Tworzenie jeziora dla usługi Direct Lake
W tym artykule opisano sposób tworzenia magazynu danych lakehouse, utworzenia tabeli Delta w magazynie lakehouse, a następnie stworzenia podstawowego modelu semantycznego dla magazynu lakehouse w obszarze roboczym usługi Microsoft Fabric.
Przed rozpoczęciem tworzenia architektury lakehouse dla Direct Lake, przeczytaj Omówienie Direct Lake.
Tworzenie domu nad jeziorem
W obszarze roboczym usługi Microsoft Fabric wybierz pozycję Nowy>Więcej opcji, następnie w obszarze Data Engineeringwybierz kafelek Lakehouse.

W oknie dialogowym New lakehouse wprowadź nazwę, a następnie wybierz pozycję Utwórz. Nazwa może zawierać tylko znaki alfanumeryczne i podkreślenia.

Sprawdź, czy nowy lakehouse został utworzony i otwiera się pomyślnie.
Tworzenie tabeli delty w lakehouse
Po utworzeniu nowego lakehouse należy utworzyć co najmniej jedną tabelę Delta, aby usługa Direct Lake mogła uzyskiwać dostęp do niektórych danych. Usługa Direct Lake może odczytywać pliki w formacie parquet, ale aby uzyskać najlepszą wydajność, najlepiej jest skompresować dane, stosując metodę VORDER. VORDER kompresuje dane przy użyciu natywnego algorytmu kompresji silnika Power BI. Dzięki temu aparat może ładować dane do pamięci tak szybko, jak to możliwe.
Istnieje wiele opcji ładowania danych do magazynu lakehouse, w tym potoków danych i skryptów. W poniższych krokach użyto narzędzia PySpark, aby dodać tabelę Delta do usługi Lakehouse w oparciu o Azure Open Dataset:
W nowo utworzonym lakehouse wybierz Otwórz notes, a następnie wybierz Nowy notes.

Skopiuj i wklej poniższy fragment kodu do pierwszej komórki kodu, aby umożliwić platformie SPARK dostęp do otwartego modelu, a następnie naciśnij Shift + Enter, aby uruchomić kod.
# Azure storage access info blob_account_name = "azureopendatastorage" blob_container_name = "holidaydatacontainer" blob_relative_path = "Processed" blob_sas_token = r"" # Allow SPARK to read from Blob remotely wasbs_path = 'wasbs://%s@%s.blob.core.windows.net/%s' % (blob_container_name, blob_account_name, blob_relative_path) spark.conf.set( 'fs.azure.sas.%s.%s.blob.core.windows.net' % (blob_container_name, blob_account_name), blob_sas_token) print('Remote blob path: ' + wasbs_path)Sprawdź, czy kod pomyślnie wyświetli zdalną ścieżkę obiektu blob.

Skopiuj i wklej następujący kod do następnej komórki, a następnie naciśnij Shift + Enter.
# Read Parquet file into a DataFrame. df = spark.read.parquet(wasbs_path) print(df.printSchema())Sprawdź, czy kod pomyślnie wyprowadza schemat ramki danych.

Skopiuj i wklej następujące wiersze do następnej komórki, a następnie naciśnij Shift + Enter. Pierwsza instrukcja umożliwia metodę kompresji VORDER, a następna instrukcja zapisuje ramkę danych jako tabelę delta w lakehouse.
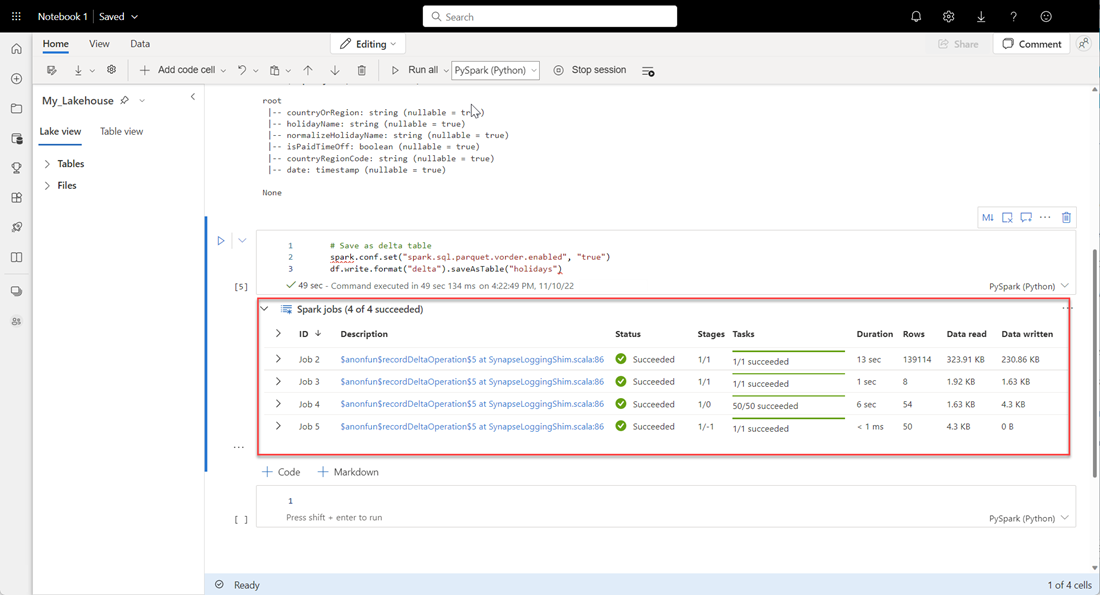
# Save as delta table spark.conf.set("spark.sql.parquet.vorder.enabled", "true") df.write.format("delta").saveAsTable("holidays")Sprawdź, czy wszystkie zadania PLATFORMy SPARK zostały ukończone pomyślnie. Rozwiń listę zadań PLATFORMy SPARK, aby wyświetlić więcej szczegółów.
Aby sprawdzić, czy tabela została pomyślnie utworzona, w lewym górnym obszarze obok Tabelawybierz wielokropek (…), a potem opcję Odśwież, po czym rozwiń węzeł Tabela.

Używając tej samej metody, co powyższe lub inne obsługiwane metody, dodaj więcej tabel różnicowych dla danych, które chcesz przeanalizować.
Utwórz podstawowy model Direct Lake dla swojego lakehouse
W usłudze Lakehouse wybierz pozycję Nowy model semantyczny, a następnie w oknie dialogowym wybierz tabele, które mają zostać dołączone.

Wybierz Potwierdź, aby wygenerować model Direct Lake. Model jest automatycznie zapisywany w obszarze roboczym na podstawie nazwy twojego lakehouse, a następnie otwierany jest model.

Wybierz pozycję Otwórz model danych, aby otworzyć środowisko modelowania w sieci Web, w którym można dodawać relacje tabel i miary języka DAX.

Po zakończeniu dodawania relacji i miar języka DAX możesz tworzyć raporty, tworzyć model złożony i wykonywać zapytania dotyczące modelu za pomocą punktów końcowych XMLA w taki sam sposób, jak w przypadku każdego innego modelu.