Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Usługa Data Wrangler przyspiesza przepływ pracy przygotowywania danych, zapewniając immersyjny interfejs wizualny do eksploracyjnej analizy danych. W tym artykule dowiesz się, jak:
- Uruchamianie narzędzia Data Wrangler z notesu usługi Fabric
- Eksplorowanie danych za pomocą interaktywnych wizualizacji i statystyk podsumowania
- Stosowanie typowych operacji czyszczenia danych przy użyciu automatycznego generowania kodu
- Eksportuj ponownie do notesu funkcje pandas lub PySpark, które można wielokrotnie używać.
Artykuł skupia się na DataFrame'ach pandas. W przypadku ramek danych platformy Spark odnieś się do tego zasobu.
Wymagania wstępne
Uzyskaj subskrypcję usługi Microsoft Fabric. Możesz też utworzyć konto bezpłatnej wersji próbnej usługi Microsoft Fabric.
Zaloguj się do usługi Microsoft Fabric.
Przełącz się na Fabric, używając przełącznika nawigacji w lewej dolnej części strony głównej.

Ograniczenia
- Niestandardowe operacje kodu obecnie obsługują tylko ramki danych pandas.
- Wyświetlacz Data Wrangler działa najlepiej na dużych monitorach. Można jednak zminimalizować lub ukryć różne części interfejsu, aby pomieścić mniejsze ekrany.
Uruchamianie narzędzia Data Wrangler
Możesz uruchomić narzędzie Data Wrangler bezpośrednio z notesu usługi Microsoft Fabric, aby eksplorować i przekształcać dowolne biblioteki pandas lub Spark DataFrame.
Aby rozpocząć pracę z przykładowymi danymi:
Ten fragment kodu przedstawia sposób odczytywania przykładowych danych do ramki danych biblioteki pandas:
import pandas as pd
# Read a CSV into a Pandas DataFrame
df = pd.read_csv("https://raw.githubusercontent.com/plotly/datasets/master/titanic.csv")
display(df)
Na karcie "Narzędzia główne" na wstążce notesu użyj listy rozwijanej Data Wrangler, aby przeglądać aktywne ramki danych dostępne do edycji. Wybierz ten, który chcesz otworzyć w narzędziu Data Wrangler.
Napiwek
Nie można otworzyć narzędzia Data Wrangler, gdy jądro notatnika jest zajęte. Komórka musi zakończyć swoje działanie, zanim będzie można uruchomić Data Wrangler, co pokazano na tym zrzucie ekranu.

Uruchom Data Wrangler z komórki
Możesz również otworzyć narzędzie Data Wrangler bezpośrednio z komórki notesu bez przechodzenia do wstążki. Ten wbudowany punkt dostępu udostępnia narzędzie Data Wrangler dokładnie tam, gdzie pracujesz z DataFrame’ami.
Po uruchomieniu komórki, która wyprowadza ramkę danych, na poziomie komórki zostanie wyświetlony monit narzędzia Data Wrangler. Wybierz monit, aby otworzyć tę ramkę danych w narzędziu Data Wrangler. Obsługiwane polecenia obejmują:
-
df.head()lubdf.head(n) -
df.tail()lubdf.tail(n) -
df.show()lubdf.show(n)
Uruchom komórkę, która wyprowadza ramkę danych:
import pandas as pd df = pd.read_csv("https://raw.githubusercontent.com/plotly/datasets/master/titanic.csv") df.head()Po zakończeniu działania komórki w komórce zostanie wyświetlony monit narzędzia Data Wrangler. Wybierz Otwórz w Data Wrangler, aby uruchomić narzędzie Data Wrangler z użyciem ramki danych
df.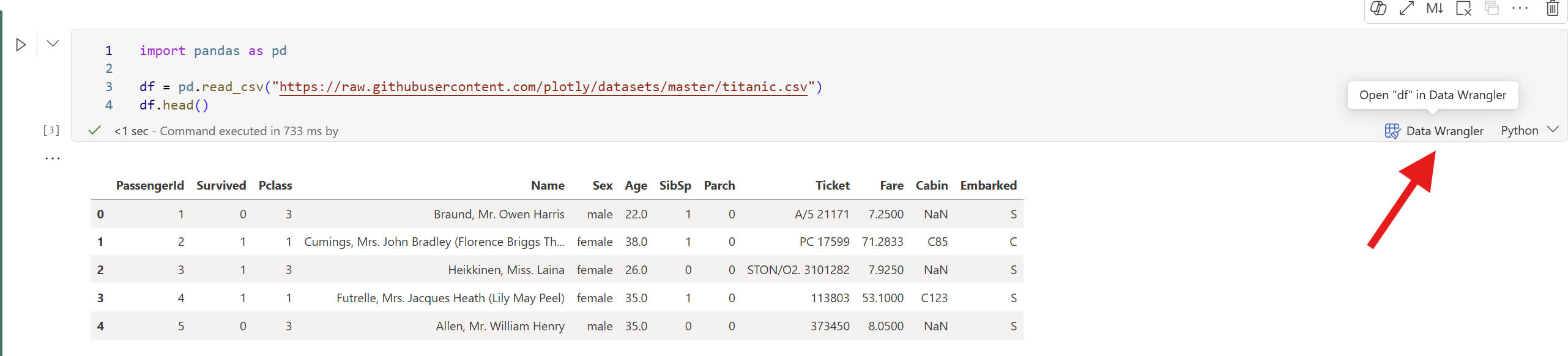

Jeśli komórka definiuje wiele obiektów DataFrame, wyświetlane jest podmenu zawierające listę wszystkich obiektów DataFrame w tej komórce. Możesz otworzyć dowolne z nich w narzędziu Data Wrangler — nawet te, których jawnie nie wypisałeś.
Uruchom komórkę, która definiuje wiele ramek danych:
import pandas as pd titanic_df = pd.read_csv("https://raw.githubusercontent.com/plotly/datasets/master/titanic.csv") iris_df = pd.read_csv("https://raw.githubusercontent.com/plotly/datasets/master/iris-data.csv") titanic_df.head() iris_df.head()Po zakończeniu działania komórki wybierz monit data Wrangler w komórce. Podmenu wyświetla wszystkie ramki danych zdefiniowane w komórce. Wybierz tę, którą chcesz eksplorować.
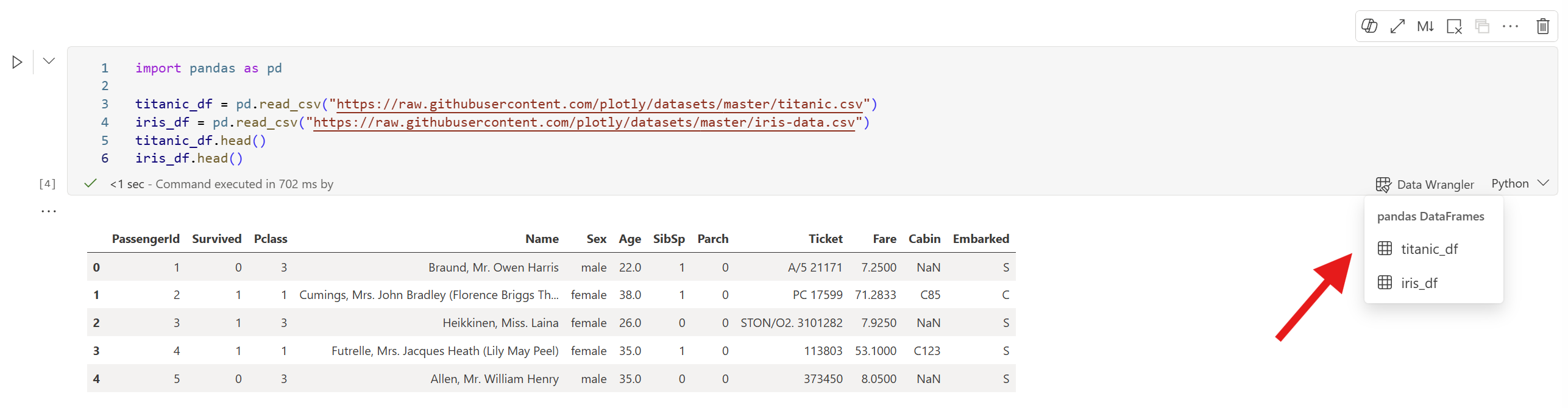

Napiwek
Podmenu wyświetla ramki danych zdefiniowane w bieżącej komórce. Aby otworzyć obiekt DataFrame z poprzedniej komórki, uruchom nową komórkę, która się do niego odwołuje, lub użyj menu rozwijanego Data Wrangler na karcie wstążki Home, aby przeglądać wszystkie aktywne obiekty DataFrame.
Wybieranie przykładów niestandardowych
Aby otworzyć niestandardowy przykład dowolnej aktywnej ramki danych z elementem Data Wrangler, wybierz z listy rozwijanej pozycję Wybierz przykład niestandardowy , jak pokazano na poniższym zrzucie ekranu:

Ta akcja otwiera okno dialogowe z opcjami określającymi rozmiar żądanej próbki (liczba wierszy) i metodę próbkowania (pierwsze rekordy, ostatnie rekordy lub losowy zestaw). Pierwsze 5000 wierszy ramki danych służy jako domyślny rozmiar próbki, jak pokazano na poniższym zrzucie ekranu:

Wyświetlanie statystyk podsumowania
Podczas ładowania Data Wrangler w panelu Podsumowanie zostanie wyświetlony opisowy widok wybranego DataFrame. To omówienie zawiera informacje o wymiarach ramki danych, brakujących wartościach i nie tylko. Po wybraniu dowolnej kolumny w siatce Wrangler danych panel Podsumowanie zostanie zaktualizowany w celu wyświetlenia opisowych statystyk dotyczących tej konkretnej kolumny. Szybkie szczegółowe informacje o każdej kolumnie są również dostępne w nagłówku.
Napiwek
Statystyki i wizualizacje specyficzne dla kolumn (zarówno w panelu Podsumowanie , jak i w nagłówkach kolumn) zależą od typu danych kolumny. Na przykład tylko wtedy, gdy kolumna jest rzutowana jako typ liczbowy, pojawia się w nagłówku kolumny histogram o podziale na przedziały, jak pokazano na tym zrzucie ekranu.

Przeglądanie operacji czyszczenia danych
Panel Operacje zawiera listę operacji czyszczenia danych z możliwością wyszukiwania. Po wybraniu operacji czyszczenia danych z panelu Operacje należy podać kolumnę docelową lub kolumny wraz z wszelkimi wymaganymi parametrami, aby ukończyć operację. Na przykład monit o liczbowe skalowanie kolumny wymaga nowego zakresu wartości, jak pokazano na poniższym zrzucie ekranu:

Napiwek
Możesz zastosować mniejszy wybór operacji z menu każdego nagłówka kolumny, jak pokazano na poniższym zrzucie ekranu:

Wyświetlanie podglądu i stosowanie operacji
Siatka wyświetlania Data Wrangler automatycznie pokazuje wyniki wybranej operacji, a odpowiedni kod pojawia się w panelu poniżej siatki. Aby zatwierdzić podgląd kodu, wybierz pozycję Zastosuj w dowolnej lokalizacji. Aby usunąć podgląd kodu i wypróbować nową operację, wybierz pozycję Odrzuć , jak pokazano na poniższym zrzucie ekranu:

Po zastosowaniu operacji siatka wyświetlania i podsumowanie statystyk usługi Data Wrangler zostaną zaktualizowane w celu odzwierciedlenia wyników. Kod zostanie wyświetlony na uruchomionej liście zatwierdzonych operacji na panelu Kroki czyszczenia , jak pokazano na poniższym zrzucie ekranu:

Napiwek
Zawsze można cofnąć ostatnio zastosowany krok. Na panelu Kroki czyszczenia zostanie wyświetlona ikona kosza po umieszczeniu kursora na ostatnio zastosowanym kroku, jak pokazano na poniższym zrzucie ekranu:

Ta tabela zawiera podsumowanie operacji obsługiwanych obecnie przez usługę Data Wrangler:
| Operacja | Opis |
|---|---|
| Sortowanie | Sortowanie kolumny w kolejności rosnącej lub malejącej |
| Filtr | Filtrowanie wierszy na podstawie co najmniej jednego warunku |
| Kodowanie jednorazowe | Utwórz nowe kolumny dla każdej unikatowej wartości w istniejącej kolumnie, co wskazuje obecność lub brak tych wartości w wierszu |
| Wieloetykietowy binarizer | Podziel dane za pomocą separatora i utwórz nowe kolumny dla każdej kategorii, oznaczając 1, jeśli wiersz zawiera tę kategorię, oraz 0, jeśli jej nie zawiera |
| Zmienianie typu kolumny | Zmienianie typu danych kolumny |
| Upuść kolumnę | Usuń co najmniej jedną kolumnę |
| Wybieranie kolumny | Wybierz co najmniej jedną kolumnę do zachowania i usuń resztę |
| Zmienianie nazwy kolumny | Zmienianie nazwy kolumny |
| Usuń brakujące wartości | Usuwanie wierszy z brakującymi wartościami |
| Usuwanie zduplikowanych wierszy | Usuwanie wszystkich wierszy, które mają zduplikowane wartości w co najmniej jednej kolumnie |
| Wypełnianie brakujących wartości | Zastąp komórki brakującymi wartościami nową wartością |
| Znajdowanie i zastępowanie | Zamień komórki dokładnie dopasowanym wzorcem |
| Grupuj według kolumn i agreguj | Grupowanie według wartości kolumn i agregowanie wyników |
| Usuń białe znaki | Usuń białe znaki od początku i końca tekstu |
| Podziel tekst | Dzielenie kolumny na kilka kolumn na podstawie ogranicznika zdefiniowanego przez użytkownika |
| Konwertowanie tekstu na małe litery | Konwertowanie tekstu na małe litery |
| Konwertowanie tekstu na wielkie litery | Konwertowanie tekstu na WIELKIE LITERY |
| Skalowanie wartości minimalnych/maksymalnych | Skalowanie kolumny liczbowej między wartością minimalną i maksymalną |
| Wypełnienie błyskawiczne | Automatycznie utwórz nową kolumnę na podstawie przykładów pochodzących z istniejącej kolumny |
Dostosowywanie wyświetlania
W dowolnym momencie możesz dostosować interfejs przy użyciu karty "Widoki" na pasku narzędzi powyżej siatki wyświetlania elementu Data Wrangler. Ta opcja może ukrywać lub wyświetlać różne okienka na podstawie preferencji i rozmiaru ekranu, jak pokazano na poniższym zrzucie ekranu:

Zapisywanie i eksportowanie kodu
Pasek narzędzi powyżej siatki wyświetlania Wrangler danych zawiera opcje zapisywania wygenerowanego kodu. Możesz skopiować kod do schowka lub wyeksportować go do notatnika jako funkcję. Eksportowanie kodu powoduje zamknięcie narzędzia Data Wrangler i dodanie nowej funkcji do komórki kodu w notesie. Można również pobrać oczyszczoną ramkę danych jako plik CSV.
Napiwek
Narzędzie Data Wrangler generuje kod uruchamiany tylko po ręcznym uruchomieniu nowej komórki i nie zastępuje oryginalnej ramki danych, jak pokazano na poniższym zrzucie ekranu:

Następnie możesz uruchomić ten wyeksportowany kod, jak pokazano na poniższym zrzucie ekranu:

Dalsze kroki
Teraz, gdy wiesz już, jak używać narzędzia Data Wrangler z ramkami danych biblioteki pandas, zapoznaj się z następującymi zasobami:
- Używanie platformy Data Wrangler z ramkami danych platformy Spark — stosowanie tych samych technik do ramek danych platformy Spark
- Obejrzyj pokaz na żywo — zobacz Data Wrangler w akcji z Guy in a Cube
- Try Data Wrangler w programie VS Code — korzystanie z narzędzia Data Wrangler w programie Visual Studio Code
Chcesz przesłać opinię? Podziel się swoimi pomysłami na forum Fabric Ideas.