Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W programie Power BI Desktop lub usługa Power BI można nawiązać połączenie z wieloma różnymi źródłami danych na różne sposoby. Możesz zaimportować dane do usługi Power BI, która jest najczęstszym sposobem pobierania danych. Możesz również połączyć się bezpośrednio z niektórymi danymi w oryginalnym repozytorium źródłowym, które nosi nazwę DirectQuery. W tym artykule omówiono przede wszystkim możliwości trybu DirectQuery.
W tym artykule opisano:
- Różne opcje łączności danych usługi Power BI.
- Wskazówki dotyczące tego, kiedy należy używać trybu DirectQuery, a nie importowania.
- Ograniczenia i implikacje korzystania z trybu DirectQuery.
- Zalecenia dotyczące pomyślnego korzystania z trybu DirectQuery.
- Jak zdiagnozować problemy z wydajnością zapytania bezpośredniego.
Artykuł koncentruje się na przepływie pracy directQuery podczas tworzenia raportu w programie Power BI Desktop, ale obejmuje również nawiązywanie połączenia za pośrednictwem trybu DirectQuery w usługa Power BI.
Uwaga
Tryb DirectQuery jest również funkcją usług SQL Server Analysis Services. Ta funkcja udostępnia wiele szczegółów w trybie DirectQuery w usłudze Power BI, ale istnieją również ważne różnice. W tym artykule opisano przede wszystkim zapytanie bezpośrednie w usłudze Power BI, a nie w usługach SQL Server Analysis Services.
Aby uzyskać więcej informacji na temat używania trybu DirectQuery z usługami SQL Server Analysis Services, zobacz Używanie modeli złożonych w programie Power BI Desktop). Zapytanie bezpośrednie pdf można również pobrać w usługach SQL Server 2016 Analysis Services.
Tryby łączności danych usługi Power BI
Usługa Power BI łączy się z dużą liczbą różnych źródeł danych, takich jak:
- Usługi online, takie jak Salesforce i Dynamics 365.
- Bazy danych, takie jak SQL Server, Access i Amazon Redshift.
- Proste pliki w programie Excel, formacie JSON i innych formatach.
- Inne źródła danych, takie jak Spark, witryny internetowe i Microsoft Exchange.
Możesz zaimportować dane z tych źródeł do usługi Power BI. W przypadku niektórych źródeł można również nawiązać połączenie przy użyciu trybu DirectQuery. Aby zapoznać się z podsumowaniem źródeł, które obsługują tryb DirectQuery, zobacz Źródła danych usługi Power BI. Źródła z obsługą trybu DirectQuery to przede wszystkim źródła, które mogą zapewnić dobrą wydajność zapytań interakcyjnych.
Dane należy importować do usługi Power BI wszędzie tam, gdzie to możliwe. Importowanie korzysta z aparatu zapytań o wysokiej wydajności usługi Power BI i zapewnia wysoce interaktywne, w pełni funkcjonalne środowisko.
Jeśli nie możesz osiągnąć swoich celów, importując dane, na przykład jeśli dane zmieniają się często, a raporty muszą odzwierciedlać najnowsze dane, rozważ użycie zapytania bezpośredniego. Zapytanie bezpośrednie jest możliwe tylko wtedy, gdy bazowe źródło danych może zapewnić interakcyjne wyniki zapytania w mniej niż pięć sekund dla typowego zapytania agregowanego i może obsłużyć wygenerowane obciążenie zapytania. Uważnie zastanów się nad ograniczeniami i implikacjami korzystania z trybu DirectQuery.
Możliwości importowania i trybu DirectQuery w usłudze Power BI zmieniają się wraz z upływem czasu. Zmiany, które zapewniają większą elastyczność podczas korzystania z importowanych danych, pozwalają importować częściej i wyeliminować niektóre wady korzystania z trybu DirectQuery. Niezależnie od ulepszeń wydajność bazowego źródła danych jest ważną kwestią podczas korzystania z trybu DirectQuery. Jeśli bazowe źródło danych działa wolno, użycie trybu DirectQuery dla tego źródła pozostaje niewykonalne.
W poniższych sekcjach opisano trzy opcje nawiązywania połączenia z danymi: importowanie, tryb DirectQuery i połączenie na żywo. Pozostała część artykułu koncentruje się na trybie DirectQuery.
Importowanie połączeń
Podczas nawiązywania połączenia ze źródłem danych, takiego jak program SQL Server i importowania danych w programie Power BI Desktop, istnieją następujące warunki łączności:
Podczas początkowego używania opcji Pobierz dane każdy wybrany zestaw tabel definiuje zapytanie zwracające zestaw danych. Te zapytania można edytować przed załadowaniem danych, na przykład w celu zastosowania filtrów, agregowania danych lub łączenia różnych tabel.
Po załadowaniu wszystkie dane zdefiniowane przez zapytania są importowane do pamięci podręcznej usługi Power BI.
Tworzenie wizualizacji w programie Power BI Desktop wykonuje zapytania dotyczące buforowanych danych. Magazyn usługi Power BI zapewnia, że zapytanie jest szybkie i wszystkie zmiany w wizualizacji są natychmiast odzwierciedlane.
Wizualizacje nie odzwierciedlają zmian danych bazowych w magazynie danych. Należy ponownie przeprowadzić importowanie, aby odświeżyć dane.
Opublikowanie raportu w usługa Power BI jako pliku pbix powoduje utworzenie i przekazanie modelu semantycznego zawierającego zaimportowane dane. Następnie możesz zaplanować odświeżanie danych w celu ponownego importowania danych codziennie, na przykład. W zależności od lokalizacji oryginalnego źródła danych może być konieczne skonfigurowanie lokalnej bramy danych na potrzeby odświeżania.
Otwarcie istniejącego raportu lub utworzenie nowego raportu w usługa Power BI ponownie wysyła zapytanie do zaimportowanych danych, zapewniając interakcyjność.
Wizualizacje lub całe strony raportu można przypiąć jako kafelki pulpitu nawigacyjnego w usługa Power BI. Kafelki są odświeżane automatycznie przy każdym odświeżeniu bazowego modelu semantycznego.
Połączenia trybu DirectQuery
W przypadku nawiązywania połączenia ze źródłem danych w programie Power BI Desktop przy użyciu trybu DirectQuery są obecne następujące warunki łączności danych:
Użyj opcji Pobierz dane , aby wybrać źródło. W przypadku źródeł relacyjnych nadal można wybrać zestaw tabel definiujących zapytanie, które logicznie zwraca zestaw danych. W przypadku źródeł wielowymiarowych, takich jak SAP Business Warehouse (SAP BW), należy wybrać tylko źródło.
Po załadowaniu żadne dane nie są importowane do magazynu usługi Power BI. Zamiast tego podczas tworzenia wizualizacji program Power BI Desktop wysyła zapytania do bazowego źródła danych w celu pobrania niezbędnych danych. Czas potrzebny na odświeżenie wizualizacji zależy od wydajności bazowego źródła danych.
Wszelkie zmiany danych bazowych nie są natychmiast odzwierciedlane w istniejących wizualizacjach. Odświeżanie jest nadal konieczne. Program Power BI Desktop ponownie wysyła niezbędne zapytania dla każdej wizualizacji i aktualizuje wizualizację w razie potrzeby.
Opublikowanie raportu w usługa Power BI powoduje utworzenie i przekazanie modelu semantycznego, tak samo jak w przypadku importowania. Jednak ten semantyczny model nie zawiera żadnych danych.
Otwarcie istniejącego raportu lub utworzenie nowego raportu w usługa Power BI wysyła zapytanie do bazowego źródła danych w celu pobrania niezbędnych danych. W zależności od lokalizacji oryginalnego źródła danych może być konieczne skonfigurowanie lokalnej bramy danych w celu pobrania danych.
Wizualizacje lub całe strony raportu można przypinać jako kafelki pulpitu nawigacyjnego. Aby upewnić się, że otwieranie pulpitu nawigacyjnego jest szybkie, kafelki są automatycznie odświeżane zgodnie z harmonogramem, na przykład co godzinę. Częstotliwość odświeżania można kontrolować w zależności od częstotliwości zmian danych i znaczenia wyświetlania najnowszych danych.
Po otwarciu pulpitu nawigacyjnego kafelki odzwierciedlają dane w momencie ostatniego odświeżenia, a niekoniecznie najnowsze zmiany wprowadzone w bazowym źródle. Możesz odświeżyć otwarty pulpit nawigacyjny, aby upewnić się, że jest on aktualny.
Połączenia na żywo
Po nawiązaniu połączenia z usługami SQL Server Analysis Services możesz zaimportować dane lub użyć połączenia na żywo z wybranym modelem danych. Użycie połączenia na żywo jest podobne do trybu DirectQuery. Żadne dane nie są importowane, a bazowe źródło danych jest odpytywane w celu odświeżenia wizualizacji.
Na przykład w przypadku używania importu do nawiązywania połączenia z usługami SQL Server Analysis Services należy zdefiniować zapytanie względem zewnętrznego źródła usług SQL Server Analysis Services i zaimportować dane. Jeśli łączysz się na żywo, nie zdefiniujesz zapytania, a cały model zewnętrzny będzie wyświetlany na liście pól.
Ta sytuacja ma zastosowanie również w przypadku nawiązywania połączenia z następującymi źródłami, z wyjątkiem braku opcji importowania danych:
Semantyczne modele usługi Power BI, na przykład łączenie się z semantycznym modelem usługi Power BI, który został już opublikowany w usłudze, w celu utworzenia nowego raportu nad nim.
Microsoft Dataverse.
Podczas publikowania raportów usług SQL Server Analysis Services korzystających z połączeń na żywo zachowanie w usługa Power BI jest podobne do raportów trybu DirectQuery w następujący sposób:
Otwarcie istniejącego raportu lub utworzenie nowego raportu w usługa Power BI wysyła zapytanie do bazowego źródła usług SQL Server Analysis Services, prawdopodobnie wymagającej lokalnej bramy danych.
Kafelki pulpitu nawigacyjnego są automatycznie odświeżane zgodnie z harmonogramem, na przykład co godzinę.
Połączenie na żywo różni się również od trybu DirectQuery na kilka sposobów. Na przykład połączenia na żywo zawsze przekazują tożsamość użytkownika otwierającego raport do bazowego źródła usług SQL Server Analysis Services.
Przypadki użycia zapytania bezpośredniego
Nawiązywanie połączenia z zapytaniem bezpośrednim może być przydatne w następujących scenariuszach. W kilku z tych przypadków pozostawienie danych w oryginalnej lokalizacji źródłowej jest konieczne lub korzystne.
Zapytanie bezpośrednie w usłudze Power BI oferuje największe korzyści w następujących scenariuszach:
- Dane są często zmieniane i potrzebne są niemal raporty w czasie rzeczywistym.
- Musisz obsługiwać duże dane bez konieczności wstępnego agregowania.
- Bazowe źródło definiuje i stosuje reguły zabezpieczeń.
- Obowiązują ograniczenia niezależności danych.
- Źródło to wielowymiarowe źródło zawierające miary, takie jak SAP BW.
Często zmieniają się dane i są potrzebne niemal raportowanie w czasie rzeczywistym
Modele można odświeżać przy użyciu importowanych danych co najwyżej raz na godzinę lub częściej z subskrypcjami usługi Power BI Pro lub Power BI Premium. Jeśli dane są stale zmieniane i raporty muszą wyświetlać najnowsze dane, użycie importu z zaplanowanym odświeżaniem może nie spełniać Twoich potrzeb. Dane można przesyłać strumieniowo bezpośrednio do usługi Power BI, chociaż istnieją ograniczenia dotyczące woluminów danych obsługiwanych w tym przypadku.
Użycie trybu DirectQuery oznacza, że otwieranie lub odświeżanie raportu lub pulpitu nawigacyjnego zawsze wyświetla najnowsze dane w źródle. Kafelki pulpitu nawigacyjnego można również aktualizować częściej, nawet co 15 minut.
Dane są bardzo duże
Jeśli dane są bardzo duże, nie jest możliwe ich zaimportowanie. Zapytanie bezpośrednie nie wymaga dużego transferu danych, ponieważ wykonuje zapytania dotyczące danych. Jednak duże dane mogą również spowodować, że wydajność zapytań względem tego bazowego źródła jest zbyt niska.
Nie zawsze trzeba importować pełne, szczegółowe dane. Edytor Power Query ułatwia wstępne agregowanie danych podczas importowania. Technicznie możliwe jest zaimportowanie dokładnie zagregowanych danych potrzebnych dla każdej wizualizacji. Chociaż tryb DirectQuery jest najprostszym podejściem do dużych danych, importowanie zagregowanych danych może zaoferować rozwiązanie, jeśli bazowe źródło danych jest zbyt wolne w przypadku trybu DirectQuery.
Te szczegóły dotyczą używania samej usługi Power BI. Aby uzyskać więcej informacji na temat używania dużych modeli w usłudze Power BI, zobacz duże modele semantyczne w usłudze Power BI Premium. Nie ma żadnych ograniczeń dotyczących częstotliwości odświeżania danych.
Bazowe źródło definiuje reguły zabezpieczeń
Podczas importowania danych usługa Power BI łączy się ze źródłem danych przy użyciu poświadczeń programu Power BI Desktop bieżącego użytkownika lub poświadczeń skonfigurowanych do zaplanowanego odświeżania z usługa Power BI. W przypadku publikowania i udostępniania raportów, które zaimportowały dane, należy zachować ostrożność, aby udostępniać je tylko użytkownikom, którzy mogą wyświetlać dane, lub należy zdefiniować zabezpieczenia na poziomie wiersza w ramach modelu semantycznego.
Tryb DirectQuery umożliwia przeglądarce raportów przekazywanie poświadczeń do bazowego źródła, które stosuje reguły zabezpieczeń. Tryb DirectQuery obsługuje logowanie jednokrotne (SSO) do źródeł danych usługi Azure SQL oraz za pośrednictwem bramy danych do lokalnych serwerów SQL. Aby uzyskać więcej informacji, zobacz Omówienie logowania jednokrotnego (SSO) dla lokalnych bram danych w usłudze Power BI.
Obowiązują ograniczenia niezależności danych
Niektóre organizacje mają zasady dotyczące niezależności danych, co oznacza, że dane nie mogą opuszczać organizacji. Te dane przedstawiają problemy dotyczące rozwiązań opartych na importowaniu danych. W przypadku zapytania bezpośredniego dane pozostają w bazowej lokalizacji źródłowej. Jednak nawet w przypadku trybu DirectQuery usługa Power BI przechowuje niektóre pamięci podręczne danych na poziomie wizualizacji z powodu zaplanowanego odświeżania kafelków.
Bazowe źródło danych używa miar
Podstawowe źródło danych, takie jak SAP HANA lub SAP BW, zawiera miary. Miary oznaczają, że zaimportowane dane są już na pewnym poziomie agregacji, zgodnie z definicją zapytania. Wizualizacja, która prosi o dane na wyższym poziomie agregacji, takiej jak TotalSales by Year, dodatkowo agreguje zagregowaną wartość. Ta agregacja jest odpowiednia dla miar addytywnych, takich jak Sum i Min, ale może być problemem dla miar nie addytywnych, takich jak Average i DistinctCount.
Łatwe uzyskiwanie prawidłowych zagregowanych danych potrzebnych dla wizualizacji bezpośrednio ze źródła wymaga wysyłania zapytań na wizualizację, tak jak w trybie DirectQuery. Po nawiązaniu połączenia z rozwiązaniem SAP BW wybranie trybu DirectQuery umożliwia takie traktowanie miar. Aby uzyskać więcej informacji, zobacz DirectQuery i SAP BW.
Obecnie zapytanie bezpośrednie za pośrednictwem platformy SAP HANA traktuje dane tak samo jak źródło relacyjne i generuje zachowanie podobne do importowania. Aby uzyskać więcej informacji, zobacz DirectQuery i SAP HANA.
Ograniczenia trybu DirectQuery
Korzystanie z trybu DirectQuery ma pewne potencjalnie negatywne konsekwencje. Niektóre z tych ograniczeń różnią się nieznacznie w zależności od konkretnego źródła, którego używasz. W poniższych sekcjach wymieniono ogólne konsekwencje korzystania z trybu DirectQuery oraz ograniczenia związane z wydajnością, zabezpieczeniami, transformacjami, modelowaniem i raportowaniem.
Ogólne implikacje
Poniżej przedstawiono ogólne implikacje i ograniczenia dotyczące używania zapytania bezpośredniego:
Jeśli dane się zmienią, musisz odświeżyć, aby wyświetlić najnowsze dane. Biorąc pod uwagę użycie pamięci podręcznych, nie ma gwarancji, że wizualizacje zawsze wyświetlają najnowsze dane. Na przykład wizualizacja może wyświetlać transakcje w ciągu ostatniego dnia. Zmiana fragmentatora może odświeżyć wizualizację w celu wyświetlenia transakcji z ostatnich dwóch dni, w tym ostatnich nowo przybyłych transakcji. Jednak zwrócenie fragmentatora do oryginalnej wartości może spowodować ponowne wyświetlenie buforowanej poprzedniej wartości. Wybierz pozycję Odśwież , aby wyczyścić wszystkie pamięci podręczne i odświeżyć wszystkie wizualizacje na stronie, aby wyświetlić najnowsze dane.
Jeśli dane się zmienią, nie ma gwarancji spójności między wizualizacjami. Różne wizualizacje, zarówno na tej samej stronie, jak i na różnych stronach, mogą być odświeżane w różnym czasie. Jeśli dane w bazowym źródle się zmieniają, nie ma gwarancji, że każda wizualizacja wyświetla dane w tym samym momencie w czasie.
Biorąc pod uwagę, że dla pojedynczej wizualizacji może być wymagane więcej niż jedno zapytanie, na przykład w celu uzyskania szczegółów i sum, nawet spójność w ramach jednej wizualizacji nie jest gwarantowana. Aby zagwarantować tę spójność, wymagałoby narzutu na odświeżenie wszystkich wizualizacji za każdym razem, gdy każda wizualizacja zostanie odświeżona, wraz z kosztowną funkcją, taką jak izolacja migawki w bazowym źródle danych.
Ten problem można rozwiązać w dużym stopniu, wybierając pozycję Odśwież , aby odświeżyć wszystkie wizualizacje na stronie. Nawet w przypadku trybu importu występuje podobny problem z zachowaniem spójności podczas importowania danych z więcej niż jednej tabeli.
Aby odzwierciedlić zmiany schematu, należy odświeżyć w programie Power BI Desktop. Po opublikowaniu raportu odśwież w usługa Power BI odświeża wizualizacje w raporcie. Jeśli jednak podstawowy schemat źródłowy ulegnie zmianie, usługa Power BI nie zaktualizuje automatycznie listy dostępnych pól. Jeśli tabele lub kolumny zostaną usunięte z bazowego źródła, może to spowodować niepowodzenie zapytania podczas odświeżania. Aby zaktualizować pola w modelu w celu odzwierciedlenia zmian, musisz otworzyć raport w programie Power BI Desktop i wybrać pozycję Odśwież.
Limit 1 milionów wierszy może zwracać dowolne zapytanie. Istnieje stały limit 1 milionów wierszy, które mogą zwracać dowolne pojedyncze zapytanie do bazowego źródła. Ten limit zazwyczaj nie ma praktycznych konsekwencji, a wizualizacje nie będą wyświetlać tych wielu punktów. Jednak limit może wystąpić w przypadkach, gdy usługa Power BI nie w pełni optymalizuje wysłanych zapytań i żąda pewnego pośredniego wyniku przekraczającego limit.
Limit może również wystąpić podczas tworzenia wizualizacji na ścieżce do bardziej uzasadnionego stanu końcowego. Na przykład uwzględnienie wartości Customer i TotalSalesQuantity może osiągnąć ten limit, jeśli istnieje ponad 1 milion klientów, dopóki nie zastosujesz filtru. Zwracany błąd to: Zestaw wyników zapytania do zewnętrznego źródła danych przekroczył maksymalny dozwolony rozmiar wierszy "1000000".
Uwaga
Pojemności Premium umożliwiają przekroczenie limitu miliona wierszy. Aby uzyskać więcej informacji, zobacz Maksymalna liczba zestawów wierszy pośrednich.
Nie można zmienić modelu z importu na tryb DirectQuery. Jeśli importujesz wszystkie niezbędne dane, możesz przełączyć model z trybu DirectQuery na tryb importu. Nie można przełączyć się z powrotem do trybu DirectQuery, przede wszystkim z powodu zestawu funkcji, który tryb DirectQuery nie obsługuje. W przypadku źródeł wielowymiarowych, takich jak SAP BW, nie można przełączyć się z trybu DirectQuery na tryb importu z powodu innego traktowania miar zewnętrznych.
Wpływ na wydajność i obciążenie
W przypadku korzystania z trybu DirectQuery ogólne środowisko zależy od wydajności bazowego źródła danych. Jeśli odświeżanie każdej wizualizacji, na przykład po zmianie wartości fragmentatora, trwa mniej niż pięć sekund, środowisko jest uzasadnione, chociaż może wydawać się powolne w porównaniu z natychmiastową reakcją z zaimportowanymi danymi. Jeśli spowolnienie źródła powoduje, że odświeżanie poszczególnych wizualizacji trwa dłużej niż dziesiątki sekund, środowisko staje się nieuzasadnionie słabe. Zapytania mogą nawet przekraczać limit czasu.
Wraz z wydajnością bazowego źródła obciążenie umieszczone na źródle ma również wpływ na wydajność. Każdy użytkownik, który otwiera udostępniony raport, a każdy kafelek pulpitu nawigacyjnego, który odświeża, wysyła co najmniej jedno zapytanie na wizualizację do bazowego źródła. Źródło musi być w stanie obsłużyć takie obciążenie zapytania przy zachowaniu rozsądnej wydajności.
Implikacje dotyczące zabezpieczeń
Jeśli bazowe źródło danych nie korzysta z logowania jednokrotnego, raport DirectQuery zawsze używa tych samych stałych poświadczeń, aby połączyć się ze źródłem po opublikowaniu go w usługa Power BI. Natychmiast po opublikowaniu raportu DirectQuery należy skonfigurować poświadczenia użytkownika do użycia. Dopóki nie skonfigurujesz poświadczeń, próba otwarcia raportu w usługa Power BI spowoduje wystąpienie błędu.
Po podaniu poświadczeń użytkownika usługa Power BI używa tych poświadczeń dla każdego, kto otworzy raport, tak samo jak w przypadku zaimportowanych danych. Każdy użytkownik widzi te same dane, chyba że zabezpieczenia na poziomie wiersza są zdefiniowane jako część raportu. Należy zwrócić tę samą uwagę na udostępnianie raportu co w przypadku zaimportowanych danych, nawet jeśli istnieją reguły zabezpieczeń zdefiniowane w bazowym źródle.
Nawiązywanie połączenia z semantycznymi modelami usługi Power BI i usługami Analysis Services w trybie DirectQuery zawsze używa logowania jednokrotnego, więc zabezpieczenia są podobne do połączeń na żywo z usługami Analysis Services.
Alternatywne poświadczenia nie są obsługiwane podczas nawiązywania połączeń DirectQuery z programem SQL Server z programu Power BI Desktop. Możesz użyć bieżących poświadczeń systemu Windows lub poświadczeń bazy danych.
Za pomocą modeli złożonych można używać wielu źródeł danych w modelu DirectQuery. W przypadku korzystania z wielu źródeł danych ważne jest, aby zrozumieć implikacje zabezpieczeń dotyczące sposobu, w jaki dane są przemieszczane między bazowymi źródłami danych.
Ograniczenia przekształcania danych
Zapytanie bezpośrednie ogranicza przekształcenia danych, które można zastosować w Edytor Power Query. Zaimportowane dane umożliwiają łatwe zastosowanie zaawansowanego zestawu przekształceń w celu czyszczenia i zmieniania danych przed ich użyciem do tworzenia wizualizacji. Można na przykład analizować dokumenty JSON lub przestawiać dane z kolumny do formularza wiersza. Te przekształcenia są bardziej ograniczone w trybie DirectQuery.
Podczas nawiązywania połączenia ze źródłem przetwarzania analitycznego online (OLAP), takiego jak SAP BW, nie można zdefiniować żadnych przekształceń, a cały model zewnętrzny jest pobierany ze źródła. W przypadku źródeł relacyjnych, takich jak SQL Server, nadal można zdefiniować zestaw przekształceń na zapytanie, ale te przekształcenia są ograniczone ze względu na wydajność.
Wszystkie przekształcenia muszą być stosowane w każdym zapytaniu do bazowego źródła, a nie raz podczas odświeżania danych. Przekształcenia muszą być w stanie rozsądnie przetłumaczyć na pojedyncze zapytanie natywne. Jeśli używasz przekształcenia, które jest zbyt złożone, zostanie wyświetlony błąd informujący, że musi zostać usunięty lub model połączenia musi zostać przełączony w celu zaimportowania.
Ponadto okno dialogowe Pobieranie danych lub Edytor Power Query używać podwybór w zapytaniach generowanych i wysyłanych do pobierania danych dla wizualizacji. Zapytania zdefiniowane w Edytor Power Query muszą być prawidłowe w tym kontekście. W szczególności nie można użyć zapytania z typowymi wyrażeniami tabeli ani tego, który wywołuje procedury składowane.
Ograniczenia modelowania
Termin modelowanie w tym kontekście oznacza działanie uzbogacenia i wzbogacania danych pierwotnych w ramach tworzenia raportu przy użyciu danych. Przykłady modelowania to:
- Definiowanie relacji między tabelami.
- Dodawanie nowych obliczeń, takich jak kolumny obliczeniowe i miary.
- Zmienianie nazw i ukrywanie kolumn i miar.
- Definiowanie hierarchii.
- Definiowanie formatowania kolumn, domyślnego podsumowania i kolejności sortowania.
- Grupowanie lub klastrowanie wartości.
W przypadku korzystania z trybu DirectQuery można nadal wprowadzać wiele z tych wzbogacenia modelu i używać zasady wzbogacania danych pierwotnych w celu zwiększenia późniejszego użycia. Jednak niektóre funkcje modelowania nie są dostępne lub są ograniczone w trybie DirectQuery. Ograniczenia są stosowane w celu uniknięcia problemów z wydajnością.
Następujące ograniczenia są wspólne dla wszystkich źródeł trybu DirectQuery. Więcej ograniczeń może dotyczyć poszczególnych źródeł.
Brak wbudowanej hierarchii dat: w przypadku zaimportowanych danych każda kolumna data/data/godzina ma również wbudowaną hierarchię dat dostępną domyślnie. Jeśli na przykład zaimportujesz tabelę zamówień sprzedaży zawierającą kolumnę OrderDate i użyjesz kolumny OrderDate w wizualizacji, możesz wybrać odpowiedni poziom daty do użycia, taki jak rok, miesiąc lub dzień. Ta wbudowana hierarchia dat nie jest dostępna w trybie DirectQuery. Jeśli istnieje tabela Date (Data ) dostępna w bazowym źródle, podobnie jak zwykle w wielu magazynach danych, możesz użyć funkcji analizy czasowej języka DAX (Data Analysis Expressions).
Obsługa daty/godziny tylko do poziomu sekund: w przypadku modeli semantycznych korzystających z kolumn czasu usługa Power BI wysyła zapytania do bazowego źródła directQuery tylko do poziomu szczegółów sekund, a nie milisekund. Usuń dane z milisekund z kolumn źródłowych.
Ograniczenia w kolumnach obliczeniowych: Kolumny obliczeniowe mogą być tylko wewnątrz wiersza, czyli mogą odwoływać się tylko do wartości innych kolumn tej samej tabeli bez używania żadnych funkcji agregujących. Ponadto dozwolone funkcje skalarne języka DAX, takie jak
LEFT(), są ograniczone do tych funkcji, które można wypchnąć do bazowego źródła. Funkcje różnią się w zależności od dokładnych możliwości źródła. Funkcje, które nie są obsługiwane, nie są wyświetlane w autouzupełnianie podczas tworzenia zapytania języka DAX dla kolumny obliczeniowej i powodują błąd, jeśli jest używany.Brak obsługi funkcji języka DAX nadrzędny-podrzędny: w trybie DirectQuery nie można używać rodziny
DAX PATH()funkcji, które zwykle obsługują struktury nadrzędny-podrzędne, takie jak wykresy kont lub hierarchii pracowników.Brak klastrowania: w przypadku korzystania z trybu DirectQuery nie można używać funkcji klastrowania do automatycznego znajdowania grup.
Ograniczenia raportowania
Prawie wszystkie funkcje raportowania są obsługiwane w przypadku modeli DirectQuery. Jeśli bazowe źródło zapewnia odpowiedni poziom wydajności, można użyć tego samego zestawu wizualizacji co w przypadku zaimportowanych danych.
Jednym z ogólnych ograniczeń jest to, że maksymalna długość danych w kolumnie tekstowej dla modeli semantycznych DirectQuery wynosi 32 764 znaki. Raportowanie dłuższych tekstów powoduje błąd.
Następujące funkcje raportowania usługi Power BI mogą powodować problemy z wydajnością w raportach opartych na zapytaniach bezpośrednich:
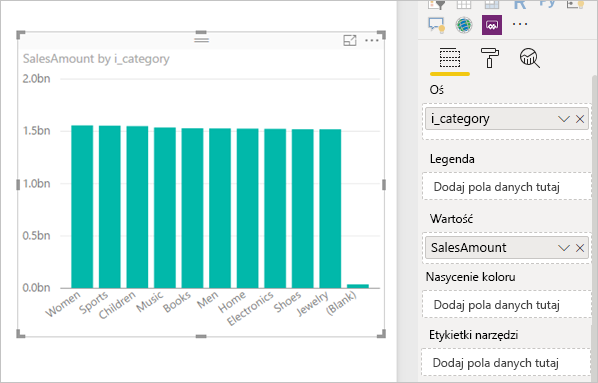
Filtry miar: wizualizacje używające miar lub agregacji kolumn mogą zawierać filtry w tych miarach. Na przykład poniższa ilustracja przedstawia kolumnę SalesAmount by Category (Kwota sprzedaży według kategorii), ale tylko dla kategorii z ponad 20 mln sprzedaży.
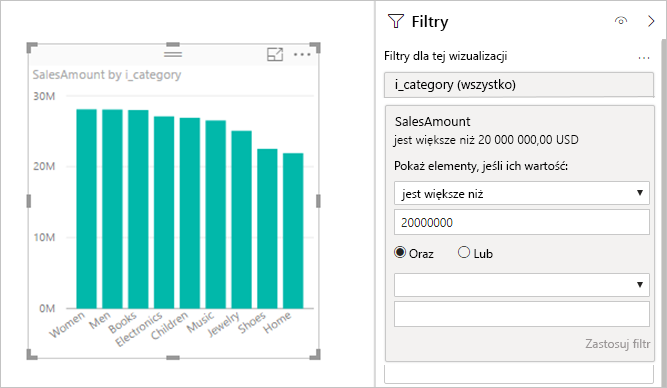
Takie podejście powoduje wysłanie dwóch zapytań do bazowego źródła:
- Pierwsze zapytanie pobiera kategorie spełniające warunek SalesAmount większy niż 20 milionów.
- Drugie zapytanie pobiera niezbędne dane dla wizualizacji, w tym kategorie, które spełniają
WHEREwarunek.
Takie podejście zwykle działa dobrze, jeśli istnieją setki lub tysiące kategorii, jak w tym przykładzie. Wydajność może ulec pogorszeniu, jeśli liczba kategorii jest znacznie większa. Zapytanie kończy się niepowodzeniem, jeśli istnieje ponad milion kategorii.
Filtry topN: można zdefiniować zaawansowane filtry, aby filtrować tylko na pierwszych lub dolnych
Nwartościach sklasyfikowanych według miary. Na przykład filtry mogą zawierać 10 pierwszych kategorii. To podejście ponownie wysyła dwa zapytania do bazowego źródła. Jednak pierwsze zapytanie zwraca wszystkie kategorie z bazowego źródła, a następnieTopNsą określane na podstawie zwróconych wyników. W zależności od kardynalności kolumny, takie podejście może prowadzić do problemów z wydajnością lub niepowodzeń zapytań z powodu limitu miliona wierszy w wynikach zapytania.Mediana: wszelkie agregacje, takie jak
SumlubCount Distinct, są wypychane do bazowego źródła. Jednak agregacjamediannie jest zwykle obsługiwana przez bazowe źródło. W przypadkumedianelementu dane szczegółowe są pobierane z bazowego źródła, a mediana jest obliczana z zwróconych wyników. Takie podejście jest uzasadnione do obliczenia mediany w stosunkowo małej liczbie wyników.Problemy z wydajnością lub błędy zapytań mogą wystąpić, jeśli kardynalność jest duża z powodu limitu miliona wierszy. Na przykład zapytanie dotyczące mediany kraju/populacji regionu może być uzasadnione, ale mediana ceny sprzedaży może nie być rozsądna.
Zaawansowane filtry tekstowe, takie jak "contains": Zaawansowane filtrowanie w kolumnie tekstowej umożliwia filtrowanie, takie jak
containsibegins with. Te filtry mogą spowodować obniżenie wydajności niektórych źródeł danych. W szczególności nie używaj filtru domyślnegocontains, jeśli potrzebujesz dokładnego dopasowania. Chociaż wyniki mogą być takie same w zależności od rzeczywistych danych, wydajność może być drastycznie inna ze względu na indeksy.Fragmentatory wielokrotnego wyboru: domyślnie fragmentatory zezwalają tylko na dokonywanie pojedynczego zaznaczenia. Zezwolenie na wybór wielu filtrów może powodować problemy z wydajnością. Jeśli na przykład użytkownik wybierze 10 interesujących produktów, każdy nowy wybór spowoduje wysłanie zapytań do źródła. Mimo że użytkownik może wybrać następny element przed ukończeniem zapytania, takie podejście powoduje dodatkowe obciążenie bazowego źródła.
Sumy w wizualizacjach tabeli: domyślnie tabele i macierze wyświetlają sumy i sumy częściowe. W wielu przypadkach pobieranie wartości dla takich sum wymaga wysyłania oddzielnych zapytań do bazowego źródła. To wymaganie ma zastosowanie za każdym razem, gdy używasz
DistinctCountagregacji lub we wszystkich przypadkach, które używają trybu DirectQuery za pośrednictwem oprogramowania SAP BW lub SAP HANA. Takie sumy można wyłączyć przy użyciu okienka Format .
Zalecenia dotyczące trybu DirectQuery
Ta sekcja zawiera ogólne wskazówki dotyczące pomyślnego korzystania z trybu DirectQuery, biorąc pod uwagę jego konsekwencje.
Wydajność bazowego źródła danych
Sprawdź, czy proste wizualizacje są odświeżane w ciągu pięciu sekund, zapewniając rozsądne interaktywne środowisko. Jeśli odświeżanie wizualizacji trwa dłużej niż 30 sekund, prawdopodobnie dalsze problemy z publikacją raportu sprawią, że rozwiązanie będzie niedostępne.
Jeśli zapytania są powolne, sprawdź zapytania wysyłane do bazowego źródła i przyczynę niskiej wydajności. Aby uzyskać więcej informacji, zobacz Diagnostyka wydajności.
Ten artykuł nie obejmuje szerokiego zakresu zaleceń dotyczących optymalizacji bazy danych w pełnym zestawie potencjalnych źródeł bazowych. W większości sytuacji stosuje się następujące standardowe praktyki bazy danych:
Aby uzyskać lepszą wydajność, bazuj relacje na kolumnach całkowitych zamiast łączenia kolumn innych typów danych.
Utwórz odpowiednie indeksy. Tworzenie indeksu zwykle oznacza używanie indeksów magazynu kolumn w źródłach, które je obsługują, na przykład programu SQL Server.
Zaktualizuj wszelkie niezbędne statystyki w źródle.
Projekt modelu
Podczas definiowania modelu postępuj zgodnie z poniższymi wskazówkami:
Unikaj złożonych zapytań w Edytor Power Query. Edytor Power Query tłumaczy złożone zapytanie na pojedyncze zapytanie SQL. Pojedyncze zapytanie jest wyświetlane w podwybór każdego zapytania wysłanego do tej tabeli. Jeśli to zapytanie jest złożone, może to spowodować problemy z wydajnością każdego wysłanego zapytania. Rzeczywiste zapytanie SQL dla zestawu kroków można uzyskać, klikając prawym przyciskiem myszy ostatni krok w obszarze Zastosowane kroki w Edytor Power Query i wybierając polecenie Wyświetl zapytanie natywne.
Zachowaj proste miary. Przynajmniej początkowo ograniczaj miary do prostych agregacji. Jeśli miary działają w zadowalający sposób, można zdefiniować bardziej złożone miary, ale zwrócić uwagę na wydajność.
Unikaj relacji w kolumnach obliczeniowych. W bazach danych, w których należy wykonać sprzężenia wielokolumna, usługa Power BI nie zezwala na oparcie relacji na wielu kolumnach jako klucz podstawowy lub klucz obcy. Typowym obejściem jest łączenie kolumn przy użyciu kolumny obliczeniowej i oparcie sprzężenia w tej kolumnie.
To obejście jest uzasadnione w przypadku zaimportowanych danych, ale w przypadku zapytania bezpośredniego powoduje sprzężenia w wyrażeniu. Ten wynik zwykle uniemożliwia korzystanie z jakichkolwiek indeksów i prowadzi do niskiej wydajności. Jedynym obejściem jest faktyczne zmaterializowanie wielu kolumn w jednej kolumnie w bazowym źródle danych.
Unikaj relacji w kolumnach "uniqueidentifier". Usługa Power BI nie obsługuje
uniqueidentifiernatywnie typu danych. Definiowanie relacji między kolumnamiuniqueidentifierpowoduje utworzenie zapytania za pomocą sprzężenia, które obejmuje rzutowanie. To podejście zwykle prowadzi do niskiej wydajności. Jedynym obejściem jest zmaterializowanie kolumn alternatywnego typu w bazowym źródle danych.Ukryj kolumnę "to" w relacjach. Kolumna
torelacji jest często kluczem podstawowym wtotabeli. Ta kolumna powinna być ukryta, ale jeśli jest ukryta, nie jest wyświetlana na liście pól i nie może być używana w wizualizacjach. Często kolumny, na których opierają się relacje, to kolumny systemowe, na przykład klucze zastępcze w magazynie danych. Nadal najlepiej ukryć takie kolumny.Jeśli kolumna ma znaczenie, wprowadź widoczną kolumnę obliczeniową, która ma proste wyrażenie równe kluczowi podstawowemu, na przykład:
ProductKey_PK (Destination of a relationship, hidden) ProductKey (= [ProductKey_PK], visible) ProductName ...Sprawdź wszystkie kolumny obliczeniowe i zmiany typu danych. Tabele obliczeniowe można używać w przypadku używania trybu DirectQuery z modelami złożonymi. Te możliwości nie muszą być szkodliwe, ale powodują zapytania zawierające wyrażenia, a nie proste odwołania do kolumn. Te zapytania mogą spowodować, że indeksy nie są używane.
Unikaj dwukierunkowego filtrowania krzyżowego w relacjach. Użycie dwukierunkowego filtrowania krzyżowego może prowadzić do instrukcji zapytań, które nie działają prawidłowo. Aby uzyskać więcej informacji na temat dwukierunkowego filtrowania krzyżowego, zobacz Włączanie dwukierunkowego filtrowania krzyżowego dla zapytania bezpośredniego w programie Power BI Desktop lub pobierz oficjalny dokument dwukierunkowy filtrowania krzyżowego . Przykłady w dokumencie dotyczą usług SQL Server Analysis Services, ale podstawowe kwestie dotyczą również usługi Power BI.
Eksperymentuj z ustawieniem Przyjmij integralność referencyjną. Ustawienie Przyjmij integralność referencyjną w relacjach umożliwia używanie
INNER JOINzapytań, a nieOUTER JOINinstrukcji. Te wskazówki zwykle zwiększają wydajność zapytań, chociaż zależą one od specyfiki źródła danych.Nie używaj filtrowania dat względnych w Edytor Power Query. Istnieje możliwość zdefiniowania filtrowania dat względnych w Edytor Power Query. Na przykład można filtrować do wierszy, w których data przypada w ciągu ostatnich 14 dni.
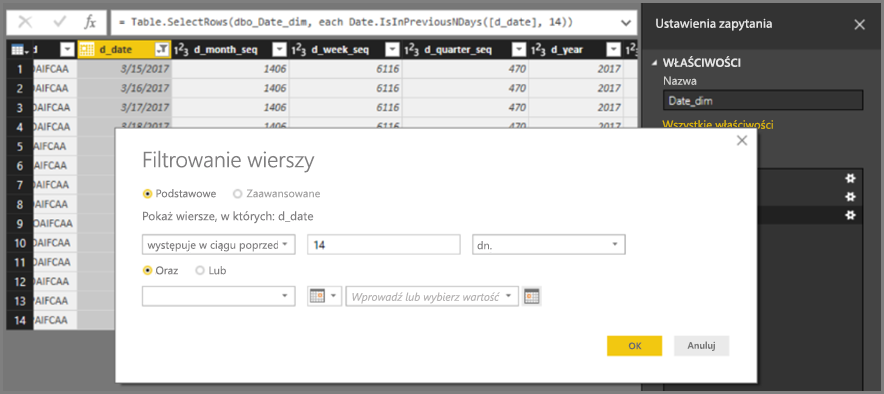
Jednak ten filtr przekłada się na filtr na podstawie stałej daty, takiej jak godzina utworzenia zapytania, jak widać w zapytaniu natywnym.

Te dane prawdopodobnie nie są potrzebne. Aby upewnić się, że filtr jest stosowany na podstawie daty w momencie uruchomienia raportu, zastosuj filtr daty w raporcie. Możesz utworzyć kolumnę obliczeniową, która oblicza liczbę dni temu przy użyciu
DAX DATE()funkcji i użyć tej kolumny obliczeniowej w filtrze.
Projekt raportu
Podczas tworzenia raportu korzystającego z połączenia DirectQuery postępuj zgodnie z następującymi wskazówkami:
Rozważ użycie opcji redukcji zapytań: usługa Power BI udostępnia opcje raportów umożliwiające wysyłanie mniejszej liczby zapytań i wyłączanie niektórych interakcji, które powodują złe środowisko, jeśli wynikowe zapytania długo się uruchamiają. Te opcje mają zastosowanie podczas interakcji z raportem w programie Power BI Desktop, a także mają zastosowanie, gdy użytkownicy korzystają z raportu w usługa Power BI.
Aby uzyskać dostęp do tych opcji w programie Power BI Desktop, przejdź do pozycji Opcje plików>i ustawienia>Opcje i wybierz pozycję Redukcja zapytań.
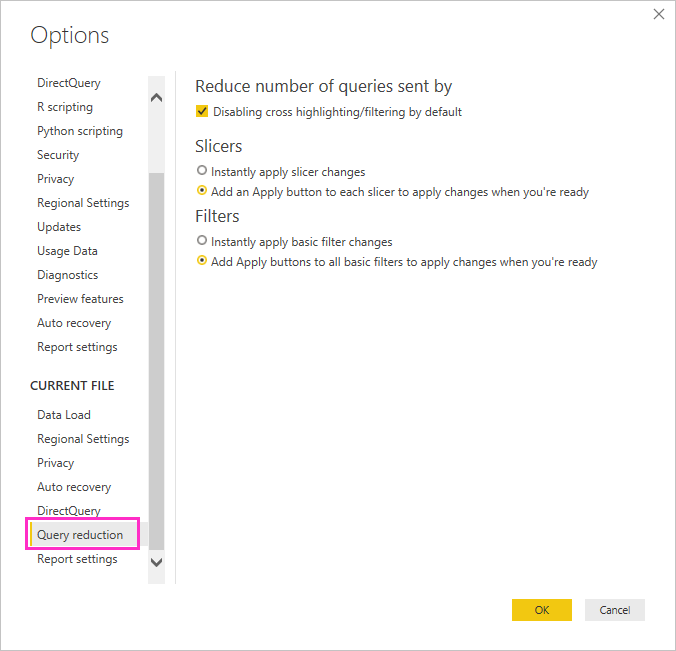
Opcje na ekranie Redukcji zapytania umożliwiają wyświetlenie przycisku Zastosuj dla fragmentatorów lub wybranych filtrów. Żadne zapytania nie są wysyłane do momentu wybrania przycisku Zastosuj w filtrze lub fragmentatorze. Następnie zapytania używają wybranych opcji do filtrowania danych. Ten przycisk umożliwia wybranie kilku fragmentatorów i filtrów przed ich zastosowaniem.
Najpierw zastosuj filtry: zawsze stosuj wszystkie odpowiednie filtry na początku tworzenia wizualizacji. Na przykład zamiast przeciągać wartości TotalSalesAmount i ProductName, a następnie filtrować do określonego roku, zastosuj filtr na początku roku .
Każdy krok tworzenia wizualizacji wysyła zapytanie. Mimo że można wprowadzić kolejną zmianę przed ukończeniem pierwszego zapytania, to podejście nadal pozostawia niepotrzebne obciążenie bazowego źródła. Wczesne stosowanie filtrów sprawia, że te zapytania pośrednie są mniej kosztowne. Nie można wcześnie zastosować filtrów, co może spowodować przekroczenie limitu miliona wierszy.
Ogranicz liczbę wizualizacji na stronie: po otwarciu strony lub zmianie fragmentatora lub filtru na poziomie strony wszystkie wizualizacje na stronie są odświeżane. Istnieje limit liczby zapytań równoległych. Wraz ze wzrostem liczby wizualizacji niektóre wizualizacje są odświeżane szeregowo, co zwiększa czas potrzebny na odświeżenie strony. Dlatego najlepiej ograniczyć liczbę wizualizacji na jednej stronie i zamiast tego mieć więcej prostszych stron.
Rozważ wyłączenie interakcji między wizualizacjami: domyślnie wizualizacje na stronie raportu mogą służyć do filtrowania krzyżowego i wyróżniania krzyżowego innych wizualizacji na stronie. Jeśli na przykład wybierzesz wykres kołowy 1999 , wykres kolumnowy zostanie wyróżniony krzyżowo, aby pokazać sprzedaż według kategorii dla 1999 roku.
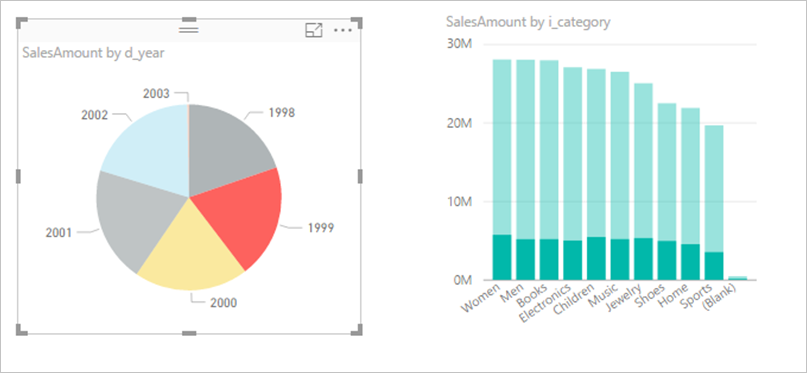
Filtrowanie krzyżowe i wyróżnianie krzyżowe w trybie DirectQuery wymaga przesłania zapytań do bazowego źródła. Należy wyłączyć tę interakcję, jeśli czas potrzebny na reagowanie na wybory użytkowników jest zbyt długi.
Możesz użyć ustawień redukcji zapytań, aby wyłączyć wyróżnianie krzyżowe w raporcie lub na podstawie wielkości liter. Aby uzyskać więcej informacji, zobacz Jak wizualizacje filtrować krzyżowo w raporcie usługi Power BI.
Maksymalna liczba połączeń
Dla każdego bazowego źródła danych można ustawić maksymalną liczbę połączeń, które steruje liczbą zapytań wysyłanych współbieżnie do każdego źródła danych.
Zapytanie bezpośrednie otwiera domyślną maksymalną liczbę 10 połączeń współbieżnych. Aby zmienić maksymalną liczbę bieżącego pliku w programie Power BI Desktop, przejdź do pozycji Opcje plików>i opcje>, a następnie wybierz pozycję DirectQuery w sekcji Bieżący plik w okienku po lewej stronie.
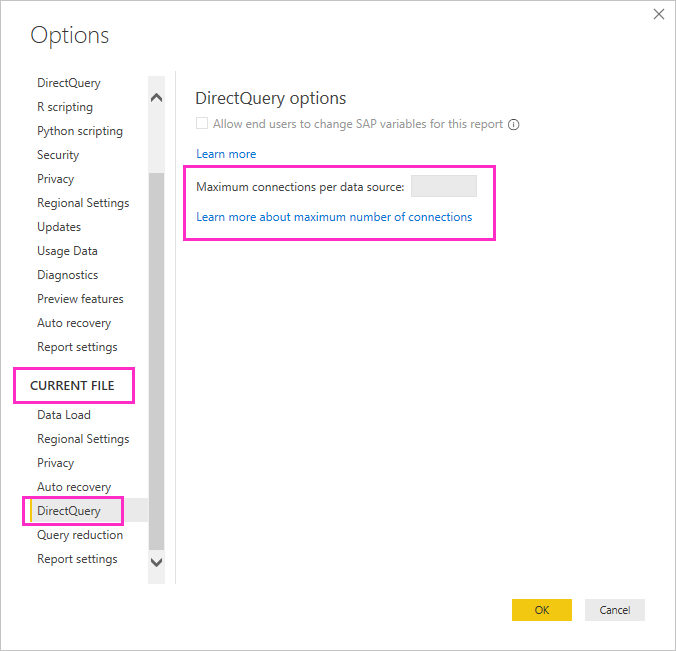
To ustawienie jest włączone tylko wtedy, gdy w bieżącym raporcie znajduje się co najmniej jedno źródło zapytania bezpośredniego. Wartość ma zastosowanie do wszystkich źródeł trybu DirectQuery oraz do wszystkich nowych źródeł directQuery dodanych do tego raportu.
Zwiększenie maksymalnej liczby połączeń na źródło danych umożliwia wysyłanie większej liczby zapytań do podanej maksymalnej liczby do bazowego źródła danych. Takie podejście jest przydatne, gdy wiele wizualizacji znajduje się na jednej stronie lub wielu użytkowników uzyskuje dostęp do raportu w tym samym czasie. Po osiągnięciu maksymalnej liczby połączeń kolejne zapytania są kolejkowane do momentu udostępnienia połączenia. Wyższy limit powoduje większe obciążenie bazowego źródła, więc ustawienie nie ma gwarancji poprawy ogólnej wydajności.
Po opublikowaniu raportu w usługa Power BI maksymalna liczba współbieżnych zapytań zależy również od stałych limitów ustawionych w środowisku docelowym, w którym raport jest publikowany. Usługi Power BI, Power BI Premium i Serwer raportów usługi Power BI nakładają różne limity. W poniższej tabeli wymieniono górne limity aktywnych połączeń na źródło danych dla każdego środowiska usługi Power BI. Te limity dotyczą źródeł danych w chmurze i lokalnych źródeł danych, takich jak SQL Server, Oracle i Teradata.
| Środowisko | Górny limit dla źródła danych |
|---|---|
| Power BI Pro | 10 aktywnych połączeń |
| Power BI Premium | Zależy od ograniczenia jednostki SKU modelu semantycznego |
| Serwer raportów usługi Power BI | 10 aktywnych połączeń |
Uwaga
Maksymalna liczba ustawień połączeń Trybu DirectQuery dotyczy wszystkich źródeł trybu DirectQuery po włączeniu rozszerzonych metadanych, co jest ustawieniem domyślnym dla wszystkich modeli utworzonych w programie Power BI Desktop.
Zapytanie bezpośrednie w usługa Power BI
Wszystkie źródła danych trybu DirectQuery są obsługiwane z poziomu programu Power BI Desktop, a niektóre źródła są również dostępne bezpośrednio z poziomu usługa Power BI. Użytkownik biznesowy może używać usługi Power BI do nawiązywania połączenia z danymi w usłudze Salesforce, na przykład i natychmiast uzyskać pulpit nawigacyjny bez korzystania z programu Power BI Desktop.
Tylko dwa następujące źródła z obsługą trybu DirectQuery są dostępne bezpośrednio w usługa Power BI:
- platforma Spark
- Azure Synapse Analytics (dawniej Azure SQL Data Warehouse)
Nawet w przypadku tych dwóch źródeł najlepszym rozwiązaniem jest uruchomienie trybu DirectQuery w programie Power BI Desktop. Chociaż początkowo można łatwo nawiązać połączenie w usługa Power BI, istnieją ograniczenia dotyczące dalszego ulepszania wynikowego raportu. Na przykład w usłudze nie można utworzyć żadnych obliczeń ani użyć wielu funkcji analitycznych albo odświeżyć metadane, aby odzwierciedlić zmiany w bazowym schemacie.
Wydajność raportu DirectQuery w usługa Power BI zależy od stopnia obciążenia umieszczonego w bazowym źródle danych. Obciążenie zależy od:
- Liczba użytkowników, którzy udostępniają raport i pulpit nawigacyjny.
- Złożoność raportu.
- Określa, czy raport definiuje zabezpieczenia na poziomie wiersza.
Zachowanie raportu w usługa Power BI
Po otwarciu raportu w usługa Power BI wszystkie wizualizacje na aktualnie widocznej stronie są odświeżane. Każda wizualizacja wymaga co najmniej jednego zapytania do bazowego źródła danych. Niektóre wizualizacje mogą wymagać więcej niż jednego zapytania. Na przykład wizualizacja może wyświetlać wartości zagregowane z dwóch różnych tabel faktów lub zawierać bardziej złożoną miarę lub zawierać sumy miary nie addytywnej, takiej jak Count Distinct. Przejście na nową stronę odświeża te wizualizacje. Odświeżanie wysyła nowy zestaw zapytań do bazowego źródła.
Każda interakcja użytkownika w raporcie może spowodować odświeżenie wizualizacji. Na przykład wybranie innej wartości we fragmentatorze wymaga wysłania nowego zestawu zapytań w celu odświeżenia wszystkich wizualizacji, których dotyczy problem. To samo dotyczy wybierania wizualizacji w celu wyróżniania krzyżowego innych wizualizacji lub zmiany filtru. Podobnie tworzenie lub edytowanie raportu wymaga wysłania zapytań dla każdego kroku na ścieżce w celu utworzenia ostatecznej wizualizacji.
Istnieje pewne buforowanie wyników. Odświeżanie wizualizacji jest natychmiastowe, jeśli ostatnio uzyskano dokładnie te same wyniki. Jeśli zdefiniowano zabezpieczenia na poziomie wiersza, te pamięci podręczne nie są współużytkowane przez użytkowników.
Użycie trybu DirectQuery nakłada pewne ważne ograniczenia w niektórych możliwościach oferowanych przez usługa Power BI dla opublikowanych raportów:
Szybki wgląd w szczegółowe informacje nie jest obsługiwany: usługa Power BI szybko wyszukuje różne podzestawy modelu semantycznego podczas stosowania zestawu zaawansowanych algorytmów w celu odnajdywania potencjalnie interesujących szczegółowych informacji. Ponieważ szybkie szczegółowe informacje wymagają zapytań o wysokiej wydajności, ta funkcja nie jest dostępna w modelach semantycznych korzystających z trybu DirectQuery.
Korzystanie z funkcji Eksploruj w programie Excel powoduje niską wydajność: możesz eksplorować model semantyczny przy użyciu funkcji Eksploruj w programie Excel , która umożliwia tworzenie tabel przestawnych i wykresów przestawnych w programie Excel. Ta funkcja jest obsługiwana w przypadku modeli semantycznych korzystających z trybu DirectQuery, ale wydajność jest niższa niż tworzenie wizualizacji w usłudze Power BI. Jeśli korzystanie z programu Excel jest ważne w Twoich scenariuszach, należy uwzględnić ten problem podczas podejmowania decyzji, czy używać trybu DirectQuery.
Program Excel nie pokazuje hierarchii: na przykład w przypadku korzystania z funkcji Analizuj w programie Excel program Excel nie wyświetla żadnych hierarchii zdefiniowanych w modelach usług Azure Analysis Services ani semantycznych modelach usługi Power BI korzystających z trybu DirectQuery.
Odświeżanie pulpitu nawigacyjnego
W usługa Power BI można przypiąć poszczególne wizualizacje lub całe strony do pulpitów nawigacyjnych jako kafelki. Kafelki oparte na semantycznych modelach DirectQuery są odświeżane automatycznie, wysyłając zapytania do bazowych źródeł danych zgodnie z harmonogramem. Domyślnie modele semantyczne są odświeżane co godzinę, ale można skonfigurować interwały harmonogramu odświeżania między tygodniem a co 15 minut w ramach ustawień modelu semantycznego.
Jeśli w modelu nie zdefiniowano zabezpieczeń na poziomie wiersza, każdy kafelek jest odświeżany raz, a wyniki są udostępniane wszystkim użytkownikom. W przypadku korzystania z zabezpieczeń na poziomie wiersza każdy kafelek wymaga oddzielnych zapytań wysyłanych przez użytkownika do bazowego źródła.
Może istnieć duży efekt mnożnika. Pulpit nawigacyjny z 10 kafelkami udostępnionymi 100 użytkownikom utworzonym w modelu semantycznym przy użyciu trybu DirectQuery z zabezpieczeniami na poziomie wiersza powoduje wysłanie co najmniej 1000 zapytań do bazowego źródła danych dla każdego odświeżenia. Należy uważnie rozważyć użycie zabezpieczeń na poziomie wiersza i konfiguracji harmonogramu odświeżania.
Limity czasu zapytań
Limit czasu czterech minut dotyczy poszczególnych zapytań w usługa Power BI. Zapytania, które trwa dłużej niż cztery minuty, kończą się niepowodzeniem. Ten limit ma na celu zapobieganie problemom spowodowanym nadmiernie długim czasem wykonywania. W przypadku źródeł, które mogą zapewnić interaktywną wydajność zapytań, należy użyć trybu DirectQuery tylko w przypadku źródeł.
Po osiągnięciu limitu czasu wizualizacje nie mogą załadować się z powodu następującego błędu: The query has exceeded the available resources. Try filtering to decrease the amount of data requested. The XML for Analysis request timed out before it was completed. Timeout value: 225 sec.
Performance Diagnostics
W tej sekcji opisano sposób diagnozowania problemów z wydajnością lub uzyskiwania bardziej szczegółowych informacji w celu optymalizacji raportów.
Rozpocznij diagnozowanie problemów z wydajnością w programie Power BI Desktop, a nie w usługa Power BI. Problemy z wydajnością są często oparte na wydajności bazowego źródła. Można łatwiej identyfikować i diagnozować problemy w bardziej izolowanym środowisku programu Power BI Desktop.
Takie podejście początkowo eliminuje niektóre składniki, takie jak brama usługi Power BI. Jeśli problemy z wydajnością nie występują w programie Power BI Desktop, możesz zbadać szczegóły raportu w usługa Power BI.
Analizator wydajności programu Power BI Desktop jest przydatnym narzędziem do identyfikowania problemów. Spróbuj odizolować wszelkie problemy z jedną wizualizacją, a nie wiele wizualizacji na stronie. Jeśli pojedyncza wizualizacja na stronie programu Power BI Desktop jest powolna, użyj analizatora wydajności do analizowania zapytań wysyłanych przez program Power BI Desktop do bazowego źródła.
Możesz również wyświetlić ślady i informacje diagnostyczne emitujące niektóre bazowe źródła danych. Nawet jeśli nie ma śladów ze źródła, plik śledzenia może zawierać przydatne szczegóły dotyczące sposobu uruchamiania zapytania i sposobu jego ulepszania. Możesz użyć następującego procesu, aby wyświetlić zapytania wysyłane przez usługę Power BI i ich czasy wykonywania.
Wyświetlanie zapytań przy użyciu programu SQL Server Profiler
Domyślnie program Power BI Desktop rejestruje zdarzenia podczas danej sesji do pliku śledzenia o nazwie FlightRecorderCurrent.trc. Plik śledzenia znajduje się w folderze programu Power BI Desktop dla bieżącego użytkownika w folderze o nazwie AnalysisServicesWorkspaces.
W przypadku niektórych źródeł zapytania bezpośredniego ten plik śledzenia zawiera wszystkie zapytania wysyłane do bazowego źródła danych. Następujące źródła danych wysyłają zapytania do dziennika:
- SQL Server
- Azure SQL Database
- Azure Synapse Analytics (dawniej Azure SQL Data Warehouse)
- Oracle
- Teradata
- SAP HANA
Pliki śledzenia można odczytać przy użyciu programu SQL Server Profiler, części bezpłatnego pobierania programu SQL Server Management Studio.
Aby otworzyć plik śledzenia dla bieżącej sesji:
Podczas sesji programu Power BI Desktop wybierz pozycję Opcje i ustawienia>, a następnie wybierz pozycję Diagnostyka.
W obszarze Kolekcja zrzutów awaryjnych wybierz pozycję Otwórz folder zrzutu awaryjnego/śladów.
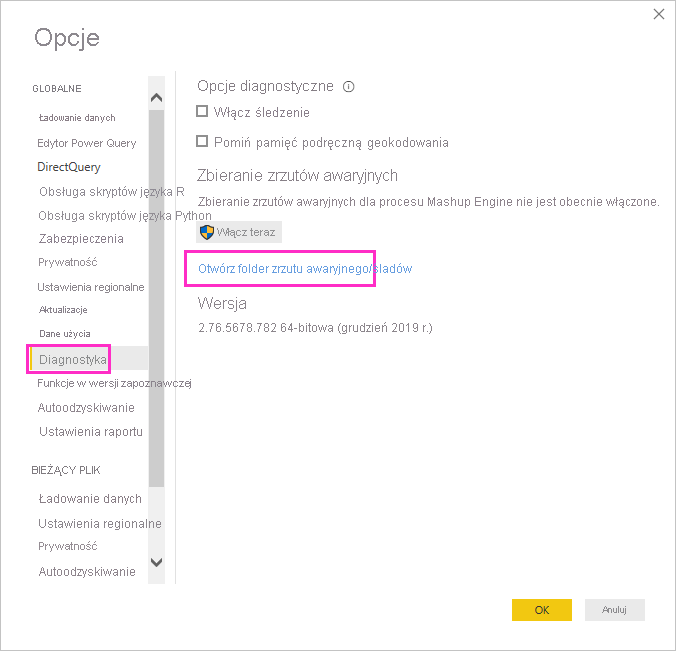
Zostanie otwarty folder Power BI Desktop\Traces .
Przejdź do folderu nadrzędnego, a następnie do folderu AnalysisServicesWorkspaces , który zawiera jeden folder obszaru roboczego dla każdego otwartego wystąpienia programu Power BI Desktop. Te foldery mają nazwę z sufiksem liczby całkowitej, takim jak AnalysisServicesWorkspace2058279583. Folder obszaru roboczego zostanie usunięty po zakończeniu skojarzonej sesji programu Power BI Desktop.
Wewnątrz folderu obszaru roboczego dla bieżącej sesji usługi Power BI folder \Data zawiera plik śledzenia FlightRecorderCurrent.trc . Zanotuj wartość lokalizacji.
Otwórz program SQL Server Profiler i wybierz pozycję Plik>>plik śledzenia.
Przejdź do lub wprowadź ścieżkę do pliku śledzenia dla bieżącej sesji usługi Power BI i otwórz plik FlightRecorderCurrent.trc.
Program SQL Server Profiler wyświetla wszystkie zdarzenia z bieżącej sesji. Poniższy zrzut ekranu przedstawia grupę zdarzeń dla zapytania. Każda grupa zapytań ma następujące zdarzenia:
Zdarzenie
Query BeginiQuery Endreprezentujące początek i koniec zapytania języka DAX wygenerowanego przez zmianę wizualizacji lub filtru w interfejsie użytkownika usługi Power BI albo filtrowanie lub przekształcanie danych w Edytor Power Query.Co najmniej jedna para zdarzeń
DirectQuery BeginiDirectQuery Endreprezentująca zapytania wysyłane do bazowego źródła danych w ramach oceny zapytania języka DAX.

Wiele zapytań języka DAX może być uruchamianych równolegle, więc zdarzenia z różnych grup mogą być przeplatane. Możesz użyć ActivityID wartości , aby określić, które zdarzenia należą do tej samej grupy.
Interesujące są również następujące kolumny:
-
TextData: tekstowy szczegół zdarzenia. W przypadku zdarzeń
Query BeginiQuery Endszczegóły to zapytanie języka DAX. W przypadku zdarzeńDirectQuery BeginiDirectQuery Endszczegóły to zapytanie SQL wysyłane do bazowego źródła. Wartość TextData dla aktualnie wybranego zdarzenia jest również wyświetlana w okienku w dolnej części ekranu. - EndTime: godzina zakończenia zdarzenia.
- Czas trwania: czas trwania w milisekundach trwał, aby uruchomić zapytanie języka DAX lub SQL.
- Błąd: czy wystąpił błąd, w którym przypadku zdarzenie jest również wyświetlane na czerwono.
Aby przechwycić ślad, aby pomóc zdiagnozować potencjalny problem z wydajnością:
Otwórz pojedynczą sesję programu Power BI Desktop, aby uniknąć pomyłek wielu folderów obszaru roboczego.
Wykonaj zestaw interesujących cię akcji programu Power BI Desktop. Uwzględnij jeszcze kilka akcji, aby upewnić się, że interesujące zdarzenia są opróżniane do pliku śledzenia.
Otwórz program SQL Server Profiler i sprawdź ślad. Pamiętaj, że zamknięcie programu Power BI Desktop powoduje usunięcie pliku śledzenia. Ponadto dalsze akcje w programie Power BI Desktop nie są natychmiast wyświetlane. Aby wyświetlić nowe zdarzenia, należy zamknąć i ponownie otworzyć plik śledzenia.
Zachowaj poszczególne sesje dość małe, być może 10 sekund akcji, a nie setki. Takie podejście ułatwia interpretowanie pliku śledzenia. Istnieje również limit rozmiaru pliku śledzenia. W przypadku długich sesji istnieje szansa na porzucenie wczesnych zdarzeń.
Omówienie formatu zapytań
Ogólny format zapytań programu Power BI Desktop używa podwybór dla każdej tabeli, do której się odwołuje. Zapytanie Edytor Power Query definiuje zapytania podwybierz. Załóżmy na przykład, że w programie SQL Server istnieją następujące tabele TPC-DS :
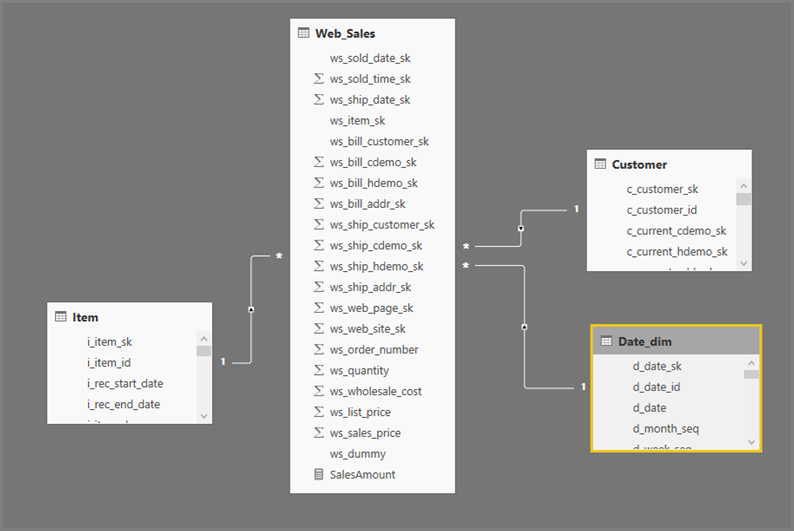
Uruchomienie następującego zapytania:
SalesAmount (SUMX(Web_Sales, [ws_sales_price]*[ws_quantity]))
by Item[i_category]
for Date_dim[d_year] = 2000
Wyniki w następującej wizualizacji w usłudze Power BI:
Odświeżanie wizualizacji powoduje utworzenie zapytania SQL na poniższej ilustracji. Istnieją trzy zapytania podwybierz dla Web_Saleselementów , Itemi Date_dim, które zwracają wszystkie kolumny w odpowiedniej tabeli, mimo że wizualizacja odwołuje się tylko do czterech kolumn.
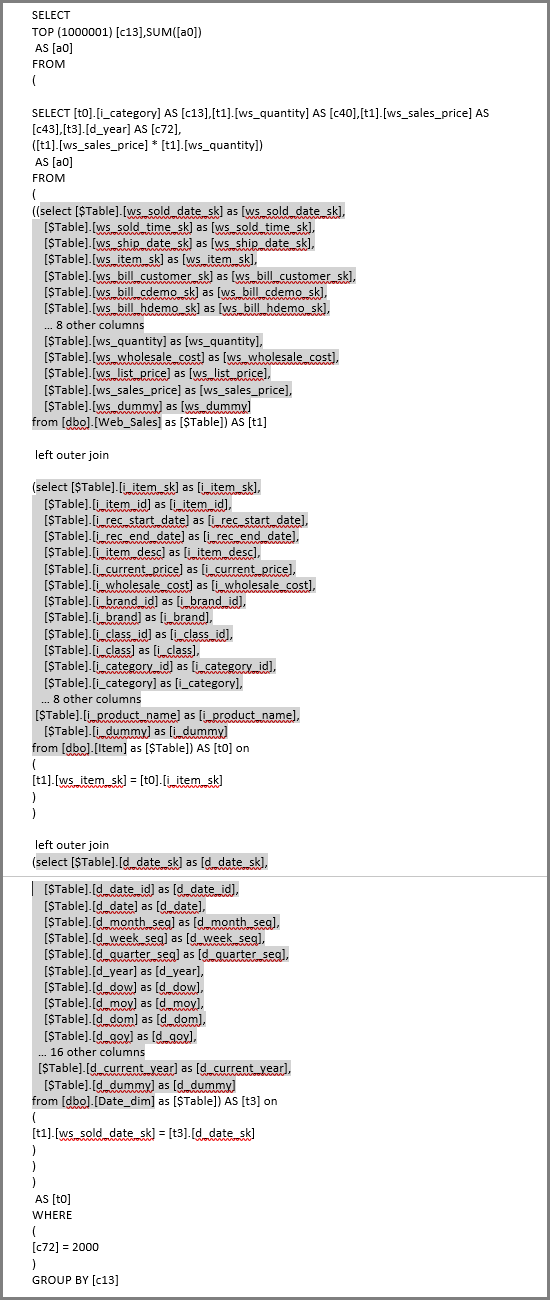
Edytor Power Query definiuje dokładne zapytania podwybierz. To użycie zapytań podrzędnych nie zostało pokazane, aby wpływać na wydajność dla źródeł danych obsługiwane przez zapytanie bezpośrednie. Źródła danych, takie jak PROGRAM SQL Server, optymalizują odwołania do innych kolumn.
Usługa Power BI używa tego wzorca, ponieważ analityk udostępnia zapytanie SQL bezpośrednio. Usługa Power BI używa podanego zapytania bez próby ponownego zapisania go.
Powiązana zawartość
Aby uzyskać więcej informacji na temat trybu DirectQuery w usłudze Power BI, zobacz:
W tym artykule opisano aspekty trybu DirectQuery, które są wspólne dla wszystkich źródeł danych. Aby uzyskać szczegółowe informacje o określonych źródłach, zobacz następujące artykuły: