Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W tym artykule wprowadzimy odświeżanie przyrostowe danych w usłudze Dataflow Gen2 dla usługi Data Factory platformy Microsoft Fabric. W przypadku korzystania z przepływów danych do pozyskiwania i przekształcania danych istnieją scenariusze, w których trzeba odświeżyć tylko nowe lub zaktualizowane dane — zwłaszcza gdy dane będą nadal rosły. Funkcja odświeżania przyrostowego eliminuje tę potrzebę, pozwalając skrócić czas odświeżania, zwiększyć niezawodność, unikając długotrwałych operacji i minimalizując użycie zasobów.
Wymagania wstępne
Aby użyć odświeżania przyrostowego w przepływie danych Gen2, należy spełnić następujące wymagania wstępne:
- Musisz mieć pojemność sieci Fabric.
- Twoje źródło danych obsługuje składanie (zalecane) i musi zawierać kolumnę Date/DateTime, która może być użyta do filtrowania danych.
- Powinno istnieć miejsce docelowe danych, które obsługuje odświeżanie przyrostowe. Aby uzyskać więcej informacji, przejdź do obszaru Obsługa miejsca docelowego.
- Przed rozpoczęciem upewnij się, że zapoznałeś się z ograniczeniami odświeżania przyrostowego. Aby uzyskać więcej informacji, przejdź do tematu Ograniczenia.
Obsługa miejsca docelowego
Następujące miejsca docelowe dla danych są obsługiwane dla odświeżania przyrostowego:
- Fabric Lakehouse (wersja zapoznawcza)
- Magazyn tkanin
- Azure SQL Database
- Azure Synapse Analytics
Inne miejsca docelowe mogą być używane w połączeniu z odświeżaniem przyrostowym przy użyciu drugiego zapytania odwołującego się do przygotowanych danych w celu zaktualizowania miejsca docelowego danych. W ten sposób można nadal używać odświeżania przyrostowego, aby zmniejszyć ilość danych, które należy przetworzyć i pobrać z systemu źródłowego. Należy jednak wykonać pełną aktualizację z przygotowanych danych do docelowego punktu danych.
Jak stosować odświeżanie przyrostowe
Utwórz nowy przepływ danych Gen2 lub otwórz istniejącą usługę Dataflow Gen2.
W edytorze przepływu danych utwórz nowe zapytanie, które pobiera dane, które mają być odświeżane przyrostowo.
Sprawdź podgląd danych, aby upewnić się, że zapytanie zwraca dane zawierające kolumnę DateTime, Date lub DateTimeZone, której można użyć do filtrowania danych.
Upewnij się, że zapytanie w pełni się spłaszcza, co oznacza, że zapytanie jest w pełni przekazywane do systemu źródłowego. Jeśli zapytanie nie jest w pełni rozwinięte, należy zmodyfikować zapytanie tak, aby było w pełni rozwinięte. Możesz upewnić się, że zapytanie jest w pełni sformatowane, sprawdzając kroki zapytania w edytorze zapytań.
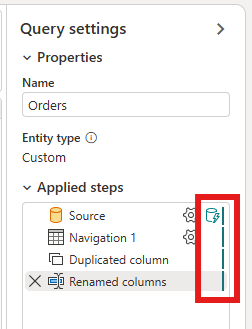
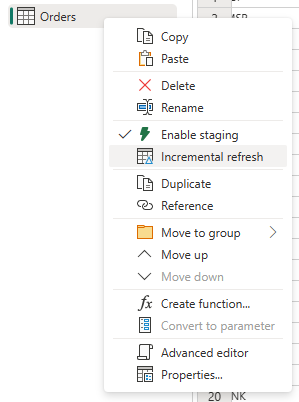
Kliknij prawym przyciskiem myszy zapytanie i wybierz Odświeżanie przyrostowe.
Podaj wymagane ustawienia odświeżania przyrostowego.
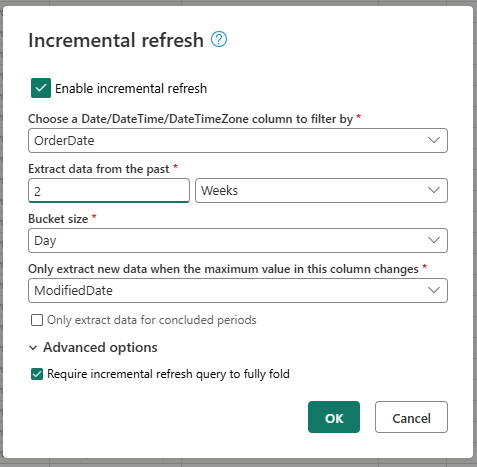
- Wybierz kolumnę DateTime do filtrowania według.
- Wyodrębnianie danych z przeszłości.
- Rozmiar zasobnika.
- Wyodrębnij nowe dane tylko wtedy, gdy zmienia się maksymalna wartość w tej kolumnie.
W razie potrzeby skonfiguruj ustawienia zaawansowane.
- Wymagaj, aby zapytanie odświeżania przyrostowego było w pełni składane.
Wybierz przycisk OK , aby zapisać ustawienia.
Jeśli chcesz, możesz teraz skonfigurować miejsce docelowe danych dla zapytania. Upewnij się, że ta konfiguracja została skonfigurowana przed pierwszym odświeżaniem przyrostowym, ponieważ w przeciwnym razie miejsce docelowe danych zawiera tylko przyrostowe zmienione dane od czasu ostatniego odświeżenia.
Opublikuj przepływ danych Gen2.
Po skonfigurowaniu odświeżania przyrostowego przepływ danych automatycznie odświeża dane przyrostowo na podstawie podanych ustawień. Przepływ danych pobiera tylko dane, które uległy zmianie od czasu ostatniego odświeżenia. W związku z tym przepływ danych działa szybciej i zużywa mniej zasobów.
Jak działa odświeżanie przyrostowe w tle
Odświeżanie przyrostowe działa przez podzielenie danych na przedziały na podstawie kolumny DateTime. Każdy zasobnik zawiera dane, które uległy zmianie od czasu ostatniego odświeżenia. Przepływ danych wie, co się zmieniło, sprawdzając maksymalną wartość w określonej kolumnie. Jeśli wartość maksymalna została zmieniona dla tego zasobnika, przepływ danych pobiera cały zasobnik i zastępuje dane w miejscu docelowym. Jeśli maksymalna wartość nie uległa zmianie, przepływ danych nie pobiera żadnych danych. Poniższe sekcje zawierają oględne omówienie funkcjonowania odświeżania przyrostowego krok po kroku.
Pierwszy krok: Ocena zmian
Po uruchomieniu przepływu danych najpierw ocenia zmiany w źródle danych. Wykonuje tę ocenę, porównując maksymalną wartość w kolumnie DateTime z maksymalną wartością w poprzednim odświeżeniu. Jeśli maksymalna wartość się zmieniła lub jeśli jest to pierwsze odświeżenie, przepływ danych zaznacza kubełek jako zmieniony i umieszcza go na liście do przetworzenia. Jeśli maksymalna wartość nie uległa zmianie, przepływ danych pomija zasobnik i nie przetwarza go.
Drugi krok: pobieranie danych
Teraz przepływ danych jest gotowy do pobrania informacji. Pobiera dane dla każdego zmienionego zasobnika. Aby zwiększyć wydajność, przepływ danych wykonuje to pobieranie równolegle. Przepływ danych pobiera dane z systemu źródłowego i ładuje je do obszaru przechowawczego. Przepływ danych pobiera tylko dane znajdujące się w zakresie zasobnika. Innymi słowy, przepływ danych pobiera tylko dane, które uległy zmianie od czasu ostatniego odświeżenia.
Ostatni krok: zastępowanie danych w miejscu docelowym danych
Przepływ danych zastępuje dane w miejscu docelowym nowymi danymi. Przepływ danych używa metody replace, aby zastąpić dane w miejscu docelowym. Oznacza to, że przepływ danych najpierw usuwa dane w miejscu docelowym dla tego zasobnika, a następnie wstawia nowe dane. Przepływ danych nie ma wpływu na dane znajdujące się poza zakresem wiadra. W związku z tym, jeśli masz dane w miejscu docelowym starszym niż pierwszy zasobnik, odświeżanie przyrostowe nie ma wpływu na te dane w żaden sposób.
Objaśnienia dotyczące ustawień przyrostowego odświeżania
Aby skonfigurować odświeżanie przyrostowe, należy określić następujące ustawienia.
Ustawienia ogólne
Ustawienia ogólne są wymagane i określają podstawową konfigurację odświeżania przyrostowego.
Wybierz kolumnę DateTime do filtrowania
To ustawienie jest wymagane i określa kolumnę używaną przez przepływy danych do filtrowania danych. Ta kolumna powinna być kolumną typu DateTime, Date lub DateTimeZone. Przepływ danych używa tej kolumny do filtrowania danych i pobiera tylko dane, które uległy zmianie od czasu ostatniego odświeżenia.
Wyodrębnianie danych z przeszłości
To ustawienie jest wymagane i określa, jak daleko w czasie przepływ danych powinien wyodrębniać dane. To ustawienie służy do pobierania początkowego zestawu danych. Przepływ danych pobiera wszystkie dane z systemu źródłowego znajdującego się w określonym zakresie czasu. Dopuszczalne wartości:
- x dni
- x tygodnie
- x miesięcy
- x kwartały
- x rok/lat
Jeśli na przykład określisz 1 miesiąc, przepływ danych pobiera wszystkie nowe dane z systemu źródłowego, który znajduje się w ciągu ostatniego miesiąca.
Rozmiar zasobnika
To ustawienie jest wymagane i określa rozmiar zasobników używanych przez przepływ danych do filtrowania danych. Przepływ danych dzieli dane na zasobniki na podstawie kolumny DateTime. Każdy zasobnik zawiera dane, które uległy zmianie od czasu ostatniego odświeżenia. Rozmiar zasobnika określa, ile danych jest przetwarzanych w każdej iteracji. Mniejszy rozmiar zasobnika oznacza, że przepływ danych przetwarza mniej danych w każdej iteracji, ale oznacza to również, że do przetwarzania wszystkich danych wymagane jest więcej iteracji. Większy rozmiar zasobnika oznacza, że przepływ danych przetwarza więcej danych w każdej iteracji, ale oznacza również, że do przetwarzania wszystkich danych jest wymagana mniejsza liczba iteracji.
Wyodrębnianie nowych danych tylko wtedy, gdy zmienia się maksymalna wartość w tej kolumnie
To ustawienie jest wymagane i określa kolumnę używaną przez przepływ danych do określenia, czy dane uległy zmianie. Przepływ danych porównuje maksymalną wartość w tej kolumnie z maksymalną wartością w poprzednim odświeżeniu. Jeśli wartość maksymalna zostanie zmieniona, przepływ danych pobiera dane, które uległy zmianie od czasu ostatniego odświeżenia. Jeśli maksymalna wartość nie zostanie zmieniona, przepływ danych nie pobiera żadnych danych.
Wyodrębnianie tylko danych dla zakończonych okresów
To ustawienie jest opcjonalne i określa, czy przepływ danych powinien wyodrębniać tylko dane dla zakończonych okresów. Jeśli to ustawienie jest włączone, przepływ danych wyodrębnia tylko dane dla okresów, które zakończyły się. W związku z tym przepływ danych wyodrębnia tylko dane z okresów, które są kompletne i nie zawierają żadnych przyszłych danych. Jeśli to ustawienie jest wyłączone, przepływ danych wyodrębnia dane dla wszystkich okresów, w tym okresy, które nie są kompletne i zawierają przyszłe dane.
Jeśli na przykład masz kolumnę DateTime zawierającą datę transakcji i chcesz odświeżyć tylko pełne miesiące, możesz włączyć to ustawienie w połączeniu z rozmiarem month wiaderka. W związku z tym przepływ danych wyodrębnia tylko dane przez pełne miesiące i nie wyodrębnia danych przez niekompletne miesiące.
Ustawienia zaawansowane
Niektóre ustawienia są uznawane za zaawansowane i nie są wymagane w większości scenariuszy.
Wymagaj, aby zapytanie dotyczące odświeżania przyrostowego było w pełni składane.
To ustawienie jest opcjonalne i określa, czy zapytanie używane do przyrostowego odświeżania musi być w pełni złożone. Jeśli to ustawienie jest włączone, zapytanie używane do odświeżania przyrostowego musi zostać w pełni rozłożone. Innymi słowy, zapytanie musi być w pełni przekazane do systemu źródłowego. Jeśli to ustawienie jest wyłączone, zapytanie używane do odświeżania przyrostowego nie musi być całkowicie złożone. W takim przypadku zapytanie może zostać częściowo przekazane do systemu źródłowego. Zdecydowanie zalecamy włączenie tego ustawienia w celu zwiększenia wydajności, aby uniknąć pobierania niepotrzebnych i niefiltrowanych danych.
Ograniczenia
Usługa Lakehouse jest obsługiwana z dodatkowymi zastrzeżeniami
Podczas pracy z usługą Lakehouse jako miejscem docelowym danych należy pamiętać o następujących ograniczeniach:
- Maksymalna liczba współbieżnych ocen wynosi 10. Oznacza to, że przepływ danych może równolegle przetwarzać tylko 10 wiader. Jeśli masz więcej niż 10 zasobników, musisz ograniczyć liczbę zasobników lub ograniczyć liczbę współbieżnych ocen.
- Podczas zapisywania danych w lakehouse, przepływ danych prowadzi własną ewidencję plików zapisywanych w lakehouse. Jest to zgodne ze standardowym wzorcem lakehouse. Oznacza to jednak, że jeśli inni autorzy, tacy jak Spark lub inne procesy zapisują w tej samej tabeli, może to spowodować problemy z odświeżaniem przyrostowym. Zalecamy, aby nie używać innych składników zapisywania do zapisu w tej samej tabeli podczas korzystania z odświeżania przyrostowego. W takim przypadku należy upewnić się, że inni autorzy nie zakłócają procesu odświeżania przyrostowego. Procesy takie jak konserwacja tabel i opróżnianie nie są obsługiwane podczas korzystania z odświeżania przyrostowego.
Miejsce docelowe danych musi być ustawione na stały schemat
Miejsce docelowe danych musi być ustawione na stały schemat, co oznacza, że schemat tabeli w miejscu docelowym danych musi być stały i nie można go zmienić. Jeśli schemat tabeli w miejscu docelowym danych jest ustawiony na schemat dynamiczny, należy zmienić go na stały schemat przed skonfigurowaniem odświeżania przyrostowego.
Jedyną obsługiwaną metodą aktualizacji w miejscu docelowym danych jest replace
Jedyną obsługiwaną metodą aktualizacji w miejscu docelowym danych jest replace, co oznacza, że przepływ danych zastępuje dane dla każdego zasobnika w miejscu docelowym danych nowymi danymi. Jednak dane znajdujące się poza zakresem wiadra nie są dotknięte. Dlatego jeśli masz dane w miejscu docelowym starsze niż pierwsza grupa danych, odświeżanie przyrostowe w żaden sposób nie wpływa na te dane.
Maksymalna liczba zasobników wynosi 50 dla pojedynczego zapytania i 150 dla całego przepływu danych
Maksymalna liczba zasobników na zapytanie obsługiwane przez przepływ danych wynosi 50. Jeśli masz więcej niż 50 zasobników, musisz zwiększyć rozmiar zasobnika lub zmniejszyć zakres zasobników, aby zmniejszyć liczbę zasobników. W przypadku całego przepływu danych maksymalna liczba zasobników wynosi 150. Jeśli masz więcej niż 150 zasobników w przepływie danych, musisz zmniejszyć liczbę zapytań odświeżania przyrostowego lub zwiększyć rozmiar zasobnika, aby zmniejszyć liczbę zasobników.
Różnice między odświeżaniem przyrostowym w przepływie danych Gen1 i Gen2
Między przepływem danych Gen1 a przepływem danych Gen2 istnieją pewne różnice w sposobie działania odświeżania przyrostowego. Na poniższej liście wyjaśniono główne różnice między odświeżaniem przyrostowym w przepływie danych Gen1 i Gen2.
- Odświeżanie przyrostowe jest teraz pełnoprawną funkcją w usłudze Dataflow Gen2. W usłudze Dataflow Gen1 trzeba było skonfigurować odświeżanie przyrostowe po opublikowaniu przepływu danych. W usłudze Dataflow Gen2 odświeżanie przyrostowe jest teraz pełnoprawną funkcją, którą można skonfigurować bezpośrednio w edytorze przepływów danych. Ta funkcja ułatwia konfigurowanie odświeżania przyrostowego i zmniejsza ryzyko wystąpienia błędów.
- W usłudze Dataflow Gen1 trzeba było określić zakres danych historycznych podczas konfigurowania odświeżania przyrostowego. W usłudze Dataflow Gen2 nie trzeba określać zakresu danych historycznych. Przepływ danych nie usuwa żadnych danych z miejsca docelowego, które są poza zakresem zasobnika. W związku z tym jeśli masz dane w miejscu docelowym starszym niż pierwszy zasobnik, odświeżanie przyrostowe nie ma wpływu na te dane w żaden sposób.
- W usłudze Dataflow Gen1 trzeba było określić parametry odświeżania przyrostowego podczas konfigurowania odświeżania przyrostowego. W usłudze Dataflow Gen2 nie trzeba określać parametrów odświeżania przyrostowego. Przepływ danych automatycznie dodaje filtry i parametry jako ostatni krok w zapytaniu. Dlatego nie trzeba ręcznie określać parametrów odświeżania przyrostowego.
Często zadawane pytania
Otrzymałem ostrzeżenie, że użyto tej samej kolumny do wykrywania zmian i filtrowania. Co to oznacza?
Jeśli zostanie wyświetlone ostrzeżenie, że użyto tej samej kolumny do wykrywania zmian i filtrowania, oznacza to, że kolumna określona do wykrywania zmian jest również używana do filtrowania danych. Nie zalecamy tego użycia, ponieważ może to prowadzić do nieoczekiwanych wyników. Zamiast tego zalecamy użycie innej kolumny do wykrywania zmian i filtrowania danych. Jeśli dane zmieniają się między zasobnikami, przepływ danych może nie być w stanie prawidłowo wykryć zmian i może utworzyć zduplikowane dane w miejscu docelowym. To ostrzeżenie można rozwiązać, używając innej kolumny do wykrywania zmian i filtrowania danych. Możesz też zignorować ostrzeżenie, jeśli masz pewność, że dane nie zmieniają się między odświeżeniami określonej kolumny.
Chcę użyć odświeżania przyrostowego z miejscem docelowym danych, które nie jest obsługiwane. Co mogę zrobić?
Jeśli chcesz użyć odświeżania przyrostowego z miejscem docelowym danych, które nie jest obsługiwane, możesz włączyć odświeżanie przyrostowe w zapytaniu i użyć drugiego zapytania odwołującego się do przygotowanych danych w celu zaktualizowania miejsca docelowego danych. W ten sposób można nadal używać odświeżania przyrostowego, aby zmniejszyć ilość danych, które należy przetworzyć i pobrać z systemu źródłowego, ale należy wykonać pełne odświeżanie z przygotowanych danych do miejsca docelowego danych. Upewnij się, że okno i rozmiar zasobnika są poprawnie skonfigurowane, ponieważ nie gwarantujemy, że dane w środowisku tymczasowym są przechowywane poza zakresem zasobnika. Inną opcją jest użycie wzorca w celu przyrostowego zmasowania danych. Mamy przewodnik dotyczący tego, jak to zrobić tutaj: Kumulowanie danych przyrostowych z Dataflow Gen2
Jak mogę wiedzieć, czy moje zapytanie ma włączone odświeżanie przyrostowe?
Możesz sprawdzić, czy zapytanie ma włączone odświeżanie przyrostowe, sprawdzając ikonę obok zapytania w edytorze przepływu danych. Jeśli ikona zawiera niebieski trójkąt, odświeżanie przyrostowe jest włączone. Jeśli ikona nie zawiera niebieskiego trójkąta, odświeżanie przyrostowe nie jest włączone.
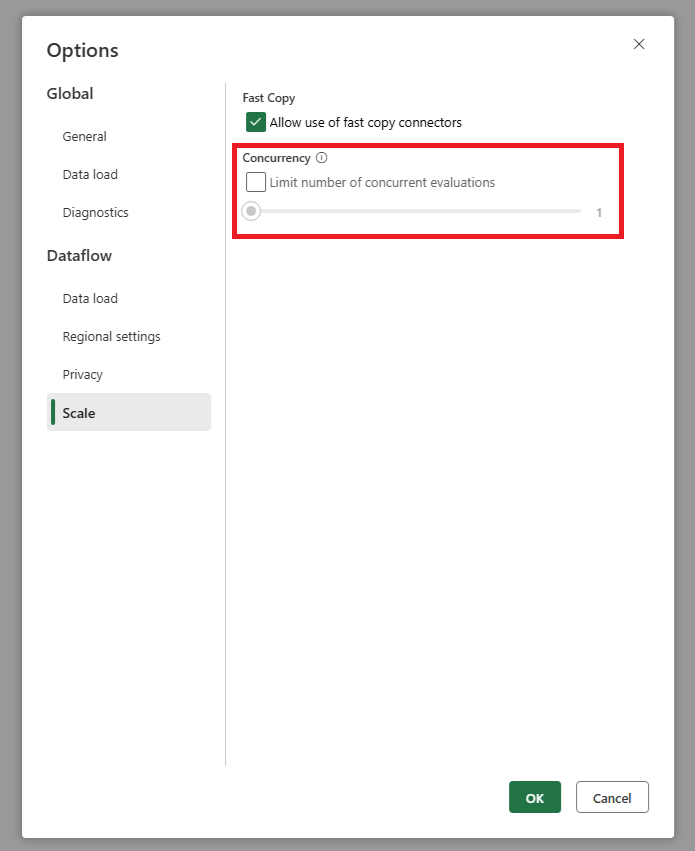
Moje źródło pobiera zbyt wiele żądań, gdy używam odświeżania przyrostowego. Co mogę zrobić?
Dodaliśmy ustawienie, które umożliwia ustawienie maksymalnej liczby równoległych ocen zapytań. To ustawienie można znaleźć w ustawieniach globalnych przepływu danych. Ustawiając tę wartość na mniejszą liczbę, można zmniejszyć liczbę żądań wysyłanych do systemu źródłowego. To ustawienie może pomóc zmniejszyć liczbę współbieżnych żądań i zwiększyć wydajność systemu źródłowego. Aby ustawić maksymalną liczbę równoległych wykonań zapytań, przejdź do ustawień globalnych przepływu danych, przejdź do karty Skalowanie i ustaw maksymalną liczbę równoległych ocen zapytań. Zalecamy, aby nie włączać tego limitu, chyba że wystąpią problemy z systemem źródłowym.
Chcę użyć odświeżania przyrostowego, ale widzę, że odświeżenie przepływu danych trwa dłużej po włączeniu. Co mogę zrobić?
Odświeżanie przyrostowe, zgodnie z opisem w tym artykule, ma na celu zmniejszenie ilości danych, które należy przetworzyć i pobrać z systemu źródłowego. Jeśli jednak odświeżanie przepływu danych trwa dłużej po włączeniu odświeżania przyrostowego, może to oznaczać, że dodatkowe obciążenie związane z sprawdzaniem, czy dane uległy zmianie i przetwarzaniu zasobników są wyższe niż czas zaoszczędzony przez przetwarzanie mniejszej ilości danych. W takim przypadku zalecamy przejrzenie ustawień odświeżania przyrostowego i dostosowanie ich w celu lepszego dopasowania do danego scenariusza. Można na przykład zwiększyć rozmiar zasobnika, aby zmniejszyć liczbę zasobników i obciążenie związane z ich przetwarzaniem. Możesz też zmniejszyć liczbę zasobników, zwiększając rozmiar zasobnika. Jeśli po dostosowaniu ustawień nadal występuje niska wydajność, możesz wyłączyć odświeżanie przyrostowe i użyć pełnego odświeżania, ponieważ może to być bardziej wydajne w danym scenariuszu.