Trenowanie modelu przetwarzania dokumentów bez struktury w Microsoft Syntex
Dotyczy: √ Przetwarzanie dokumentów bez struktury
Postępuj zgodnie z instrukcjami w temacie Tworzenie modelu w aplikacji Syntex , aby utworzyć model przetwarzania dokumentów bez struktury w centrum zawartości. Możesz też wykonać instrukcje opisane w temacie Tworzenie modelu w lokalnej witrynie programu SharePoint , aby utworzyć model w witrynie lokalnej. Następnie zacznij od tego artykułu, aby rozpocząć trenowanie modelu.
Utwórz klasyfikator
Klasyfikator to typ modelu, którego można użyć do zautomatyzowania identyfikacji i klasyfikacji typu dokumentu.
Możesz na przykład zidentyfikować wszystkie dokumenty odnawiania kontraktu dodane do biblioteki dokumentów, takie jak pokazano na poniższej ilustracji.

Utworzenie klasyfikatora umożliwia utworzenie nowego typu zawartości programu SharePoint , który będzie skojarzony z modelem.
Podczas tworzenia klasyfikatora należy utworzyć wyjaśnienia , aby zdefiniować model. Ten krok umożliwia zanotowanie typowych danych, których można oczekiwać od spójnego znajdowania tego typu dokumentu.
Użyj przykładów typu dokumentu ("pliki przykładowe"), aby "wytrenować" model w celu zidentyfikowania plików o tym samym typie zawartości.
Aby utworzyć klasyfikator, należy wykonać następujące czynności:
- Nadaj modelowi nazwę.
- Dodaj przykładowe pliki.
- Etykietowanie przykładowych plików.
- Utwórz wyjaśnienie.
- Przetestuj model.
Uwaga
Podczas gdy model używa klasyfikatora do identyfikowania i klasyfikowania typów dokumentów, możesz również pobrać określone informacje z każdego pliku zidentyfikowanego przez model. W tym celu utwórz wyodrębniacz , który ma zostać dodany do modelu. Zobacz Tworzenie wyodrębniacza.
Nadaj modelowi nazwę
Pierwszym krokiem tworzenia modelu jest nadanie mu nazwy:
W centrum zawartości wybierz pozycję Nowy, a następnie pozycję Model.
Na stronie Opcje tworzenia modelu wybierz pozycję Metoda nauczania.
Na stronie Metoda nauczania: Szczegóły wybierz pozycję Dalej.
Na stronie Tworzenie modelu przy użyciu metody dydaktycznej w polu Nazwa modelu wpisz nazwę modelu. Jeśli na przykład chcesz zidentyfikować dokumenty odnawiania kontraktu, możesz nadać modelowi nazwę Odnowienie kontraktu.
Wybierz pozycję Utwórz. Ta akcja tworzy stronę główną modelu.
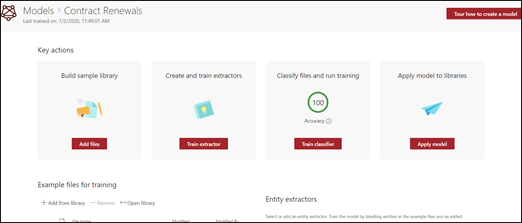
Podczas tworzenia modelu tworzysz również nowy typ zawartości witryny. Typ zawartości reprezentuje kategorię dokumentów, które mają wspólne cechy i udostępniają kolekcję kolumn lub właściwości metadanych dla danej zawartości. Typy zawartości programu SharePoint są zarządzane za pośrednictwem galerii Typy zawartości. W tym przykładzie podczas tworzenia modelu tworzysz nowy typ zawartości Odnawianie kontraktu .
Wybierz pozycję Ustawienia zaawansowane , jeśli chcesz zamapować ten model na istniejący typ zawartości przedsiębiorstwa w galerii typów zawartości programu SharePoint, aby użyć jego schematu. Typy zawartości przedsiębiorstwa są przechowywane w centrum typów zawartości w centrum administracyjnym programu SharePoint i są syndykatowane do wszystkich witryn w dzierżawie. Należy pamiętać, że nawet jeśli możesz użyć istniejącego typu zawartości, aby wykorzystać jego schemat, aby ułatwić identyfikację i klasyfikację, nadal musisz wytrenować model w celu wyodrębnienia informacji z zidentyfikowanych plików.

Dodawanie przykładowych plików
Na stronie głównej modelu dodaj przykładowe pliki, które będą potrzebne do wytrenowania modelu w celu zidentyfikowania typu dokumentu.
Uwaga
Należy użyć tych samych plików zarówno do trenowania klasyfikatora, jak i wyodrębniania. Zawsze możesz dodać więcej później, ale zazwyczaj dodajesz pełny zestaw przykładowych plików. Oznacz niektóre, aby wytrenować model, i przetestuj pozostałe nieoznaczone etykiety, aby ocenić kondycję modelu.
W przypadku zestawu treningowego chcesz użyć zarówno pozytywnych, jak i negatywnych przykładów:
- Pozytywny przykład: dokumenty reprezentujące typ dokumentu. Zawierają one ciągi i informacje, które zawsze znajdują się w tym typie dokumentu.
- Negatywny przykład: dowolny inny dokument, który nie reprezentuje dokumentu, który chcesz sklasyfikować.
Pamiętaj, aby użyć co najmniej pięciu pozytywnych przykładów i co najmniej jednego negatywnego przykładu do trenowania modelu. Chcesz utworzyć kolejne, aby przetestować model po zakończeniu procesu trenowania.
Aby dodać przykładowe pliki:
Na stronie głównej modelu na kafelku Dodawanie przykładowych plików wybierz pozycję Dodaj pliki.
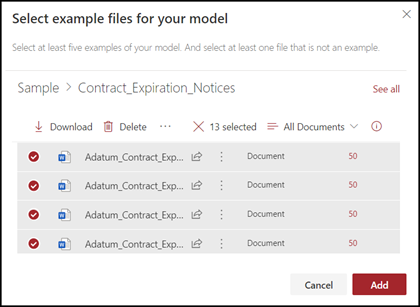
Na stronie Wybieranie przykładowych plików dla modelu wybierz przykładowe pliki z biblioteki Pliki szkoleniowe w centrum zawartości. Jeśli nie przekazano ich w tym miejscu, wybierz, aby przekazać je teraz, klikając pozycję Przekaż , aby skopiować je do biblioteki Plików szkoleniowych.
Po wybraniu przykładowych plików do wytrenowania modelu wybierz pozycję Dodaj.
Etykietowanie przykładowych plików
Po dodaniu przykładowych plików należy oznaczyć je jako przykłady dodatnie lub negatywne.
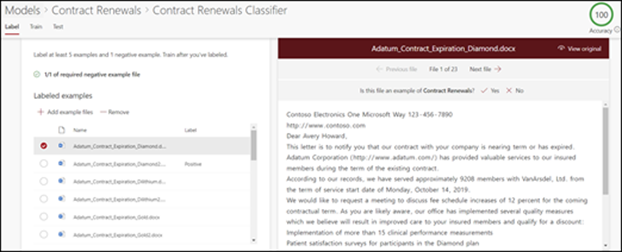
Na stronie głównej modelu na kafelku Classify files and run training (Klasyfikowanie plików i uruchamianie trenowania) wybierz pozycję Train classifier (Trenowanie klasyfikatora). W tym kroku zostanie wyświetlona strona etykiety zawierająca listę przykładowych plików z pierwszym plikiem widocznym w przeglądarce.
W przeglądarce w górnej części pierwszego przykładowego pliku powinien zostać wyświetlony tekst z pytaniem, czy plik jest przykładem właśnie utworzonego modelu. Jeśli jest to pozytywny przykład, wybierz pozycję Tak. Jeśli jest to przykład negatywny, wybierz pozycję Nie.
Z listy Przykłady oznaczone po lewej stronie wybierz dodatkowe pliki, których chcesz użyć jako przykłady, i oznacz je etykietami.
Uwaga
Oznacz co najmniej pięć pozytywnych przykładów. Należy również oznaczyć etykietą co najmniej jeden negatywny przykład.
Tworzenie objaśnień
Następnym krokiem jest utworzenie objaśnienia na stronie Trenowanie. Wyjaśnienie ułatwia modelowi zrozumienie sposobu rozpoznawania dokumentu. Na przykład dokumenty odnowienia umowy zawsze zawierają żądanie dodatkowego ciągu tekstowego ujawnienia.
Uwaga
W przypadku użycia z wyodrębniaczami wyjaśnienie identyfikuje ciąg, który chcesz wyodrębnić z dokumentu.
Aby utworzyć wyjaśnienie:
Na stronie głównej modelu wybierz kartę Trenowanie , aby przejść do strony Trenowanie.
Na stronie Trenowanie w sekcji Wytrenowane pliki powinna zostać wyświetlona lista wcześniej oznaczonych przykładowych plików. Wybierz jeden z pozytywnych plików z listy i zostanie wyświetlony w przeglądarce.
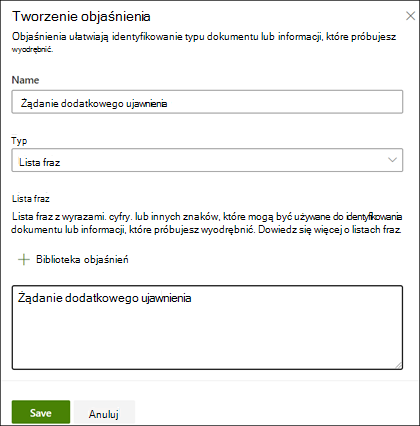
W sekcji Wyjaśnienie wybierz pozycję Nowy , a następnie pozycję Puste.
Na stronie Tworzenie wyjaśnienia : a. Wpisz nazwę (na przykład "Blok ujawniania"). B. Wybierz typ. W przykładzie wybierz pozycję Lista fraz, ponieważ dodasz ciąg tekstowy. C. W polu Wpisz tutaj wpisz ciąg. W przykładzie dodaj ciąg "Żądanie dodatkowego ujawnienia". Jeśli ciąg musi uwzględniać wielkość liter, możesz wybrać pozycję Wielkość liter. d. Wybierz Zapisz.
Centrum zawartości sprawdza teraz, czy utworzone wyjaśnienie jest wystarczająco kompletne, aby poprawnie zidentyfikować pozostałe pliki przykładowe oznaczone etykietami jako pozytywne i negatywne przykłady. W sekcji Wytrenowane pliki sprawdź kolumnę Ewaluacja po zakończeniu trenowania, aby wyświetlić wyniki. W plikach jest wyświetlana wartość Match (Dopasowanie), jeśli utworzone wyjaśnienia były wystarczające do dopasowania do wartości oznaczonych jako dodatnie lub ujemne.
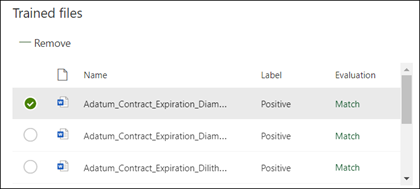
Jeśli otrzymasz niezgodność w plikach oznaczonych etykietą, może być konieczne utworzenie dodatkowego objaśnienia, aby udostępnić modelowi więcej informacji w celu zidentyfikowania typu dokumentu. Jeśli wystąpi niezgodność, wybierz plik, aby uzyskać więcej informacji o tym, dlaczego wystąpiła niezgodność.
Po wytrenowanym wyodrębniaczu ten wytrenowany wyodrębniacz może być używany jako wyjaśnienie. W sekcji Wyjaśnienia jest to wyświetlane jako odwołanie do modelu.
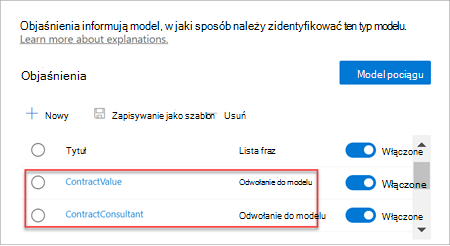
Testowanie modelu
Jeśli otrzymasz dopasowanie do oznaczonych plików przykładowych, możesz teraz przetestować model w pozostałych nieoznaczonych plikach przykładowych, których model nie widział wcześniej. Ten krok jest opcjonalny, ale przydatnym krokiem do oceny "kondycji" lub gotowości modelu przed jego użyciem przez przetestowanie go na plikach, których model nie widział wcześniej.
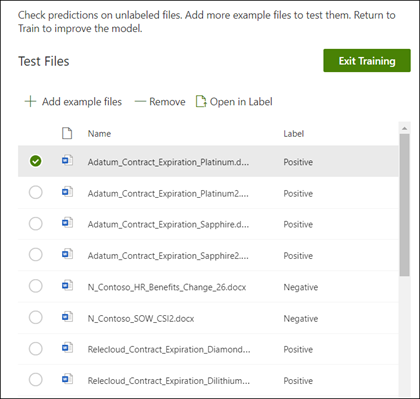
Na stronie głównej modelu wybierz kartę Test . Spowoduje to uruchamianie modelu w nieoznakowanych plikach przykładowych.
Na liście Pliki testowe przykładowe pliki są wyświetlane i pokazują, czy model przewidział ich wyniki dodatnie lub ujemne. Te informacje ułatwiają określenie skuteczności klasyfikatora w identyfikowaniu dokumentów.
Zobacz też
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla