Rozszerzanie rozwiązania Smart Store Analytics
Zaawansowani użytkownicy Smart Store Analytics mogą uzyskiwać dostęp do odpowiednich danych i analiz z poziomu własnego magazynu data lake. Dostęp może być oferowany za pośrednictwem innych usług lub aplikacji, które obsługują definicje Microsoft Azure Data Lake Storage i Common Data Model, na przykład Microsoft Azure Synapse Analytics, Microsoft Azure Data Factory lub Microsoft Power BI.
Ważne
Należy użyć serwera Microsoft Azure Data Lake Storage Gen2, ponieważ witryna Microsoft Azure Data Lake Storage będzie niezgodna.
Model danych Smart Store Analytics jest zgodny z szablonami bazy danych Azure Synapse dla handlu detalicznego , jest wzbogacony o specyfikę Smart Store Analytics i upraszcza połączenie innych aplikacji z lake data.
Struktura Smart Store Analytics data lake
Data lake Smart Store Analytics postępuje zgodnie z definicją Common Data Model (metadane Common Data Model).
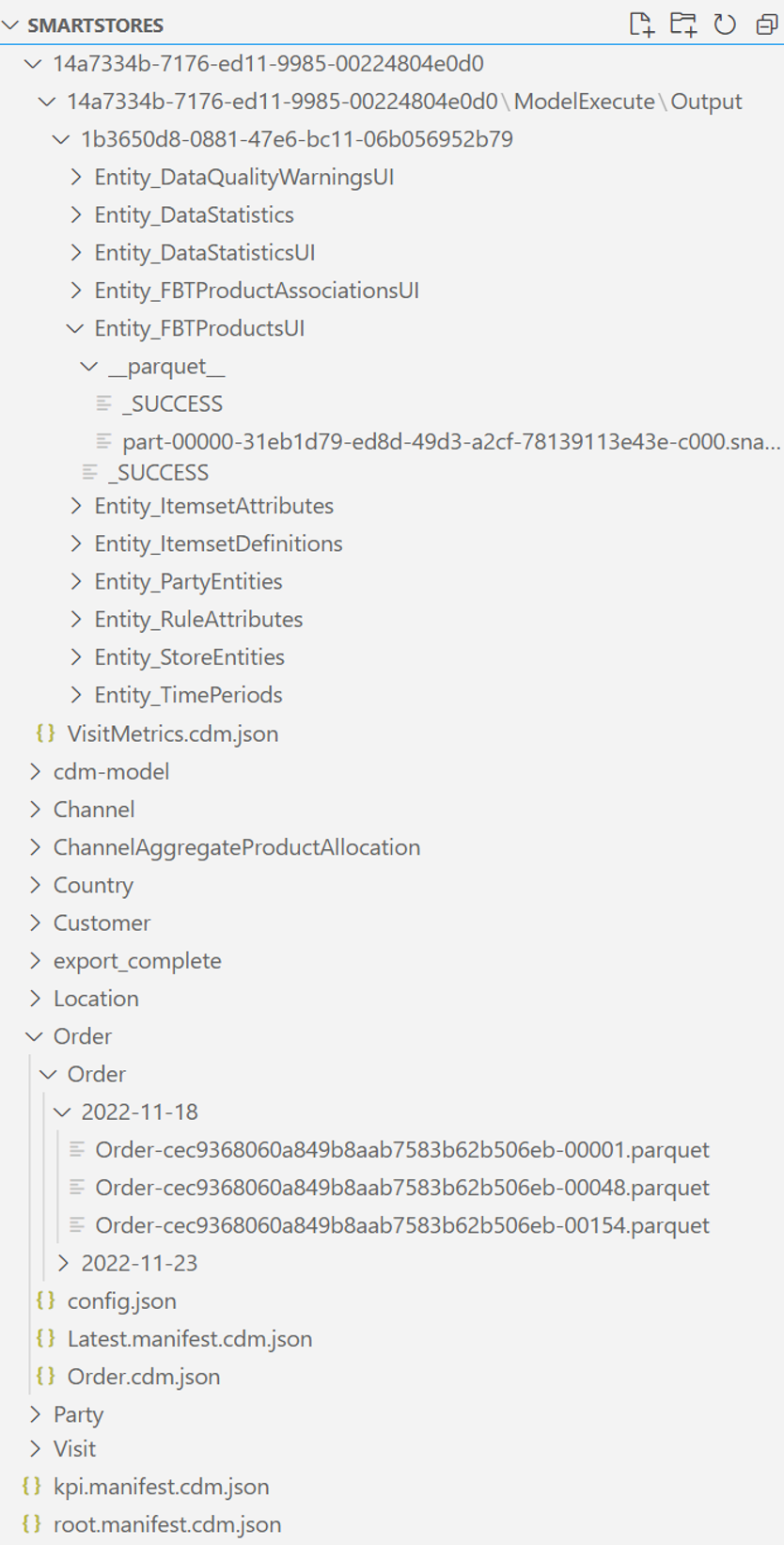
Folder główny o nazwie smartstores/. W folderze głównym znajdują się dwie migawki danych:
Dane przekształcine od dostawcy magazynu inteligentnego (nieprzetworzone dane magazynu inteligentnego)
Główny manifest Common Data Model dla nieprzetworzonych danych to root.manifest.cdm.json. Plik manifestu odnosi się na przykład do plików schematu i rzeczywistych plików danych znajdujących się w podfolderach (nazwanych tak od tabel) smartstores/Order/.
Podfolder każdej tabeli zawiera:
plik schematu, który definiuje metadane tabeli, kolumny i typy w formacie table-name.cdm.json , na przykład Order.cdm.json
Pliki danych, znane również jako partycje danych lub rekordy tabel, w formacie parquet, na przykład Order-cec9368060a849b8aab7583b62b506eb-00001.parquet
Dane generowane przez moduły Retail Analytical i AI z nieprzetworzonych danych inteligentnego sklepu
Wszystkie wygenerowane dane znajdują się w folderze o nazwie GUID, na przykład smartstores/14a7334b-7176-ed11-9985-00224804e0d0/. Główny manifest Common Data Model dla nieprzetworzonych danych to kpi.manifest.cdm.json. Plik manifestu odnosi się do plików schematu i rzeczywistych plików danych znajdujących się w folderze o nazwie GUID.
Folder o nazwie GUID zawiera:
Plik schematu dla każdej tabeli, który definiuje metadane tabeli, kolumny i typy, w formacie table-name.cdm.json na przykład, OrderMetrics.cdm.json
Pliki danych, znane również jako partycje danych lub rekordy tabel, w formacie parquet, na przykład part-00000-1e110bf0-6474-400b-b40a-086fce9f8e2a-c000.snappy.parquet
Ważne
Zgodnie z kontraktem metadanych common data model, użytkownicy potrzebują danych tylko z plików manifest.cdm.json . Nie muszą zinterpretować struktury folderów ani innych plików wewnętrznych obecnych w danych.
Wykorzystanie Smart Store Analytics data lake
Poniżej przedstawiono kilka przykładów danych synchronizowanych z analizy/analizą AI wygenerowanych przez Microsoft Cloud for Retail.
Potok danych z Microsoft Azure Data Factory
Aby utworzyć potok danych:
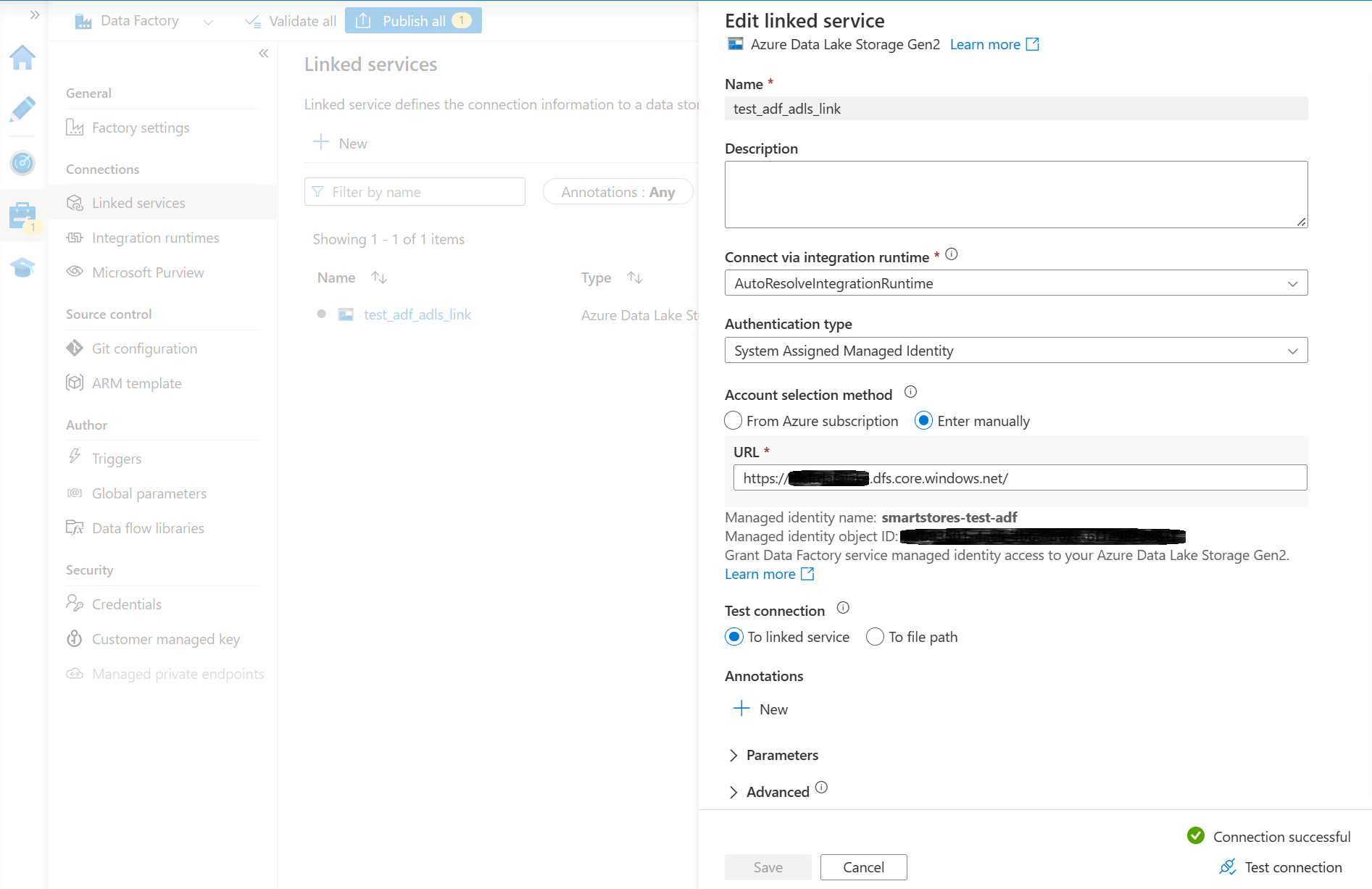
- Utwórz instancję usługi Azure Data Factory i połącz ją z magazynem Data Lake usługi Smart Store Analytics. Powinna zostać powiązana usługa z udanym testem połączenia.
Uwaga
Najprostszym sposobem połączenia wystąpienia Azure Data Factory Azure z Azure Data Lake Storage do jest przypisanie roli zabezpieczeń współautor do tożsamości zarządzanej Azure Data Factory w ramach konta Azure Data Lake Storage. Szczegółowe informacje można znaleźć w dokumentacji Azure Data Factory.
- Wybierz Publikuj wszystko, aby opublikować nowe łącze.
Utwórz potok danych za pomocą Microsoft Azure Data Factory
Aby utworzyć potok kopiowania dla folderu smartstores/ jako źródło, wykonaj następujące czynności:
- W sekcji Autor wybierz pozycję Nowy przepływ danych, aby utworzyć nowy przepływ danych.
- Rozpocznij debugowanie, aby szybciej sprawdzić konfigurację potoku.
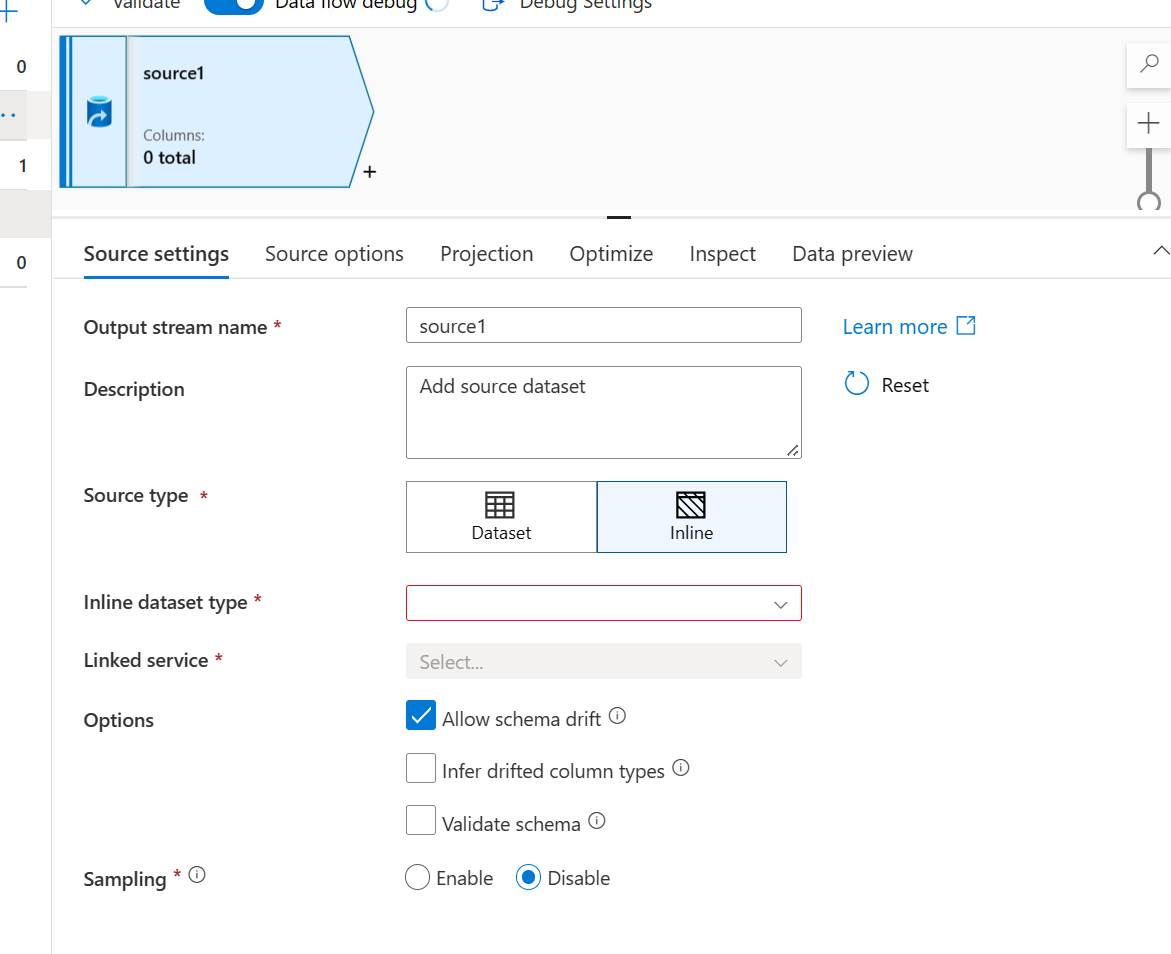
- Skonfiguruj ustawienia źródłowe w następujący sposób:
- W Typ źródła wybierz śródwierszowy.
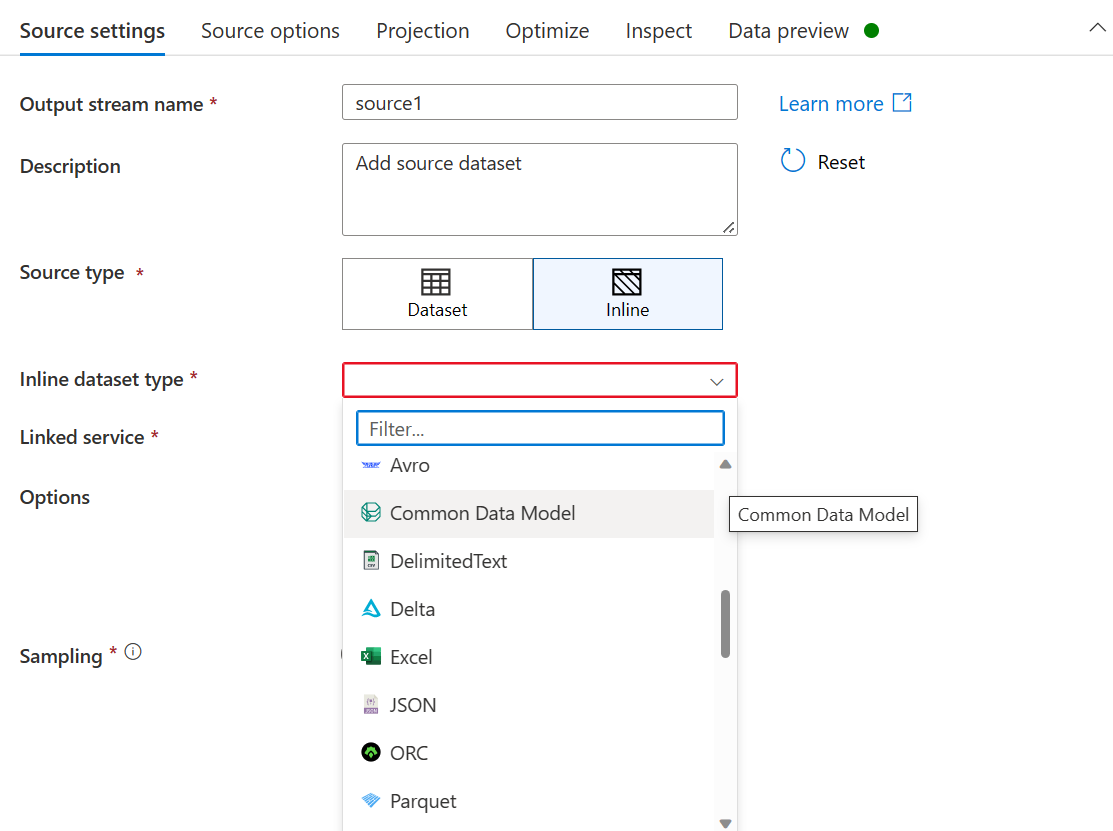
- W Typ zestaw danych śródwierszowych: Wybierz wspólny model danych.
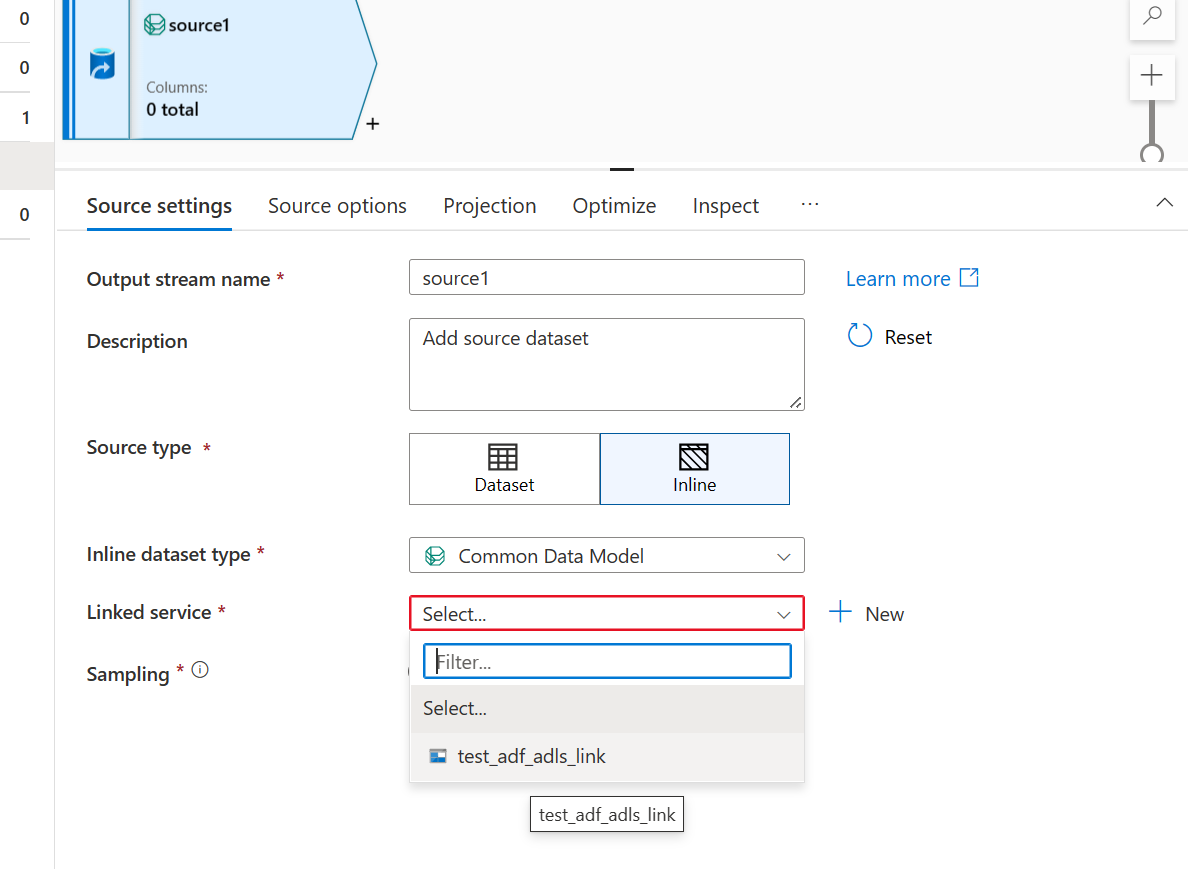
- Użyj łącza Azure Data Lake Storage utworzonego dla magazynu data lake Smart Store Analytics.
- W sekcji Opcje źródła skonfiguruj źródło schematu Common Data Model w następujący sposób:
- W Format metadanych wybierz Manifest.
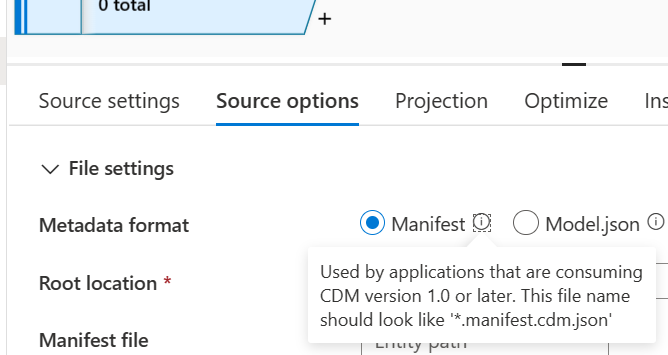
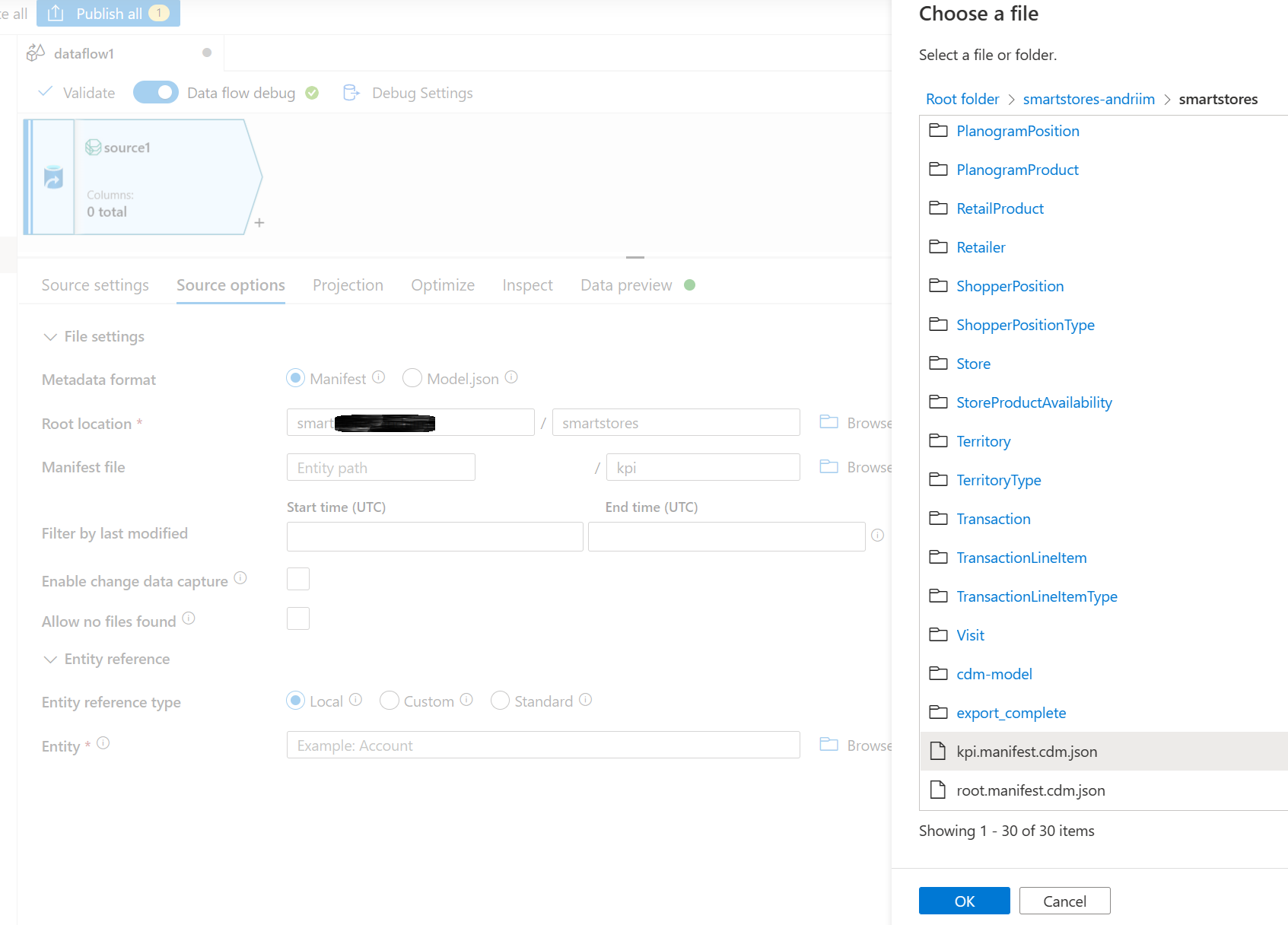
W lokalizacji głównej należy przeglądać i wybrać smartstores.
W sekcji Plik manifestu przejdź do wymaganego manifestu głównego. Wybierz plik główny dla danych analitycznych i analiz AI kpi.manifest.cdm.json.
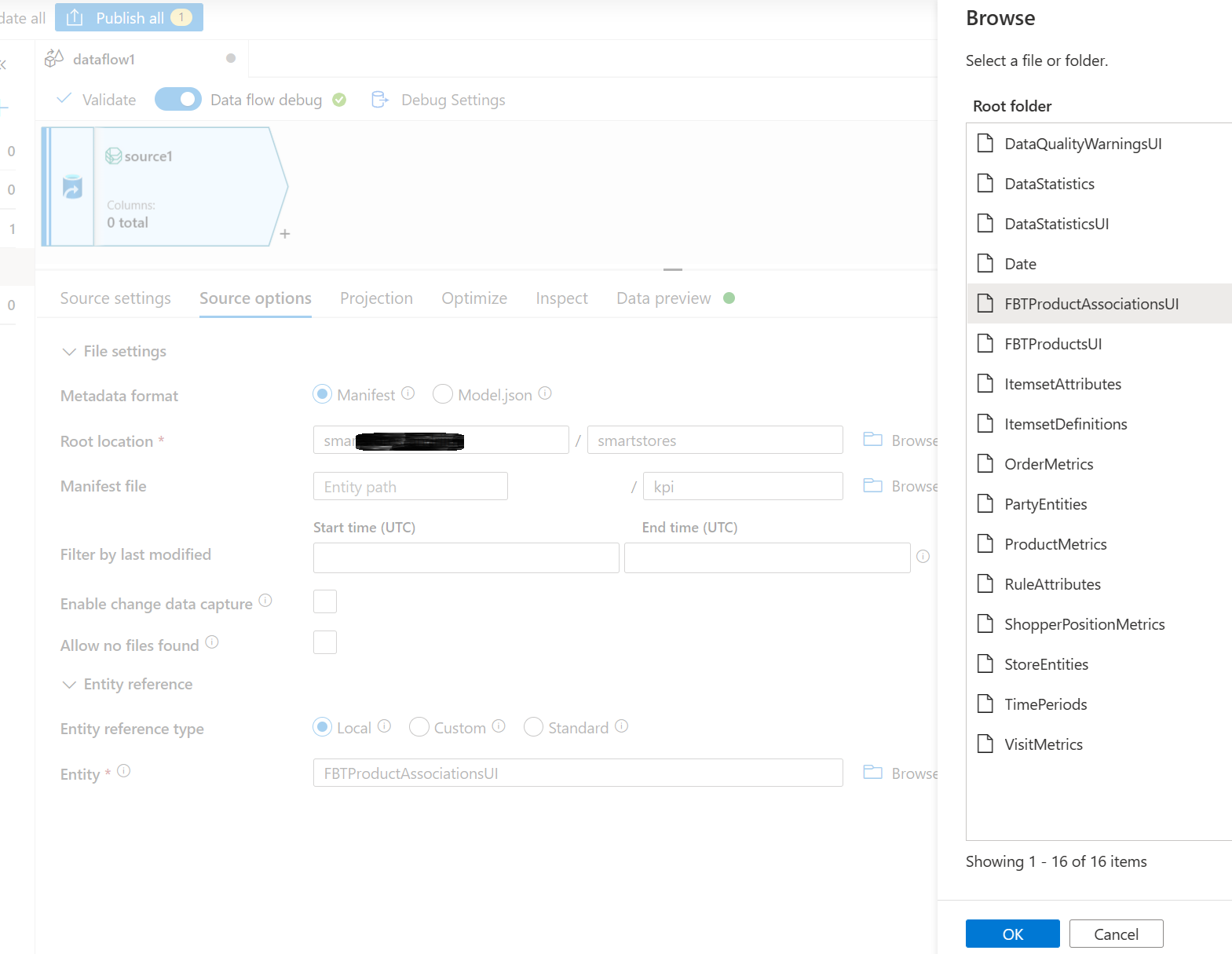
W sekcji Jednostka wybierz jednostkę (tabelę), którą chcesz skopiować/przekształcić, na przykład FBTProductAssociationsUI z pakietu Często kupowane razem.
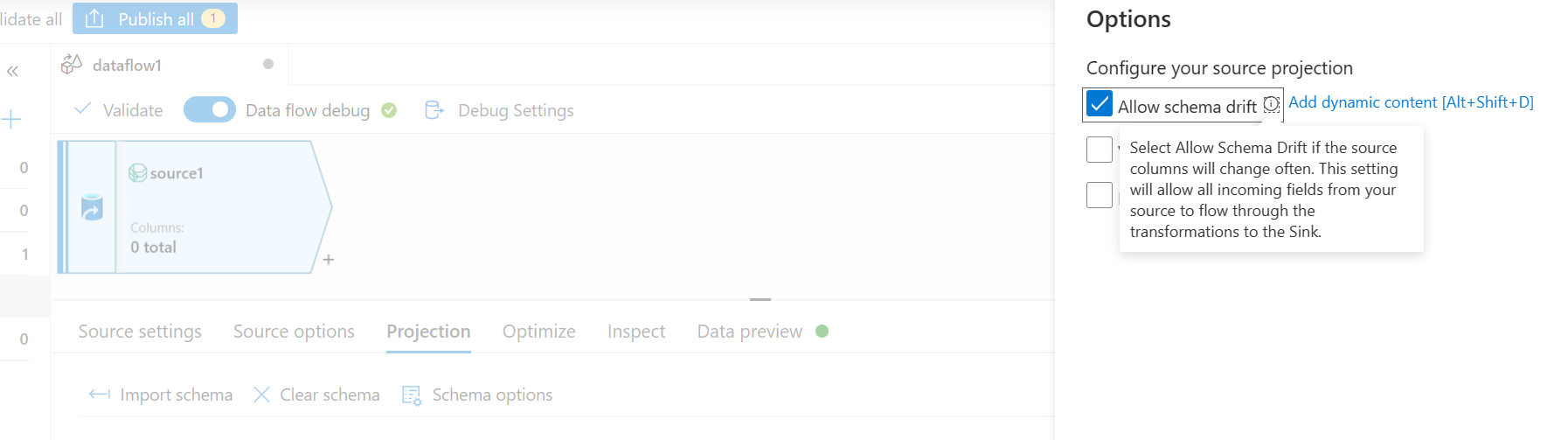
- Na karcie Pochyłki wybierz opcję Zezwalaj na schemat. Ten wybór zapewni, że schemat nie zostanie zweryfikowany u źródła, ale przejdzie do innych kroków transformacji/ujścia.
- Na karcie Podgląd danych wybierz opcję Przeładuj , aby sprawdzić poprawność źródło danych konfiguracji.
Dodaj krok ujścia — ustaw parametry i mapowanie danych zgodnie z wymaganiami swojego scenariusza.
Wybierz Publikuj, aby opublikować zmiany.