Przetwarzanie danych zdarzeń za pomocą edytora procesora zdarzeń
Edytor procesora zdarzeń to środowisko bez kodu, które umożliwia przeciąganie i upuszczanie w celu zaprojektowania logiki przetwarzania danych zdarzeń. W tym artykule opisano sposób projektowania logiki przetwarzania za pomocą edytora.
Uwaga
Jeśli chcesz użyć rozszerzonych możliwości dostępnych w wersji zapoznawczej, wybierz pozycję Rozszerzone możliwości u góry. W przeciwnym razie wybierz pozycję Możliwości standardowe. Aby uzyskać informacje o rozszerzonych możliwościach dostępnych w wersji zapoznawczej, zobacz Wprowadzenie do strumieni zdarzeń usługi Fabric.
Wymagania wstępne
Przed rozpoczęciem należy spełnić następujące wymagania wstępne:
- Uzyskaj dostęp do obszaru roboczego w warstwie Premium z uprawnieniami współautora lub wyższymi uprawnieniami, w których znajduje się strumień zdarzeń.
Ważne
Ulepszone możliwości strumieni zdarzeń sieci Szkieletowej są obecnie dostępne w wersji zapoznawczej.
Projektowanie przetwarzania zdarzeń za pomocą edytora
Aby wykonać operacje przetwarzania strumieniowego na strumieniach danych przy użyciu edytora bez kodu, wykonaj następujące kroki:
Wybierz pozycję Edytuj na wstążce, jeśli nie jesteś jeszcze w trybie edycji. Upewnij się, że węzeł nadrzędny dla połączonych operacji ma schemat.
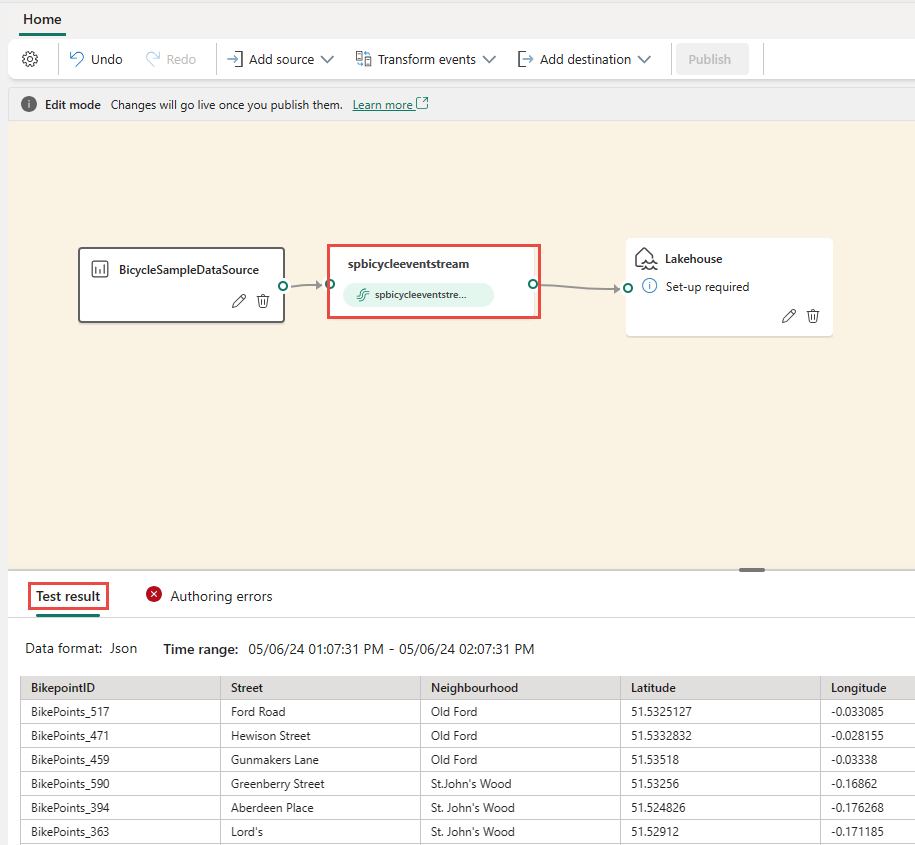
Aby wstawić operator przetwarzania zdarzeń między węzłem strumienia i miejscem docelowym w trybie edycji, można użyć jednej z następujących dwóch metod:
Wstaw operator bezpośrednio z wiersza połączenia. Zatrzymaj wskaźnik myszy na wierszu połączenia, a następnie wybierz + przycisk. Menu rozwijane jest wyświetlane w wierszu połączenia i można wybrać operator z tego menu.
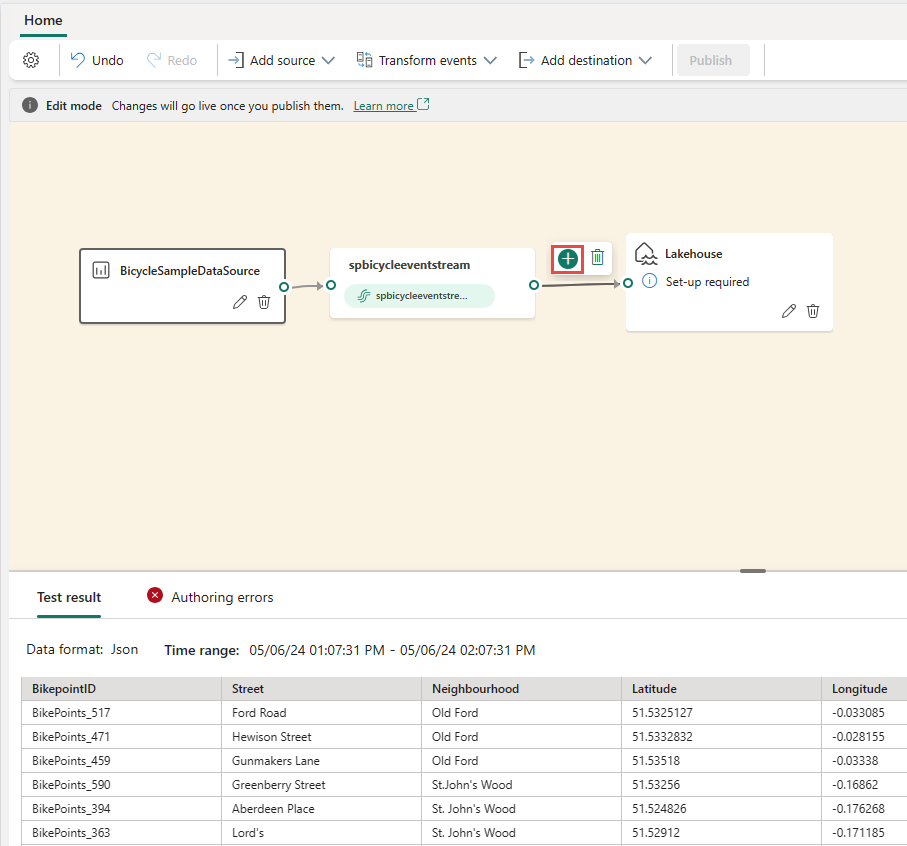
Wstaw operator z menu wstążki lub kanwy.
Możesz wybrać operator z menu Przekształć zdarzenia na wstążce.
Alternatywnie możesz umieścić kursor na jednym z węzłów, a następnie wybrać + przycisk, jeśli wiersz połączenia został usunięty. Obok tego węzła zostanie wyświetlone menu rozwijane i możesz wybrać operator z tego menu.

Po wstawieniu operatora należy ponownie połączyć te węzły. Umieść kursor na lewej krawędzi węzła strumienia, a następnie wybierz i przeciągnij zielony okrąg, aby połączyć go z węzłem operatora Zarządzaj polami . Wykonaj ten sam proces, aby połączyć węzeł operatora Zarządzaj polami z miejscem docelowym.

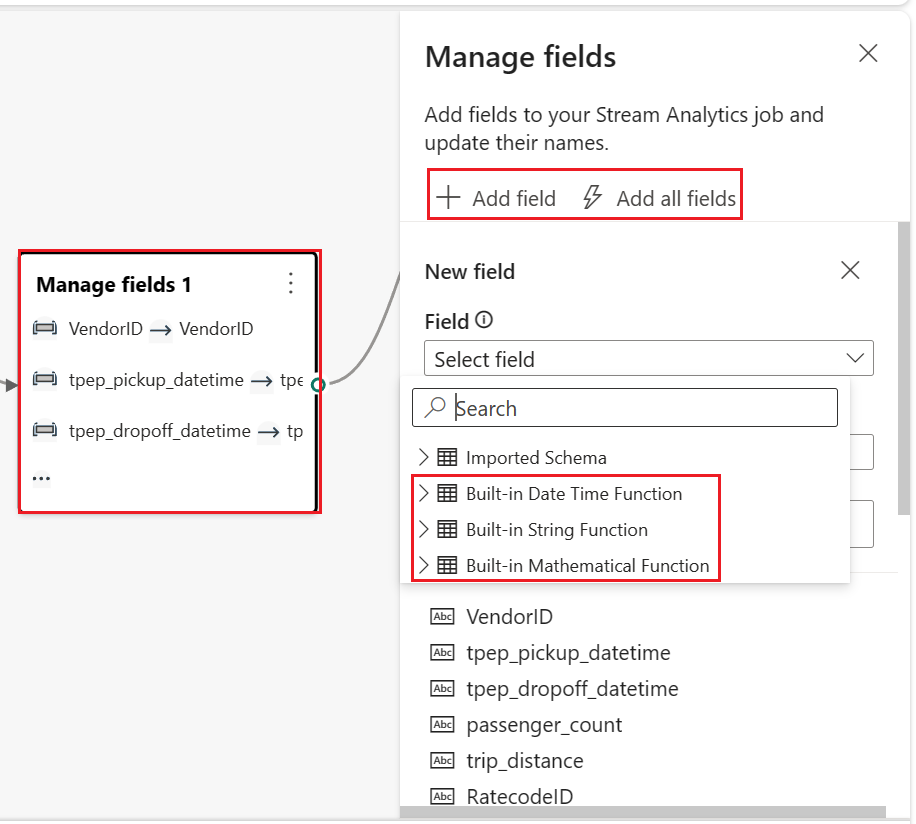
Wybierz węzeł Operator Zarządzaj polami. W panelu Zarządzanie polami wybierz pola, które chcesz wyświetlić. Jeśli chcesz dodać wszystkie pola, wybierz pozycję Dodaj wszystkie pola. Możesz również dodać nowe pole z wbudowanymi funkcjami, aby agregować dane z nadrzędnego strumienia. (Obecnie funkcje wbudowane, które obsługujemy, to niektóre funkcje w funkcjach ciągów, funkcjach daty i godziny, funkcjach matematycznych. Aby je znaleźć, wyszukaj ciąg
built-in.)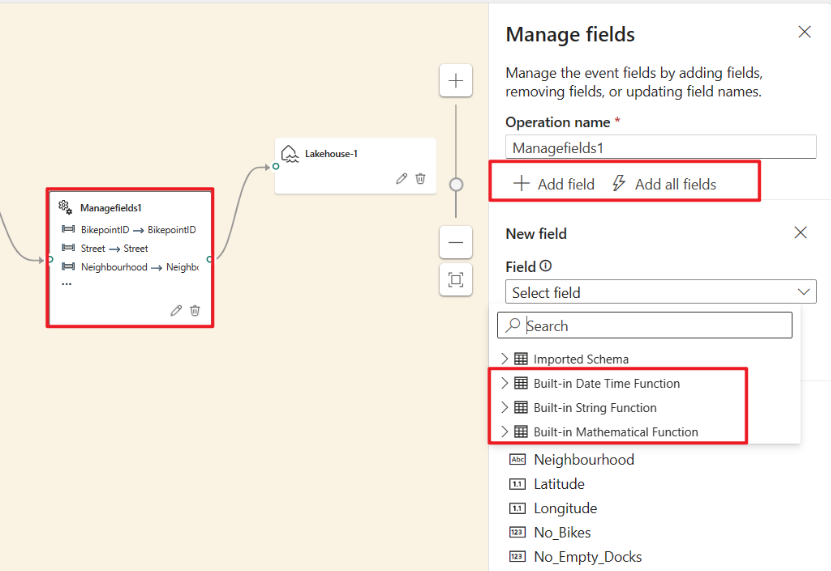
Po skonfigurowaniu operatora Zarządzanie polami wybierz pozycję Odśwież , aby zweryfikować wynik testu wygenerowany przez ten operator.

Jeśli występują błędy konfiguracji, są one wyświetlane na karcie Błędy tworzenia w dolnym okienku.
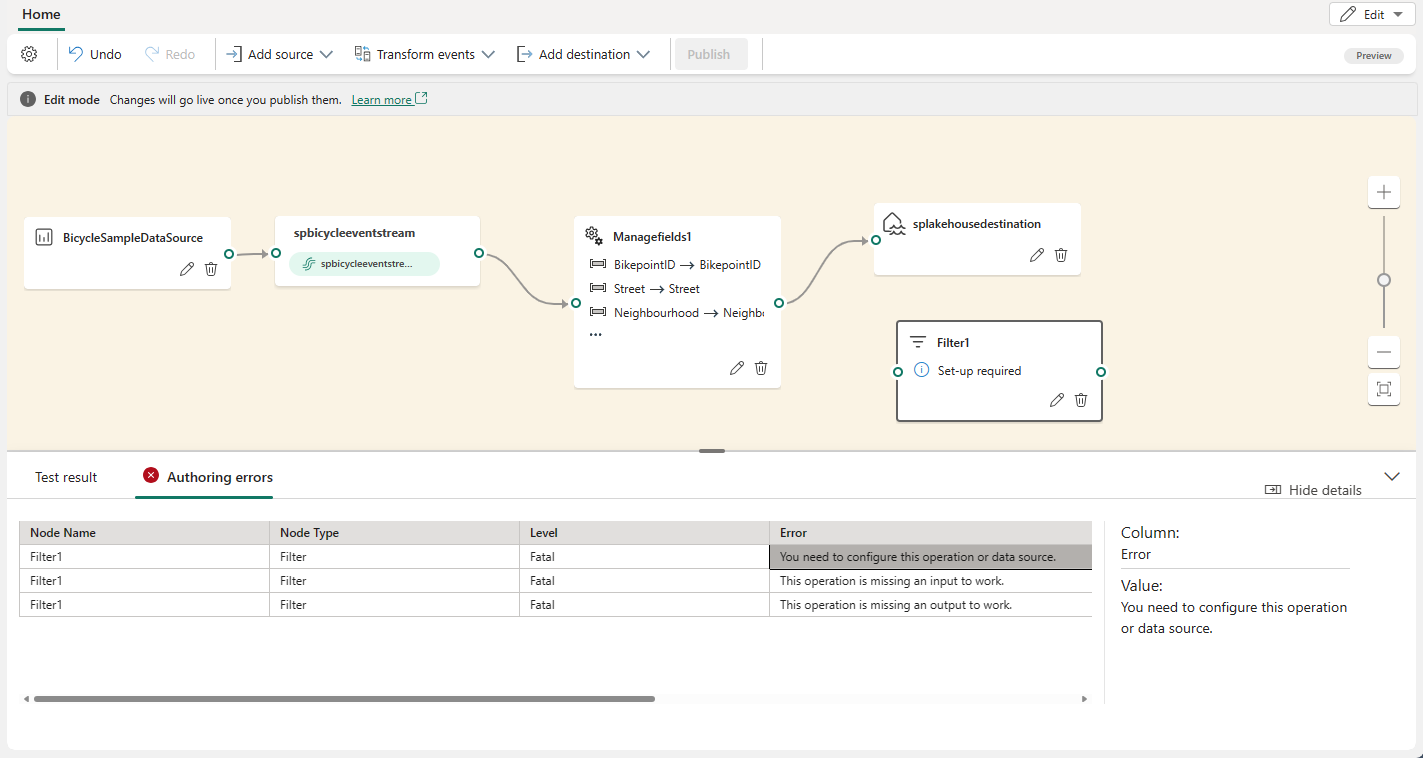
Jeśli wynik testu wygląda poprawnie, wybierz pozycję Publikuj , aby zapisać logikę przetwarzania zdarzeń i wrócić do widoku na żywo.
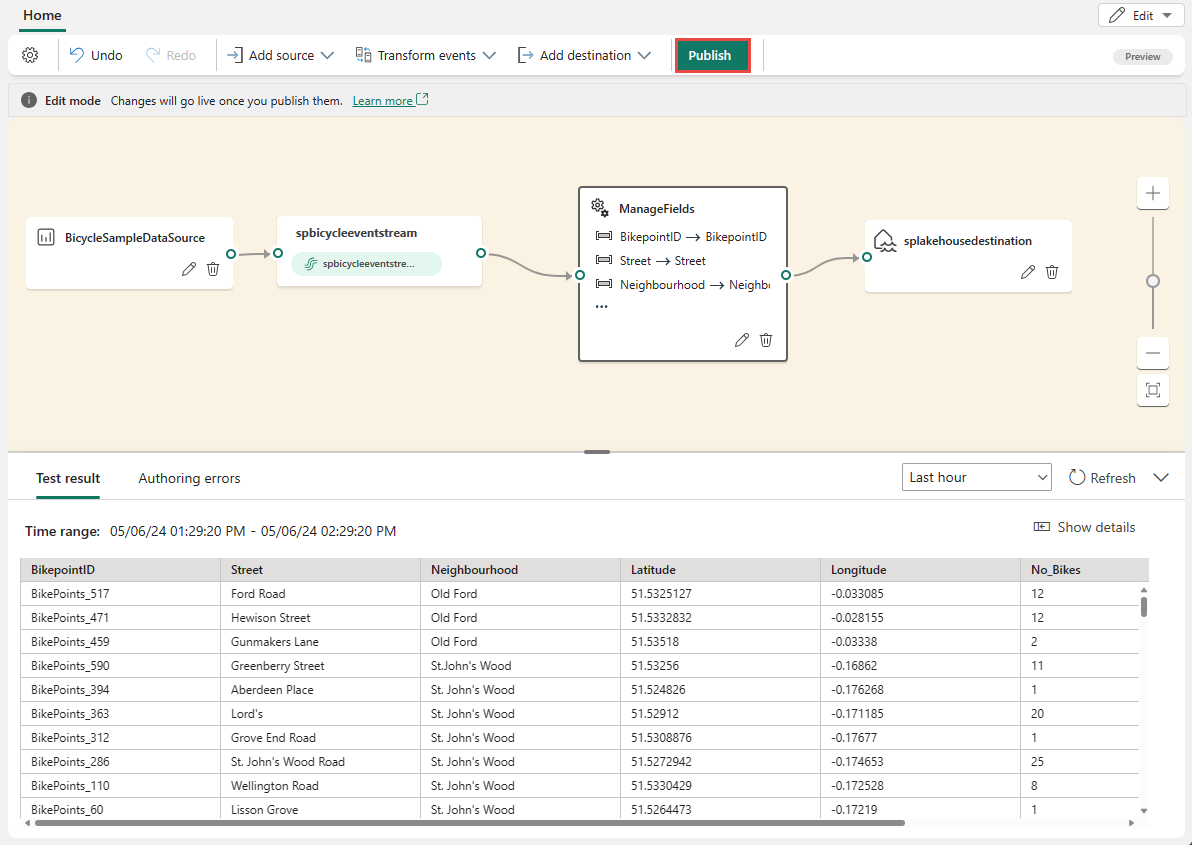
Po wykonaniu tych kroków możesz zwizualizować sposób rozpoczęcia przesyłania strumieniowego i przetwarzania danych strumienia zdarzeń w widoku na żywo.









Edytor przetwarzania zdarzeń
Edytor procesora zdarzeń (kanwa w trybie edycji) umożliwia przekształcanie danych w różne miejsca docelowe. Wprowadź tryb edycji, aby zaprojektować operacje przetwarzania strumienia dla strumieni danych.

Tryb edycji zawiera kanwę i dolne okienko, w którym można wykonywać następujące czynności:
- Skompiluj logikę przekształcania danych zdarzeń za pomocą przeciągania i upuszczania.
- Podgląd wyniku testu w każdym z węzłów przetwarzania od początku do końca.
- Odnajdź wszelkie błędy tworzenia w węzłach przetwarzania.
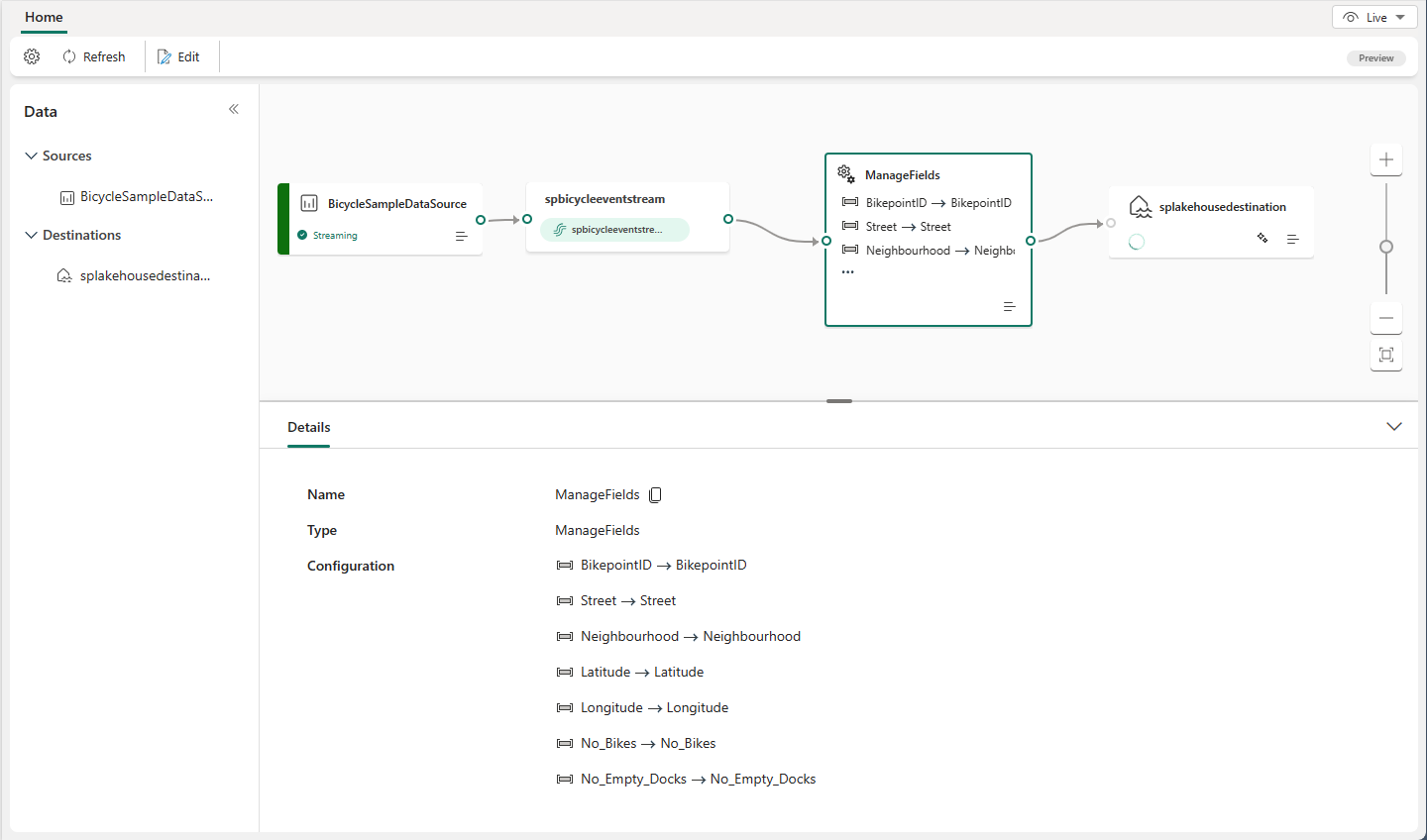
Układ edytora

- Menu wstążki i Kanwa (numerowane jeden na obrazie): W tym okienku możesz zaprojektować logikę przekształcania danych, wybierając operator (z menu Przekształć zdarzenia) i łącząc strumień i węzły docelowe za pośrednictwem nowo utworzonego węzła operatora. Możesz przeciągać i upuszczać linie łączące lub wybierać i usuwać połączenia.
- Okienko edycji po prawej stronie (dwa na obrazie): to okienko umożliwia skonfigurowanie wybranego węzła lub nazwy strumienia widoku.
- Dolne okienko z kartami podglądu danych i błędami tworzenia (trzy na obrazie): W tym okienku wyświetl podgląd wyniku testu w wybranym węźle z kartą Wynik testu. Karta Błędy tworzenia zawiera wszystkie niekompletne lub nieprawidłowe konfiguracje w węzłach operacji.
Obsługiwane typy węzłów i przykłady
Poniżej przedstawiono typy docelowe, które obsługują dodawanie operatorów przed pozyskiwaniem:
- Lakehouse
- Baza danych KQL (przetwarzanie zdarzeń przed pozyskiwaniem)
- Strumień pochodny
Uwaga
W przypadku miejsc docelowych, które nie obsługują dodawania operatora pozyskiwania wstępnego, możesz najpierw dodać strumień pochodny jako dane wyjściowe operatora. Następnie dołącz zamierzone miejsce docelowe do tego pochodnego strumienia.

Procesor zdarzeń w usłudze Lakehouse i bazie danych KQL (przetwarzanie zdarzeń przed pozyskiwaniem) umożliwia przetwarzanie danych przed ich pozyskaniem do miejsca docelowego.
Wymagania wstępne
Przed rozpoczęciem należy spełnić następujące wymagania wstępne:
- Uzyskaj dostęp do obszaru roboczego w warstwie Premium z uprawnieniami współautora lub wyższymi uprawnieniami, w których znajduje się strumień zdarzeń.
- Uzyskaj dostęp do obszaru roboczego w warstwie Premium z uprawnieniami współautora lub wyższymi uprawnieniami, w których znajduje się baza danych lakehouse lub KQL.
Projektowanie przetwarzania zdarzeń za pomocą edytora
Aby zaprojektować przetwarzanie zdarzeń za pomocą edytora procesora zdarzeń:
Dodaj lokalizację docelową usługi Lakehouse i wprowadź niezbędne parametry w okienku po prawej stronie. (Zobacz Dodaj lokalizację docelową w strumieniu zdarzeń i zarządzaj nią, aby uzyskać szczegółowe instrukcje. )
Wybierz pozycję Otwórz procesor zdarzeń. Zostanie wyświetlony ekran Edytor przetwarzania zdarzeń.
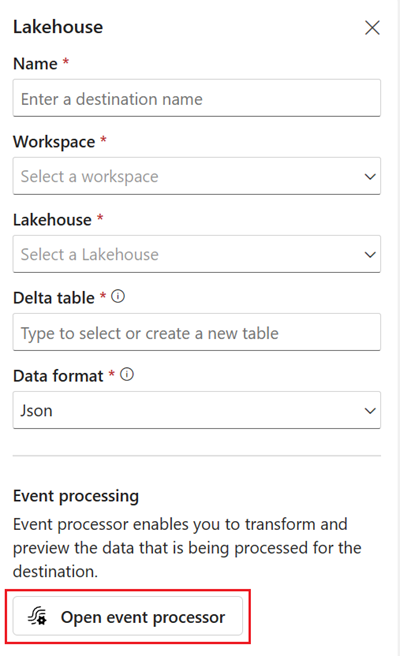
Na kanwie edytora przetwarzania zdarzeń wybierz węzeł eventstream. Możesz wyświetlić podgląd schematu danych lub zmienić typ danych w prawym okienku Strumienia zdarzeń .

Aby wstawić operator przetwarzania zdarzeń między tym strumieniem zdarzeń a miejscem docelowym w edytorze procesora zdarzeń, można użyć jednej z następujących dwóch metod:
Wstaw operator bezpośrednio z wiersza połączenia. Zatrzymaj wskaźnik myszy na wierszu połączenia, a następnie wybierz przycisk "+". Menu rozwijane jest wyświetlane w wierszu połączenia i można wybrać operator z tego menu.
Wstaw operator z menu wstążki lub kanwy.
Możesz wybrać operator z menu Operacje na wstążce. Alternatywnie możesz zatrzymać wskaźnik myszy na jednym z węzłów, a następnie wybrać przycisk "+", jeśli wiersz połączenia został usunięty. Obok tego węzła zostanie wyświetlone menu rozwijane i możesz wybrać operator z tego menu.
Na koniec należy ponownie połączyć te węzły. Umieść kursor na lewej krawędzi węzła strumienia zdarzeń, a następnie wybierz i przeciągnij zielony okrąg, aby połączyć go z węzłem operatora Zarządzaj polami . Postępuj zgodnie z tym samym procesem, aby połączyć węzeł operatora Zarządzaj polami z węzłem lakehouse.
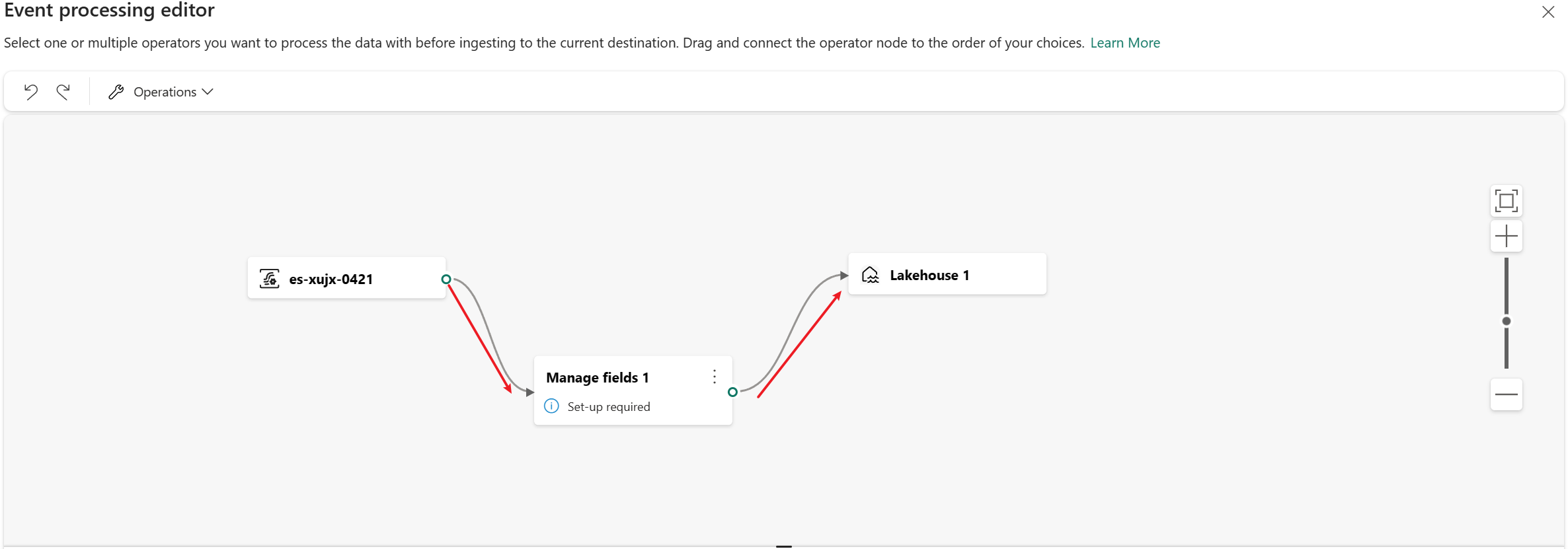
Wybierz węzeł Operator Zarządzaj polami. W panelu Zarządzanie polami wybierz pola, które chcesz wyświetlić. Jeśli chcesz dodać wszystkie pola, wybierz pozycję Dodaj wszystkie pola. Możesz również dodać nowe pole z wbudowanymi funkcjami, aby agregować dane z nadrzędnego strumienia. (Obecnie funkcje wbudowane, które obsługujemy, to niektóre funkcje w programie Funkcje ciągów, funkcje daty i godziny, funkcje matematyczne. Aby je znaleźć, wyszukaj frazę "wbudowane".
Po skonfigurowaniu operatora Zarządzanie polami wybierz pozycję Odśwież statyczną wersję zapoznawcza , aby wyświetlić podgląd danych generowanych przez tego operatora.
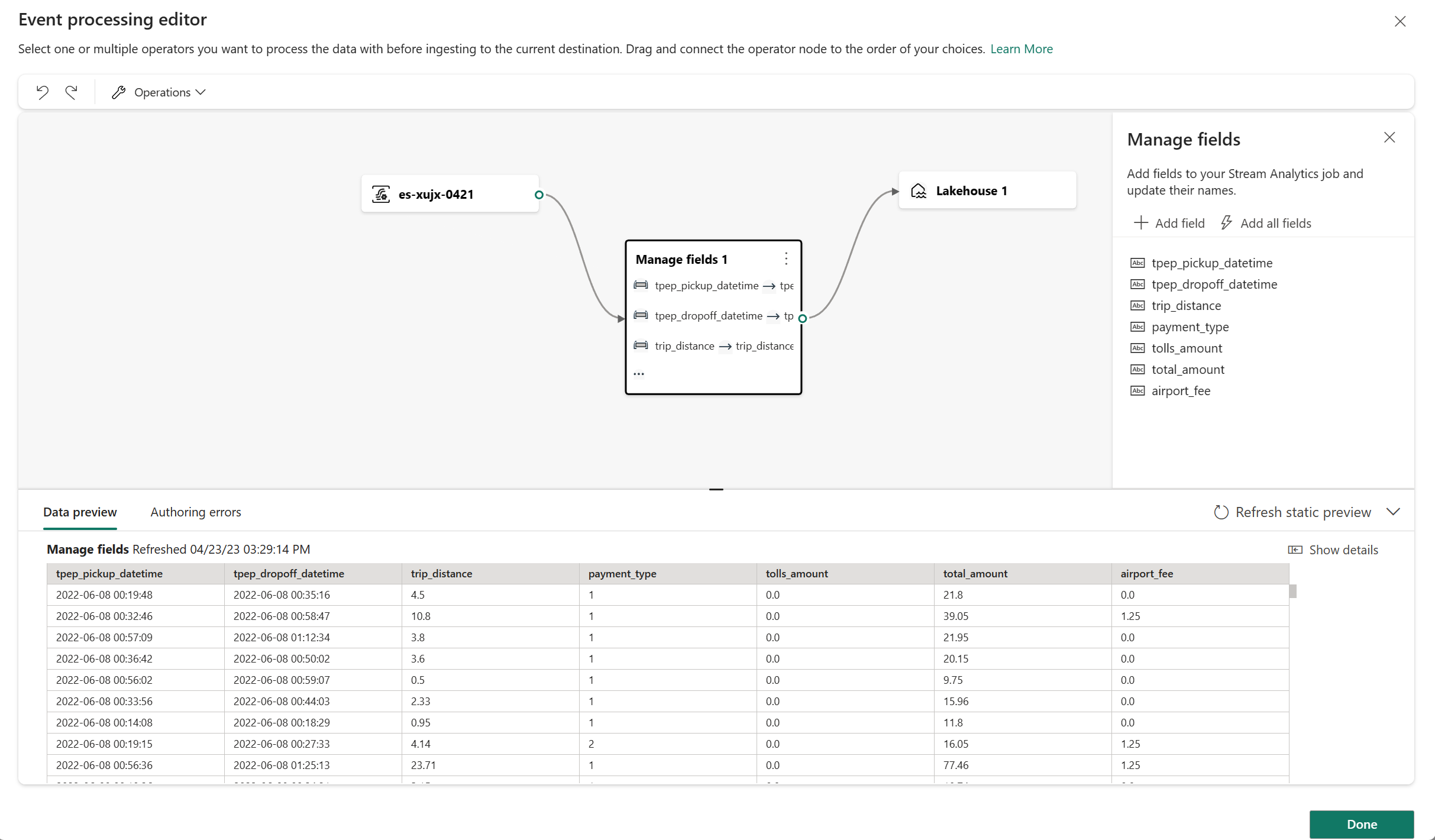
Jeśli występują błędy konfiguracji, są one wyświetlane na karcie Błąd tworzenia w dolnym okienku.
Jeśli podgląd danych wygląda poprawnie, wybierz pozycję Gotowe , aby zapisać logikę przetwarzania zdarzeń i wrócić do ekranu konfiguracji docelowej usługi Lakehouse.
Wybierz pozycję Dodaj , aby ukończyć tworzenie miejsca docelowego usługi Lakehouse.




Edytor procesora zdarzeń
Procesor zdarzeń umożliwia przekształcanie danych, które są pozyskiwane do miejsca docelowego usługi Lakehouse. Po skonfigurowaniu miejsca docelowego usługi Lakehouse opcja Otwórz procesor zdarzeń znajduje się w środku ekranu konfiguracji docelowej usługi Lakehouse.

Wybranie pozycji Otwórz procesor zdarzeń uruchamia ekran edytora przetwarzania zdarzeń, na którym można zdefiniować logikę przekształcania danych.
Edytor procesora zdarzeń zawiera kanwę i dolne okienko, w którym można:
- Skompiluj logikę przekształcania danych zdarzeń za pomocą przeciągania i upuszczania.
- Wyświetl podgląd danych w każdym z węzłów przetwarzania od początku do końca.
- Odnajdź wszelkie błędy tworzenia w węzłach przetwarzania.
Układ ekranu jest podobny do głównego edytora. Składa się z trzech sekcji pokazanych na poniższej ilustracji:

Kanwa z widokiem diagramu: w tym okienku możesz zaprojektować logikę przekształcania danych, wybierając operator (z menu Operacje ) i łącząc strumień zdarzeń i węzły docelowe za pośrednictwem nowo utworzonego węzła operatora. Możesz przeciągać i upuszczać linie łączące lub wybierać i usuwać połączenia.
Okienko edycji po prawej stronie: to okienko umożliwia skonfigurowanie wybranego węzła operacji lub wyświetlenie schematu strumienia zdarzeń i miejsca docelowego.
Dolne okienko z kartami podglądu danych i błędami tworzenia: w tym okienku wyświetl podgląd danych w wybranym węźle z kartą Podgląd danych. Karta Błędy tworzenia zawiera wszystkie niekompletne lub nieprawidłowe konfiguracje w węzłach operacji.
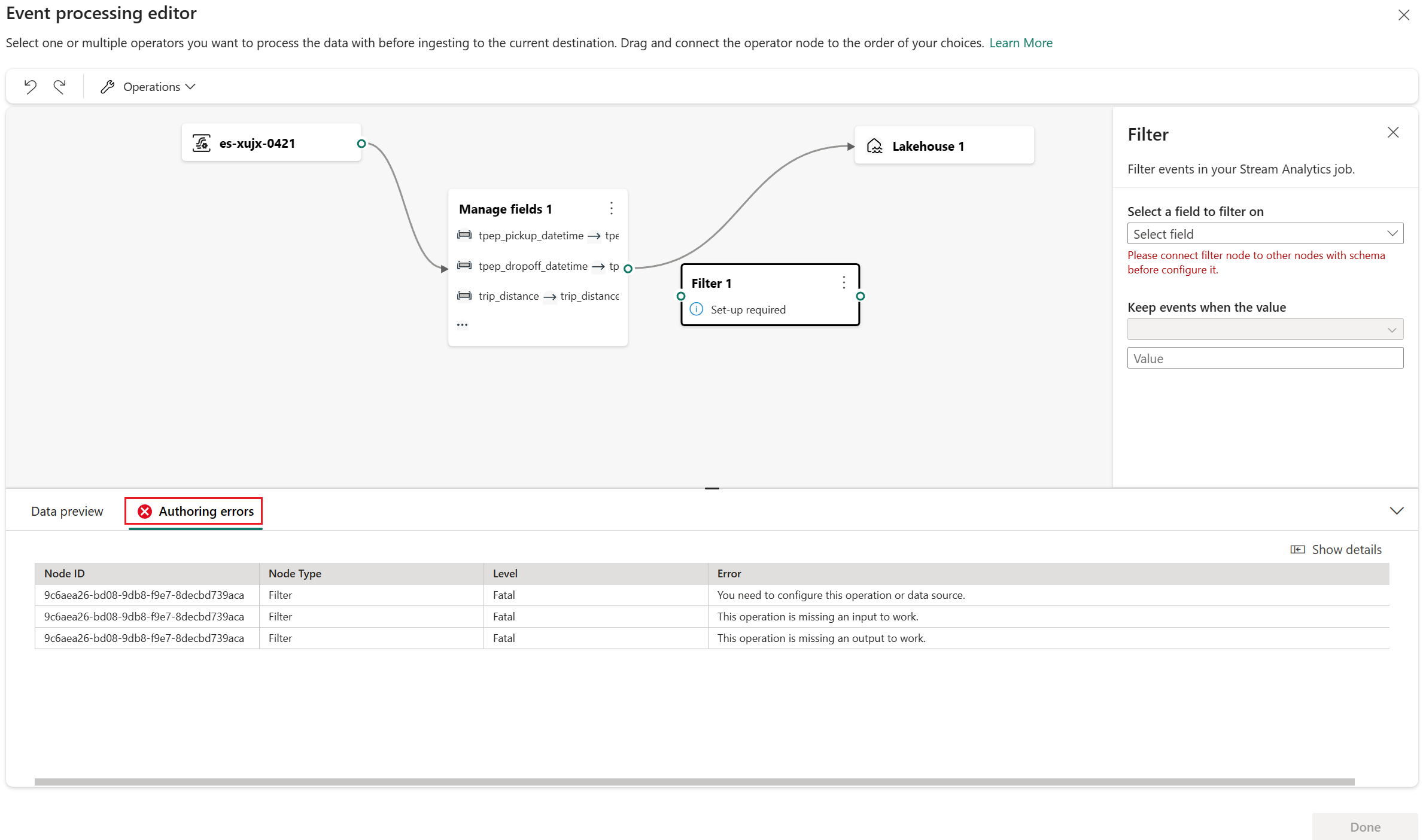
Błędy tworzenia
Błędy tworzenia odnoszą się do błędów występujących w edytorze procesora zdarzeń z powodu niekompletnej lub nieprawidłowej konfiguracji węzłów operacji, pomagając znaleźć i rozwiązać potencjalne problemy w procesorze zdarzeń.
Błędy tworzenia można wyświetlić w dolnym panelu edytora procesora zdarzeń. Na dolnym panelu wymieniono wszystkie błędy tworzenia. Każdy błąd tworzenia zawiera cztery kolumny:
- Identyfikator węzła: wskazuje identyfikator węzła operacji, w którym wystąpił błąd tworzenia.
- Typ węzła: wskazuje typ węzła operacji, w którym wystąpił błąd tworzenia.
- Poziom: wskazuje ważność błędu tworzenia, istnieją dwa poziomy: Krytyczny i Informacyjny. Błąd tworzenia na poziomie krytycznym oznacza, że procesor zdarzeń ma poważne problemy i nie można go zapisać ani uruchomić. Błąd tworzenia na poziomie informacji oznacza, że procesor zdarzeń zawiera wskazówki lub sugestie, które mogą pomóc w optymalizacji lub ulepszaniu procesora zdarzeń.
- Błąd: wskazuje konkretne informacje o błędzie tworzenia, krótko opisując przyczynę i wpływ błędu tworzenia. Możesz wybrać kartę Pokaż szczegóły , aby wyświetlić szczegóły.
Ponieważ usługa Eventstream i baza danych KQL obsługują różne typy danych, proces konwersji typu danych może generować błędy tworzenia.
W poniższej tabeli przedstawiono wyniki konwersji typu danych z eventstream do bazy danych KQL. Kolumny reprezentują typy danych obsługiwane przez strumień zdarzeń, a wiersze reprezentują typy danych obsługiwane przez bazę danych KQL. Komórki wskazują wyniki konwersji, które mogą być jednym z następujących trzech:
✔️ Wskazuje pomyślną konwersję, nie są generowane żadne błędy ani ostrzeżenia.
❌ Wskazuje niemożliwą konwersję, generowany jest błąd tworzenia krytycznego. Komunikat o błędzie jest podobny do: Typ danych "{1}" dla kolumny "{0}" nie jest zgodny z oczekiwanym typem "{2}" w wybranej tabeli KQL i nie można go automatycznie rozpoznać.
⚠✔ Wskazuje możliwą, ale niedokładną konwersję, generowany jest błąd tworzenia informacji. Komunikat o błędzie jest podobny do: Typ danych "{1}" dla kolumny "{0}" nie jest dokładnie zgodny z oczekiwanym typem "{2}" w wybranej tabeli KQL. Jest ona automatycznie przywracana do "{2}".
| string | bool | datetime | dynamiczna | Identyfikator GUID | int | długi | rzeczywiste | zakres czasu | decimal | |
|---|---|---|---|---|---|---|---|---|---|---|
| Int64 | ❌ | ❌ | ❌ | ✔️ | ❌ | ⚠️ | ✔️ | ⚠️ | ❌ | ✔️ |
| Podwójne | ❌ | ❌ | ❌ | ✔️ | ❌ | ❌ | ❌ | ⚠️ | ❌ | ⚠️ |
| ciąg | ✔️ | ❌ | ❌ | ✔️ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ |
| Data i godzina | ⚠️ | ❌ | ✔️ | ✔️ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ |
| Nagraj | ⚠️ | ❌ | ❌ | ✔️ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ |
| Tablica | ⚠️ | ❌ | ❌ | ✔️ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ |
Jak widać w tabeli, niektóre konwersje typów danych są pomyślne, takie jak ciąg do ciągu. Te konwersje nie generują żadnych błędów tworzenia i nie mają wpływu na działanie procesora zdarzeń.
Niektóre konwersje typów danych są niemożliwe, takie jak int do ciągu. Te konwersje generują błędy tworzenia na poziomie krytycznym, co powoduje niepowodzenie zapisywania procesora zdarzeń. Aby uniknąć tych błędów, musisz zmienić typ danych w strumieniu zdarzeń lub w tabeli KQL.
Niektóre konwersje typów danych są możliwe, ale nie są precyzyjne, takie jak int do rzeczywistego. Te konwersje generują błędy tworzenia na poziomie informacji, wskazujące niezgodność między typami danych i wyniki automatycznej konwersji. Te konwersje mogą spowodować utratę dokładności lub struktury danych. Możesz wybrać, czy zignorować te błędy, czy zmodyfikować typ danych w strumieniu zdarzeń lub w tabeli KQL, aby zoptymalizować procesor zdarzeń.
Operatory przekształcania
Procesor zdarzeń udostępnia sześć operatorów, których można użyć do przekształcania danych zdarzeń zgodnie z potrzebami biznesowymi.
Agregacja
Użyj przekształcenia Agregacja, aby obliczyć agregację (Suma, Minimum, Maksimum lub Średnia) za każdym razem, gdy nowe zdarzenie występuje w danym okresie. Ta operacja umożliwia również zmianę nazw tych kolumn obliczeniowych oraz filtrowanie lub fragmentowanie agregacji na podstawie innych wymiarów w danych. W tej samej transformacji można mieć co najmniej jedną agregację.
Rozwiń
Użyj przekształcenia Rozwiń tablicę, aby utworzyć nowy wiersz dla każdej wartości w tablicy.
Filtr
Użyj przekształcenia filtru, aby filtrować zdarzenia na podstawie wartości pola w danych wejściowych. W zależności od typu danych (liczby lub tekstu) przekształcenie zachowuje wartości zgodne z wybranym warunkiem, na przykład ma wartość null lub nie ma wartości null.
Grupuj według
Użyj przekształcenia Grupuj według , aby obliczyć agregacje we wszystkich zdarzeniach w określonym przedziale czasu. Można grupować według wartości w co najmniej jednym polu. Jest to podobne do przekształcenia Agregacja umożliwia zmianę nazw kolumn, ale udostępnia więcej opcji agregacji i zawiera bardziej złożone opcje dla okien czasowych. Podobnie jak agregacja, można dodać więcej niż jedną agregację na transformację.
Agregacje dostępne w transformacji to:
- Średnia
- Licznik
- Maksymalnie
- Minimum
- Percentyl (ciągły i dyskretny)
- Odchylenie standardowe
- Sum
- Wariancja
W scenariuszach przesyłania strumieniowego czasu wykonywanie operacji na danych zawartych w oknach czasowych jest typowym wzorcem. Procesor zdarzeń obsługuje funkcje okien, które są zintegrowane z operatorem Grupuj według . Można go zdefiniować w ustawieniu tego operatora.

Zarządzanie polami
Przekształcenie Zarządzaj polami umożliwia dodawanie, usuwanie, zmienianie typu danych lub zmienianie nazwy pól przychodzących z danych wejściowych lub innej transformacji. Ustawienia okienka bocznego umożliwiają dodawanie nowego pola, wybierając pozycję Dodaj pole, dodając wiele pól lub dodając jednocześnie wszystkie pola.
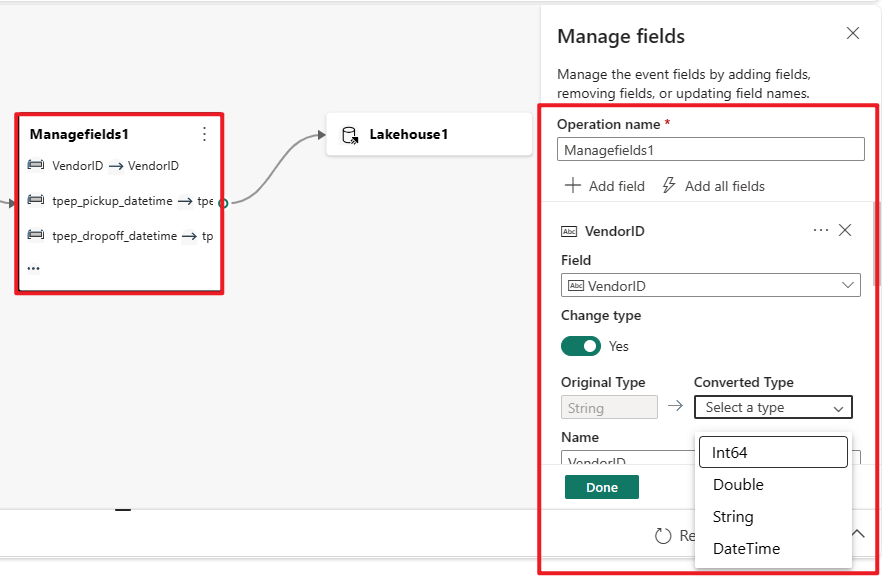
Ponadto można dodać nowe pole z wbudowanymi funkcjami, aby agregować dane z nadrzędnego strumienia. (Obecnie funkcje wbudowane, które obsługujemy, to niektóre funkcje w programie Funkcje ciągów, funkcje daty i godziny oraz funkcje matematyczne. Aby je znaleźć, wyszukaj frazę "wbudowane".
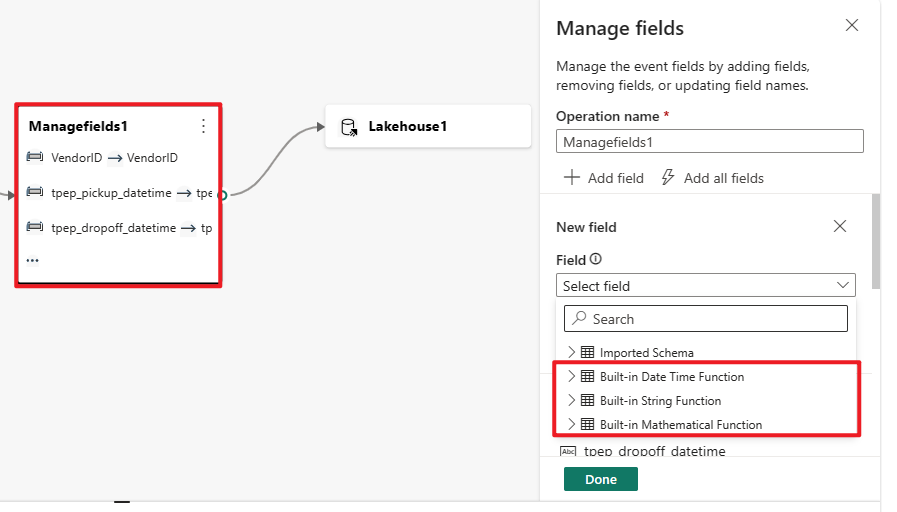
W poniższej tabeli przedstawiono wyniki zmiany typu danych przy użyciu pól zarządzania. Kolumny reprezentują oryginalne typy danych, a wiersze reprezentują docelowy typ danych.
- Jeśli znajduje się obiekt ✔️ w komórce, oznacza to, że można ją przekonwertować bezpośrednio, a docelowy typ danych jest wyświetlany na liście rozwijanej.
- Jeśli komórka znajduje ❌ się w komórce, oznacza to, że nie można jej przekonwertować, a docelowy typ danych nie jest wyświetlany na liście rozwijanej.
- Jeśli w komórce znajduje ⚠się element ✔ oznacza to, że można go przekonwertować, ale musi spełniać określone warunki, takie jak format ciągu musi być zgodny z wymaganiami docelowego typu danych. Na przykład podczas konwertowania z ciągu na int ciąg ciąg musi być prawidłową liczbą całkowitą, taką jak
123, a nieabc.
| Int64 | Liczba rzeczywista | String | Datetime | Nagraj | Tablica | |
|---|---|---|---|---|---|---|
| Int64 | ✔️ | ✔️ | ✔️ | ❌ | ❌ | ❌ |
| Podwójne | ✔️ | ✔️ | ✔️ | ❌ | ❌ | ❌ |
| ciąg | ⚠️ | ⚠️ | ✔️ | ⚠️ | ❌ | ❌ |
| Data i godzina | ❌ | ❌ | ✔️ | ✔️ | ❌ | ❌ |
| Nagraj | ❌ | ❌ | ✔️ | ❌ | ✔️ | ❌ |
| Tablica | ❌ | ❌ | ✔️ | ❌ | ❌ | ✔️ |
Unia
Użyj przekształcenia Unii, aby połączyć co najmniej dwa węzły i dodać zdarzenia współużytkowane pola (o tej samej nazwie i typie danych) do jednej tabeli. Pola, które nie są zgodne, są porzucane i nie są uwzględniane w danych wyjściowych.
Dołączanie
Użyj przekształcenia Join, aby połączyć zdarzenia z dwóch danych wejściowych na podstawie wybranych par pól. Jeśli nie wybierzesz pary pól, sprzężenia są domyślnie oparte na czasie. Wartością domyślną jest to, co sprawia, że ta transformacja różni się od tej wsadowej.
Podobnie jak w przypadku zwykłych sprzężeń, masz opcje logiki sprzężenia:
- Sprzężenie wewnętrzne: dołącz tylko rekordy z obu tabel, w których para jest zgodna.
- Lewe sprzężenia zewnętrzne: dołącz wszystkie rekordy z lewej (pierwszej) tabeli i tylko rekordy z drugiej, które pasują do pary pól. Jeśli nie ma dopasowania, pola z drugiego danych wejściowych są puste.