Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Dotyczy: ✅Microsoft Fabric✅✅
Scala wyniki HLL. Jest to wersja skalarna zagregowanej wersji hll_merge().
Przeczytaj o algorytmie bazowym (H yperL ogLog)i dokładności szacowania.
Ważne
Wyniki hll(), hll_if() i hll_merge() można przechowywać i pobierać później. Możesz na przykład utworzyć codzienne, unikatowe podsumowanie użytkowników, które następnie może służyć do obliczania liczb tygodniowych. Jednak dokładna reprezentacja binarna tych wyników może ulec zmianie w czasie. Nie ma gwarancji, że te funkcje generują identyczne wyniki dla identycznych danych wejściowych, dlatego nie zalecamy polegania na nich.
Składnia
hll_merge(
Hll,hll2, [ hll3, ... ])
Dowiedz się więcej na temat konwencji składni.
Parametry
| Nazwisko | Type | Wymagania | opis |
|---|---|---|---|
| hll, hll2, ... | string |
✔️ | Nazwy kolumn zawierające wartości HLL do scalenia. Funkcja oczekuje od 2 do 64 argumentów. |
Zwraca
Zwraca jedną wartość HLL. Wartość jest wynikiem scalenia kolumn hll, hll2, ... hllN.
Przykłady
W tym przykładzie przedstawiono wartość scalonych kolumn.
range x from 1 to 10 step 1
| extend y = x + 10
| summarize hll_x = hll(x), hll_y = hll(y)
| project merged = hll_merge(hll_x, hll_y)
| project dcount_hll(merged)
Wyjście
dcount_hll_merged |
|---|
| 20 |
Dokładność szacowania
Ta funkcja używa wariantu algorytmu HyperLogLog (HLL), który wykonuje stochastyczne oszacowanie kardynalności zestawu. Algorytm udostępnia "pokrętło", które może służyć do równoważenia dokładności i czasu wykonywania na rozmiar pamięci:
| Dokładność | Błąd (%) | Liczba pozycji |
|---|---|---|
| 0 | 1.6 | 212 |
| 1 | 0,8 | 214 |
| 2 | 0,4 | 216 |
| 3 | 0,28 | 217 |
| 100 | 0,2 | 218 |
Uwaga
Kolumna "liczba wpisów" jest liczbą liczników 1 bajtów w implementacji HLL.
Algorytm zawiera pewne przepisy dotyczące wykonywania doskonałej liczby (błąd zerowy), jeśli kardynalność zestawu jest wystarczająco mała:
- Gdy poziom dokładności to
1, zwracane są wartości 1000 - Gdy poziom dokładności to
2, zwracane są wartości 8000
Granica błędu jest probabilistyczna, a nie teoretyczna granica. Wartość jest odchyleniem standardowym rozkładu błędów (sigma), a 99,7% oszacowań będzie miało względny błąd poniżej 3 x sigma.
Na poniższej ilustracji przedstawiono funkcję rozkładu prawdopodobieństwa błędu szacowania względnego w procentach dla wszystkich obsługiwanych ustawień dokładności:
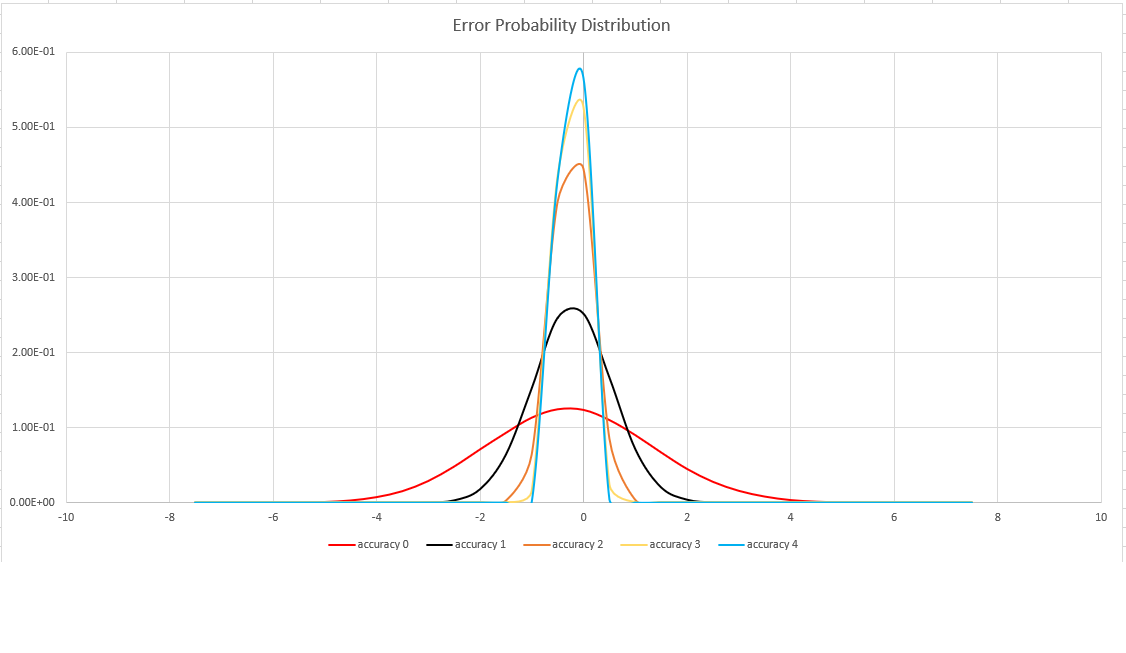
Powiązana zawartość
- using hll() and tdigest()
- hll() (funkcja agregacji)
- hll_if() (funkcja agregacji)
- hll_merge() (funkcja agregacji)