Integrowanie usługi OneLake z usługą Azure Databricks
W tym scenariuszu pokazano, jak nawiązać połączenie z usługą OneLake za pośrednictwem usługi Azure Databricks. Po ukończeniu tego samouczka będziesz mieć możliwość odczytu i zapisu w usłudze Microsoft Fabric lakehouse z obszaru roboczego usługi Azure Databricks.
Wymagania wstępne
Przed nawiązaniem połączenia musisz mieć następujące elementy:
- Obszar roboczy usługi Fabric i usługa lakehouse.
- Obszar roboczy usługi Azure Databricks w warstwie Premium. Tylko obszary robocze usługi Azure Databricks w warstwie Premium obsługują przekazywanie poświadczeń firmy Microsoft, które są potrzebne w tym scenariuszu.
Konfigurowanie obszaru roboczego usługi Databricks
Otwórz obszar roboczy usługi Azure Databricks i wybierz pozycję Utwórz>klaster.
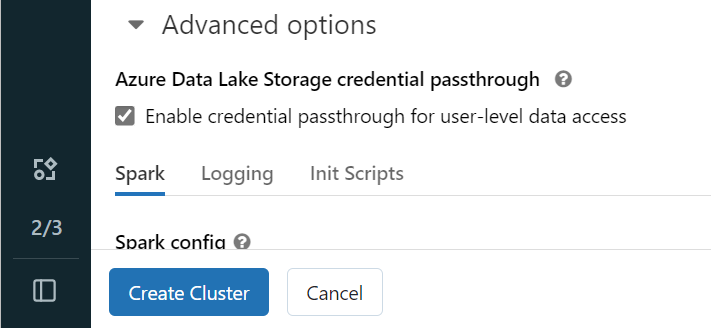
Aby uwierzytelnić się w usłudze OneLake przy użyciu tożsamości firmy Microsoft Entra, musisz włączyć przekazywanie poświadczeń usługi Azure Data Lake Storage (ADLS) w klastrze w opcjach zaawansowanych.
Uwaga
Możesz również połączyć usługę Databricks z usługą OneLake przy użyciu jednostki usługi. Aby uzyskać więcej informacji na temat uwierzytelniania usługi Azure Databricks przy użyciu jednostki usługi, zobacz Zarządzanie jednostkami usługi.
Utwórz klaster z preferowanymi parametrami. Aby uzyskać więcej informacji na temat tworzenia klastra usługi Databricks, zobacz Konfigurowanie klastrów — Azure Databricks.
Otwórz notes i połącz go z nowo utworzonym klastrem.
Tworzenie notesu
Przejdź do usługi Fabric lakehouse i skopiuj ścieżkę azure Blob Filesystem (ABFS) do usługi Lakehouse. Można go znaleźć w okienku Właściwości .
Uwaga
Usługa Azure Databricks obsługuje tylko sterownik azure Blob Filesystem (ABFS) podczas odczytywania i zapisywania w usługach ADLS Gen2 i OneLake:
abfss://myWorkspace@onelake.dfs.fabric.microsoft.com/.Zapisz ścieżkę do usługi Lakehouse w notesie usługi Databricks. W tym lakehouse zapisujesz przetworzone dane później:
oneLakePath = 'abfss://myWorkspace@onelake.dfs.fabric.microsoft.com/myLakehouse.lakehouse/Files/'Ładowanie danych z publicznego zestawu danych usługi Databricks do ramki danych. Możesz również odczytać plik z innego miejsca w sieci szkieletowej lub wybrać plik z innego konta usługi ADLS Gen2, którego już jesteś właścicielem.
yellowTaxiDF = spark.read.format("csv").option("header", "true").option("inferSchema", "true").load("/databricks-datasets/nyctaxi/tripdata/yellow/yellow_tripdata_2019-12.csv.gz")Filtrowanie, przekształcanie lub przygotowywanie danych. W tym scenariuszu możesz przyciąć zestaw danych w celu szybszego ładowania, dołączania do innych zestawów danych lub filtrowania do określonych wyników.
filteredTaxiDF = yellowTaxiDF.where(yellowTaxiDF.fare_amount<4).where(yellowTaxiDF.passenger_count==4) display(filteredTaxiDF)Zapisz przefiltrowaną ramkę danych w usłudze Fabric lakehouse przy użyciu ścieżki OneLake.
filteredTaxiDF.write.format("csv").option("header", "true").mode("overwrite").csv(oneLakePath)Przetestuj, czy dane zostały pomyślnie zapisane, odczytując nowo załadowany plik.
lakehouseRead = spark.read.format('csv').option("header", "true").load(oneLakePath) display(lakehouseRead.limit(10))
Gratulacje. Teraz możesz odczytywać i zapisywać dane w usłudze Fabric przy użyciu usługi Azure Databricks.