczas wykonywania usługa automatycznie wykrywa partycje fizyczne i kopiuje dane według partycji. To check if your table has physical partition or not, you can refer to this query. |
| Full load from large table, without physical partitions, while with an integer or datetime column for data partitioning. |
Opcje partycji: partycja zakresu dynamicznego. Kolumna partycji (opcjonalnie): określ kolumnę używaną do partycjonowania danych. If not specified, the index or primary key column is used. Partition upper bound and partition lower bound (optional): Specify if you want to determine the partition stride. Nie dotyczy to filtrowania wierszy w tabeli. Wszystkie wiersze w tabeli zostaną podzielone na partycje i skopiowane. Jeśli nie zostaną określone, operacja kopiowania automatycznie wykrywa wartości i może to zająć dużo czasu w zależności od wartości MIN i MAX. Zaleca się podanie górnej granicy i dolnej granicy. For example, if your partition column "ID" has values range from 1 to 100, and you set the lower bound as 20 and the upper bound as 80, with parallel copy as 4, the service retrieves data by 4 partitions - IDs in range <=20, [21, 50], [51, 80], and >=81, respectively. |
| Załaduj dużą ilość danych przy użyciu zapytania niestandardowego, bez partycji fizycznych, natomiast z liczbą całkowitą lub kolumną date/datetime na potrzeby partycjonowania danych. |
Opcje partycji: partycja zakresu dynamicznego. Query: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>.Kolumna partycji: określ kolumnę używaną do partycjonowania danych. Partition upper bound and partition lower bound (optional): Specify if you want to determine the partition stride. Nie jest to przeznaczone do filtrowania wierszy w tabeli, wszystkie wiersze w wyniku zapytania zostaną partycjonowane i skopiowane. Jeśli nie zostanie określona, operacja kopiowania automatycznie wykryje wartość. Jeśli na przykład kolumna partycji "ID" zawiera wartości z zakresu od 1 do 100, a dolna granica zostanie ustawiona jako 20 i górna granica jako 80, z równoległym kopiowaniem jako 4, usługa pobiera dane według 4 partycji — identyfikatory w zakresie <=20, [21, 50], [51, 80] i >= 81. Poniżej przedstawiono więcej przykładowych zapytań dla różnych scenariuszy: • Wykonaj zapytanie dotyczące całej tabeli: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition• Zapytanie z tabeli z wyborem kolumn i dodatkowymi filtrami klauzuli where: SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>• Kwerenda z podzapytaniami: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>• Zapytanie z partycjonowaniem w podzapytaniu: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
Najlepsze rozwiązania dotyczące ładowania danych z opcją partycji:
- Wybierz charakterystyczną kolumnę jako kolumnę partycji (np. klucz podstawowy lub unikatowy klucz), aby uniknąć niesymetryczności danych.
- If the table has built-in partition, use partition option Physical partitions of table to get better performance.
Przykładowe zapytanie do sprawdzania partycji fizycznej
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, pf.name AS PartitionFunctionName, c.name AS ColumnName, iif(pf.name is null, 'no', 'yes') AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.partition_schemes ps ON i.data_space_id = ps.data_space_id
LEFT JOIN sys.partition_functions pf ON pf.function_id = ps.function_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
Jeśli tabela ma partycję fizyczną, zostanie wyświetlona wartość "HasPartition" jako "tak", jak pokazano poniżej.

Podsumowanie tabeli
Poniższe tabele zawierają więcej informacji na temat działania kopiowania w bazie danych SQL.
Źródło
| Nazwa | Opis | Wartość | Required | Właściwość skryptu JSON |
|---|---|---|---|---|
| Connection | Your connection to the source data store. | <your connection> | Tak | connection |
| Use query | Sposób odczytywania danych. Zastosuj table, aby odczytywać dane z określonej tabeli lub stosować Query do odczytywania danych przy użyciu zapytań SQL. | • Table • Query • Stored procedure |
Tak | / |
| dla tabeli | ||||
| nazwa schematu | Name of the schema. | < your schema name > | Nie | schema |
| nazwa tabeli | Nazwa tabeli. | < your table name > | Nie | table |
| For Query | ||||
| Zapytanie | Określ niestandardowe zapytanie SQL do odczytu danych. Na przykład: SELECT * FROM MyTable. |
< zapytań SQL > | Nie | sqlReaderQuery |
| For Stored procedure | ||||
| Stored procedure name | Name of the stored procedure. | < your stored procedure name > | Nie | sqlReaderStoredProcedureName |
| limit czasu zapytania (w minutach) | Limit czasu wykonywania polecenia zapytania, wartość domyślna to 120 minut. Jeśli parametr jest ustawiony dla tej właściwości, dozwolone wartości są przedziałem czasu, takim jak "02:00:00" (120 minut). | przedział czasu | Nie | queryTimeout |
| poziom izolacji | Określa zachowanie blokowania transakcji dla źródła SQL. | • Read committed • Read uncommitted • Powtarzalny odczyt • Serializable • Snapshot |
Nie | isolationLevel: • ReadCommitted • ReadUncommitted • RepeatableRead • Serializable • Snapshot |
| Opcja partycji | Opcje partycjonowania danych używane do ładowania danych z bazy danych SQL. | • Żaden • Physical partitions of table • Dynamic range |
Nie | opcje partycji • PhysicalPartitionsOfTable • DynamicRange |
| dla zakresu dynamicznego | ||||
| Partition column name | The name of the source column in integer or date/datetime type (int, smallint, bigint, date, smalldatetime, datetime, datetime2, or datetimeoffset) that's used by range partitioning for parallel copy. Jeśli nie zostanie określony, indeks lub klucz podstawowy tabeli zostanie automatycznie wykryty i użyty jako kolumna partycji. Jeśli używasz zapytania do pobierania danych źródłowych, podłącz ?DfDynamicRangePartitionCondition w klauzuli WHERE. |
< your partition column names > | Nie | partitionColumnName |
| Partition upper bound | The maximum value of the partition column for partition range splitting. Ta wartość służy do decydowania o kroku partycji, a nie do filtrowania wierszy w tabeli. All rows in the table or query result will be partitioned and copied. Jeśli nie zostanie określona, operacja kopiowania automatycznie wykryje wartość. | < your partition upper bound > | Nie | partitionUpperBound |
| Partition lower bound | The minimum value of the partition column for partition range splitting. Ta wartość służy do decydowania o kroku partycji, a nie do filtrowania wierszy w tabeli. All rows in the table or query result will be partitioned and copied. Jeśli nie zostanie określona, operacja kopiowania automatycznie wykryje wartość. | < your partition lower bound > | Nie | partitionLowerBound |
| dodatkowe kolumny | Dodaj więcej kolumn danych, aby przechowywać ścieżkę względną plików źródłowych lub wartość statyczną. Expression is supported for the latter. | •Nazwa •Wartość |
Nie | dodatkoweKolumny: •nazwa •wartość |
Destination
| Nazwa | Opis | Wartość | Required | Właściwość skryptu JSON |
|---|---|---|---|---|
| Connection | Your connection to the destination data store. | <your connection > | Tak | connection |
| Table option | Your destination data table. Select from Use existing or Auto create table. | Użyj istniejącej • Automatyczne tworzenie tabeli |
Tak | schema table |
| Write behavior | Definiuje zachowanie zapisu, gdy źródłem są pliki z magazynu danych opartego na plikach. | • Insert • Upsert • Stored procedure |
Nie | writeBehavior: • insert • upsert • sqlWriterStoredProcedureName |
| Bulk insert table lock | Use this setting to improve copy performance during a bulk insert operation on a table with no index from multiple clients. | Tak lub Nie (ustawienie domyślne) | Nie | sqlWriterUseTableLock: true lub false (wartość domyślna) |
| For Upsert | ||||
| użyj bazy danych TempDB | Whether to use a global temporary table or physical table as the interim table for upsert. | wybrane (domyślne) lub niezaznaczone | Nie | useTempDB: true (wartość domyślna) lub fałsz |
| Kluczowe kolumny | Wybierz kolumnę używaną do określenia, czy wiersz ze źródła pasuje do wiersza z miejsca docelowego. | < your key column> | Nie | Klucze |
| For Stored procedure | ||||
| Stored procedure name | Ta właściwość jest nazwą procedury składowanej, która odczytuje dane z tabeli źródłowej. Ostatnia instrukcja SQL musi być instrukcją SELECT w procedurze zaprogramowanej. | < stored procedure name > | Nie | sqlWriterStoredProcedureName |
| Pre-copy script | Skrypt dla czynności kopiowania do wykonania przed zapisaniem danych w tabeli docelowej przy każdym uruchomieniu. Za pomocą tej właściwości można wyczyścić wstępnie załadowane dane. |
<pre-copy script> (string) |
Nie | preCopyScript |
| Write batch timeout | The wait time for the batch insert operation to finish before it times out. The allowed value is timespan. Wartość domyślna to "00:30:00" (30 minut). | przedział czasu | Nie | writeBatchTimeout |
| Write batch size | Liczba wierszy do wstawiania do tabeli SQL na partię. Domyślnie usługa dynamicznie określa odpowiedni rozmiar partii na podstawie rozmiaru wiersza. |
<number of rows> (liczba całkowita) |
Nie | writeBatchSize |
| maksymalna liczba współbieżnych połączeń | Górny limit współbieżnych połączeń ustanawianych z magazynem danych podczas wykonywania działania. Określ wartość tylko wtedy, gdy chcesz ograniczyć połączenia współbieżne. |
<górny limit połączeń współbieżnych> (liczba całkowita) |
Nie | maksymalnaLiczbaPołączeńJednoczesnych (maxConcurrentConnections) |