Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Ważne
Tłumaczenia nieanglojęzyczne są dostępne tylko dla wygody. Aby zapoznać się z wiążącą wersją, sprawdź EN-US wersję tego dokumentu.
Ten artykuł zawiera szczegółowe informacje dotyczące sposobu przetwarzania, używania i przechowywania danych dostarczonych przez Użytkownika do usługi Azure OpenAI. Usługa Azure OpenAI przechowuje i przetwarza dane w celu zapewnienia usługi oraz monitorowania pod kątem zastosowań naruszających odpowiednie warunki produktu. Zobacz również dodatek Microsoft Products and Services Data Protection, który zarządza przetwarzaniem danych przez usługę Azure OpenAI Service. Azure OpenAI to usługa platformy Azure; dowiedz się więcej o odpowiednich ofertach zgodności platformy Azure.
Ważne
Monity (dane wejściowe) i zakończenia (dane wyjściowe), osadzanie i dane szkoleniowe:
- nie są dostępne dla innych klientów.
- nie są dostępne dla OpenAI.
- nie są używane do ulepszania modeli OpenAI.
- Nie są używane do trenowania, ponownego trenowania lub ulepszania modeli platformy Azure OpenAI Service Foundation.
- nie są używane do ulepszania żadnych produktów lub usług firmy Microsoft lub innych firm bez Twojej zgody lub polecenia.
- Dostosowane modele usługi Azure OpenAI są dostępne wyłącznie do użytku.
Usługa Azure OpenAI jest obsługiwana przez firmę Microsoft jako usługę platformy Azure; Firma Microsoft hostuje modele OpenAI w środowisku platformy Azure firmy Microsoft, a usługa nie współdziała z żadnymi usługami obsługiwanymi przez interfejs OpenAI (np. ChatGPT lub interfejs API OpenAI).
Jakie dane przetwarza usługa Azure OpenAI?
Usługa Azure OpenAI przetwarza następujące typy danych:
- Propozycje i wygenerowana zawartość. Podpowiedzi są przesyłane przez użytkownika, a zawartość jest generowana przez usługę za pomocą operacji uzupełniania, uzupełniania czatu, tworzenia obrazów i osadzania.
- Przekazane dane. Możesz udostępnić własne dane do użycia z określonymi funkcjami usługi (np. dostrajaniem, interfejsem API asystentów, przetwarzaniem wsadowym) przy użyciu interfejsu API plików lub magazynu wektorów.
- Dane dla jednostek stanowych. W przypadku korzystania z niektórych opcjonalnych funkcji usługi Azure OpenAI, takich jak funkcja Wątki interfejsu API Asystentów i Przechowywane uzupełnienia, usługa tworzy repozytorium danych do trwałego zapisywania historii komunikatów i innej zawartości zgodnie z konfiguracjami funkcji.
- Rozszerzone dane dołączone do polecenia lub za pośrednictwem monitów. Gdy używasz danych skojarzonych z jednostkami z pamięcią stanu, usługa pobiera odpowiednie dane ze skonfigurowanego magazynu danych i uzupełnia monit, aby tworzyć generacje osadzone w twoich danych. Monity mogą być również rozszerzone o dane pobrane ze źródła uwzględnionego bezpośrednio w monicie, na przykład adres URL.
- Dane trenowania i walidacji. Możesz podać własne dane szkoleniowe składające się z pary podpowiedzi i odpowiedzi na potrzeby dostrajania modelu OpenAI.
Jak usługa Azure OpenAI przetwarza dane?
Na poniższym diagramie przedstawiono sposób przetwarzania danych. Ten diagram obejmuje kilka typów przetwarzania:
- Sposób przetwarzania monitów przez usługę Azure OpenAI za pośrednictwem wnioskowania w celu wygenerowania zawartości (w tym gdy dodatkowe dane z wyznaczonego źródła danych są dodawane do monitu przy użyciu usługi Azure OpenAI na danych, asystentach lub przetwarzaniu wsadowym).
- Jak funkcja Asystentów przechowuje dane w związku z wiadomościami, wątkami i przebiegami.
- Jak funkcja usługi Batch przetwarza przekazane dane.
- Jak usługa Azure OpenAI tworzy dostosowany (niestandardowy) model na podstawie wgranych danych.
- W jaki sposób usługa Azure OpenAI Service i personel firmy Microsoft analizują monity i odpowiedzi (tekst i obraz) ze względu na szkodliwą zawartość oraz wzorce sugerujące korzystanie z usługi w sposób naruszający Kodeks postępowania lub inne obowiązujące postanowienia dotyczące produktu.

Jak pokazano na powyższym diagramie, klienci zarządzani mogą wnioskować o zmianę monitorowania nadużyć.
Generowanie uzupełniania, obrazów lub osadzania za pomocą wnioskowania
Modele (podstawowe lub dostrojone) wdrożone w twoim zasobie przetwarzają monity wejściowe i generują odpowiedzi w postaci tekstu, obrazów lub osadzeń. Interakcje klientów z modelem są logicznie izolowane i zabezpieczone przy użyciu środków technicznych, w tym nie tylko do szyfrowania transportu protokołu TLS1.2 lub nowszego, obwodu zabezpieczeń obliczeniowych, tokenizacji tekstu i wyłącznego dostępu do przydzielonej pamięci procesora GPU. Podpowiedzi i odpowiedzi są oceniane w czasie rzeczywistym pod kątem szkodliwych treści, a generowanie treści jest filtrowane na podstawie skonfigurowanych progów. Dowiedz się więcej na temat filtrowania zawartości usługi Azure OpenAI Service.
Monity i odpowiedzi są przetwarzane w lokalizacji geograficznej określonej przez klienta (chyba że używasz globalnego typu wdrożenia), ale mogą być przetwarzane między regionami w lokalizacji geograficznej na potrzeby operacyjne (w tym zarządzanie wydajnością i pojemnością). Poniżej znajdują się informacje o lokalizacji przetwarzania w przypadku korzystania z globalnego typu wdrożenia.
Modele są bezstanowe: w modelu nie są przechowywane żadne polecenia ani wyniki generowania. Ponadto monity i generowane treści nie są używane do trenowania, ponownego trenowania ani ulepszania modeli podstawowych.
Zrozumienie lokalizacji przetwarzania dla typów wdrożeń "Globalny" i "Strefa danych"
Oprócz standardowych wdrożeń usługa Azure OpenAI Service oferuje opcje wdrażania oznaczone jako "Globalne" i "DataZone". W przypadku dowolnego typu wdrożenia oznaczonego jako "Globalny" monity i odpowiedzi mogą być przetwarzane w dowolnej lokalizacji geograficznej, w której wdrożono odpowiedni model usługi Azure OpenAI (dowiedz się więcej o dostępności regionów modeli). W przypadku dowolnego typu wdrożenia oznaczonego jako "DataZone" monity i odpowiedzi mogą być przetwarzane w dowolnej lokalizacji geograficznej w określonej strefie danych, zgodnie z definicją przez firmę Microsoft. Jeśli utworzysz wdrożenie DataZone w zasobie usługi Azure OpenAI znajdującym się w Stanach Zjednoczonych, monity i odpowiedzi mogą być przetwarzane w dowolnym miejscu w Stanach Zjednoczonych. Jeśli utworzysz wdrożenie DataZone w zasobie Azure OpenAI znajdującym się w kraju członkowskim Unii Europejskiej, monity i odpowiedzi mogą być przetwarzane w tym lub w innym kraju członkowskim Unii Europejskiej. W przypadku typów wdrożeń Global i DataZone wszystkie dane przechowywane w spoczynku, takie jak przekazane dane, są przechowywane w lokalizacji geograficznej wyznaczonej przez klienta. Dotyczy to tylko lokalizacji przetwarzania, gdy klient używa globalnego typu wdrożenia lub typu wdrożenia DataZone w usłudze Azure OpenAI Service; Zobowiązania dotyczące przetwarzania danych i zgodności platformy Azure pozostają stosowane.
Rozszerzanie poleceń, aby oprzeć wygenerowane wyniki na twoich danych
Funkcja Azure OpenAI "na podstawie danych" umożliwia łączenie źródeł danych, aby uzasadnić wygenerowane wyniki w oparciu o Twoje dane. Dane pozostają przechowywane w źródle danych i wyznaczonej lokalizacji; Usługa Azure OpenAI nie tworzy zduplikowanego magazynu danych. Po otrzymaniu monitu użytkownika usługa pobiera odpowiednie dane ze połączonego źródła danych i rozszerza monit. Model przetwarza ten rozszerzony monit, a wygenerowana zawartość jest zwracana zgodnie z powyższym opisem. Dowiedz się więcej na temat bezpiecznego korzystania z funkcji Na Twoich Danych.
Magazyn danych dla funkcji usługi Azure OpenAI Service
Niektóre funkcje usługi Azure OpenAI Service przechowują dane w usłudze. Te dane są przekazywane przez klienta przy użyciu interfejsu API plików lub magazynu wektorów lub są automatycznie przechowywane w połączeniu z niektórymi jednostkami stanowymi, takimi jak funkcja Wątki interfejsu API Asystentów i przechowywanych ukończeń. Dane przechowywane dla funkcji usługi Azure OpenAI Service:
- Jest przechowywany w stanie spoczynku w zasobie usługi Azure OpenAI w dzierżawie platformy Azure klienta w tej samej lokalizacji geograficznej co zasób usługi Azure OpenAI.
- Jest zawsze szyfrowany w spoczynku przy użyciu szyfrowania AES-256 firmy Microsoft domyślnie z opcją używania klucza zarządzanego przez klienta (niektóre funkcje w wersji zapoznawczej mogą nie obsługiwać kluczy zarządzanych przez klienta).
- Mogą zostać usunięte przez klienta w dowolnym momencie.
Uwaga / Notatka
Funkcje usługi Azure OpenAI w wersji zapoznawczej mogą nie obsługiwać wszystkich powyższych warunków.
Przechowywane dane mogą być używane z następującymi funkcjami/możliwościami usługi:
- Tworzenie dostosowanego (dopasowanego) modelu. Dowiedz się więcej o tym, jak działa dostrajanie. Dokomponowane modele są dostępne wyłącznie dla klienta, którego dane zostały użyte do ich stworzenia. Modele te są szyfrowane w przypadku nieaktywności (gdy nie są wdrożone do celów inferencji) i mogą zostać usunięte przez klienta w dowolnym momencie. Dane szkoleniowe przekazane do dostrajania nie są używane do trenowania, ponownego trenowania ani ulepszania modeli bazowych firmy Microsoft ani innych firm.
- Przetwarzanie wsadowe. Dowiedz się więcej o sposobie działania przetwarzania wsadowego. Przetwarzanie wsadowe jest globalnym typem wdrożenia; dane przechowywane w spoczynku pozostają w wyznaczonej lokalizacji geograficznej platformy Azure do momentu udostępnienia pojemności przetwarzania; przetwarzanie może wystąpić w dowolnej lokalizacji geograficznej, w której wdrożono odpowiedni model usługi Azure OpenAI (dowiedz się więcej o dostępności modeli w regionie).
- Interfejs API asystentów (wersja zapoznawcza). Dowiedz się więcej o sposobie działania interfejsu API Asystentów. Niektóre funkcje Asystentów, takie jak Wątki, przechowują historię komunikatów i inną zawartość.
- Zapisane uzupełnienia (wersja zapoznawcza). Przechowywane uzupełnienia zapisują pary wejście-wyjście z modeli Azure OpenAI wdrożonych przez klienta, takich jak GPT-4o, za pomocą interfejsu API do ukończeń czatów i wyświetlają te pary w portalu Azure AI Foundry. Dzięki temu klienci mogą tworzyć zestawy danych ze swoimi danymi produkcyjnymi, które mogą być następnie używane do oceny lub dostrajania modeli (zgodnie z obowiązującymi warunkami produktu).
Zapobieganie nadużyciom i szkodliwemu generowaniu zawartości
Aby zmniejszyć ryzyko szkodliwego użycia usługi Azure OpenAI Service, usługa Azure OpenAI Service obejmuje zarówno filtrowanie zawartości, jak i funkcje monitorowania nadużyć. Aby dowiedzieć się więcej na temat filtrowania zawartości, zobacz Filtrowanie zawartości w usłudze Azure OpenAI Service. Aby dowiedzieć się więcej na temat monitorowania nadużyć, zobacz Monitorowanie nadużyć.
Filtrowanie zawartości odbywa się synchronicznie, ponieważ procesy usługi monituje o wygenerowanie zawartości zgodnie z powyższym opisem i tutaj. Żadne monity ani wygenerowana zawartość nie są przechowywane w modelach klasyfikatora zawartości, a monity i dane wyjściowe nie są używane do trenowania, ponownego trenowania ani ulepszania modeli klasyfikatora bez zgody użytkownika.
Oceny bezpieczeństwa dostosowanych modeli oceniają dostosowany model pod kątem potencjalnie szkodliwych reakcji przy użyciu metryk ryzyka i bezpieczeństwa platformy Azure. Tylko wynikowa ocena (można wdrożyć lub nie można jej wdrożyć) jest rejestrowana przez usługę.
System monitorowania nadużyć w usłudze Azure OpenAI został zaprojektowany w celu wykrywania i eliminowania wystąpień cyklicznej zawartości i/lub zachowań sugerujących korzystanie z usługi w sposób, który może naruszać kodeks postępowania lub inne obowiązujące postanowienia dotyczące produktu. Zgodnie z opisem w tym miejscu system stosuje algorytmy i algorytmy heurystyczne w celu wykrywania wskaźników potencjalnych nadużyć. Po wykryciu tych wskaźników można wybrać próbkę monitów oraz odpowiedzi klienta do przeglądu. Przegląd jest przeprowadzany głównie przez LLM, z dodatkowymi recenzjami przez recenzentów ludzkich, jeśli to konieczne. Szczegółowe informacje na temat sztucznej inteligencji i przeglądu ludzkiego są dostępne w temacie Monitorowanie nadużyć w usłudze Azure OpenAI Service.
W ramach przeglądu związanym ze sztuczną inteligencją, podpowiedzi i zakończenia klienta nie są przechowywane przez system ani używane do treningu LLM lub innych systemów. W przypadku przeglądu przez człowieka magazyn danych, w którym są przechowywane polecenia i uzupełnienia, jest logicznie wydzielony według zasobów klienta (każde żądanie zawiera identyfikator zasobu klienta w usłudze Azure OpenAI). Oddzielny magazyn danych znajduje się w każdej lokalizacji geograficznej, w której jest dostępna usługa Azure OpenAI, a monity klienta i wygenerowana zawartość są przechowywane w lokalizacji geograficznej platformy Azure, w której wdrożono zasób usługi Azure OpenAI klienta, w granicach usługi Azure OpenAI. Recenzenci oceniający potencjalne nadużycie mogą uzyskać dostęp do danych podpowiedzi i uzupełnień tylko wtedy, gdy te dane zostały już oznaczone przez system monitorowania nadużyć. Recenzenci są autoryzowani przez pracowników firmy Microsoft, którzy uzyskują dostęp do danych za pośrednictwem zapytań punktowych przy użyciu identyfikatorów żądań, stacji roboczych bezpiecznego dostępu (SAW) i żądań Just-In-Time (JIT) udzielonych przez menedżerów zespołów. W przypadku usługi Azure OpenAI wdrożonej w Europejskim Obszarze Gospodarczym autoryzowani pracownicy firmy Microsoft znajdują się w Europejskim Obszarze Gospodarczym.
Jeśli klient został zatwierdzony do monitorowania zmodyfikowanych nadużyć (dowiedz się więcej w temacie Monitorowanie nadużyć w usłudze Azure OpenAI), firma Microsoft nie przechowuje monitów i uzupełniania skojarzonych z zatwierdzonymi subskrypcjami platformy Azure, a opisany powyżej proces przeglądu przez człowieka nie jest możliwy i nie jest wykonywany. Jednak przegląd sztucznej inteligencji może być nadal przeprowadzony, wykorzystując modele LLM, które sprawdzają podpowiedzi i odpowiedzi w momencie dostarczenia lub generowania, jeśli jest to odpowiednie.
Uwaga / Notatka
Funkcje platformy Azure w wersji zapoznawczej, w tym modele usługi Azure OpenAI w wersji zapoznawczej, mogą korzystać z różnych praktyk dotyczących prywatności, w tym w odniesieniu do monitorowania nadużyć. Wersje zapoznawcze mogą podlegać dodatkowym warunkom na stronie: Dodatkowe warunki użytkowania dla wersji zapoznawczych platformy Microsoft Azure.
Jak klient może sprawdzić, czy magazyn danych na potrzeby monitorowania nadużyć jest wyłączony?
Istnieją dwa sposoby dla klientów, aby po uzyskaniu zatwierdzenia wyłączyć monitorowanie nadużyć i sprawdzić, czy przechowywanie danych dla tego monitorowania zostało zakończone w zatwierdzonej subskrypcji platformy Azure.
- Korzystanie z witryny Azure Portal lub
- Azure CLI (lub dowolny interfejs API zarządzania).
Uwaga / Notatka
Wartość "false" atrybutu "ContentLogging" jest wyświetlana tylko wtedy, gdy magazyn danych na potrzeby monitorowania nadużyć jest wyłączony. W przeciwnym razie ta właściwość nie będzie wyświetlana w Azure Portal ani w wynikach Azure CLI.
Wymagania wstępne
- Zaloguj się do platformy Azure
- Wybierz subskrypcję platformy Azure, która hostuje zasób usługi Azure OpenAI Service.
- Przejdź do strony Przegląd zasobu usługi Azure OpenAI Service.
- Korzystanie z Azure Portal
- Korzystanie z interfejsu wiersza polecenia platformy Azure (lub innego interfejsu API zarządzania)
Przejdź do strony Przegląd zasobu
Kliknij link widok JSON w prawym górnym rogu, jak pokazano na poniższej ilustracji.
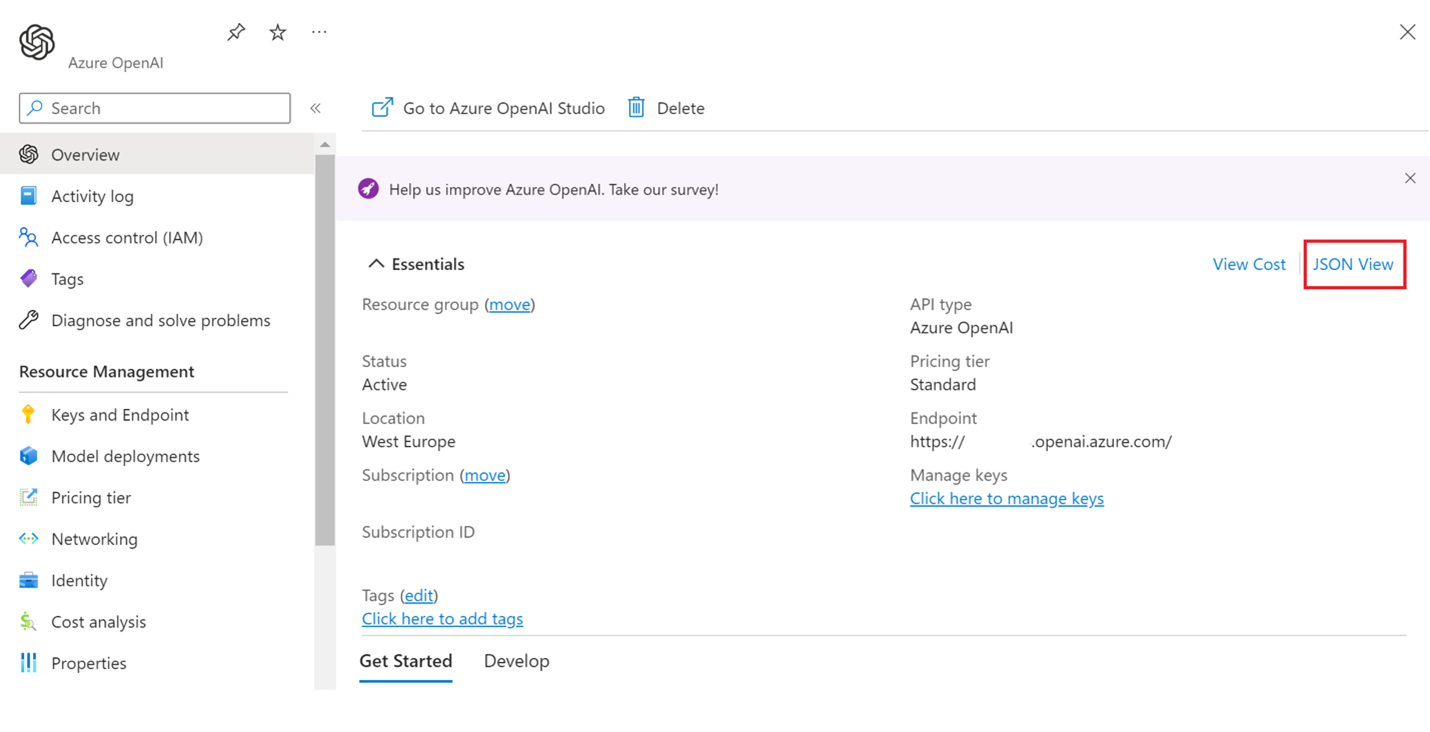
Na liście Możliwości będzie wartość o nazwie "ContentLogging", która będzie wyświetlana i ustawiona na FALSE, gdy rejestrowanie w celu monitorowania nadużyć jest wyłączone.
{
"name":"ContentLogging",
"value":"false"
}
Aby dowiedzieć się więcej na temat zobowiązań firmy Microsoft dotyczących prywatności i zabezpieczeń, zobacz Centrum zaufania firmy Microsoft.
Dziennik zmian
| Data kalendarzowa | Zmiany |
|---|---|
| 17 grudnia 2024 r. | Dodano informacje o przetwarzaniu i przechowywaniu danych w połączeniu z nową funkcją Uzupełnianie przechowywane; dodano język wyjaśniający, że funkcje usługi Azure OpenAI w wersji zapoznawczej mogą nie obsługiwać wszystkich warunków przechowywania danych; usunięto oznaczenie "wersja zapoznawcza" dla przetwarzania wsadowego |
| 18 listopada 2024 r. | Dodano informacje o lokalizacji przetwarzania danych dla nowych typów wdrożeń w 'Strefie danych'; dodano informacje o nowym przeglądzie poleceń i uzupełnień przez sztuczną inteligencję w ramach zapobiegania nadużyciom i generowaniu szkodliwych treści. |
| 4 września 2024 r. | Dodano informacje (i odpowiednio poprawiony istniejący tekst) dotyczące przetwarzania danych dla nowych funkcji, takich jak interfejs API Asystentów (wersja zapoznawcza), Usługa Batch (wersja zapoznawcza) i wdrożenia globalne; poprawiony język związany z lokalizacją przetwarzania danych zgodnie z zasadami rezydencji danych platformy Azure; dodano informacje o przetwarzaniu danych w celu oceny bezpieczeństwa dostosowanych modeli; wyjaśnione zobowiązania związane z korzystaniem z monitów i uzupełniania; drobne poprawki w celu zwiększenia przejrzystości |
| 23 czerwca 2023 r. | Dodano informacje o przetwarzaniu danych dla nowej funkcji Azure dla Twoich danych; usunięto informacje o monitorowaniu nadużyć, które są teraz dostępne w ramach monitorowania nadużyć w usłudze Azure OpenAI Service. Dodano notatkę podsumowującą. Zaktualizowana i usprawniona zawartość oraz zaktualizowane diagramy w celu uzyskania dodatkowej jasności. dodano dziennik zmian |
Zobacz także
- Kodeks postępowania dla integracji usługi Azure OpenAI Service
- Omówienie praktyk odpowiedzialnej sztucznej inteligencji dla modeli platformy Azure OpenAI
- Uwaga dotycząca przejrzystości i przypadki użycia usługi Azure OpenAI Service
- Jurysdykcja danych na platformie Azure
- Porównanie usługi Azure OpenAI w usłudze Azure Government
- Ograniczony dostęp do usługi Azure OpenAI Service
- Zgłoś nadużycie usługi Azure OpenAI za pośrednictwem portalu zgłaszania nadużyć
- Zgłoś problem cscraireport@microsoft.com