Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Microsoft Fabric umożliwia operacjonalizacja modeli machine learning przy użyciu skalowalnej funkcji PREDICT. Ta funkcja obsługuje ocenianie wsadowe w dowolnym silniku obliczeniowym. Przewidywania wsadowe można wygenerować bezpośrednio z notesu Microsoft Fabric lub na stronie elementu danego modelu uczenia maszynowego.
Z tego artykułu dowiesz się, jak zastosować funkcję PREDICT, pisząc kod samodzielnie lub korzystając z środowiska interfejsu użytkownika z przewodnikiem, które obsługuje ocenianie wsadowe.
Wymagania wstępne
Pobierz subskrypcję Microsoft Fabric. Możesz też utworzyć bezpłatne konto Microsoft Fabric wersji próbnej.
Zaloguj się do Microsoft Fabric.
Przełącz się na Fabric, używając przełącznika nawigacji w lewej dolnej części strony głównej.

Ograniczenia
- Funkcja PREDICT obsługuje obecnie tylko następujące wersje modelu uczenia maszynowego:
- CatBoost
- Keras
- LightGBM
- ONNX
- Prorok
- PyTorch
- Sklearn
- Spark
- Statsmodels
- TensorFlow
- XGBoost
- Funkcja PREDICT wymaga zapisania modeli uczenia maszynowego w formacie MLflow z wypełnionymi podpisami.
- Funkcja PREDICT nie obsługuje modeli uczenia maszynowego z wieloma tensorami jako danymi wejściowymi lub wyjściowymi.
Wywoływanie funkcji PREDICT z notesu
Funkcja PREDICT obsługuje modele spakowane przez platformę MLflow w rejestrze Microsoft Fabric. Jeśli w obszarze roboczym istnieje już wytrenowany i zarejestrowany model uczenia maszynowego, możesz przejść do kroku 2. Jeśli nie, krok 1 zawiera przykładowy kod, który przeprowadzi Cię przez trenowanie przykładowego modelu regresji logistycznej. Użyj tego modelu, aby wygenerować przewidywania wsadowe na końcu procedury.
Trenowanie modelu uczenia maszynowego i rejestrowanie go w usłudze MLflow. W następnym przykładzie kodu użyto interfejsu API platformy MLflow do utworzenia eksperymentu machine learning, a następnie uruchomienia środowiska MLflow dla modelu regresji logistycznej scikit-learn. Wersja modelu jest następnie przechowywana i zarejestrowana w rejestrze Microsoft Fabric. Aby uzyskać więcej informacji na temat modeli trenowania i śledzenia własnych eksperymentów, zobacz jak trenować modele uczenia maszynowego przy użyciu biblioteki scikit-learn.
import mlflow import numpy as np from sklearn.linear_model import LogisticRegression from sklearn.datasets import load_diabetes from mlflow.models.signature import infer_signature mlflow.set_experiment("diabetes-demo") with mlflow.start_run() as run: lr = LogisticRegression() data = load_diabetes(as_frame=True) lr.fit(data.data, data.target) signature = infer_signature(data.data, data.target) mlflow.sklearn.log_model( lr, "diabetes-model", signature=signature, registered_model_name="diabetes-model" )Załaduj dane testowe jako ramkę danych platformy Spark. Aby wygenerować przewidywania wsadowe przy użyciu modelu uczenia maszynowego wytrenowanego w poprzednim kroku, potrzebne są dane testowe w postaci ramki danych platformy Spark. W poniższym kodzie zastąp wartość zmiennej
testwłasnymi danymi.# You can substitute "test" below with your own data test = spark.createDataFrame(data.frame.drop(['target'], axis=1))MLFlowTransformerUtwórz obiekt, aby załadować model uczenia maszynowego na potrzeby wnioskowania. Aby utworzyć obiekt do generowaniaMLFlowTransformerprzewidywań wsadowych, wykonaj następujące akcje:-
testOkreśl potrzebne kolumny ramki danych jako dane wejściowe modelu (w tym przypadku wszystkie z nich). - Wybierz nazwę nowej kolumny danych wyjściowych (w tym przypadku
predictions). - Podaj poprawną nazwę modelu i wersję modelu na potrzeby generowania tych przewidywań.
Jeśli używasz własnego modelu uczenia maszynowego, zastąp wartości kolumn wejściowych, nazwą kolumny wyjściowej, nazwą modelu i wersją modelu.
from synapse.ml.predict import MLFlowTransformer # You can substitute values below for your own input columns, # output column name, model name, and model version model = MLFlowTransformer( inputCols=test.columns, outputCol='predictions', modelName='diabetes-model', modelVersion=1 )-
Generowanie przewidywań przy użyciu funkcji PREDICT. Aby wywołać funkcję PREDICT, użyj interfejsu API Transformer, interfejsu API SQL platformy Spark lub funkcji zdefiniowanej przez użytkownika (UDF) PySpark. W poniższych sekcjach przedstawiono sposób generowania przewidywań wsadowych przy użyciu danych testowych i modelu uczenia maszynowego zdefiniowanego w poprzednich krokach przy użyciu różnych metod wywoływania funkcji PREDICT.
PRZEWIDYWANIE za pomocą API Transformer
Ten kod wywołuje funkcję PREDICT za pomocą Transformer API. Jeśli używasz własnego modelu uczenia maszynowego, zastąp wartości modelu i danych testowych.
# You can substitute "model" and "test" below with values
# for your own model and test data
model.transform(test).show()
PREDICT with the Spark SQL API
Ten kod wywołuje funkcję PREDICT przy użyciu interfejsu API SQL platformy Spark. Jeśli używasz własnego modelu uczenia maszynowego, zastąp wartości , model_namemodel_versioni features nazwą modelu, wersją modelu i kolumnami funkcji.
Uwaga
W przypadku generowania przewidywań przy użyciu interfejsu API SQL platformy Spark nadal trzeba utworzyć MLFlowTransformer obiekt, jak pokazano w kroku 3.
from pyspark.ml.feature import SQLTransformer
# You can substitute "model_name," "model_version," and "features"
# with values for your own model name, model version, and feature columns
model_name = 'diabetes-model'
model_version = 1
features = test.columns
sqlt = SQLTransformer().setStatement(
f"SELECT PREDICT('{model_name}/{model_version}', {','.join(features)}) as predictions FROM __THIS__")
# You can substitute "test" below with your own test data
sqlt.transform(test).show()
PREDICT with a user-defined function (PRZEWIDYWANIE za pomocą funkcji zdefiniowanej przez użytkownika)
Ten kod wywołuje funkcję PREDICT przy użyciu funkcji UDF PySpark. Jeśli używasz własnego modelu uczenia maszynowego, zastąp wartości modelu i funkcji.
from pyspark.sql.functions import col, pandas_udf, udf, lit
# You can substitute "model" and "features" below with your own values
my_udf = model.to_udf()
features = test.columns
test.withColumn("PREDICT", my_udf(*[col(f) for f in features])).show()
Generowanie kodu PREDICT na stronie elementu modelu uczenia maszynowego
Na stronie elementu dowolnego modelu uczenia maszynowego możesz wybrać jedną z tych opcji, aby rozpocząć generowanie przewidywań wsadowych dla określonej wersji modelu przy użyciu funkcji PREDICT:
- Skopiuj szablon kodu do notesu i dostosuj parametry samodzielnie.
- Użyj interaktywnego środowiska użytkownika, aby wygenerować kod PREDICT.
Korzystanie z interfejsu użytkownika z przewodnikiem
Interaktywny interfejs użytkownika poprowadzi Cię przez następujące kroki:
- Wybierz dane źródłowe do oceniania.
- Poprawnie przyporządkuj dane do danych wejściowych modelu uczenia maszynowego.
- Określ miejsce docelowe dla danych wyjściowych modelu.
- Utwórz notes, który używa funkcji PREDICT do generowania i przechowywania wyników przewidywania.
Aby użyć prowadzonego doświadczenia,
Przejdź do strony elementu dla danej wersji modelu uczenia maszynowego.
Z listy rozwijanej Zastosuj tę wersję wybierz pozycję Zastosuj ten model w kreatorze.
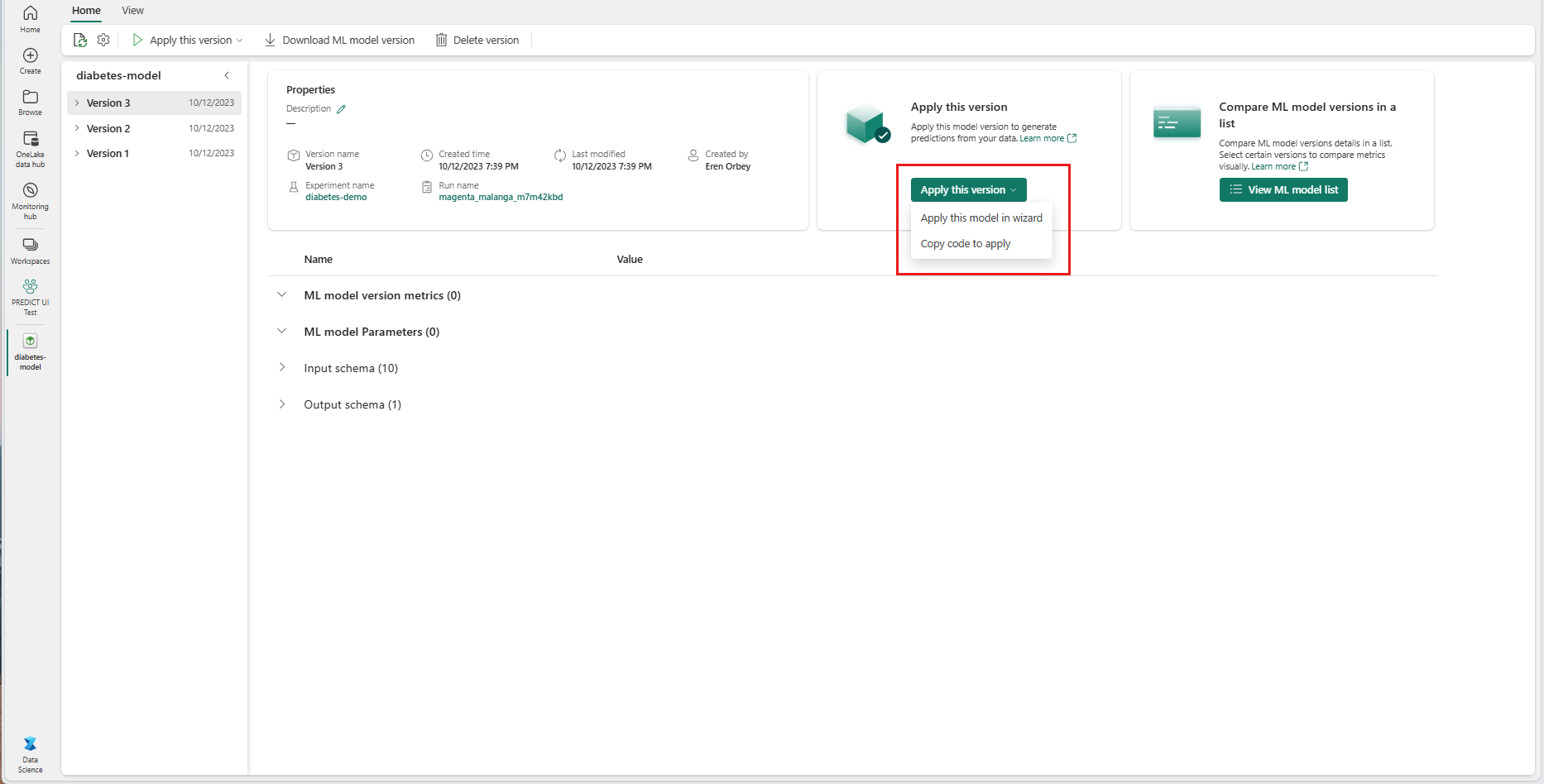
W kroku "Wybierz tabelę wejściową" zostanie otwarte okno "Zastosuj przewidywania modelu uczenia maszynowego".
Wybierz tabelę wejściową z usługi Lakehouse w bieżącym obszarze roboczym.
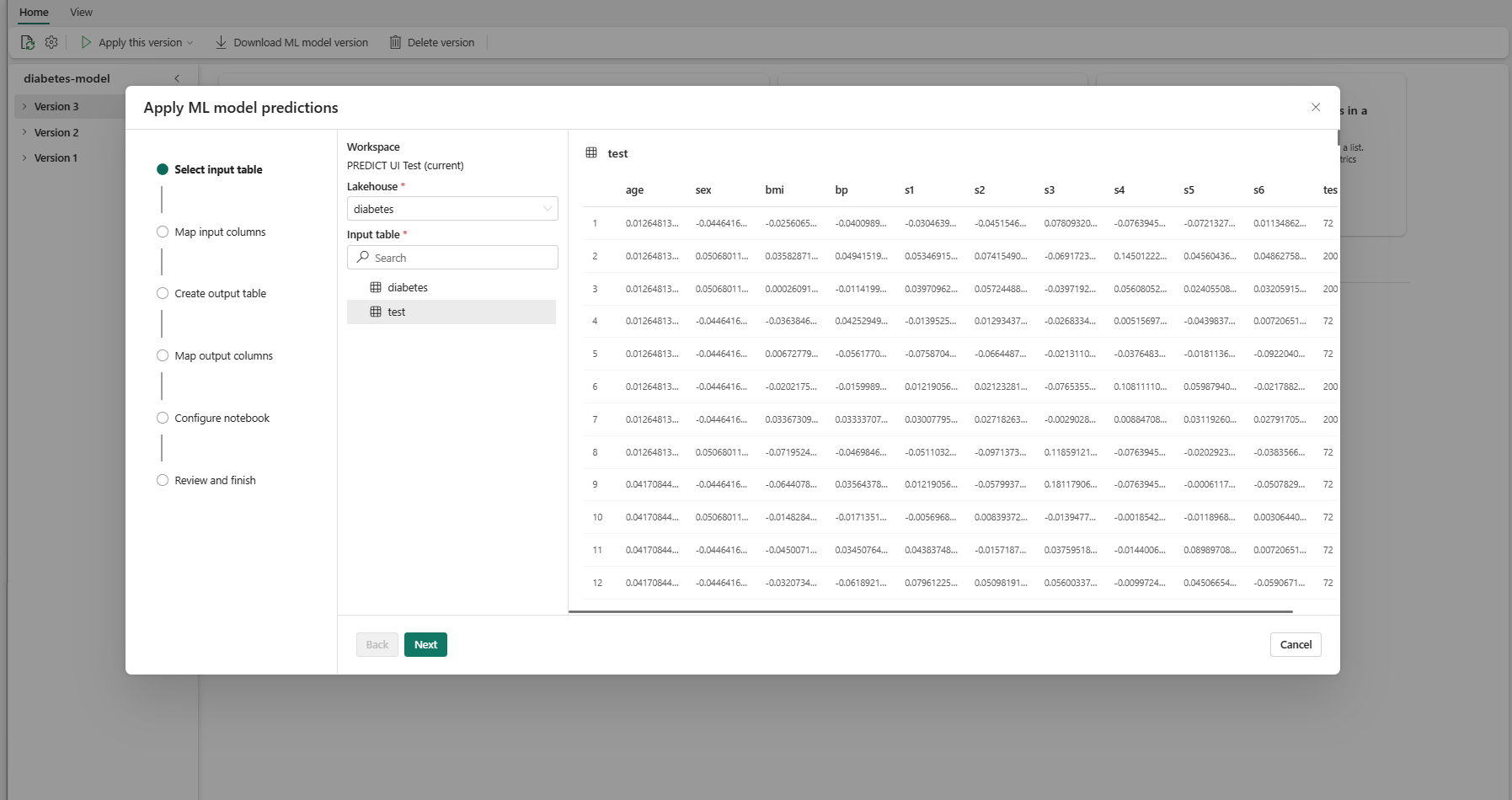
Wybierz przycisk Dalej , aby przejść do kroku "Mapuj kolumny wejściowe".
Mapuj nazwy kolumn z tabeli źródłowej na pola wejściowe modelu uczenia maszynowego, które są pobierane z sygnatury modelu. Musisz podać kolumnę wejściową dla wszystkich wymaganych pól modelu. Ponadto typy danych kolumny źródłowej muszą być zgodne z oczekiwanymi typami danych modelu.
Wskazówka
Kreator wstępnie wypełnia to mapowanie, jeśli nazwy kolumn tabeli wejściowej są zgodne z nazwami kolumn zarejestrowanych w podpisie modelu uczenia maszynowego.
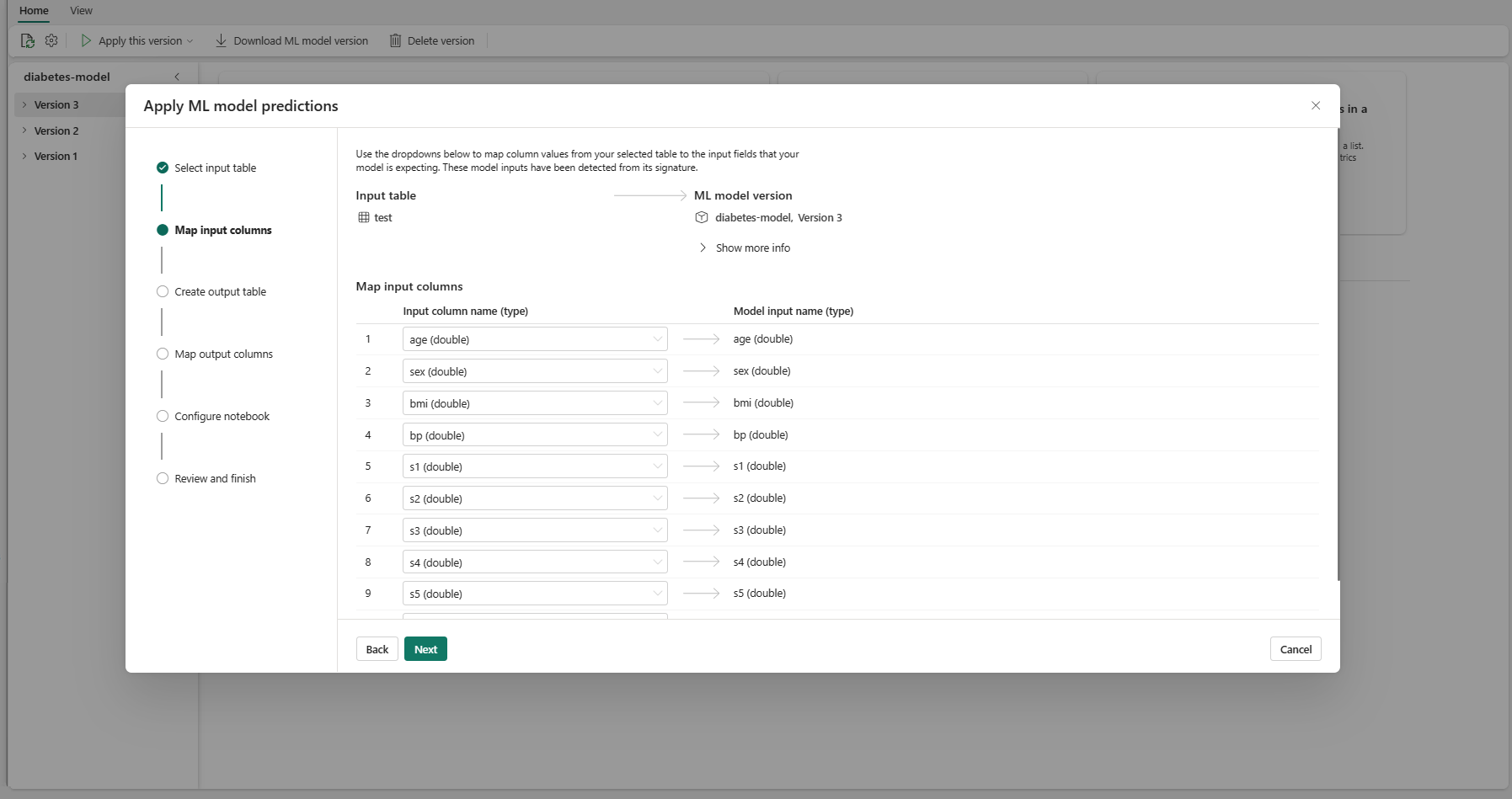
Wybierz przycisk Dalej , aby przejść do kroku "Utwórz tabelę danych wyjściowych".
Podaj nazwę nowej tabeli w wybranym jeziorze bieżącego obszaru roboczego. Ta tabela danych wyjściowych przechowuje wartości wejściowe modelu uczenia maszynowego i dołącza wartości przewidywania do tej tabeli. Domyślnie tabela wyjściowa jest tworzona w tym samym lakehouse co tabela wejściowa. Możesz zmienić docelowy lakehouse.
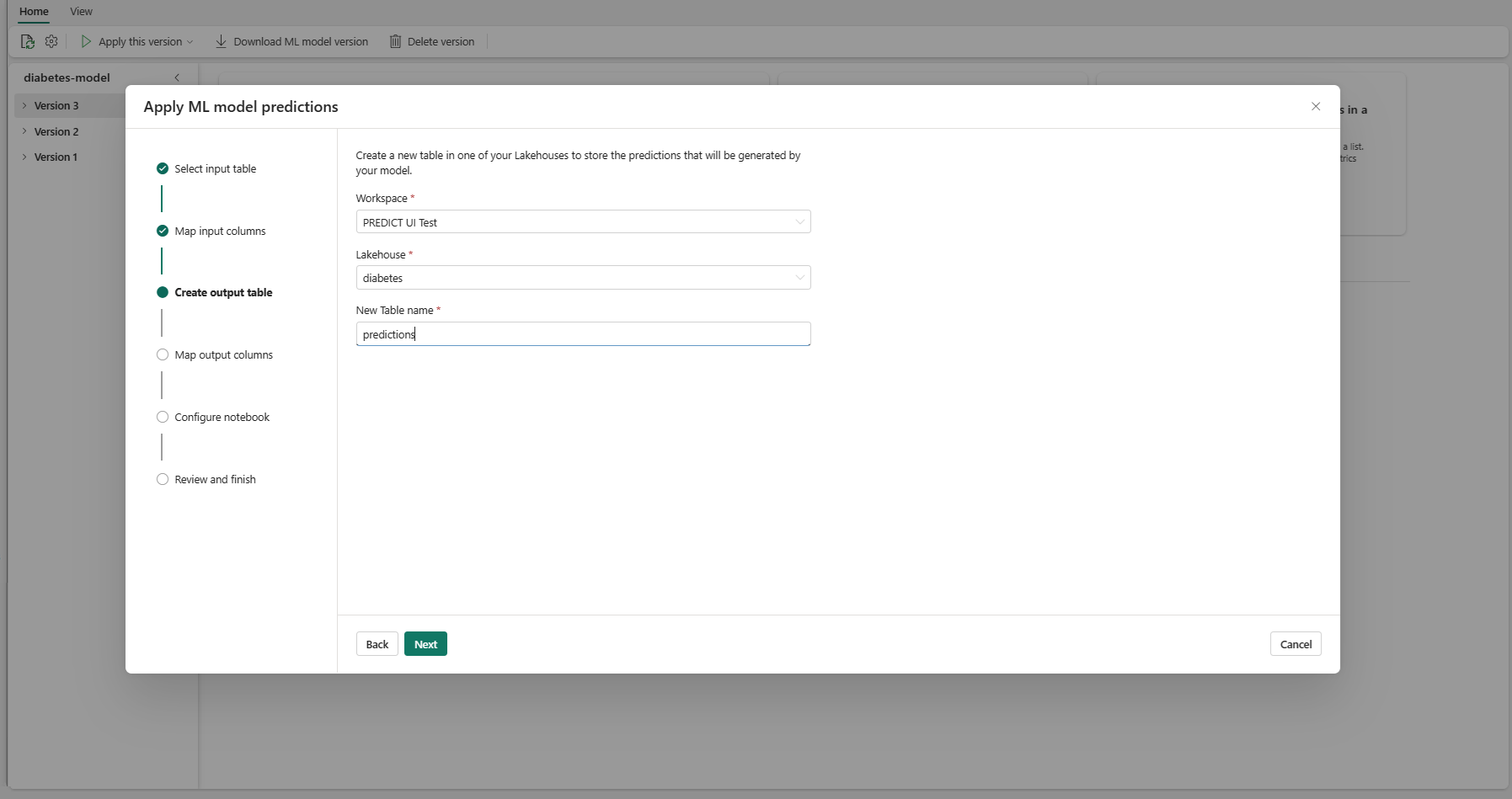
Wybierz pozycję Dalej , aby przejść do kroku "Mapuj kolumny wyjściowe".
Użyj podanych pól tekstowych, aby nazwać kolumny tabeli wyjściowej, która przechowuje przewidywania modelu uczenia maszynowego.
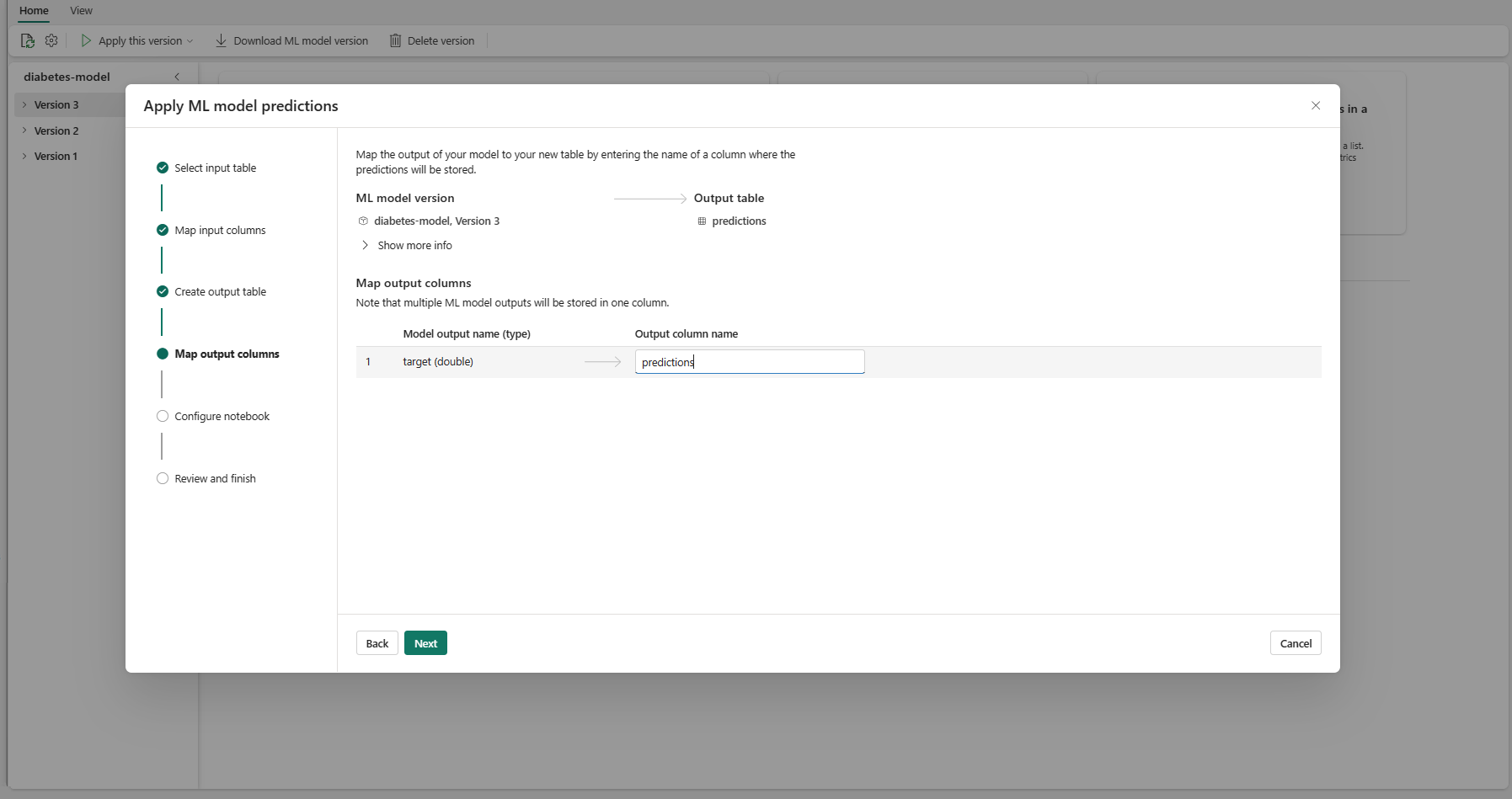
Wybierz przycisk Dalej , aby przejść do kroku "Konfigurowanie notesu".
Podaj nazwę nowego notesu, który uruchamia wygenerowany kod PREDICT. Kreator wyświetla podgląd wygenerowanego kodu w tym kroku. Jeśli chcesz, możesz skopiować kod do schowka i wkleić go do istniejącego notatnika.
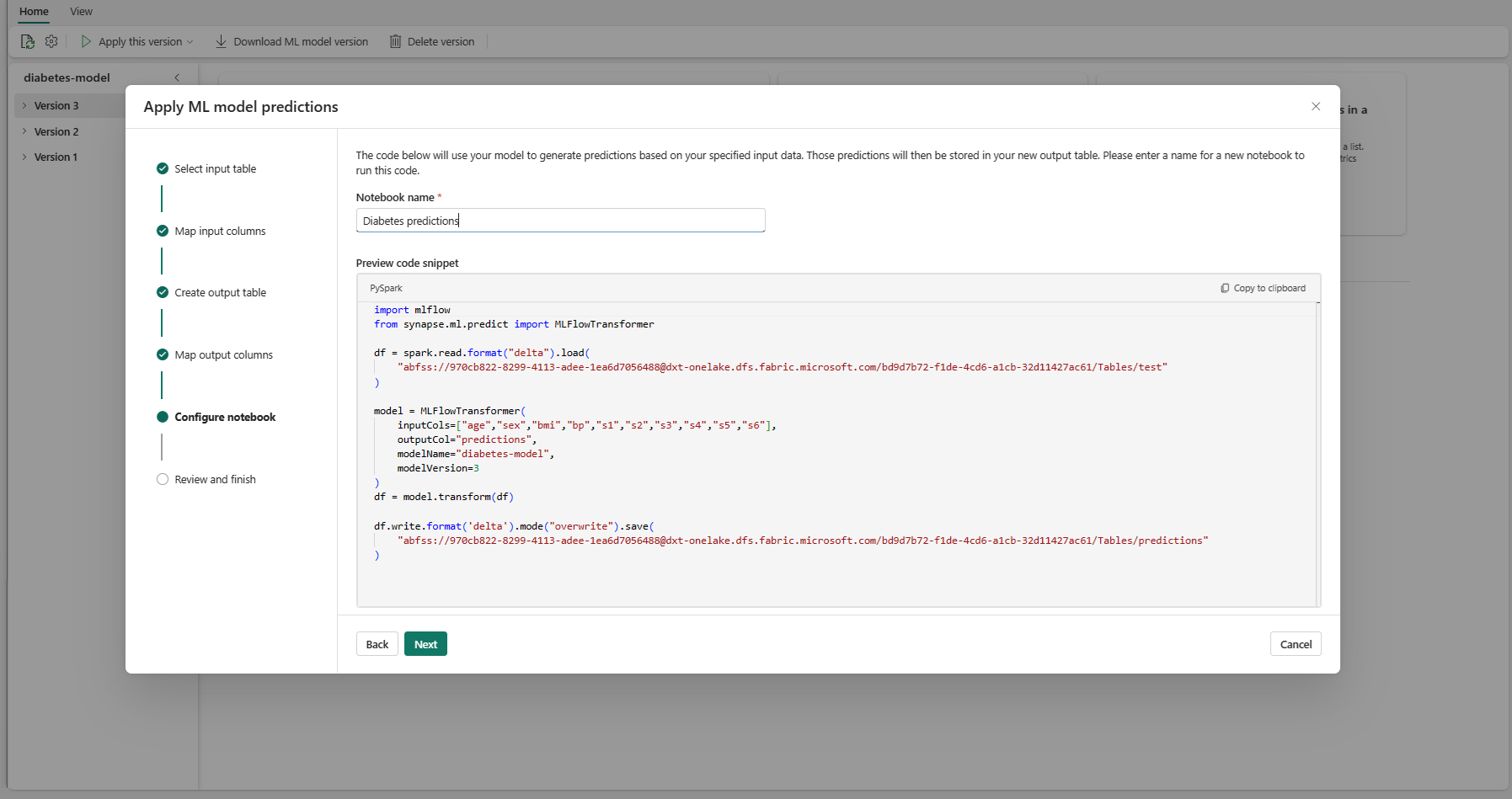
Wybierz przycisk Dalej , aby przejść do kroku "Przeglądanie i kończenie".
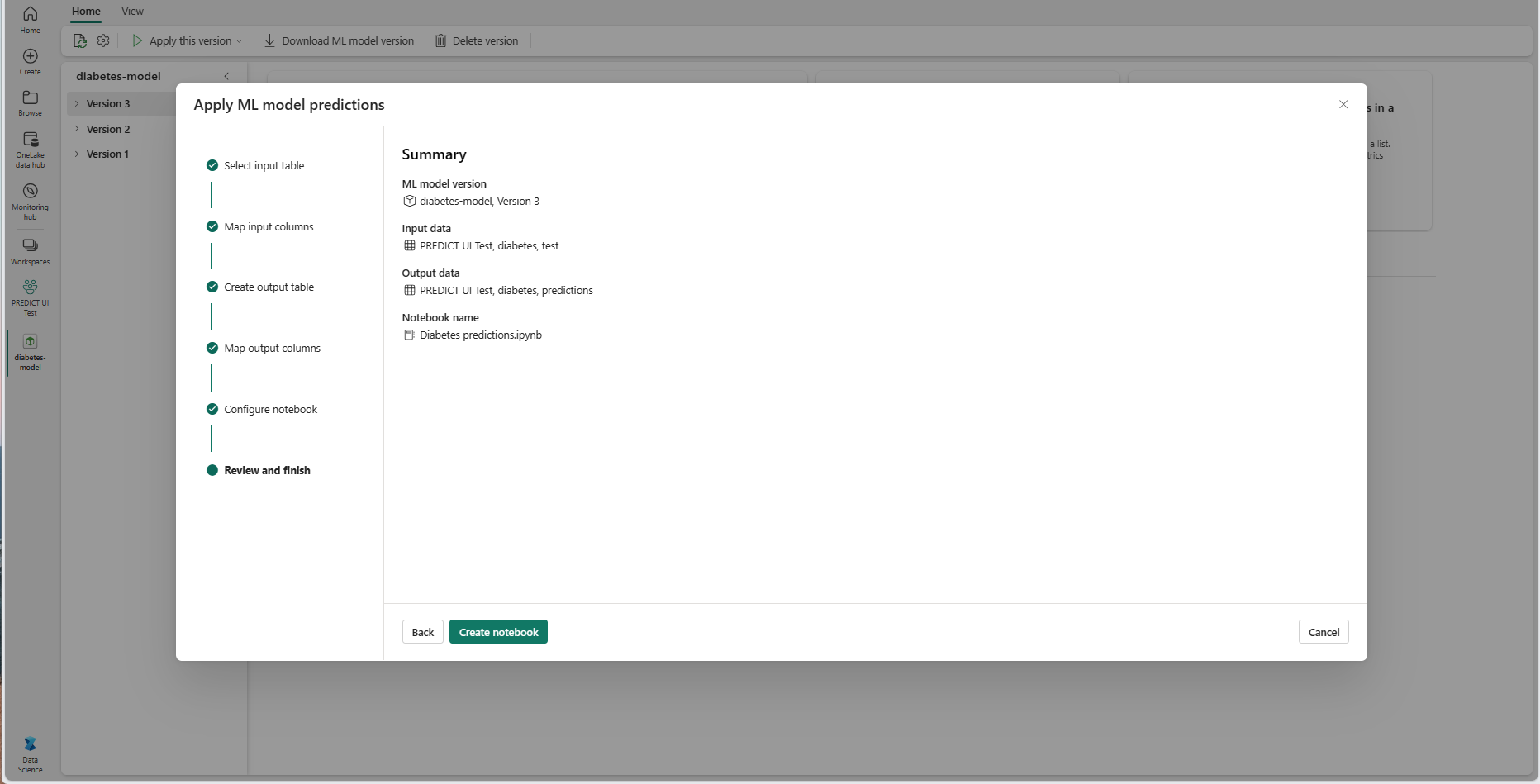
Przejrzyj szczegóły na stronie podsumowania i wybierz pozycję Utwórz notes , aby dodać nowy notes z wygenerowanym kodem do obszaru roboczego. Możesz przejść bezpośrednio do tego notesu, w którym możesz uruchomić kod w celu wygenerowania i przechowywania przewidywań.







Używanie dostosowywalnego szablonu kodu
Aby użyć szablonu kodu do generowania przewidywań wsadowych:
- Przejdź do strony elementu dla danej wersji modelu uczenia maszynowego.
- Wybierz pozycję Kopiuj kod, który ma być stosowany z listy rozwijanej Zastosuj tę wersję . Wybrana opcja kopiuje konfigurowalny szablon kodu.
Możesz wkleić ten szablon kodu do notesu, aby wygenerować przewidywania wsadowe za pomocą modelu uczenia maszynowego. Aby pomyślnie uruchomić szablon kodu, ręcznie zastąp następujące wartości:
-
<INPUT_TABLE>: ścieżka pliku dla tabeli, która dostarcza dane wejściowe do modelu uczenia maszynowego. -
<INPUT_COLS>: tablica nazw kolumn z tabeli wejściowej do podania do modelu uczenia maszynowego. -
<OUTPUT_COLS>: nazwa nowej kolumny w tabeli wyjściowej, która przechowuje przewidywania. -
<MODEL_NAME>: nazwa modelu uczenia maszynowego, który ma być używany do generowania przewidywań. -
<MODEL_VERSION>: wersja modelu uczenia maszynowego do użycia do generowania przewidywań. -
<OUTPUT_TABLE>: ścieżka pliku tabeli, w której są przechowywane przewidywania.

import mlflow
from synapse.ml.predict import MLFlowTransformer
df = spark.read.format("delta").load(
<INPUT_TABLE> # Your input table filepath here
)
model = MLFlowTransformer(
inputCols=<INPUT_COLS>, # Your input columns here
outputCol=<OUTPUT_COLS>, # Your new column name here
modelName=<MODEL_NAME>, # Your ML model name here
modelVersion=<MODEL_VERSION> # Your ML model version here
)
df = model.transform(df)
df.write.format('delta').mode("overwrite").save(
<OUTPUT_TABLE> # Your output table filepath here
)