Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Przekształcenia konwertują nieprzetworzone pliki (CSV, Parquet i JSON) na tabele Delta, które zawsze pozostają zsynchronizowane z danymi źródłowymi. Przekształcenie jest wykonywane przez Fabric Spark compute, które kopiuje dane wskazane przez skrót OneLake do zarządzanej tabeli Delta, dzięki czemu nie musisz samodzielnie budować i orkiestracji tradycyjnych potoków ekstrakcji, przekształcania i ładowania (ETL). Dzięki automatycznej obsłudze schematów, możliwości głębokiego spłaszczania oraz obsłudze wielu formatów kompresji, uproszczenia w procesie przekształceń eliminują złożoność tworzenia i utrzymania potoków ETL.
Note
Przekształcenia skrótów są obecnie dostępne w publicznej wersji zapoznawczej i mogą ulec zmianie.
Dlaczego warto używać skrótów przekształceń?
- Brak ręcznych potoków — Fabric automatycznie kopiuje i konwertuje pliki źródłowe na Delta format; nie trzeba organizować ładunków przyrostowych.
- Częste odświeżanie – Fabric sprawdza skrót co 2 minuty i synchronizuje wszystkie zmiany niemal natychmiast.
- Otwarte i gotowe do analizy danych — dane wyjściowe to tabela Delta Lake, którą każdy silnik zgodny z Apache Spark może używać do zapytań.
- Ujednolicone zarządzanie — skrót dziedziczy pochodzenie OneLake, uprawnienia i zasady Microsoft Purview.
- Oparty na platformie Spark — przekształca kompilację na potrzeby skalowania.
Prerequisites
| Requirement | Details |
|---|---|
| Microsoft Fabric SKU | Pojemność lub wersja próbna obsługująca obciążenia Lakehouse. |
| Dane źródłowe | Folder zawierający homogeniczne pliki CSV, Parquet lub JSON. |
| Rola obszaru roboczego | Współautor lub wyższy. |
Obsługiwane źródła, formaty i miejsca docelowe
Obsługiwane są wszystkie źródła danych obsługiwane w usłudze OneLake.
| Format pliku źródłowego | Destynacja | Obsługiwane rozszerzenia | Obsługiwane typy kompresji | Notatki |
|---|---|---|---|---|
| CSV (UTF-8, UTF-16) | W folderze Lakehouse/Tables znajduje się tabela Delta Lake | .csv,.txt(oddzielony przecinkami),.tsv(oddzielony tabulatorami),.psv(oddzielony pionowymi kreskami) | .csv.gz,.csv.bz2 | .csv.zip,.csv.snappy nie są obsługiwane do chwili obecnej |
| Parquet | Tabela Delta Lake w folderze Lakehouse/Tables | .parkiet | .parquet.snappy,.parquet.gzip,.parquet.lz4,.parquet.brotli,.parquet.zstd | |
| JSON | Tabela Delta Lake w folderze Lakehouse/Tables | .json,.jsonl,.ndjson | .json.gz,.json.bz2,.jsonl.gz,.ndjson.gz,.jsonl.bz2,.ndjson.bz2 | .json.zip, .json.snappy nie są obsługiwane od pewnego momentu |
- Obsługa plików programu Excel jest częścią planu działania
- Przekształcenia bazujące na sztucznej inteligencji dostępne są do obsługi formatów plików bez struktury (.txt, .doc, .docx) w ramach zastosowania analizy tekstu, a zapowiedziano dalsze ulepszenia.
Skonfiguruj przekształcenie skrótu klawiaturowego
W Lakehouse wybierz Nowy skrót do tabeli w sekcji Tabele. Jest to transformacja skrótu (wersja zapoznawcza) i wybierz swoje źródło (na przykład Azure Data Lake, Azure Blob Storage, Dataverse, Amazon S3, GCP, SharePoint, OneDrive itp.).
Wybierz plik, Skonfiguruj skrót przekształcania i tworzenia — przejdź do istniejącego skrótu OneLake wskazującego folder z plikami CSV, skonfiguruj parametry i zainicjuj tworzenie.
- Ogranicznik w plikach CSV — wybierz znak używany do oddzielania kolumn (przecinek, średnik, pionowa kreska, tabulator, ampersand, spacja).
- Pierwszy wiersz jako nagłówki — wskazuje, czy pierwszy wiersz zawiera nazwy kolumn.
- Nazwa skrótu tabeli — podaj przyjazną nazwę; Fabric tworzy ją w /Tables.
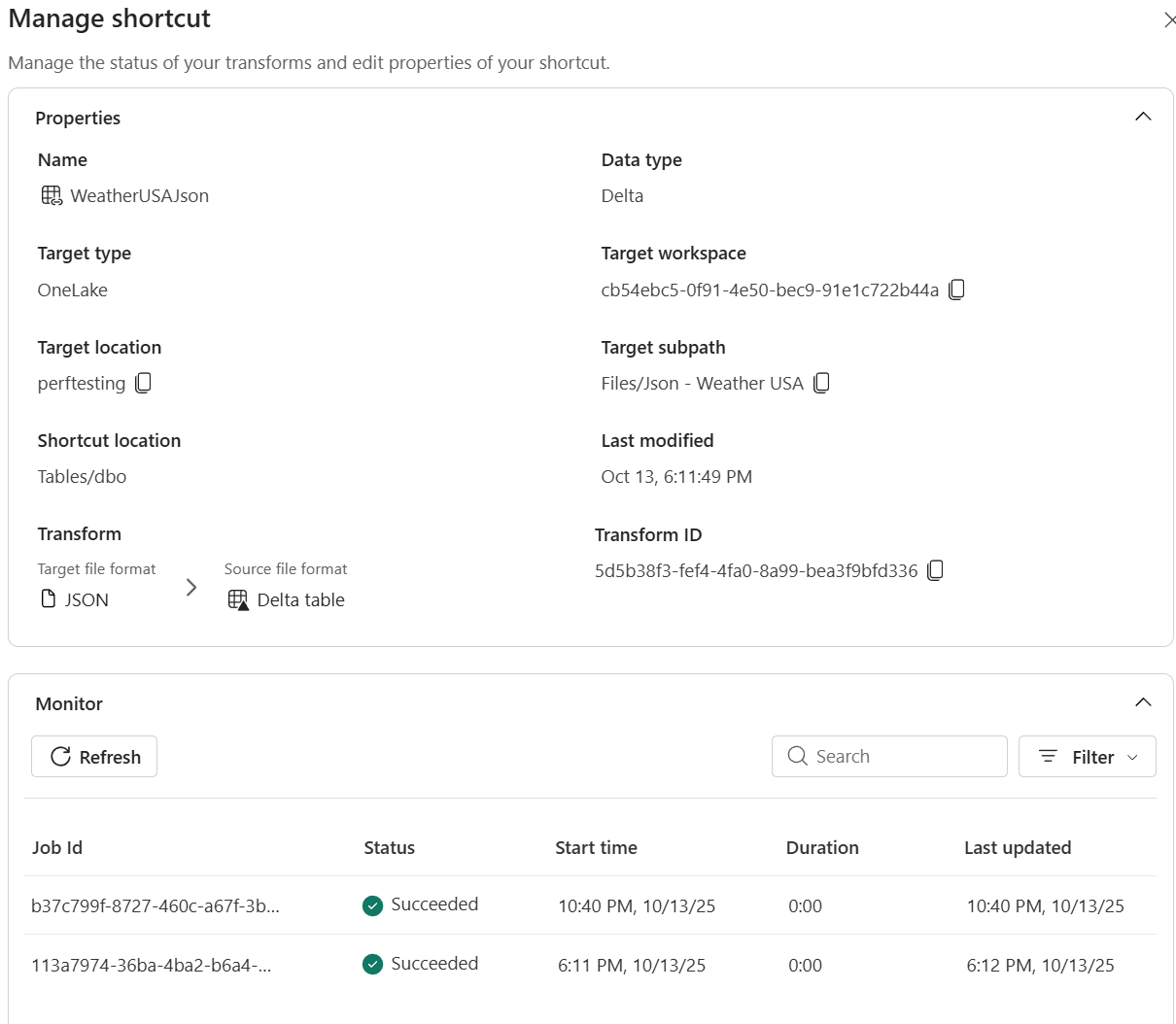
Śledź odświeżenia i wyświetlaj dzienniki dla przejrzystości w centrum zarządzania monitorowaniem skrótów.
Usługa Fabric Spark kopiuje dane do tabeli Delta i pokazuje postęp w okienku Zarządzanie skrótem. Transformacje skrótów są dostępne w elementach Lakehouse. Tworzą tabele Delta Lake w folderze Lakehouse/Tables.
Jak działa synchronizacja
Po początkowym ładowaniu, obliczenia Fabric Spark:
- Sprawdza cel skrótu co 2 minuty.
- Wykrywa nowe lub zmodyfikowane pliki oraz odpowiednio dołącza lub zastępuje wiersze.
- Wykrywa usunięte pliki i usuwa odpowiednie wiersze.
Monitorowanie i rozwiązywanie problemów
Przekształcenia skrótów obejmują monitorowanie oraz obsługę błędów, co umożliwia śledzenie statusu wczytywania danych i diagnozowanie problemów.
- Otwórz Lakehouse i kliknij prawym przyciskiem myszy skrót, który zasila twoją transformację.
- Wybierz pozycję Zarządzaj skrótem.
- W okienku szczegółów można wyświetlić:
- Stan — ostatni wynik skanowania i bieżący stan synchronizacji.
-
Historia odświeżania — chronologiczna lista operacji synchronizacji z liczbami wierszy i wszelkimi szczegółami błędów.
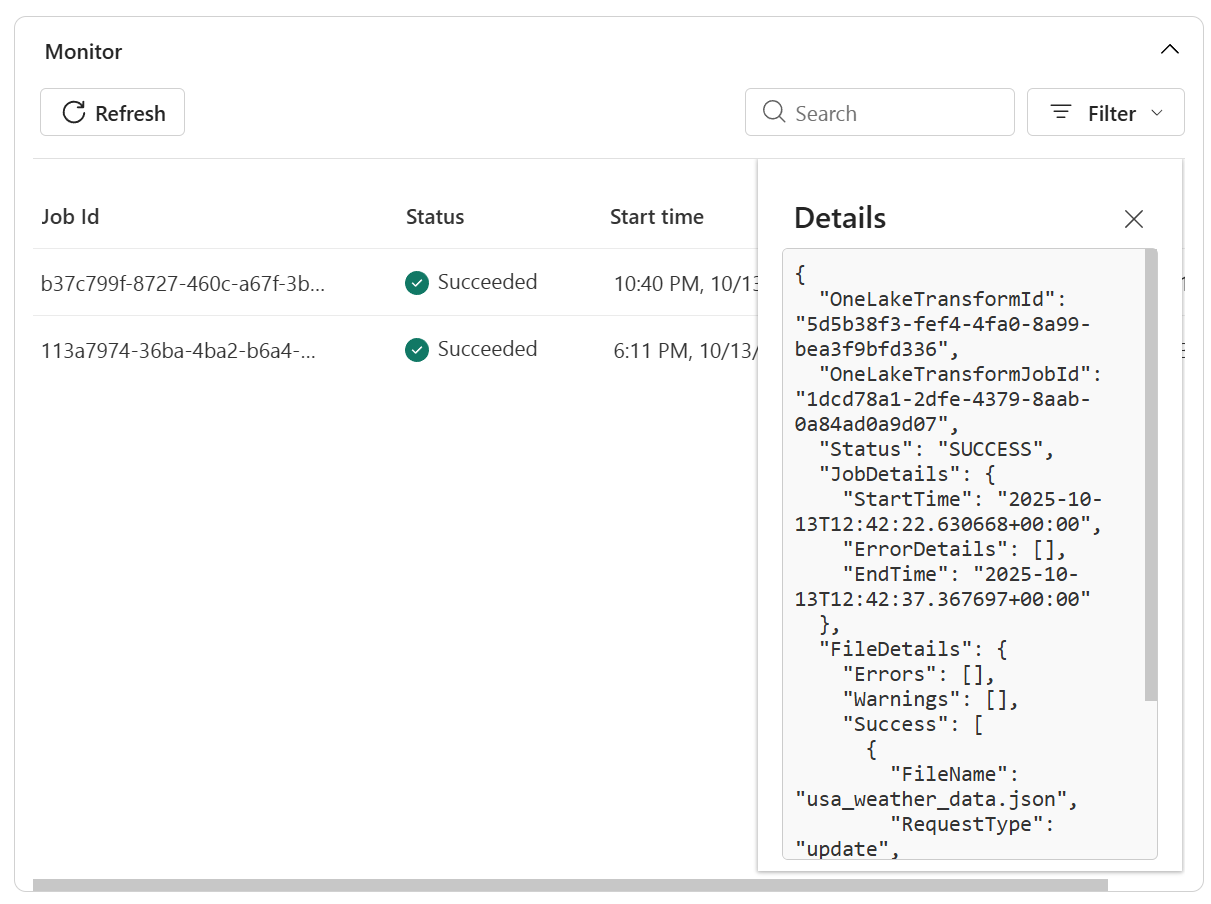
- Wyświetl więcej szczegółów w dziennikach, aby
Note
Wstrzymywanie lub usuwanie transformacji z tej karty to zbliżająca się część planu działania funkcji
Ograniczenia
Bieżące ograniczenia transformacji skrótów:
- Obsługiwane są tylko formaty plików CSV, Parquet i JSON .
- Pliki muszą współużytkować identyczny schemat; Dryf schematu nie jest jeszcze obsługiwany.
- Przekształcenia są zoptymalizowane pod kątem odczytu; Instrukcje MERGE INTO lub DELETE bezpośrednio w tabeli są blokowane.
- Dostępne tylko w elementach lakehouse (nie w magazynach lub bazach danych KQL).
- Nieobsługiwane typy danych dla woluminów CSV: Mieszane kolumny typu danych, Timestamp_Nanos, złożone typy logiczne — MAP/LIST/STRUCT, nieprzetworzone dane binarne
- Nieobsługiwany typ danych dla Parquet: Timestamp_nanos, Dziesiętne z INT32/INT64, INT96, Nieprzypisane typy całkowitoliczbowe — UINT_8/UINT_16/UINT_64, Złożone typy logiczne — MAP/LIST/STRUCT)
- Nieobsługiwane typy danych dla formatu JSON: Mieszane typy danych w tablicy, nieprzetworzone binarne obiekty blob w formacie JSON, Timestamp_Nanos
- Spłaszczanie typu danych tablicy w formacie JSON: Typ danych tablicy należy przechowywać w tabeli różnicowej, a dane są dostępne przy użyciu Spark SQL i Pyspark, gdzie w przypadku dalszych przekształceń materializowane widoki jeziora Fabric mogą być używane dla warstwy srebrnej
- Format źródłowy: Na dzień dzisiejszy obsługiwane są tylko pliki CSV, JSON i Parquet.
- Spłaszczanie głębokości w formacie JSON: struktury zagnieżdżone są spłaszczone do pięciu poziomów głębokości. Głębsze zagnieżdżanie wymaga wstępnego przetwarzania.
- Operacje zapisu: przekształcenia są zoptymalizowane pod kątem odczytu; Instrukcje direct MERGE INTO lub DELETE w tabeli docelowej przekształcenia nie są obsługiwane.
- Dostępność obszaru roboczego: dostępne tylko w elementach usługi Lakehouse (nie w magazynach danych lub bazach danych KQL).
- Spójność schematu pliku: Pliki muszą współużytkować identyczny schemat.
Note
Dodanie obsługi niektórych z powyższych oraz redukcja ograniczeń są częścią naszej mapy drogowej. Śledź nasze komunikaty dotyczące wersji, aby uzyskać bieżące aktualizacje.
Czyszczenie
Aby zatrzymać synchronizację, usuń przekształcenie skrótu z interfejsu użytkownika usługi Lakehouse.
Usunięcie przekształcenia nie powoduje usunięcia plików bazowych.