Kierowanie strumieni danych na podstawie zawartości w strumieniach zdarzeń usługi Fabric (wersja zapoznawcza)
W tym artykule przedstawiono sposób kierowania zdarzeń na podstawie zawartości w strumieniach zdarzeń usługi Microsoft Fabric.
Teraz możesz użyć edytora bez kodu na głównej kanwie strumieni zdarzeń sieci szkieletowej, aby utworzyć złożoną logikę przetwarzania strumieniowego bez konieczności pisania kodu. Ta funkcja umożliwia łatwiejsze dostosowywanie, przekształcanie i zarządzanie strumieniami danych. Po ustawieniu operacji przetwarzania strumienia można bezproblemowo wysyłać strumienie danych do różnych miejsc docelowych zgodnie z określonym schematem i danymi strumienia.
Ważne
Ulepszone możliwości strumieni zdarzeń sieci Szkieletowej są obecnie dostępne w wersji zapoznawczej.
Obsługiwane operacje
Oto lista operacji obsługiwanych w przypadku przetwarzania danych w czasie rzeczywistym:
Agregacja: obsługują funkcje SUM, AVG, MIN i MAX, które wykonują obliczenia w kolumnie wartości, zwracając pojedynczy wynik.
Rozwiń: rozwiń wartość tablicy i utwórz nowy wiersz dla każdej wartości w tablicy.
Filtr: wybierz lub przefiltruj określone wiersze ze strumienia danych na podstawie warunku.
Grupuj według: Agreguj wszystkie dane zdarzeń w określonym przedziale czasu z opcją grupowania co najmniej jednej kolumny.
Zarządzanie polami: dodawanie, usuwanie lub zmienianie typu danych pola lub kolumny strumieni danych.
Unia: Połączenie co najmniej dwa strumienie danych z udostępnionymi polami o tej samej nazwie i typie danych w jednym strumieniu danych. Pola, które nie są zgodne, są porzucane.
Sprzężenia: połącz dane z dwóch strumieni na podstawie zgodnego warunku między nimi.
Obsługiwane miejsca docelowe
Obsługiwane miejsca docelowe to:
Lakehouse: To miejsce docelowe zapewnia możliwość przekształcania zdarzeń w czasie rzeczywistym przed pozyskiwaniem do jeziora. Zdarzenia w czasie rzeczywistym są konwertowane na format usługi Delta Lake, a następnie przechowują je w wyznaczonych tabelach lakehouse. To miejsce docelowe pomaga w scenariuszach magazynowania danych.
Baza danych KQL: to miejsce docelowe umożliwia pozyskiwanie danych zdarzeń w czasie rzeczywistym do bazy danych KQL, gdzie można używać zaawansowanych język zapytań Kusto (KQL) do wykonywania zapytań i analizowania danych. Dzięki danym w bazie danych KQL możesz uzyskać bardziej szczegółowy wgląd w dane zdarzeń i tworzyć zaawansowane raporty i pulpity nawigacyjne.
Refleks: To miejsce docelowe umożliwia bezpośrednie połączenie danych zdarzeń w czasie rzeczywistym z refleksem. Refleks to rodzaj inteligentnego agenta, który zawiera wszystkie informacje niezbędne do nawiązania połączenia z danymi, monitorowania warunków i działania. Gdy dane osiągną określone progi lub pasują do innych wzorców, odruch automatycznie podejmuje odpowiednie działania, takie jak powiadamianie użytkowników lub rozpoczynanie przepływów pracy usługi Power Automate.
Niestandardowy punkt końcowy (była aplikacja niestandardowa): dzięki temu miejscu docelowemu można łatwo kierować zdarzenia w czasie rzeczywistym do aplikacji niestandardowej. To miejsce docelowe umożliwia łączenie własnych aplikacji z strumieniem zdarzeń i korzystanie z danych zdarzenia w czasie rzeczywistym. Jest to przydatne, gdy chcesz wychodzących danych w czasie rzeczywistym do systemu zewnętrznego poza usługą Microsoft Fabric.
Strumień: to miejsce docelowe reprezentuje domyślny nieprzetworzony strumień zdarzeń przekształcony przez serię operacji, nazywany również strumieniem pochodnym. Po utworzeniu możesz wyświetlić strumień z centrum czasu rzeczywistego.
W poniższym przykładzie pokazano, jak trzy odrębne miejsca docelowe strumienia zdarzeń usługi Fabric mogą obsługiwać oddzielne funkcje dla pojedynczego źródła strumienia danych. Jedna baza danych KQL jest przeznaczona do przechowywania danych pierwotnych, a druga baza danych KQL służy do przechowywania przefiltrowanych strumieni danych, a usługa Lakehouse służy do przechowywania zagregowanych wartości.
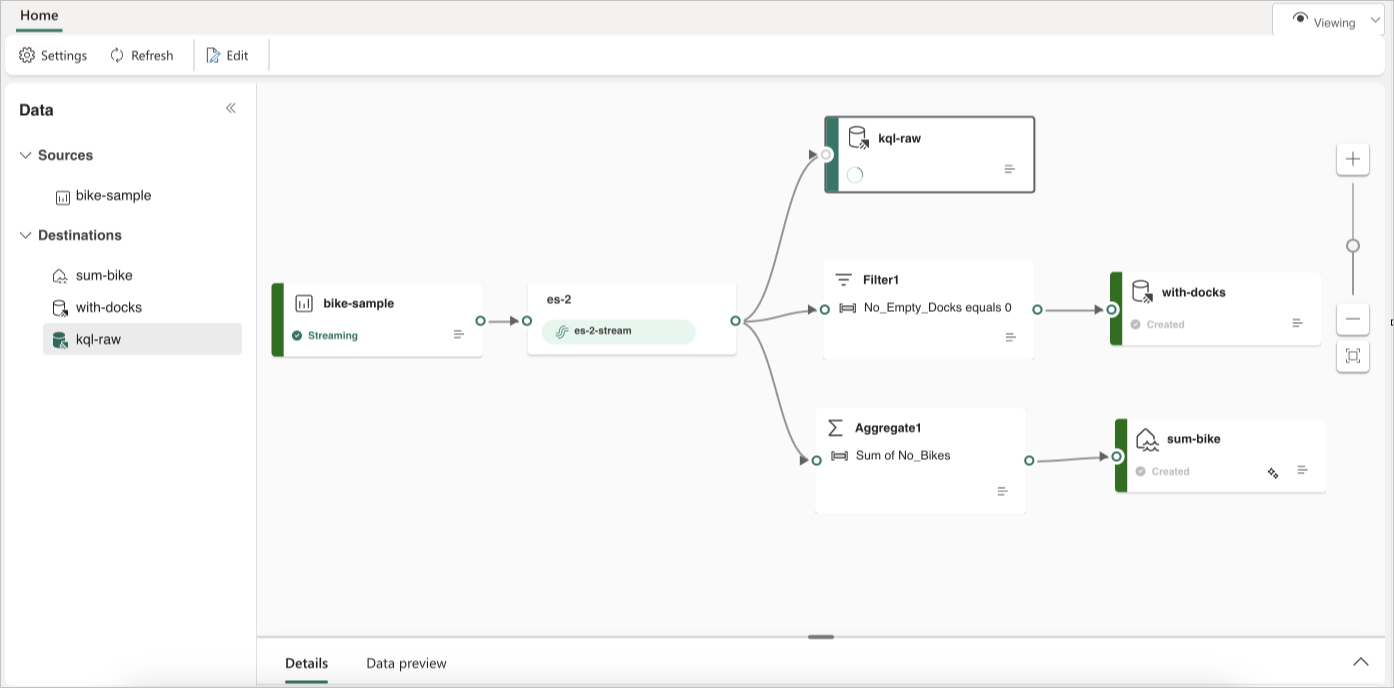
Aby przekształcić i skierować strumień danych na podstawie zawartości, wykonaj kroki opisane w temacie Edytowanie i publikowanie strumienia zdarzeń oraz rozpoczęcie projektowania logiki przetwarzania strumienia dla strumienia danych.
Powiązana zawartość
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla