Przyrostowe ładowanie danych z magazynu danych do usługi Lakehouse
Z tego samouczka dowiesz się, jak przyrostowo ładować dane z usługi Data Warehouse do usługi Lakehouse.
Omówienie
Diagram ogólny rozwiązania wygląda następująco:

Poniżej przedstawiono ważne czynności związane z tworzeniem tego rozwiązania:
Wybierz kolumnę limitu. Wybierz jedną kolumnę w tabeli danych źródłowych, która może służyć do fragmentowania nowych lub zaktualizowanych rekordów dla każdego przebiegu. Zazwyczaj dane w tej wybranej kolumnie (na przykład last_modify_time lub ID) rosną wraz z tworzeniem i aktualizacją wierszy. Maksymalna wartość w tej kolumnie jest używana jako limit.
Przygotuj tabelę do przechowywania ostatniej wartości limitu w magazynie danych.
Utwórz potok z następującym przepływem pracy:
Potok w tym rozwiązaniu obejmuje następujące działania:
- Utwórz dwa działania lookup. Użyj pierwszego działania wyszukiwania do pobrania ostatniej wartości limitu. Użyj drugiego działania wyszukiwania do pobrania nowej wartości limitu. Te wartości limitu są przekazywane do działania kopiowania.
- Utwórz działanie kopiowania, które kopiuje wiersze z tabeli danych źródłowych z wartością kolumny limitu większej niż stara wartość limitu i mniejsza niż nowa wartość limitu. Następnie kopiuje dane z magazynu danych do usługi Lakehouse jako nowy plik.
- Utwórz działanie procedury składowanej, które aktualizuje ostatnią wartość limitu dla następnego uruchomienia potoku.
Wymagania wstępne
- Magazyn danych. Magazyn danych jest używany jako źródłowy magazyn danych. Jeśli go nie masz, zobacz Tworzenie magazynu danych, aby zapoznać się z krokami, które należy utworzyć.
- Lakehouse. Usługa Lakehouse jest używana jako docelowy magazyn danych. Jeśli go nie masz, zobacz Tworzenie usługi Lakehouse , aby uzyskać instrukcje tworzenia. Utwórz folder o nazwie IncrementalCopy do przechowywania skopiowanych danych.
Przygotowywanie źródła
Poniżej przedstawiono niektóre tabele i procedurę składowaną, które należy przygotować w źródłowym magazynie danych przed skonfigurowaniem potoku kopiowania przyrostowego.
1. Tworzenie tabeli źródła danych w magazynie danych
Uruchom następujące polecenie SQL w usłudze Data Warehouse, aby utworzyć tabelę o nazwie data_source_table jako tabelę źródła danych. W tym samouczku użyjesz go jako przykładowych danych do wykonania przyrostowej kopii.
create table data_source_table
(
PersonID int,
Name varchar(255),
LastModifytime DATETIME2(6)
);
INSERT INTO data_source_table
(PersonID, Name, LastModifytime)
VALUES
(1, 'aaaa','9/1/2017 12:56:00 AM'),
(2, 'bbbb','9/2/2017 5:23:00 AM'),
(3, 'cccc','9/3/2017 2:36:00 AM'),
(4, 'dddd','9/4/2017 3:21:00 AM'),
(5, 'eeee','9/5/2017 8:06:00 AM');
Dane w tabeli źródła danych są pokazane poniżej:
PersonID | Name | LastModifytime
-------- | ---- | --------------
1 | aaaa | 2017-09-01 00:56:00.000
2 | bbbb | 2017-09-02 05:23:00.000
3 | cccc | 2017-09-03 02:36:00.000
4 | dddd | 2017-09-04 03:21:00.000
5 | eeee | 2017-09-05 08:06:00.000
W tym samouczku użyjesz funkcji LastModifytime jako kolumny limitu.
2. Utwórz inną tabelę w magazynie danych, aby przechowywać ostatnią wartość limitu
Uruchom następujące polecenie SQL w usłudze Data Warehouse, aby utworzyć tabelę o nazwie waterstadtable do przechowywania ostatniej wartości limitu:
create table watermarktable ( TableName varchar(255), WatermarkValue DATETIME2(6), );Ustaw wartość domyślną ostatniego limitu z nazwą tabeli danych źródłowych. W tym samouczku nazwa tabeli to data_source_table, a wartość domyślna to
1/1/2010 12:00:00 AM.INSERT INTO watermarktable VALUES ('data_source_table','1/1/2010 12:00:00 AM')Przejrzyj dane w tabeli waterstadtable.
Select * from watermarktableDane wyjściowe:
TableName | WatermarkValue ---------- | -------------- data_source_table | 2010-01-01 00:00:00.000
3. Tworzenie procedury składowanej w magazynie danych
Uruchom następujące polecenie, aby utworzyć procedurę składowaną w magazynie danych. Ta procedura składowana służy do aktualizowania ostatniej wartości limitu po ostatnim uruchomieniu potoku.
CREATE PROCEDURE usp_write_watermark @LastModifiedtime datetime, @TableName varchar(50)
AS
BEGIN
UPDATE watermarktable
SET [WatermarkValue] = @LastModifiedtime
WHERE [TableName] = @TableName
END
Konfigurowanie potoku na potrzeby kopiowania przyrostowego
Krok 1. Tworzenie potoku
Przejdź do usługi Power BI.
Wybierz ikonę usługi Power BI w lewym dolnym rogu ekranu, a następnie wybierz pozycję Fabryka danych , aby otworzyć stronę główną usługi Data Factory.
Przejdź do obszaru roboczego usługi Microsoft Fabric.
Wybierz pozycję Potok danych, a następnie wprowadź nazwę potoku, aby utworzyć nowy potok.
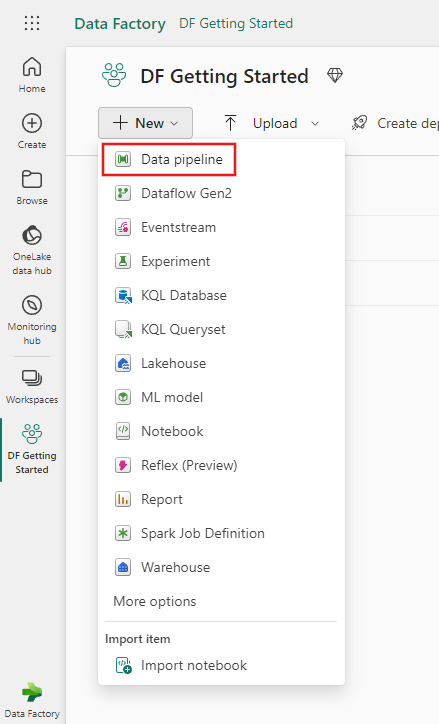
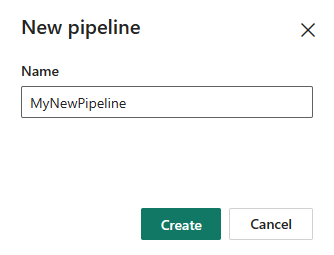
Krok 2. Dodawanie działania odnośnika dla ostatniego znaku wodnego
W tym kroku utworzysz działanie odnośnika, aby uzyskać ostatnią wartość limitu. Wartość 1/1/2010 12:00:00 AM domyślna ustawiona przed zostanie uzyskana.
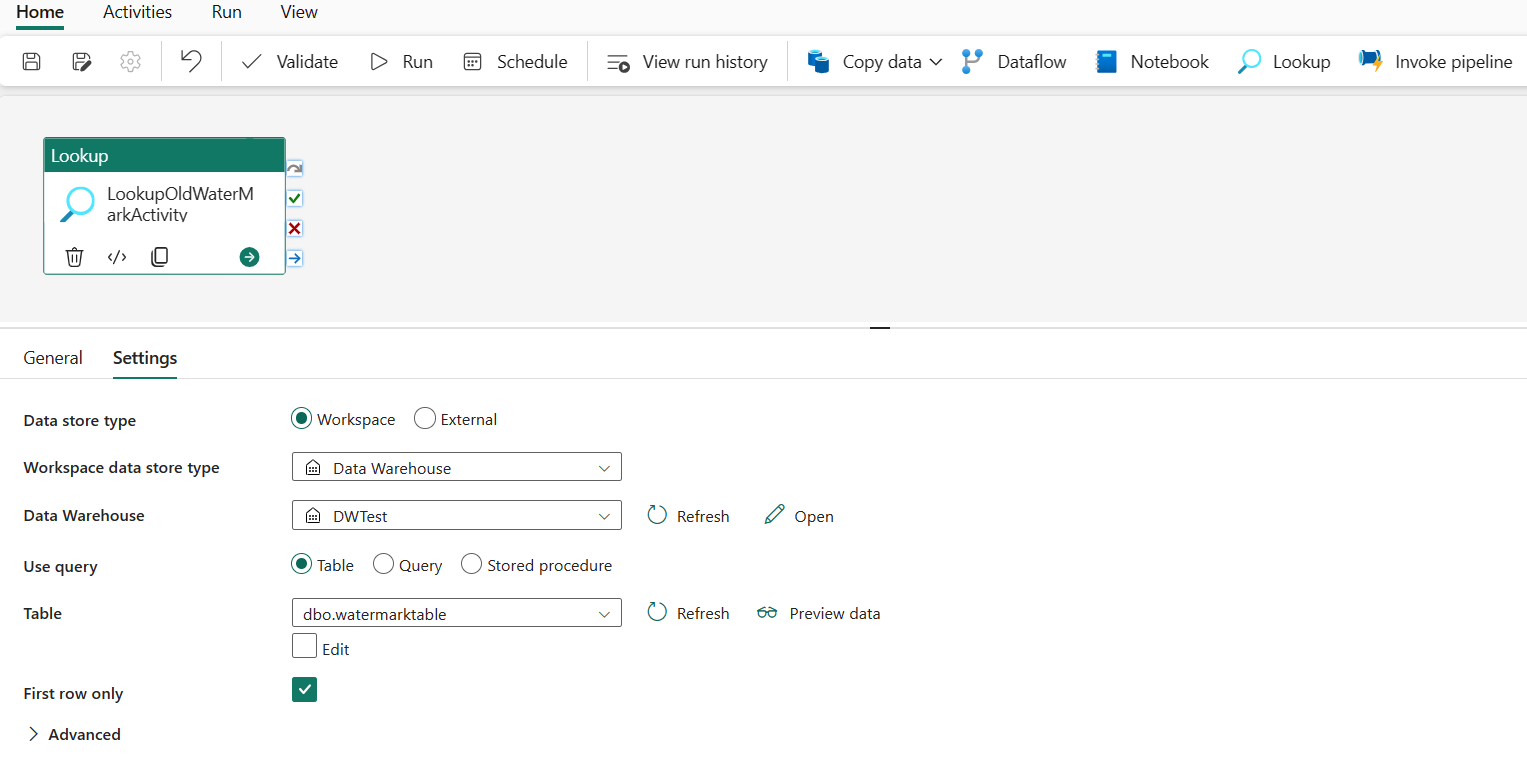
Wybierz pozycję Dodaj działanie potoku i wybierz pozycję Wyszukaj z listy rozwijanej.
Na karcie Ogólne zmień nazwę tego działania na LookupOldWaterMarkActivity.
Na karcie Ustawienia wykonaj następującą konfigurację:
- Typ magazynu danych: wybierz pozycję Obszar roboczy.
- Typ magazynu danych obszaru roboczego: wybierz pozycję Magazyn danych.
- Data Warehouse: wybierz magazyn danych.
- Użyj zapytania: wybierz pozycję Tabela.
- Tabela: wybierz pozycję dbo.waterstadtable.
- Tylko pierwszy wiersz: wybrany.
Krok 3. Dodawanie działania wyszukiwania dla nowego znaku wodnego
W tym kroku utworzysz działanie odnośnika, aby uzyskać nową wartość limitu. Użyjesz zapytania, aby uzyskać nowy znak wodny z tabeli danych źródłowych. Zostanie uzyskana maksymalna wartość w kolumnie LastModifytime w data_source_table .
Na górnym pasku wybierz pozycję Odnośnik na karcie Działania , aby dodać drugie działanie wyszukiwania.
Na karcie Ogólne zmień nazwę tego działania na LookupNewWaterMarkActivity.
Na karcie Ustawienia wykonaj następującą konfigurację:
Typ magazynu danych: wybierz pozycję Obszar roboczy.
Typ magazynu danych obszaru roboczego: wybierz pozycję Magazyn danych.
Data Warehouse: wybierz magazyn danych.
Użyj zapytania: wybierz pozycję Zapytanie.
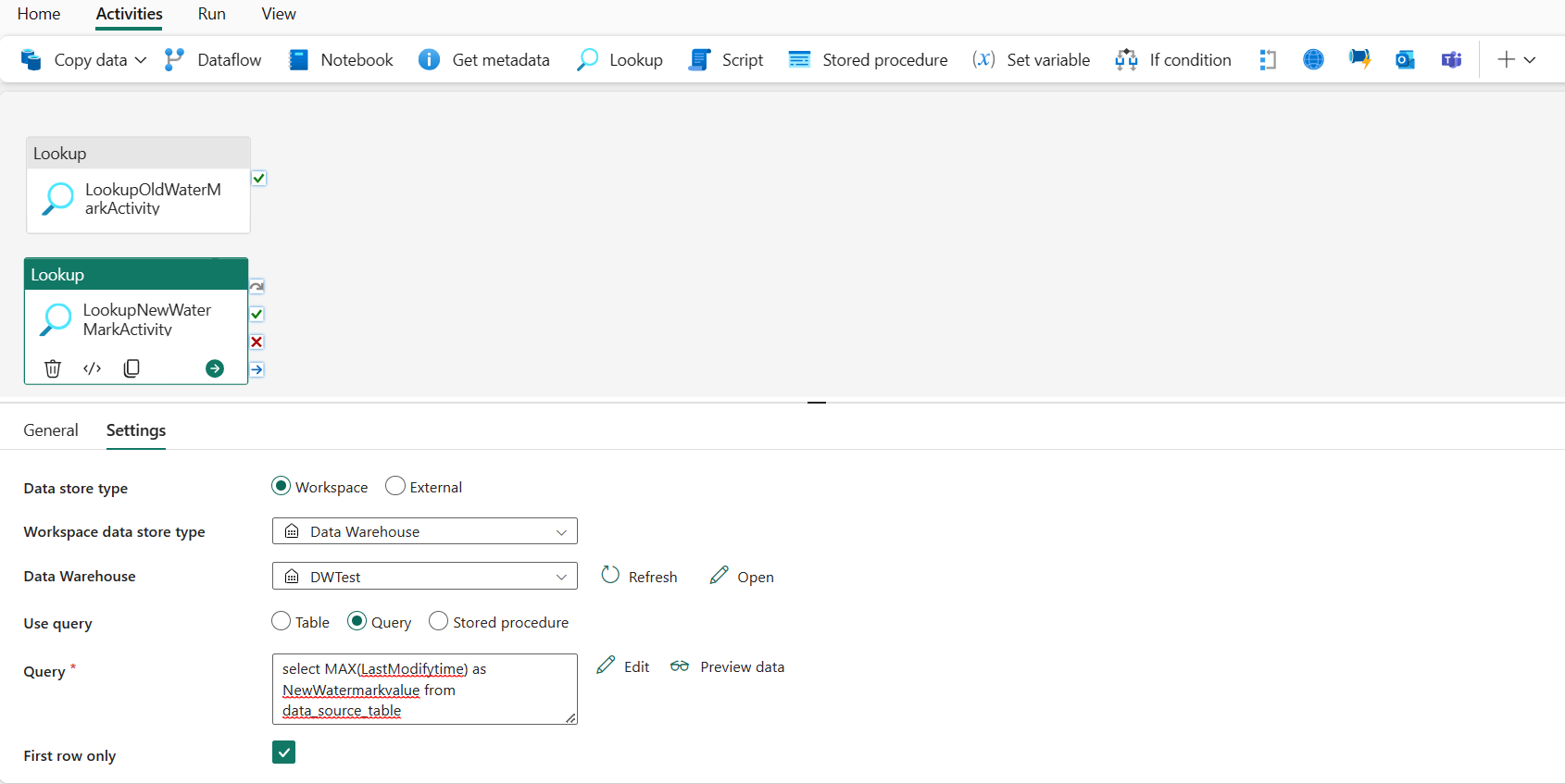
Zapytanie: Wprowadź następujące zapytanie, aby wybrać maksymalny czas ostatniej modyfikacji jako nowy znak wodny:
select MAX(LastModifytime) as NewWatermarkvalue from data_source_tableTylko pierwszy wiersz: wybrany.
Krok 4. Dodawanie działania kopiowania w celu kopiowania danych przyrostowych
W tym kroku dodasz działanie kopiowania, aby skopiować dane przyrostowe między ostatnim znakiem wodnym a nowym znakiem wodnym z usługi Data Warehouse do usługi Lakehouse.
Wybierz pozycję Działania na górnym pasku i wybierz pozycję Kopiuj dane -> Dodaj do kanwy , aby uzyskać działanie kopiowania.
Na karcie Ogólne zmień nazwę tego działania na IncrementalCopyActivity.
Połączenie działania wyszukiwania do działania kopiowania, przeciągając zielony przycisk (Po powodzeniu) dołączony do działań odnośników do działania kopiowania. Zwolnij przycisk myszy, gdy kolor obramowania działania kopiowania zmieni się na zielony.

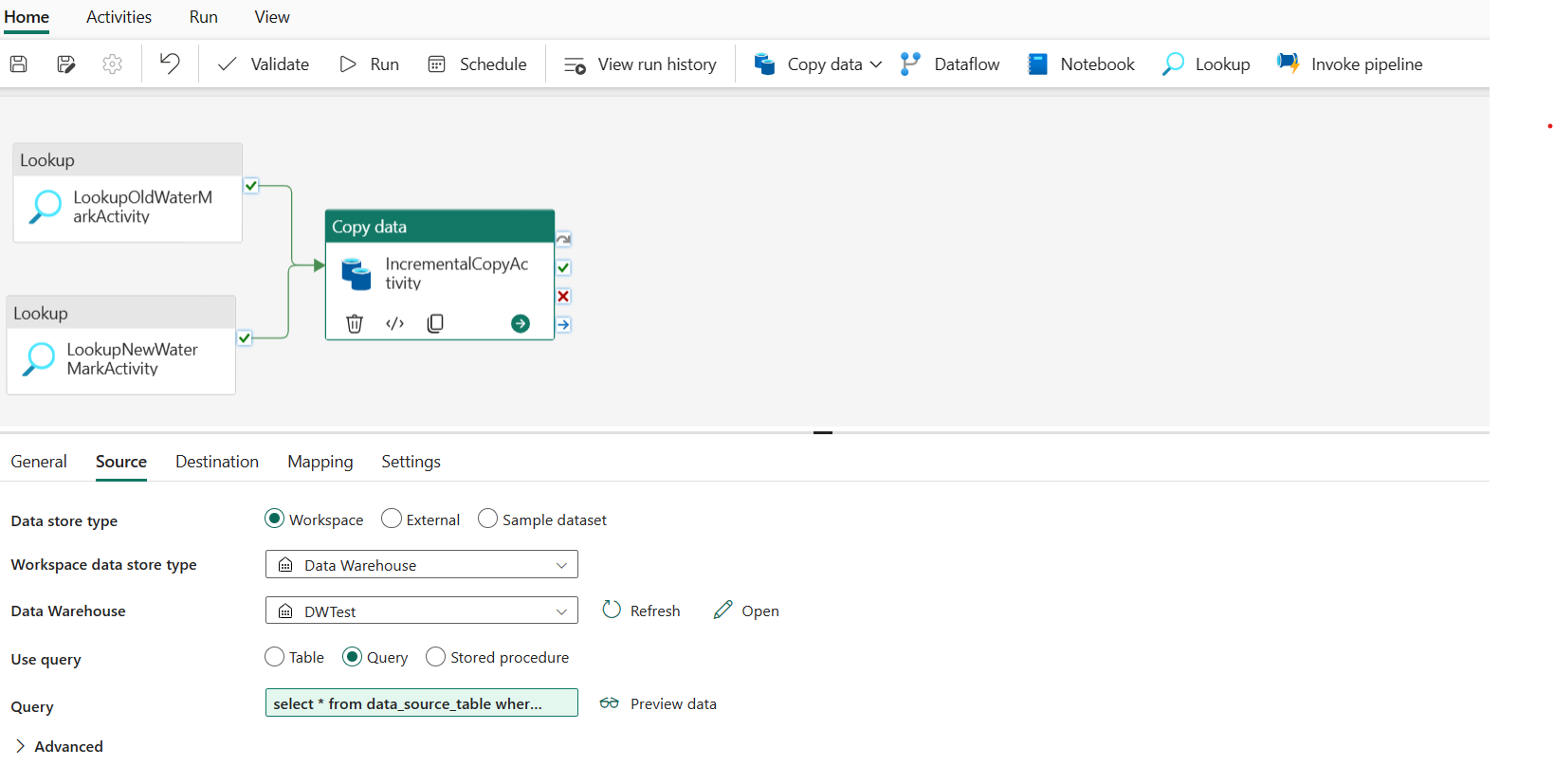
Na karcie Źródło wykonaj następującą konfigurację:
Typ magazynu danych: wybierz pozycję Obszar roboczy.
Typ magazynu danych obszaru roboczego: wybierz pozycję Magazyn danych.
Data Warehouse: wybierz magazyn danych.
Użyj zapytania: wybierz pozycję Zapytanie.
Zapytanie: wprowadź następujące zapytanie, aby skopiować dane przyrostowe między ostatnim znakiem wodnym a nowym znakiem wodnym.
select * from data_source_table where LastModifytime > '@{activity('LookupOldWaterMarkActivity').output.firstRow.WatermarkValue}' and LastModifytime <= '@{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue}'
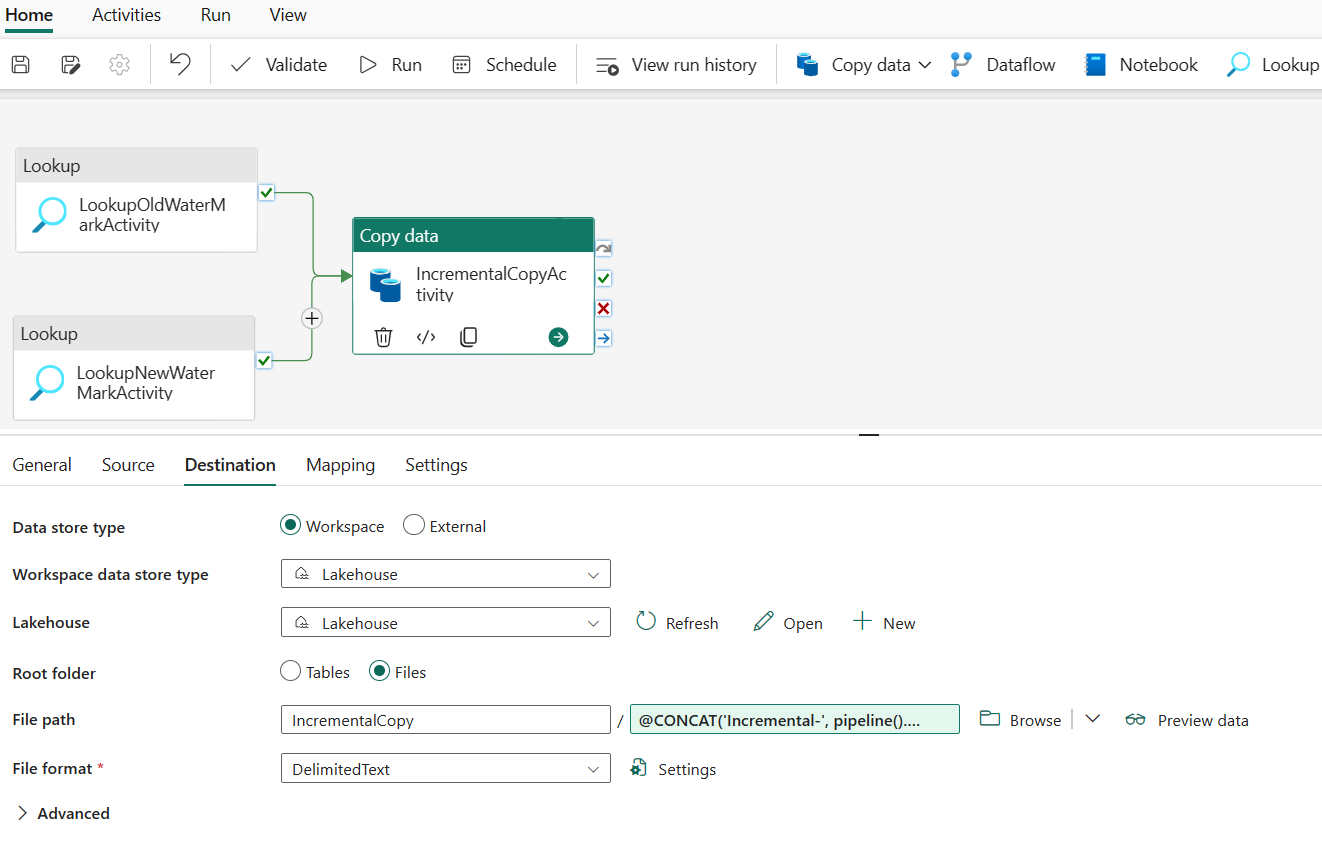
Na karcie Miejsce docelowe wykonaj następującą konfigurację:
- Typ magazynu danych: wybierz pozycję Obszar roboczy.
- Typ magazynu danych obszaru roboczego: wybierz pozycję Lakehouse.
- Lakehouse: wybierz swoją usługę Lakehouse.
- Folder główny: wybierz pozycję Pliki.
- Ścieżka pliku: określ folder, który chcesz przechowywać skopiowane dane. Wybierz pozycję Przeglądaj , aby wybrać folder. W polu Nazwa pliku otwórz pozycję Dodaj zawartość dynamiczną i wprowadź
@CONCAT('Incremental-', pipeline().RunId, '.txt')w otwartym oknie, aby utworzyć nazwy plików dla skopiowanego pliku danych w usłudze Lakehouse. - Format pliku: wybierz typ formatu danych.
Krok 5. Dodawanie działania procedury składowanej
W tym kroku dodasz działanie procedury składowanej, aby zaktualizować ostatnią wartość limitu dla następnego uruchomienia potoku.
Wybierz pozycję Działania na górnym pasku i wybierz pozycję Procedura składowana, aby dodać działanie procedury składowanej.
Na karcie Ogólne zmień nazwę tego działania na StoredProceduretoWriteWatermarkActivity.
Połączenie zielonych (po powodzeniu) danych wyjściowych działania kopiowania do działania procedury składowanej.
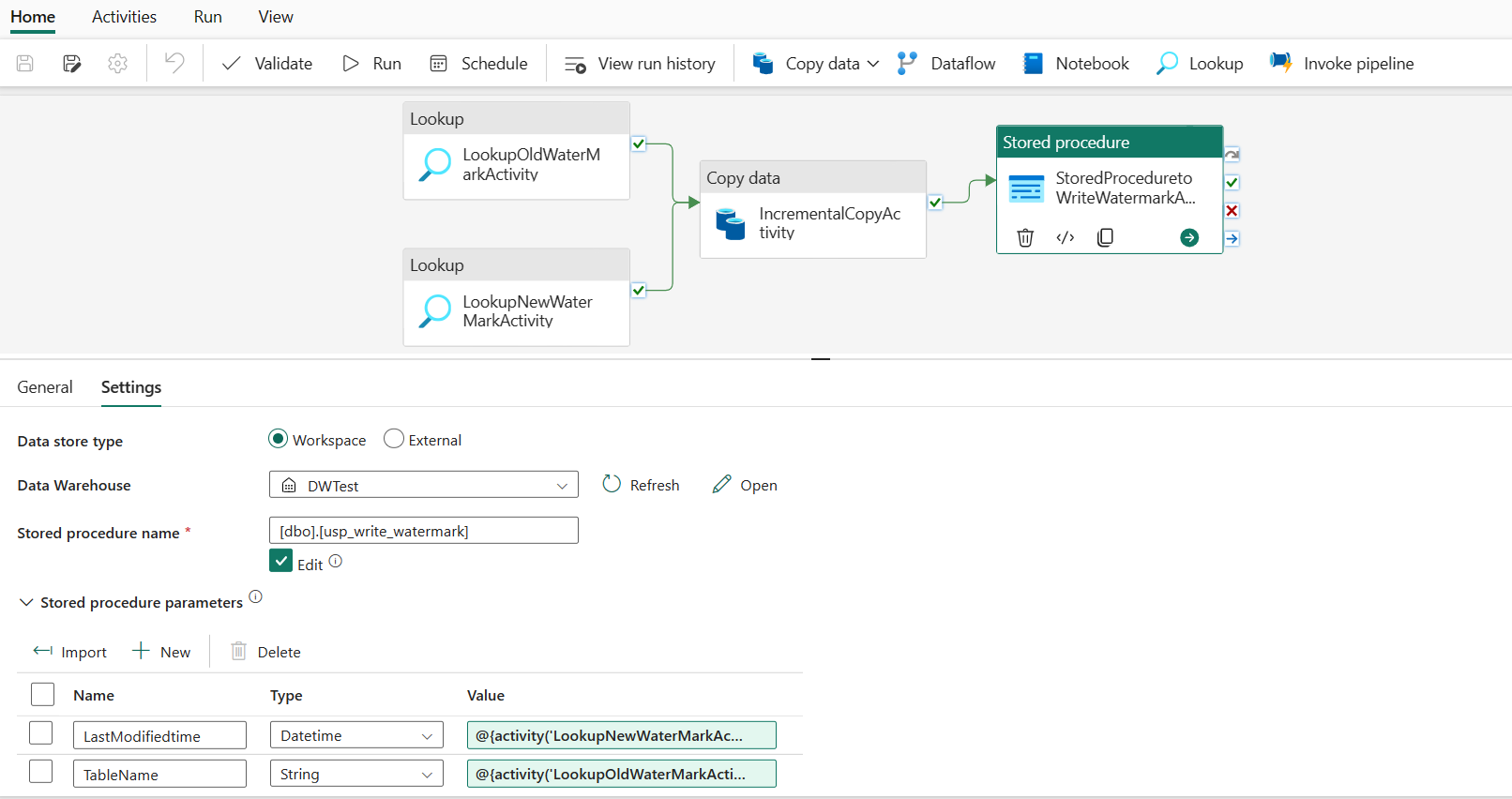
Na karcie Ustawienia wykonaj następującą konfigurację:
Typ magazynu danych: wybierz pozycję Obszar roboczy.
Data Warehouse: wybierz magazyn danych.
Nazwa procedury składowanej: określ procedurę składowaną utworzoną w magazynie danych: [dbo].[ usp_write_watermark].
Rozwiń węzeł Parametry procedury składowanej. Aby określić wartości parametrów procedury składowanej, wybierz pozycję Importuj i wprowadź następujące wartości dla parametrów:
Nazwisko Typ Wartość LastModifiedtime DateTime @{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue} TableName String @{activity('LookupOldWaterMarkActivity').output.firstRow.TableName}
Krok 6. Uruchamianie potoku i monitorowanie wyniku
Na górnym pasku wybierz pozycję Uruchom na karcie Narzędzia główne . Następnie wybierz pozycję Zapisz i uruchom. Uruchomienie potoku jest uruchamiane i można monitorować potok na karcie Dane wyjściowe .
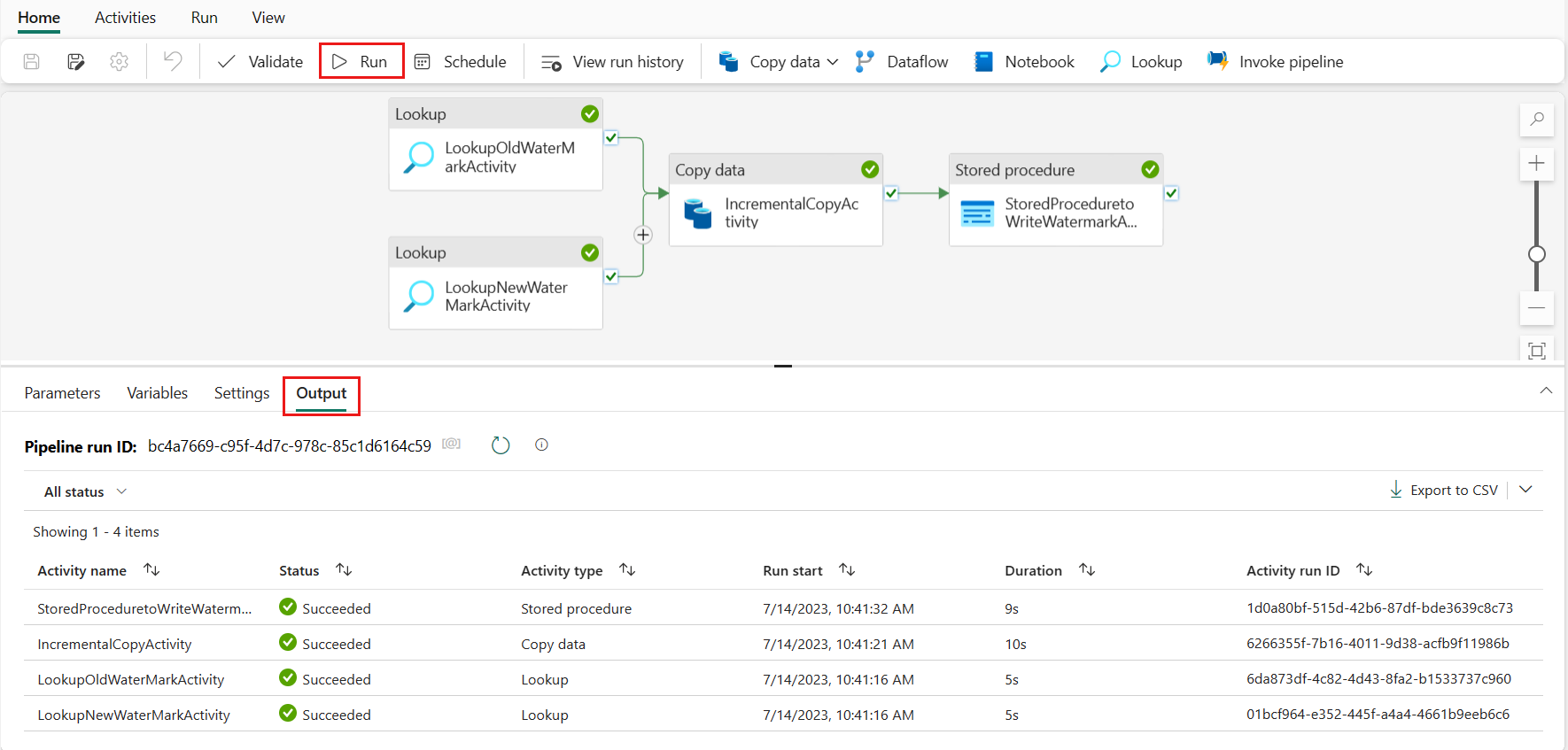
Przejdź do usługi Lakehouse, aby znaleźć plik danych znajduje się w określonym folderze i możesz wybrać plik, aby wyświetlić podgląd skopiowanych danych.
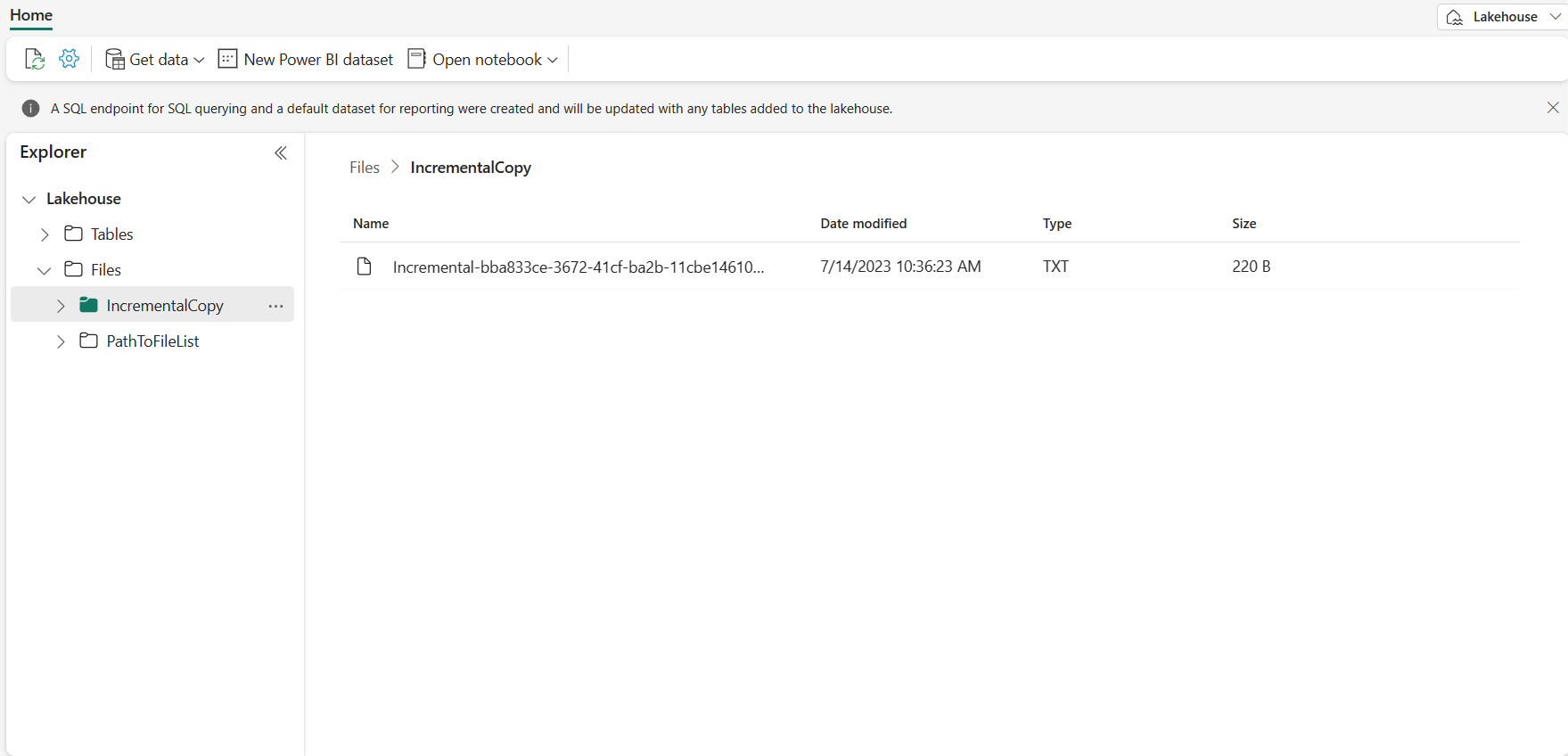
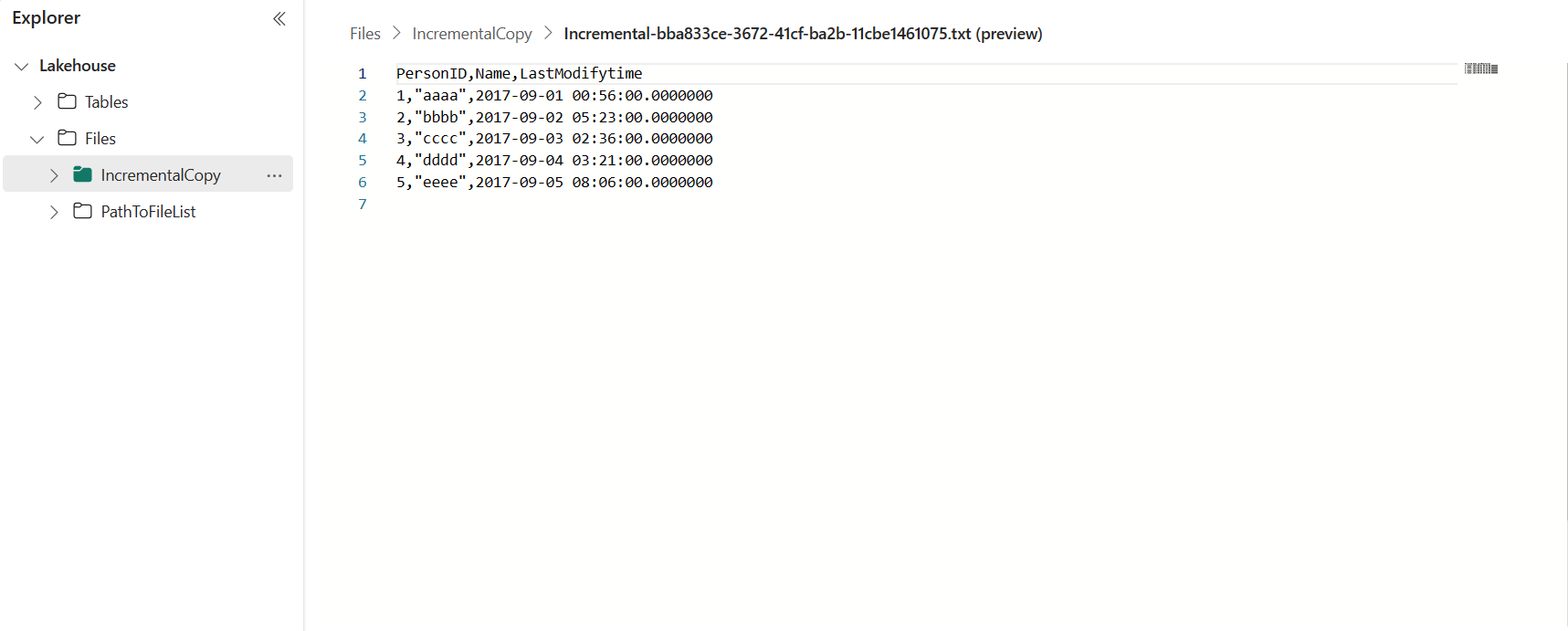
Dodawanie większej liczby danych w celu wyświetlenia wyników kopiowania przyrostowego
Po zakończeniu pierwszego uruchomienia potoku spróbujmy dodać więcej danych w tabeli źródłowej magazynu danych, aby sprawdzić, czy ten potok może skopiować dane przyrostowe.
Krok 1. Dodawanie większej ilości danych do źródła
Wstaw nowe dane do magazynu danych, uruchamiając następujące zapytanie:
INSERT INTO data_source_table
VALUES (6, 'newdata','9/6/2017 2:23:00 AM')
INSERT INTO data_source_table
VALUES (7, 'newdata','9/7/2017 9:01:00 AM')
Zaktualizowane dane dla data_source_table to:
PersonID | Name | LastModifytime
-------- | ---- | --------------
1 | aaaa | 2017-09-01 00:56:00.000
2 | bbbb | 2017-09-02 05:23:00.000
3 | cccc | 2017-09-03 02:36:00.000
4 | dddd | 2017-09-04 03:21:00.000
5 | eeee | 2017-09-05 08:06:00.000
6 | newdata | 2017-09-06 02:23:00.000
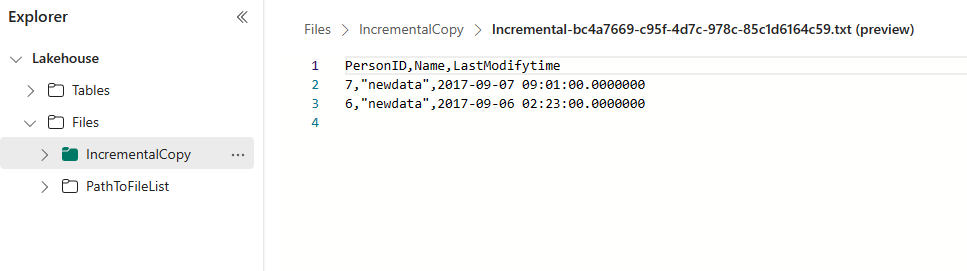
7 | newdata | 2017-09-07 09:01:00.000
Krok 2. Wyzwalanie innego uruchomienia potoku i monitorowanie wyniku
Wróć do strony potoku. Na górnym pasku ponownie wybierz pozycję Uruchom na karcie Narzędzia główne. Potok zostanie uruchomiony i można monitorować potok w obszarze Dane wyjściowe.
Przejdź do usługi Lakehouse, znajdziesz nowy skopiowany plik danych znajduje się w określonym folderze i możesz wybrać plik, aby wyświetlić podgląd skopiowanych danych. Zobaczysz, że dane przyrostowe są wyświetlane w tym pliku.
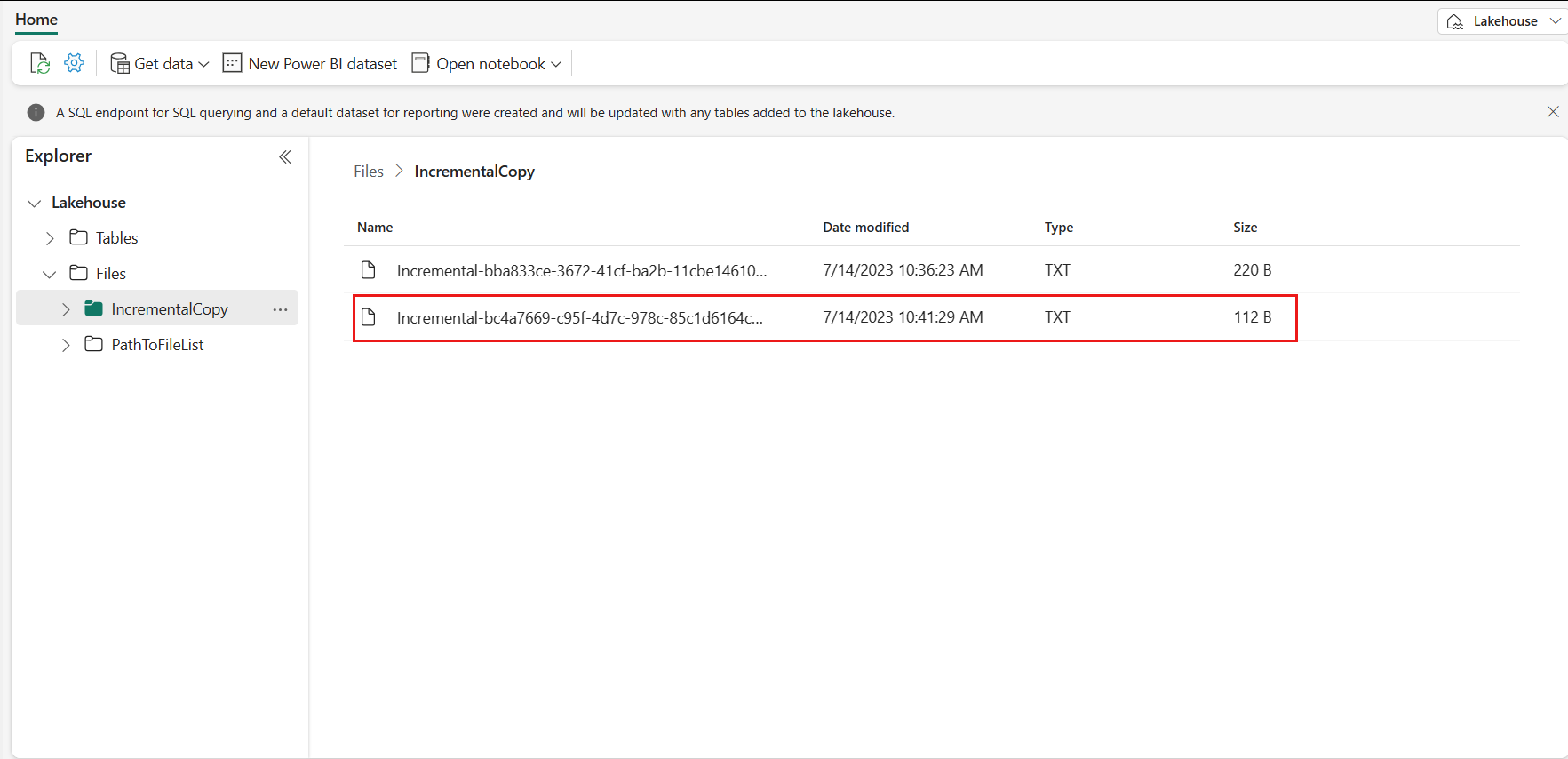
Powiązana zawartość
Następnie przejdź dalej, aby dowiedzieć się więcej na temat kopiowania z usługi Azure Blob Storage do usługi Lakehouse.
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla