Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Funkcja jest funkcją dbscan_fl() zdefiniowaną przez użytkownika (funkcją zdefiniowaną przez użytkownika), która klasteruje zestaw danych przy użyciu algorytmu DBSCAN.
Wymagania wstępne
- Wtyczka języka Python musi być włączona w klastrze. Jest to wymagane w przypadku wbudowanego języka Python używanego w funkcji.
- Wtyczka języka Python musi być włączona w bazie danych. Jest to wymagane w przypadku wbudowanego języka Python używanego w funkcji.
Składnia
T | invoke dbscan_fl(funkcje, cluster_col ,metric_params metryki, min_samples ,epsilon, )
Dowiedz się więcej na temat konwencji składni.
Parametry
| Nazwisko | Type | Wymagania | opis |
|---|---|---|---|
| features | dynamic |
✔️ | Tablica zawierająca nazwy kolumn funkcji do użycia na potrzeby klastrowania. |
| cluster_col | string |
✔️ | Nazwa kolumny do przechowywania identyfikatora klastra wyjściowego dla każdego rekordu. |
| Epsilon | real |
✔️ | Maksymalna odległość między dwoma próbkami, które mają być traktowane jako sąsiady. |
| min_samples | int |
Liczba próbek w sąsiedztwie punktu, który ma być traktowany jako punkt podstawowy. | |
| metryka | string |
Metryka do użycia podczas obliczania odległości między punktami. | |
| metric_params | dynamic |
Dodatkowe argumenty słowa kluczowego dla funkcji metryki. |
- Aby uzyskać szczegółowy opis parametrów, zobacz dokumentację DBSCAN
- Aby uzyskać listę metryk, zobacz Obliczenia odległości
Definicja funkcji
Funkcję można zdefiniować, osadzając jej kod jako funkcję zdefiniowaną przez zapytanie lub tworząc ją jako funkcję przechowywaną w bazie danych w następujący sposób:
Zdefiniuj funkcję przy użyciu następującej instrukcji let. Nie są wymagane żadne uprawnienia.
Ważne
Instrukcja let nie może działać samodzielnie. Należy po nim wykonać instrukcję wyrażenia tabelarycznego. Aby uruchomić działający przykład polecenia kmeans_fl(), zobacz przykład.
let dbscan_fl=(tbl:(*), features:dynamic, cluster_col:string, epsilon:double, min_samples:int=10,
metric:string='minkowski', metric_params:dynamic=dynamic({'p': 2}))
{
let kwargs = bag_pack('features', features, 'cluster_col', cluster_col, 'epsilon', epsilon, 'min_samples', min_samples,
'metric', metric, 'metric_params', metric_params);
let code = ```if 1:
from sklearn.cluster import DBSCAN
from sklearn.preprocessing import StandardScaler
features = kargs["features"]
cluster_col = kargs["cluster_col"]
epsilon = kargs["epsilon"]
min_samples = kargs["min_samples"]
metric = kargs["metric"]
metric_params = kargs["metric_params"]
df1 = df[features]
mat = df1.values
# Scale the dataframe
scaler = StandardScaler()
mat = scaler.fit_transform(mat)
# see https://docs.scipy.org/doc/scipy/reference/spatial.distance.html for the various distance metrics
dbscan = DBSCAN(eps=epsilon, min_samples=min_samples, metric=metric, metric_params=metric_params) # 'minkowski', 'chebyshev'
labels = dbscan.fit_predict(mat)
result = df
result[cluster_col] = labels
```;
tbl
| evaluate python(typeof(*),code, kwargs)
};
// Write your query to use the function here.
Przykład
W poniższym przykładzie użyto operatora invoke do uruchomienia funkcji.
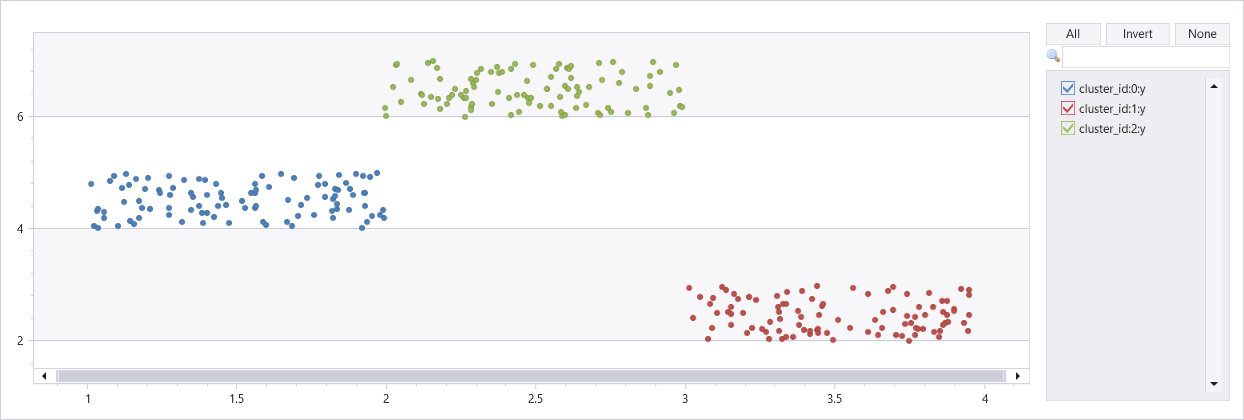
Klastrowanie sztucznego zestawu danych z trzema klastrami
Aby użyć funkcji zdefiniowanej przez zapytanie, wywołaj ją po definicji funkcji osadzonej.
let dbscan_fl=(tbl:(*), features:dynamic, cluster_col:string, epsilon:double, min_samples:int=10,
metric:string='minkowski', metric_params:dynamic=dynamic({'p': 2}))
{
let kwargs = bag_pack('features', features, 'cluster_col', cluster_col, 'epsilon', epsilon, 'min_samples', min_samples,
'metric', metric, 'metric_params', metric_params);
let code = ```if 1:
from sklearn.cluster import DBSCAN
from sklearn.preprocessing import StandardScaler
features = kargs["features"]
cluster_col = kargs["cluster_col"]
epsilon = kargs["epsilon"]
min_samples = kargs["min_samples"]
metric = kargs["metric"]
metric_params = kargs["metric_params"]
df1 = df[features]
mat = df1.values
# Scale the dataframe
scaler = StandardScaler()
mat = scaler.fit_transform(mat)
# see https://docs.scipy.org/doc/scipy/reference/spatial.distance.html for the various distance metrics
dbscan = DBSCAN(eps=epsilon, min_samples=min_samples, metric=metric, metric_params=metric_params) # 'minkowski', 'chebyshev'
labels = dbscan.fit_predict(mat)
result = df
result[cluster_col] = labels
```;
tbl
| evaluate python(typeof(*),code, kwargs)
};
union
(range x from 1 to 100 step 1 | extend x=rand()+3, y=rand()+2),
(range x from 101 to 200 step 1 | extend x=rand()+1, y=rand()+4),
(range x from 201 to 300 step 1 | extend x=rand()+2, y=rand()+6)
| extend cluster_id=int(null)
| invoke dbscan_fl(pack_array("x", "y"), "cluster_id", epsilon=0.6, min_samples=4, metric_params=dynamic({'p':2}))
| render scatterchart with(series=cluster_id)