Pobieranie danych z usługi Azure Storage
Z tego artykułu dowiesz się, jak pobrać dane z usługi Azure Storage (kontener usługi ADLS Gen2, kontener obiektów blob lub pojedynczych obiektów blob) do nowej lub istniejącej tabeli.
Wymagania wstępne
- Obszar roboczy z pojemnością z włączoną usługą Microsoft Fabric
- Baza danych KQL z uprawnieniami do edycji
- Konto magazynu
Źródło
Na dolnej wstążce bazy danych KQL wybierz pozycję Pobierz dane.
W oknie Pobieranie danych zostanie wybrana karta Źródło.
Wybierz źródło danych z listy dostępnych. W tym przykładzie pozyskiwane są dane z usługi Azure Storage.
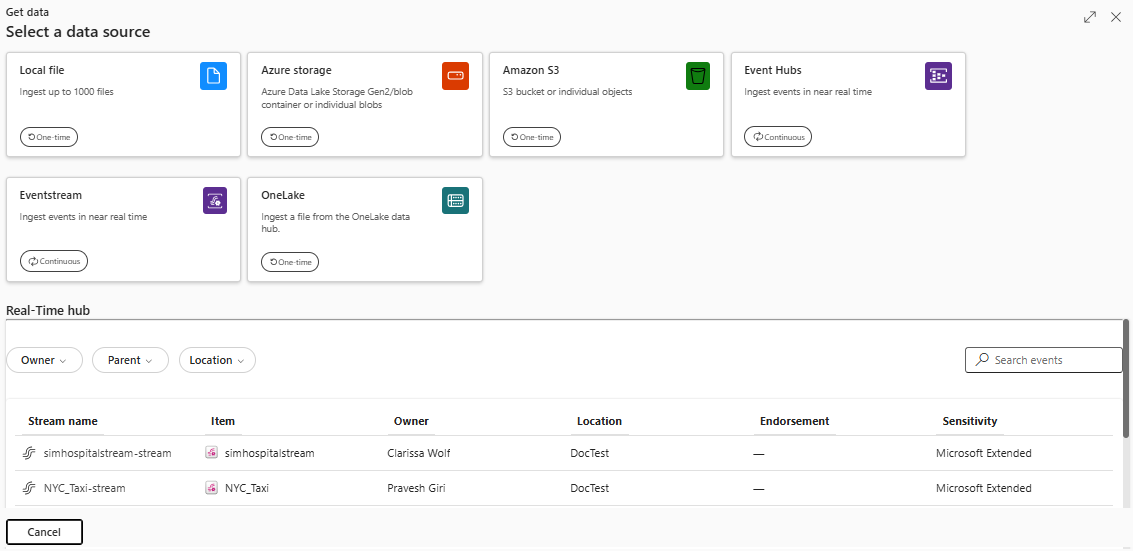

Konfiguruj
Wybierz tabelę docelową. Jeśli chcesz pozyskać dane do nowej tabeli, wybierz pozycję + Nowa tabela i wprowadź nazwę tabeli.
Uwaga
Nazwy tabel mogą zawierać maksymalnie 1024 znaki, w tym spacje, alfanumeryczne, łączniki i podkreślenia. Znaki specjalne nie są obsługiwane.
Aby dodać źródło danych, wklej parametry połączenia magazynu w polu identyfikatora URI, a następnie wybierz pozycję +. W poniższej tabeli wymieniono obsługiwane metody uwierzytelniania oraz uprawnienia wymagane do pozyskiwania danych z usługi Azure Storage.
Metoda uwierzytelniania Pojedynczy obiekt blob Kontener obiektów blob Azure Data Lake Storage Gen2 Token dostępu współdzielonego (SAS) Odczytywanie i zapisywanie Odczyt i lista Odczyt i lista Klucz dostępu do konta magazynu Uwaga
- Można dodać maksymalnie 10 pojedynczych obiektów blob lub pozyskać maksymalnie 5000 obiektów blob z jednego kontenera. Nie można pozyskiwać obu w tym samym czasie.
- Każdy obiekt blob może być maksymalnie 1 GB nieskompresowany.
Jeśli wklejono parametry połączenia dla kontenera obiektów blob lub usługi Azure Data Lake Storage Gen2, możesz dodać następujące opcjonalne filtry:

Ustawienie Opis pola Filtry plików (opcjonalnie) Folder path Filtruje dane w celu pozyskiwania plików przy użyciu określonej ścieżki folderu. Rozszerzenie pliku Filtruje dane do pozyskiwania plików tylko za pomocą określonego rozszerzenia pliku.
Wybierz Dalej

Kontrola
Karta Inspekcja zostanie otwarta z podglądem danych.
Aby ukończyć proces pozyskiwania, wybierz pozycję Zakończ.

Opcjonalnie:
- Wybierz pozycję Przeglądarka poleceń, aby wyświetlić i skopiować polecenia automatyczne wygenerowane na podstawie danych wejściowych.
- Użyj listy rozwijanej Plik definicji schematu, aby zmienić plik, z którego jest wywnioskowany schemat.
- Zmień automatycznie wnioskowany format danych, wybierając żądany format z listy rozwijanej. Aby uzyskać więcej informacji, zobacz Formaty danych obsługiwane przez analizę w czasie rzeczywistym.
- Edytuj kolumny.
- Zapoznaj się z opcjami zaawansowanymi na podstawie typu danych.
Edytuj kolumny
Uwaga
- W przypadku formatów tabelarycznych (CSV, TSV, PSV) nie można dwukrotnie mapować kolumny. Aby zamapować na istniejącą kolumnę, najpierw usuń nową kolumnę.
- Nie można zmienić istniejącego typu kolumny. Jeśli spróbujesz mapować kolumnę na inny format, może się okazać, że kolumny będą puste.
Zmiany, które można wprowadzić w tabeli, zależą od następujących parametrów:
- Typ tabeli jest nowy lub istniejący
- Typ mapowania to nowy lub istniejący
| Typ tabeli | Typ mapowania | Dostępne korekty |
|---|---|---|
| Nowa tabela | Nowe mapowanie | Zmienianie nazwy kolumny, zmienianie typu danych, zmienianie źródła danych, przekształcanie mapowania, dodawanie kolumny, usuwanie kolumny |
| Istniejąca tabela | Nowe mapowanie | Dodaj kolumnę (na której można następnie zmienić typ danych, zmienić nazwę i zaktualizować) |
| Istniejąca tabela | Istniejące mapowanie | Brak |

Przekształcenia mapowania
Niektóre mapowania formatów danych (Parquet, JSON i Avro) obsługują proste przekształcenia czasu pozyskiwania. Aby zastosować przekształcenia mapowania, utwórz lub zaktualizuj kolumnę w oknie Edytowanie kolumn .
Przekształcenia mapowania można wykonać na kolumnie typu ciąg lub data/godzina, a źródło ma typ danych int lub long. Obsługiwane przekształcenia mapowania to:
- DateTimeFromUnixSeconds
- DateTimeFromUnixMilliseconds
- DateTimeFromUnixMicroseconds
- DateTimeFromUnixNanoseconds
Opcje zaawansowane oparte na typie danych
Tabelaryczny (CSV, TSV, PSV):
Jeśli pozyskujesz formaty tabelaryczne w istniejącej tabeli, możesz wybrać pozycję Zaawansowane>zachowaj schemat tabeli. Dane tabelaryczne nie muszą zawierać nazw kolumn używanych do mapowania danych źródłowych na istniejące kolumny. Po zaznaczeniu tej opcji mapowanie odbywa się według kolejności, a schemat tabeli pozostaje taki sam. Jeśli ta opcja nie jest zaznaczona, nowe kolumny są tworzone dla danych przychodzących, niezależnie od struktury danych.
Aby użyć pierwszego wiersza jako nazw kolumn, wybierz pozycję Zaawansowane>pierwszy wiersz to nagłówek kolumny.
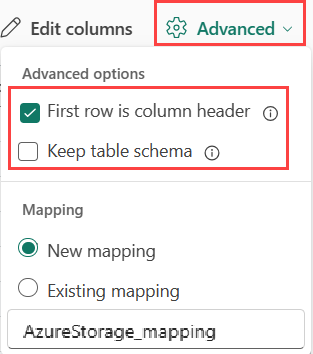
JSON:
Aby określić podział kolumn danych JSON, wybierz pozycję Zaawansowane>poziomy zagnieżdżone z zakresu od 1 do 100.
W przypadku wybrania opcji Zaawansowane>pomiń wiersze JSON z błędami dane są pozyskiwane w formacie JSON. Jeśli to pole wyboru nie zostanie zaznaczone, dane są pozyskiwane w formacie wielossonowym.
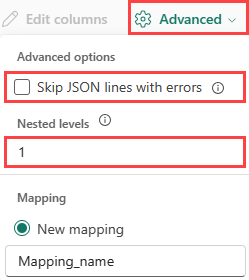
Podsumowanie
W oknie Przygotowywanie danych wszystkie trzy kroki są oznaczone zielonymi znacznikami wyboru po pomyślnym zakończeniu pozyskiwania danych. Możesz wybrać kartę, aby wykonać zapytanie, usunąć pozyskane dane lub wyświetlić pulpit nawigacyjny podsumowania pozyskiwania.

Powiązana zawartość
- Aby zarządzać bazą danych, zobacz Zarządzanie danymi
- Aby tworzyć, przechowywać i eksportować zapytania, zobacz Query data in a KQL queryset (Wykonywanie zapytań w zestawie zapytań języka KQL)
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla